




AWSサーバーレスのエラーキャッチ手法&メトリクス運用監視方法まとめ_CTO監修
 2023.09.06
2023.09.06



こんにちは!
本記事では、AWS サーバーレス構成におけるエラーキャッチの手法と、障害を未然に防止するメトリクスの運用監視方法をまとめます。AWS の開発プロジェクトに関わる人は必見です。
想定する読者
- AWS 開発プロジェクトに関わるヒト
- AWS の保守運用を行うヒト
- 他社の構築した AWS 環境を引き継ぐヒト
はじめに
本記事の記載の方法は銀の弾丸では有りません。アプリケーション層の実装方法と運用要件を俯瞰してプロジェクトにフィットする運用監視の方法を検討していく必要があります。例えばモノリシックな実装を行っているレガシーな構成の場合、まずシステムのログをどこで持っているのか、エラーケースはどのようなものがあるのかを把握し、CloudWatch にメトリクスやログの収集を設定していく必要があります。つまり既存の実装状況によって、まず運用監視するためのアーキテクチャーを構成しないといけないことがある、ということです。
そして本記事の前提として強く伝えたいのは、単一のコンピュートインスタンス内で、運用監視を完結させないことが重要という点です。レガシー構成で度々見られるのが、単一の EC2 や ECS 内のアプリケーション内に、ビジネスロジックの実装と一緒に運用監視のモジュールを導入しているケースです。私たちは運用監視のモジュールとアプリケーション層のビジネスロジックは可能な限り疎結合にするべきと考えます。
本記事では、AWS の運用監視の核となるサービス「CloudWatch」を用いたサーバーレスでエレガントな運用監視方法について解説します。
CloudWatchとは?

Amazon CloudWatch は、AWS リソースと、AWS で実行されているアプリケーションをリアルタイムでモニターリングします。CloudWatch のコンソールには、使用している AWS の各サービスに関するメトリクスが自動的に表示されます。さらに、カスタムダッシュボードを作成してアプリケーションのメトリクスを表示したり、選択したメトリクスのカスタムコレクションを表示したりできます。
つまり、CloudWatch により、システム全体のリソース使用率、アプリケーションパフォーマンス、およびオペレーションの状態監視が可能となります。
サーバーレス構成では、Lambda や AppSync のログ確認から、Lambda や DynamoDB のメトリクス監視などに用います。使い方が幅広く検討できますので、ぜひ運用要件が定まっているなら CloudWatch で実現できないか検討してみてください。
CloudWatchで監視する主要なメトリクス
※ 推奨 CloudWatchAlarm 条件が「-」 の項目は要件次第で検討する項目となります
Lambda
| メトリクス | 推奨 CloudWatchAlarm 条件 | 対応 |
| Errors | – | 例外の種類に応じてソースコードの修正を検討 |
| Duration | – | パフォーマンスを測定、適宜インフラ調整又は並列処理等を検討 |
| Invocations | – | スロットリングの対策と実行数を把握しコストの予測に役立てます スロットリングを疑われる場合は上限緩和申請またはワークロードの見直しを検討 |
| DeadLetterErrors | – | リソース設定ミスの可能性有、CloudFormation 及びインフラ調整検討 |
| DestinationDeliveryFailures | – | リソース設定ミスの可能性有、CloudFormation 及びインフラ調整検討 |
| Throttles | – | 上限緩和申請またはワークロードの修正検討 |
| RecursiveInvocationsDropped | – | ソースコードの実装ミスの可能性有り、ソースコードの修正を検討 |
| ConcurrentExecutions | アカウントの Lambda 同時実行数の閾値 × 80% ※ N分以内の頻度などの条件も検討してください | リージョンの同時実行クォータに近づいた場合は上限緩和申請又はワークロードの修正検討 |
| AsyncEventAge | – | Errors メトリクスを調べて関数エラーを特定し、Throttles メトリクスを見て同時実行の問題を特定し修正 |
| AsyncEventsDropped | – | Errors メトリクスを調べて関数エラーを特定し、Throttles メトリクスを見て同時実行の問題を特定し修正 |
DynamoDB
各アカウントとリージョンのメトリクス
