




ChatGPTの最速モデル「GPT-4o」が登場!その概要と特徴、ユースケースをまとめ
 2024.05.14
2024.05.14



こんにちは!OpenAIから待望の新モデル「GPT-4o」がリリースされました。今回は、このGPT-4oの概要や特徴、想定されるユースケースについてご紹介します。
はじめに
GPT-4oは、OpenAIが開発したマルチモーダルAIモデルで、テキスト、音声、画像をリアルタイムで処理できるのが特徴です。「o」は「omni(全て)」を意味し、あらゆる入力形式を受け付け、柔軟な出力が可能になっています。
GPT-4oの主な特徴は以下の通りです。
- 人間に近い応答速度(平均320ミリ秒)
- 英語と非英語のテキストおよびコードにおいてGPT-4 Turboと同等以上の性能
- APIの料金はGPT-4の半額で、処理速度は2倍
- ビジョンと音声理解が大幅に向上
公式アナウンスはこちらです。ぜひご一読ください。 https://openai.com/blog/gpt-4o
GPT-4oのケイパビリティ
エンドツーエンドのマルチモーダル統合モデル
GPT-4o最大の特徴は、テキスト・ビジョン・オーディオを単一のニューラルネットワークでエンドツーエンドに処理する点です。これまでのChatGPTのVoice Modeは、音声認識、GPT、音声合成の3つのモデルをパイプラインで繋げていました。一方、GPT-4oは音声の抑揚や背景ノイズも直接観測でき、笑い声や歌声も出力できます。
優れた性能と言語性能の向上
GPT-4oは、英語と非英語のテキスト、プログラミングコードの理解において、GPT-4 Turboと同等以上の性能を発揮します。特に、GPT-3.5と比較して、テルグ語で3.5倍、タミル語で3.3倍、マラーティー語で2.9倍のトークン圧縮率を達成しています。また、一般知識に関する質問応答「MMLU」でも88.7%の高スコアを記録しました。

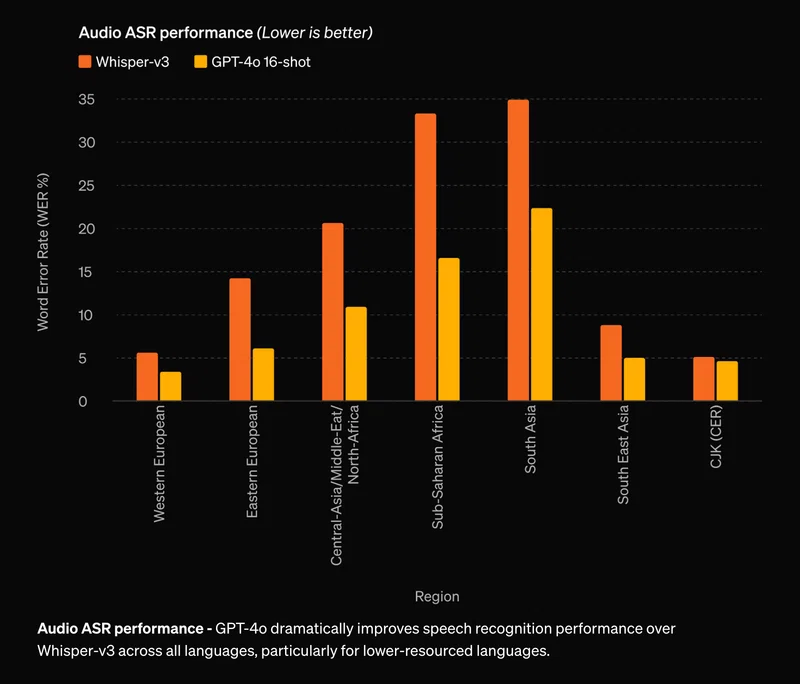
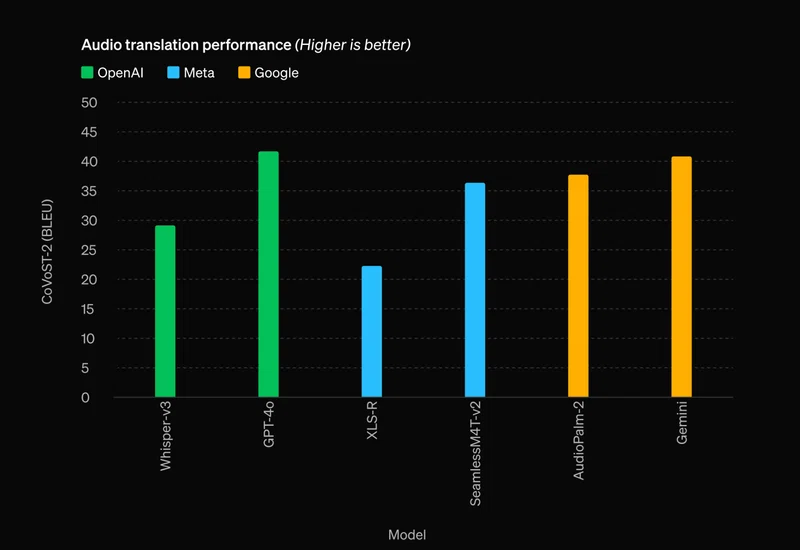
