




RDB設計者のための DynamoDB の解説!開発経験者が語る DynamoDB 設計入門🤔
 2020.05.19
2020.05.19



こんにちは!
様々な DBMS を組み合わせてアプリ開発を行う今時のアプリ開発では、DynamoDB という選択肢に魅力を感じやすいと思います。
DynamoDB は設計次第でサービススケール後も低レイテンシーを維持し、サーバーレスの側面による高い可用性を実現してくれます。
本記事では、DynamoDB 設計、プロジェクト導入などについて共有します。
想定する読者
- RDBMS の実務経験はあるけど、NoSQL の経験はない人
- MySQL の設計をしたことがある人
- これから DynamoDB を使った開発に挑戦したい人
はじめに
DynamoDB のユースケース
DynamoDB は設計次第で非常に高速なデータアクセスを実現可能です。その利点を活かした下記のようなケースで多く採用例があります。
- CtoC / BtoB の Web やスマフォアプリのデータベース
- 既存の RDBMS と組み合わせたハイブリッド DB構成( 高速なのを生かしたセッションストレージ利用等 )
- ゲームなど水平スケール( カラム増減が激しいプロダクト開発 )
採用を慎重にしたい良いケース
逆に、DynamoDB の IAM でアクセス制限 & ドキュメント型でのデータ保持 & パーティションによるデータ保持の特性を考えると、下記ケースでは採用を慎重にした方が良いでしょう。
- インフラが AWS ではないケース
- リレーションを重要としデータ整合性保証をしなければならないケース
- 強い整合性を持った読み込みを常に必要とされるケース( 読み込み時に書き込みされていることを常に保証しなければいけないケース )
また、私たちが最も採用を推奨したいのはスタートアップの開発です。
リーンスタートアップなどでデータ構造がバシバシ変わるようなプロダクトケースに、DynamoDB は最適です。
DynamoDB と RDBMS の比較
| RDBMS | DynamoDB |
| 正規化 / リレーショナル | 非正規化 / 階層化 |
| SQLを使用可能なので検索が柔軟 | データアクセス設計が必要 |
| データの堅牢性・一貫性 | 高速なパフォーマンス |
| スケールアウトの煩雑さ | 高スケーラビリティ |
DynamoDBで完全な探索要件の構築を目指さないでください
DynamoDBはKVSです。水平軸の検索要件はElasticSearchを使用しましょう。
最も重要なことは、一つのデータベースで全ての機能の実現を目指さないこと
アプリケーションの DB 開発において、様々なワークロードに対応したデータベース構築を目指した場合、どうしても DynamoDB だけ、MySQL だけで対応できないことがしばしば有ります。
例えば、オンデマンド動画視聴サービスの視聴ログを Read 集計する要件には縦軸集計に強いグラフ型の RedShift などを採用し、顧客の投稿情報に対する複雑なテキスト検索には ElasticSearch を検討します。
私たちは、多くのアプリケーション開発で DynamoDB を採用してきたメリットを下記のように感じています。
- 設計次第でスループットを効率的に利用・低レイテンシーを実現可能
- 多いレコード量でもインデックス調整で低レイテンシーを維持可能
- 高い可用性を AWS が自動的にサポートするので、運用が楽
- 初期コストが安価で新規事業に最適
多様なデータベースをユースケースで上手に使い分けることが現代のアプリ開発では非常に重要です。
DynamoDB の強み・弱みを理解いただき、今後のアプリ開発に役立てていただけると幸いです。
DynamoDBのデータベースの構造