アカウント内の AWS リージョンごとに、モニタリングする必要があるアカウントレベルのメトリクスがいくつかありますが、複数のチーム(または複数のプロダクト)が DynamoDB テーブルを同じアカウントにデプロイしている場合、当該セクション特に重要になります。
1 つのチームの変更は、たとえば、別のチームのテーブルの Auto Scaling 機能に影響を与え、アカウント管理者はアカウントの制限を引き上げるためにアクションを実行する必要がある場合があります。
| メトリクス | 推奨 CloudWatchAlarm 条件 | 説明 | 対応 |
| AccountProvisionedReadCapacityUtilization | MAX > 80% | 割り当てられたアカウント制限読み取りプロビジョニング済みキャパシティの割合 | 開発環境や本番環境などの複数環境が同居している場合はアカウント分離を検討 複数のプロダクトが同居している場合はマルチアカウント管理を検討 |
| AccountProvisionedWriteCapacityUtilization | MAX > 80% | 割り当てられたアカウント制限書き込みプロビジョニング済みキャパシティの割合 | 同上 |
| MaxProvisionedTableReadCapacityUtilization | MAX > 80% | アカウントの最も高い読み取りプロビジョニングされたテーブルによって使用される、読み取りプロビジョニングされたキャパシティの割合 | 同上 |
| MaxProvisionedTableWriteCapacityUtilization | MAX > 80% | アカウントの最も高い書き込みプロビジョニングされたテーブルで使用される、読み取りプロビジョニングされたキャパシティの割合 | 同上 |
DynamoDBAccountReadCapAlarm:
Type: 'AWS::CloudWatch::Alarm'
Properties:
AlarmName: 'DynamoDBAccountReadCapAlarm'
AlarmDescription: 'Alarm when account approaches maximum read capacity limit'
AlarmActions:
- !Ref DynamoDBMonitoringSNSTopic
Namespace: 'AWS/DynamoDB'
MetricName: 'AccountProvisionedReadCapacityUtilization'
Statistic: 'Maximum'
Threshold: 80
ComparisonOperator: 'GreaterThanThreshold'
Period: 300
EvaluationPeriods: 1各テーブルと GSI のメトリクス
継続的に重度のスロットリングが発生する場合、スキーマの設計上の問題、Auto Scaling のないテーブルの構成ミス、または Auto Scaling 制限の設定が低すぎることを示している場合があります。このような問題には、開発者の介入が必要な場合があり、また問題を解決するには AWS の設定またはアプリケーションコードを変更する必要がある場合もあります。
| メトリクス | 推奨 CloudWatchAlarm 条件 | 説明 | 対応 |
| サンプル数 ReadThrottleEvents / (サンプル数 ConsumedReadCapacityUnits) | > 2% | 持続的な読み取りスロットル | 割り当てた ReadCapacityUnits の容量またはワークロードを見直す |
| サンプルカウント書き込み ThrottleEvents / (サンプルカウント ConsumedWriteCapacityUnits) | > 2% | 持続的な書き込みスロットル | 割り当てた WriteCapacityUnits の容量またはワークロードを見直す |
| サンプルカウント SystemErrors / (サンプルカウント ConsumedReadCapacityUnits +サンプルカウント ConsumedWriteCapacityUnits) | > 2% | システムエラーの持続的かつ大幅な上昇 | 発生時点周辺のログを確認しトラブルシューティング、リソース設定ミスの可能性有、CloudFormation 及びインフラ調整検討 |
| サンプルカウント UserErrors / (サンプルカウント ConsumedReadCapacityUnits +サンプルカウント ConsumedWriteCapacityUnits) | > 2% | ユーザーエラーの持続的かつ大幅な上昇 | CloudTrail で「データイベント」を取得する証跡を作成し原因を調査(併せてCloudWatch Logs確認) |