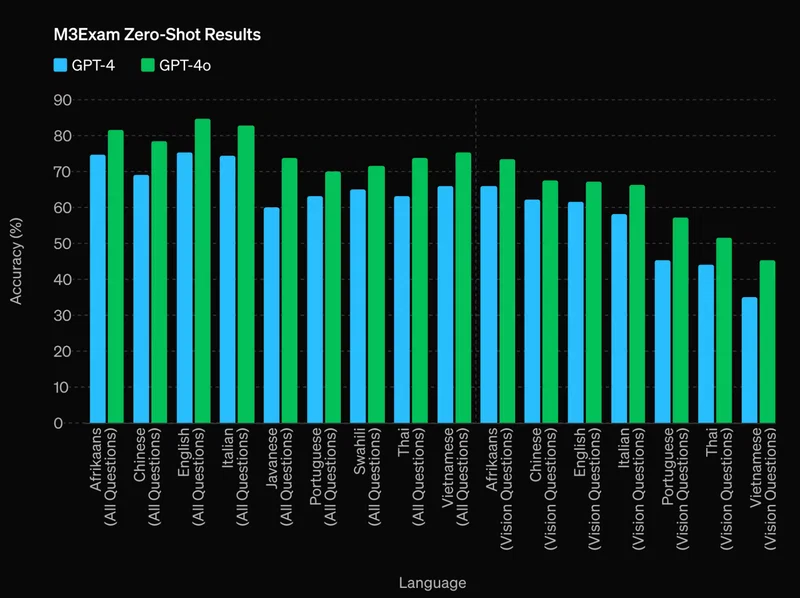
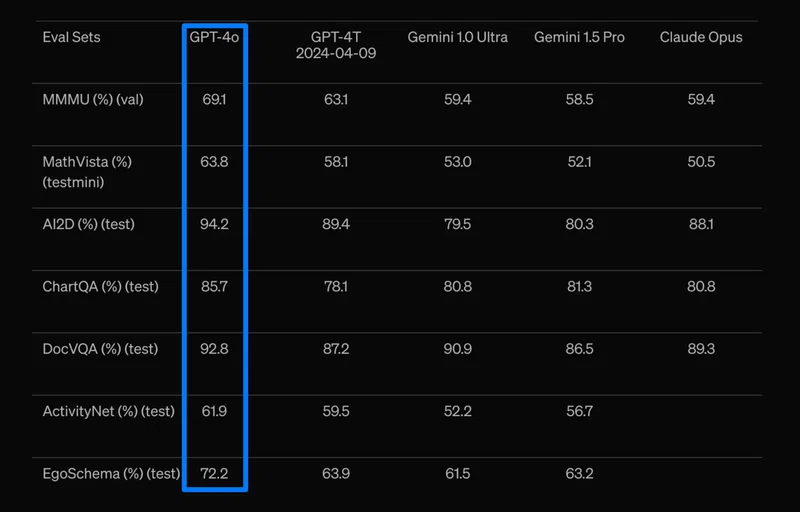
組み込みの安全性
GPT-4oには、学習データのフィルタリングや事後学習による安全性システムが組み込まれています。サイバーセキュリティ、CBRN、説得、モデルの自律性などのリスク評価も実施されています。ただし、GPT-4oにはまだ様々な制約があることも認識しておく必要があります。
想定されるユースケース
自然な対話インターフェース
GPT-4oは、これまでにない自然な対話インターフェースを実現できます。音声だけでなく、表情や身振り手振りも組み合わせたマルチモーダルな対話が可能になるでしょう。カスタマーサポートやバーチャルアシスタントなど、人間とのインタラクションが求められる場面での活用が期待されます。
マルチリンガルアプリケーション
GPT-4oの多言語対応力は非常に高く、ローカライズの手間を大幅に削減できます。英語以外の言語でのチャットボットやコンテンツ生成など、グローバル展開を見据えたアプリケーション開発に役立つでしょう。
知的な画像/動画解析
GPT-4oは、画像や動画の理解力も飛躍的に向上しています。物体検出や行動認識だけでなく、コンテキストを踏まえた高度な解釈が可能になります。医療診断の支援や、監視カメラの異常検知など、様々な分野での活用が見込まれます。
TIPS
GPT-4oとファインチューニングは強力
特定のドメインや業務に特化させるために、GPT-4oを追加学習させることをおすすめします。少量の学習データでも、GPT-4oのパフォーマンスを大きく向上できる可能性があります。
プロンプトエンジニアリング
GPT-4oを効果的に活用するには、適切な指示(プロンプト)を与えることが重要です。タスクに合わせて、明確かつ具体的なプロンプトを設計しましょう。うまくいったプロンプトは積極的に共有し、ベストプラクティスを蓄積していくことが大切です。
他のAIモデルとの組み合わせ
GPT-4oと、Stable DiffusionやDALL-E等の画像生成AIを組み合わせることで、テキストから画像への変換や、画像からのストーリー生成など、より表現力豊かなアプリケーションを開発できるでしょう。
