




Amazon Textract をサーバーレスエキスパートが解説🤲AWSでデータからテキストデータを自動的に抽出しましょう
 2022.01.19
2022.01.19



こんにちは!
今回はドキュメントテキストの検出と分析ができる Amazon Textract を解説します!
想定する読者
- AWS の機械学習系サービスを知りたいヒト
- テキストの検出、分析を行いたいヒト
- Amazon Textract を使ってみたいヒト
はじめに
Amazon Textract は、スキャンされたドキュメントからテキスト、手書きの文字などを読み取ることのできる機械学習のサービスです。Amazon が培ってきた機械学習の機能が API として利用できるため、深い専門知識を要することなく、シンプルにテキストの検出や分析といった機能をアプリケーションに追加することができます。
ユースケース
- 手書きのテキストの検出
- 請求書や領収書のテキストの検出
- 財務文書、調査レポート、医療記録などからテキストと表形式のデータの抽出
上記がユースケースとなります。会計アプリなどでレシートを写真で撮影すると情報を自動入力してくれるものなどがありますが、まさにそういったことを実現したい場合に利用します。
なお Amazon Textract は現在、東京リージョンと日本語に対応しておりませんので、今後のアップデートを待つしかありません。
Amazon Textract を使ってみた
Amazon Textract は SDK を用いて利用するもののため、CloudFormation や GUI で設定することなどはありません。ちなみにマネジメントコンソールではお試しで触れるので、今回はこちらに触れながら動作を確認していきましょう。
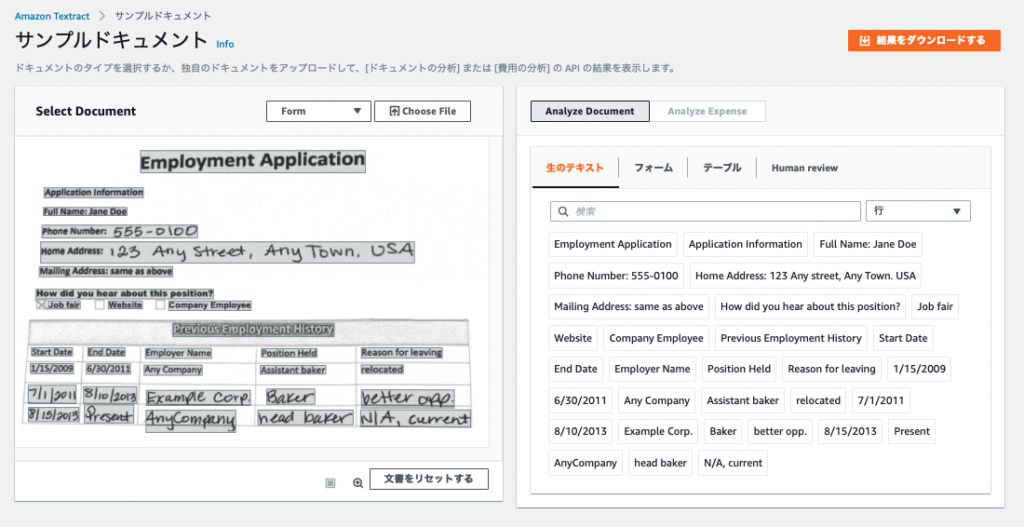
「生のテキスト」だと読み取られた単語や文章が抽出されていることがわかります。
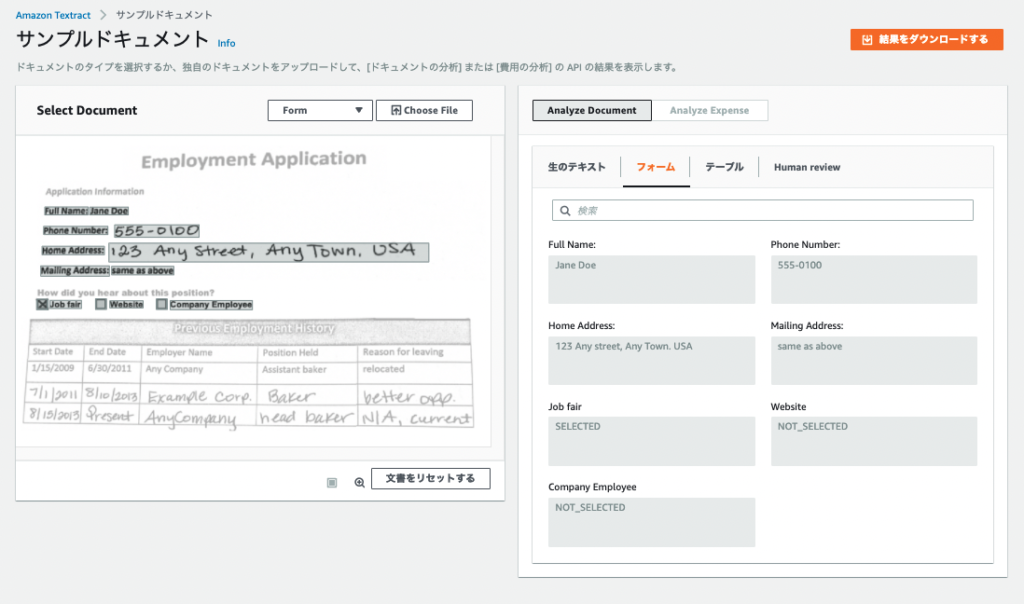
「フォーム」のところでは、さまざまな見出しにどんな情報が入っているかどうかを認識しています。
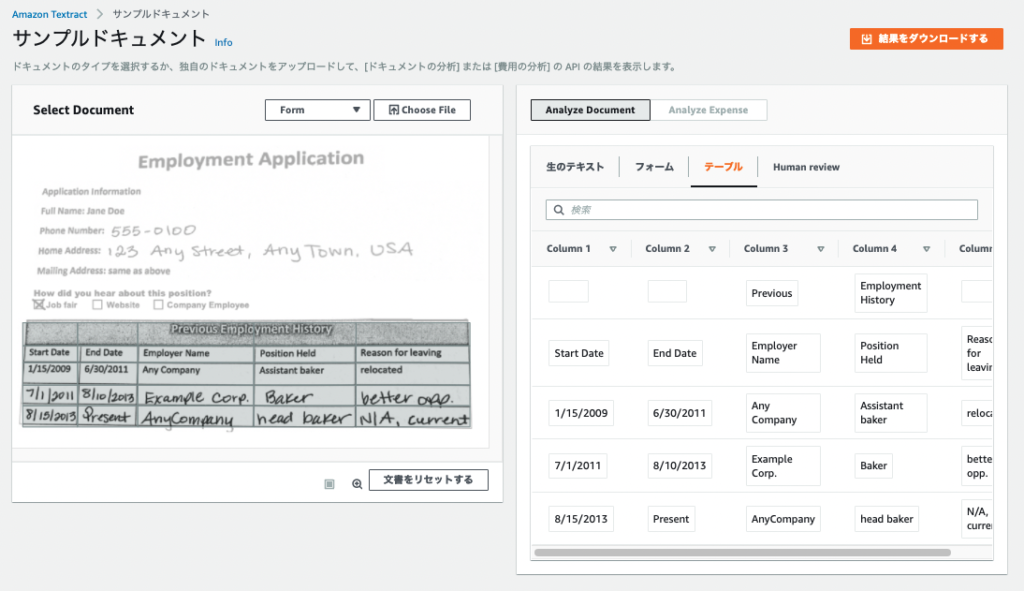
最後に「テーブル」のところでは、ドキュメントの下部にある表を読み取ってテーブル化してくれています。
以上が Amazon Textract の標準的な機能です。
Amazon Textract の実装
実装は抽出と分析によって実装方法が異なります。
例えば Python で画像からテキストを抽出する場合は以下のように記述します。
import boto3
s3BucketName = "ki-textract-demo-docs"
documentName = "simple-document-image.jpg"
textract = boto3.client('textract')
response = textract.detect_document_text(
Document={
'S3Object': {
'Bucket': s3BucketName,