| ConditionalCheckFailedRequests | SUM > 100 | 状態チェックエラーの持続的かつ大幅な上昇 (オプション) | Condition の内容次第でソースコードまたはワークロードの修正を検討 |
| TransactionConflict | SUM > 100 | トランザクションの競合の持続的かつ大幅な上昇 (オプション) | ソースコードの実装ミスの可能性が高いのでソースコードの修正を検討 ユニットテストで十分なテストケースを追加し動作を保証する |
DynamoDBGSIReadThrottlingAlarm:
Type: 'AWS::CloudWatch::Alarm'
Properties:
AlarmName: 'DynamoDBGSIReadThrottlingAlarm'
AlarmDescription: 'Alarm when GSI read throttle requests exceed 2% of total number of read requests'
AlarmActions:
- !Ref DynamoDBMonitoringSNSTopic
Metrics:
- Id: 'e1'
Expression: '(m1/m2) * 100'
Label: GSIReadThrottlesOverTotalReads
- Id: 'm1'
MetricStat:
Metric:
Namespace: 'AWS/DynamoDB'
MetricName: 'ReadThrottleEvents'
Dimensions:
- Name: 'TableName'
Value: !Ref DynamoDBProvisionedTableNameAmazon CloudWatch Contributor Insights for DynamoDB は、頻繁にアクセスするアイテムが持続的なスロットリングを引き起こしているかどうかを調べるのに役立ちますので運用時に利用を検討してください。
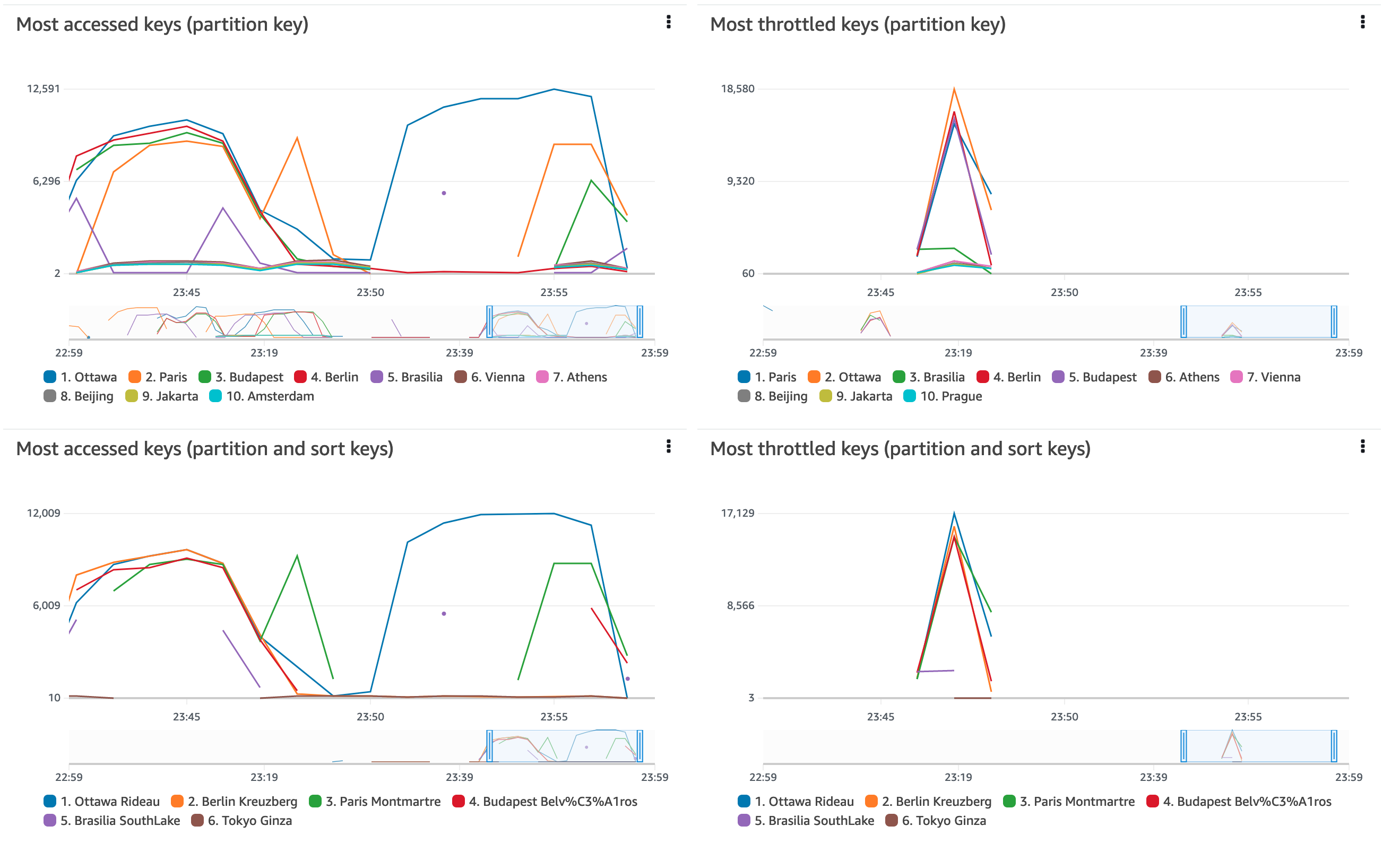
プロビジョニングされた各スループットテーブルと GSI のメトリクス
ベストプラクティスとして、ベーステーブルとすべての GSI の両方に対して、プロビジョニングされたスループット (「PROVISIONED Billing Mode」) を使用して、テーブルの Auto Scaling を有効にする必要があります。そうすることで、使用率の低い時間帯に縮小してコストを削減し、予期しない負荷ピーク時のプロビジョニング不足によるスロットルを最小限に抑えることができます。
| メトリクス | 推奨 CloudWatchAlarm 条件 | 説明 | 対応 |
| ProvisionedReadCapacityAutoScalingPct | > 90% | Auto Scaling の最大読み取り使用率 | ReadCapacityUnits の容量追加を検討 |
| ProvisionedWriteCapacityAutoScalingPct | > 90% | Auto Scaling の最大書き込み使用率 | WriteCapacityUnits の容量追加を検討 |
DynamoDBTableASReadAlarm:
Type: 'AWS::CloudWatch::Alarm'
Properties:
AlarmName: 'DynamoDBTableASReadAlarm'
AlarmDescription: 'Alarm when table auto scaling read setting approaches table AS maximum'
AlarmActions:
- !Ref DynamoDBMonitoringSNSTopic
Namespace: !Ref DynamoDBCustomNamespace
MetricName: 'ProvisionedReadCapacityAutoScalingPct'
Dimensions:
- Name: 'TableName'
Value: !Ref DynamoDBProvisionedTableName
Statistic: 'Maximum'
Unit: 'Percent'
Threshold: 90
ComparisonOperator: 'GreaterThanThreshold'
Period: 60
EvaluationPeriods: 2各オンデマンドキャパシティテーブルと GSI のメトリクス