無料ユーザー向けの制限
無料ユーザーは上記の機能にアクセスできますが、以下の制限があります:
- 画像生成:無料ユーザーは画像生成機能にアクセス不可
- メッセージ制限:無料ユーザーには、利用制限があり、制限に達した場合はGPT-3.5に自動的に切替
- GPTsの作成:無料ユーザーはGPTsを使用できますが、新しいGPTsを作成することは出来ない
倫理的な配慮
GPT-4oの能力の高さゆえに、倫理的な配慮がより重要になります。プライバシーの保護やバイアスの排除など、responsible AIの原則に基づいた開発が求められます。
まとめ
OpenAIの新モデル「GPT-4o」は、マルチモーダルAIの新たな可能性を切り開くものです。以下のような特徴と想定されるユースケースを見てきました。
- エンドツーエンドのマルチモーダル統合により、自然な対話インターフェースを実現
- 多言語対応力の高さから、グローバル展開に適したアプリケーション開発が可能
- 画像や動画の高度な理解力を活かした、知的な解析ツールへの応用
- 創造性を発揮するジェネレーティブAIとして、様々なコンテンツ生成シーンで活躍
GPT-4oは、開発者にとって強力な武器になるはずです。ファインチューニングやプロンプトエンジニアリングなどの工夫を凝らしながら、GPT-4oの力を最大限に引き出していきたいですね。 同時に、倫理的な配慮を忘れずに、社会に受け入れられるAIアプリケーション開発を心がけることが大切だと思います。
皆さんも、GPT-4oの登場で、AIがもたらす新しい可能性にワクワクしているのではないでしょうか。私たちも、GPT-4oを使った様々な実験に早速取り組んでみたいと思います。
スモールスタート開発支援、サーバーレス・NoSQLのことなら
ラーゲイトまでご相談ください
低コスト、サーバーレスの
モダナイズ開発をご検討なら
 開発 をご希望の企業様
開発 をご希望の企業様 下請け対応可能
Sler企業様からの依頼も歓迎
協業 をご希望の企業様 



ラーゲイトは、世界の最新技術を追い続ける
プロフェッショナルチームです。