'Name': documentName
}
})
print(response)レスポンスは以下のように返ってきます。
{
"DocumentMetadata": {
"Pages": 1
},
"Blocks": [
{
"BlockType": "PAGE",
"Geometry": {
"BoundingBox": {
"Width": 1,
"Height": 1,
"Left": 0,
"Top": 0
},
"Polygon": [
{
"X": 3.210373653229761e-17,
"Y": 0
},
{
"X": 1,
"Y": 4.671605344486976e-16
},
{
"X": 1,
"Y": 1
},
{
"X": 0,
"Y": 1
}
]
},
"Id": "eecb10cb-4f41-4b47-ba33-9f7d7dbcaf58",
"Relationships": [
{
"Type": "CHILD",
"Ids": [
"207fc516-c93b-458e-a1c3-d5445eba3f3c",
"a6c76b62-3be0-4dab-a121-f00303967524"
]
}
]
},
# 中略
{
"BlockType": "WORD",
"Confidence": 99.97045135498047,
"Text": "test",
"TextType": "PRINTED",
"Geometry": {
"BoundingBox": {
"Width": 0.05099273473024368,
"Height": 0.08388098329305649,
"Left": 0.43721261620521545,
"Top": 0.423963338136673
},
"Polygon": [
{
"X": 0.43721261620521545,
"Y": 0.423963338136673
},
{
"X": 0.48820534348487854,
"Y": 0.423963338136673
},
{
"X": 0.48820534348487854,
"Y": 0.5078443288803101
},
{
"X": 0.43721261620521545,
"Y": 0.5078443288803101
}
]
},
"Id": "606a404d-1a40-4979-ab0a-fbbe7e7e34dc"
},
{
"BlockType": "WORD",
"Confidence": 99.63347625732422,
"Text": "document.",
"TextType": "PRINTED",
"Geometry": {
"BoundingBox": {
"Width": 0.13917101919651031,
"Height": 0.08495254814624786,
"Left": 0.5587800741195679,
"Top": 0.4227216839790344
},
"Polygon": [
{
"X": 0.5587800741195679,
"Y": 0.4227216839790344