オンデマンドキャパシティモード (PAY_PER_REQUEST Billing Mode) を使用するテーブルは、現在のキャパシティ設定を増減できないため、モニタリングする必要が少なくなります。主な懸念は、テーブルレベルの読み取りと書き込みのアカウントの上限に近づいているかどうかです。
| メトリクス | 推奨 CloudWatchAlarm 条件 | 説明 | 対応 |
| SUM ConsumedReadCapacityUnits / MAXIMUM AccountMaxTableLevelReads | > 90% | テーブル制限の割合としての読み取り消費 | 過去のキャパシティユニット消費量から需要を予測しPROVISIONED Billing Mode の使用を検討 |
| SUM ConsumedWriteCapacityUnits / MAXIMUM AccountMaxTableLevelWrites | > 90% | テーブル制限の割合としての書き込み消費 | 過去のキャパシティユニット消費量から需要を予測しPROVISIONED Billing Mode の使用を検討 |
DynamoDBOnDemandTableWriteLimitAlarm:
Type: 'AWS::CloudWatch::Alarm'
Properties:
AlarmName: 'DynamoDBOnDemandTableWriteLimitAlarm'
AlarmDescription: 'Alarm when consumed table reads approach the account limit'
AlarmActions:
- !Ref DynamoDBMonitoringSNSTopic
Metrics:
- Id: 'e1'
Expression: '(((m1 / 300) / m2) * 100)'
Label: TableWritesOverMaxWriteLimit
- Id: 'm1'
MetricStat:
Metric:
Namespace: 'AWS/DynamoDB'
MetricName: 'ConsumedWriteCapacityUnits'
Dimensions:
- Name: 'TableName'
Value: !Ref DynamoDBOnDemandTableName
Period: 300
Stat: 'SampleCount'
Unit: 'Count'
ReturnData: False
- Id: 'm2'
MetricStat:
Metric:
Namespace: 'AWS/DynamoDB'
MetricName: 'AccountMaxTableLevelWrites'
Period: 300
Stat: 'Maximum'
ReturnData: False
EvaluationPeriods: 2
Threshold: 90
ComparisonOperator: 'GreaterThanThreshold'DynamoDB グローバルテーブルのモニタリング
※ オンデマンドスループットを使用するテーブルでは、この当該セクションを考慮する必要はありません
DynamoDB グローバルテーブルは、完全マネージド型のマルチマスター形式で、異なるリージョンのテーブル間でデータをレプリケートします。
プロビジョニングされたスループットを使用するグローバルテーブルでは、すべてのテーブルレプリカにわたって同じ WCU 設定をプロビジョニングする必要があります。そうしないと、あるリージョンのレプリカが別のリージョンからの変更のレプリケートに遅れることがあります。これにより、レプリカが他のレプリカから分岐する可能性があります。テーブルで Auto Scaling を使用する場合、すべてのレプリカテーブルで同じ Auto Scaling 設定を使用することが推奨されます。
| メトリクス | 推奨 CloudWatchAlarm 条件 | 説明 | 対応 |
| ReplicationLatency | 平均 > 180,000 ミリ秒 (3 分) | 2 つのリージョン間のレプリケーションレイテンシーの上昇 | プロビジョンされたモードを使用するレプリカテーブルに適用する すべてのレプリカテーブルで同じ Auto Scaling 設定を使用する |
DynamoDBGTReplLatencyAlarm:
Type: 'AWS::CloudWatch::Alarm'
Properties:
AlarmName: 'DynamoDBGTReplLatencyAlarm'
AlarmDescription: 'Alarm when global table replication latency exceeds 3 minutes (180k ms)'
AlarmActions:
- !Ref DynamoDBMonitoringSNSTopic
Namespace: 'AWS/DynamoDB'
MetricName: 'ReplicationLatency'
Dimensions:
- Name: 'TableName'
Value: !Ref DynamoDBGlobalTableName
- Name: 'ReceivingRegion'
Value: !Ref DynamoDBGlobalTableReceivingRegion
Statistic: 'Average'
Threshold: 180000
ComparisonOperator: 'GreaterThanThreshold'
Period: 60
EvaluationPeriods: 15DynamoDB Streams Lambda
DynamoDB テーブルの変更によってトリガーされる AWS Lambda 関数を作成する場合、オブジェクトが Lambda 関数によって処理されずに DynamoDB Streams 上に長時間滞在している場合にアラートを生成する必要があります。これは、Lambda 関数に欠陥がある (未処理の例外など) か、イベントを十分に速く処理できないためにキューが深くなる Lambda 関数の証拠である可能性があります。
| メトリクス | 推奨 CloudWatchAlarm 条件 | 説明 | 対応 |
| IteratorAge | 30,000 ミリ秒 (30 秒) | DynamoDB Streams イベントの経過時間の上昇 | Lambda 関数の処理内容を確認し実行時間が長い場合はSQSへのメッセージ送信を検討 |
DynamoStreamLambdaIteratorAgeAlarm:
Type: 'AWS::CloudWatch::Alarm'
Properties:
AlarmName: 'DynamoStreamLambdaIteratorAgeAlarm'
AlarmDescription: 'Alarm when lambda iterator age exceeds 30 seconds (30k ms)'
AlarmActions:
- !Ref DynamoDBMonitoringSNSTopic
Namespace: 'AWS/Lambda'
MetricName: 'IteratorAge'
Dimensions:
- Name: 'Function'
Value: !Ref DynamoDBStreamLambdaFunctionName
- Name: 'Resource'
Value: !Ref DynamoDBStreamLambdaFunctionName
Statistic: 'Average'
Threshold: 30000
ComparisonOperator: 'GreaterThanThreshold'
Period: 60
EvaluationPeriods: 2Lambdaのアプリケーションエラーの検出とその対応

Lambda 関数におけるエラー検知方法は、@aws-lambda-powertools/loggerを使用して出力した CloudWatch ログを、サブスクリプションフィルターしエラー検知を実現します。検知後は、SNS へメッセージを作成し、SNS の各サブスクライバーが必要に応じて通知処理を行います。
ServerlessFramework を使用した具体的な実装方法は以下になります。
# functions.yml
CreateUser:
handler: 'src/functions/events/appsync/createUser.handler'
name: 'CreateUser'
CloudWatchLogsErrorNotify:
handler: 'src/functions/events/cloudwatch/cloudWatchLogsErrorNotify.handler'
name: '${self:custom.awsResourcePrefix}CloudWatchLogsErrorNotify'# SubscriptionFilter
CreateUserErrorNotifySubscriptionFilter:
Type: 'AWS::Logs::SubscriptionFilter'
Properties:
DestinationArn: !GetAtt CloudWatchLogsErrorNotifyLambdaFunction.Arn