},
{
"X": 0.697951078414917,
"Y": 0.4227216839790344
},
{
"X": 0.697951078414917,
"Y": 0.5076742768287659
},
{
"X": 0.5587800741195679,
"Y": 0.5076742768287659
}
]
},
"Id": "9e7c25f5-ac8d-4f11-bfeb-0cabd14d2073"
},
# 中略
],
"DetectDocumentTextModelVersion": "1.0",
"ResponseMetadata": {
"RequestId": "1fe539ab-f823-456b-a552-f10620bbfcce",
"HTTPStatusCode": 200,
"HTTPHeaders": {
"x-amzn-requestid": "1fe539ab-f823-456b-a552-f10620bbfcce",
"content-type": "application/x-amz-json-1.1",
"content-length": "11775",
"date": "Sun, 12 Dec 2021 15:17:17 GMT"
},
"RetryAttempts": 0
}
}Amazon Textract には様々な API があり、上記の例だと DetectDocumentText API を実行しています。
代表的な API は以下のようなものがあります。
| AnalyzeDocument | 検出されたアイテム間の関係についてドキュメントを分析します。 |
| AnalyzeExpense | ドキュメントを同期的に分析して、テキスト間の財務的な関連を調べます。 |
| DetectDocumentText | JPEG または PNG 形式の画像のドキュメントのテキストを読み取ります。 |
そのほかにも様々な API がありますので、用途に応じて使ってみてください。
なお制約については、各 API ごとに1秒あたりのトランザクションの最大数(TPS)が決まっておりますので、使用前にドキュメントをご確認ください。
関連記事
まとめ
Amazon Textract で容易にテキストの抽出や分析が可能となります。日本語対応はまだですが、使えるようになったらとても便利なサービスなので待ち遠しいですね。機械学習系サービスの日本語対応は全体的に遅いですが、今後のアップデートに期待です。
このブログでは、AWS の記事をどんどん公開しておりますので、ご興味のある方は他の記事もご覧いただければと思います。
AWS に関する開発は、お気軽にお問い合わせください。
スモールスタート開発支援、サーバーレス・NoSQLのことなら
ラーゲイトまでご相談ください
低コスト、サーバーレスの
モダナイズ開発をご検討なら
 開発 をご希望の企業様
開発 をご希望の企業様 下請け対応可能
Sler企業様からの依頼も歓迎
協業 をご希望の企業様 



ラーゲイトは、世界の最新技術を追い続ける
プロフェッショナルチームです。