FilterPattern: '{$.level = "ERROR"}'
LogGroupName: '/aws/lambda/CreateUser'
CreateUserLambdaPermission:
Type: 'AWS::Lambda::Permission'
Properties:
FunctionName: !Ref CloudWatchLogsErrorNotifyLambdaFunction
Action: lambda:InvokeFunction
Principal: logs.amazonaws.com
SourceArn: !Sub 'arn:aws:logs:${self:provider.region}:${AWS::AccountId}:log-group:/aws/lambda/CreateUser:*'# cloudWatchLogsErrorNotify.handler (typescript)
import zlib from 'zlib';
import { CloudWatchLogsEvent, Context } from 'aws-lambda';
import middy from '@middy/core';
import { injectLambdaContext } from '@aws-lambda-powertools/logger';
import errorCatch from 'middlewares/middy/errorCatch';
import snsService from 'services/snsService'
const {
ERROR_NOTIFY_SNS_TOPIC_ARN, // インシデント通知先のSNSをトピックを設定
LOG_LEVEL,
SERVICE
} = process.env;
const logger = new Logger({
logLevel: (LOG_LEVEL as LogLevel) || 'INFO',
serviceName: SERVICE as string,
});
export const handler = middy().use(injectLambdaContext(logger)).use(errorCatch()).handler(async (event: CloudWatchLogsEvent, context: Context) => {
const payload = Buffer.from(event.awslogs.data, 'base64');
return new Promise((resolve, reject) => {
zlib.gunzip(payload, (err: Error, result: Buffer) => {
if (err) {
// ログのテキスト情報のデコードに失敗
return reject(context.fail(err));
}
// エラーログ出力
const json = JSON.stringify(JSON.parse(result.toString('utf-8')), null, '\t');
const params = {
Message: json,
TopicArn: ERROR_NOTIFY_SNS_TOPIC_ARN,
};
try {
const data = new snsService().publish(params).promise();
logger.info(`Message ${params.Message} sent to the topic ${params.TopicArn}`);
logger.info('MessageID is ' + data.MessageId);
} catch(e) {
logger.error(err);
reject(err);
}
});
});
});まとめ
本記事では、わたしたちがサーバーレスを運用する上で欠かせない各メトリクスから、Lambda のエラー検出方法をまとめました。これから新規でサーバーレス開発に取り組むヒトはもちろんのこと、サーバーレスの開発プロジェクトを引き継ぐ必要があるヒトは、本記事を参考にまずは CloudWatch による自動的な運用監視のアーキテクチャーを検討してみてください。
スモールスタート開発支援、サーバーレス・NoSQLのことなら
ラーゲイトまでご相談ください
低コスト、サーバーレスの
モダナイズ開発をご検討なら
 開発 をご希望の企業様
開発 をご希望の企業様 下請け対応可能
Sler企業様からの依頼も歓迎
協業 をご希望の企業様 



ラーゲイトは、世界の最新技術を追い続ける
プロフェッショナルチームです。