※上の表では1つのマイナンバー(国民)がN個の情報を持てるようにしています(SK のオーバーローディング設計手法を想定)
DynamoDB は、パーティションキーによる完全一致、もしくはパーティションキー&ソートキーの組み合わせから検索クエリーを発行し、Item(レコード)を取得します。
この点は RDBMS の複合プライマリーキーと似ていますが、DynamoDB は、パーティションキーによる完全一致と、パーティションキーとソートキーの組み合わせでしか効率良い絞り込みが行えません。( 効率よくデータアクセス可能なキー設計を行えば、プロダクトがスケールしても低レイテンシーを維持可能 )
キー以外の属性でも絞り込みは可能ですが、一度スキャンして絞り込みをする性質上、キー属性で探索範囲を絞り込まないと結果 DynamoDB 全体をスキャンすることになります。
DynamoDB は集計に弱い
DynamoDB は、レコード集計に強くありません。フルスキャンして集計かければ実現できなくはないですが、リードキャパシティユニットを大きく消費する可能性があるので注意しましょう。
基本的に集計を行う時は、グラフ型の DBMS の採用を検討してください。
DynamoDB の設計 = パーティションキー / ソートキーの設計
DynamoDB の設計では、パーティションキーとソートキーの設計が非常に重要です。
確実に理解しましょう。
パーティションキー
DynamoDB は、テーブルの Item をパーティションと呼ばれる領域に保持します。Item がどのパーティションへ配置されるかはパーティションキーによって決定されます。
DynamoDB は、テーブルで一意となっているパーティションキーに対しハッシュ関数を実行し、ハッシュ文字列を生成します。そのハッシュ文字列で Item を格納するパーティションを決定します。( 裏側で自動的に行われています )
パーティションキーに対し、ハッシュ関数を実行し生成されたハッシュ文字でどのパーティションへ配置するかを決定します。
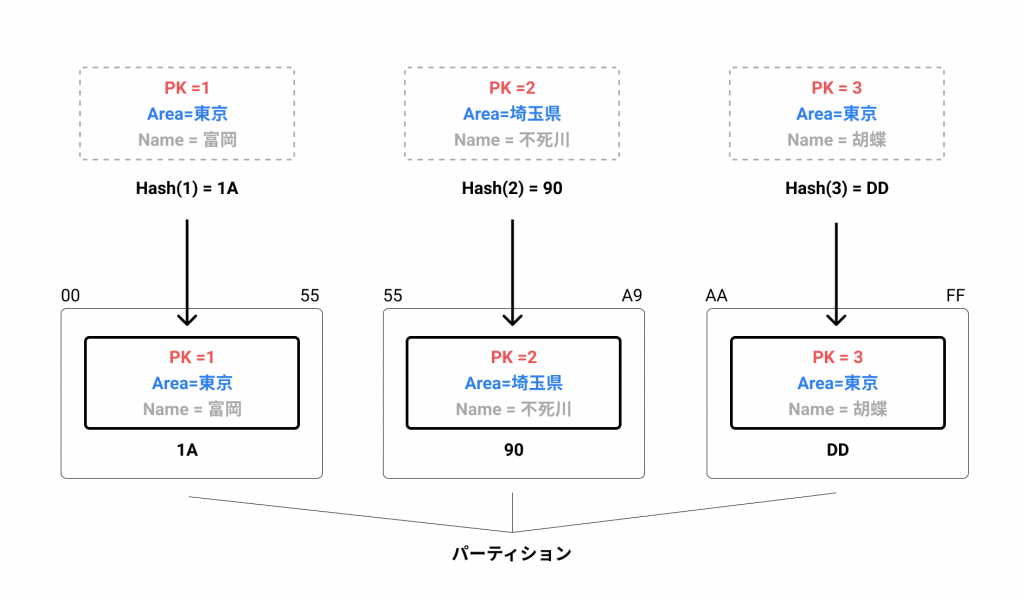
もし特定のパーティションキーにアクセスを集中してしまうと、負荷が特定のパーティションに集中してしまい、パフォーマンスが低下します。
あるアプリケーションで新商品をリリースした際に、アクセスがその商品に集中するとします。すると、一つのパーティションにのみアクセスが集中し、効率よくスループットできません。
DynamoDB では、特定のパーティションにデータアクセスが集中するような設計は好ましくありません。( これをホットパーティションと呼びます )
パーティション内部の Item は 3 つにレプリケーションされます
また、パーティション内のデータは裏側で自動的に3つのアベイラビリティゾーンへ、レプリケーションされます。これによって高い可用性が実現されています。
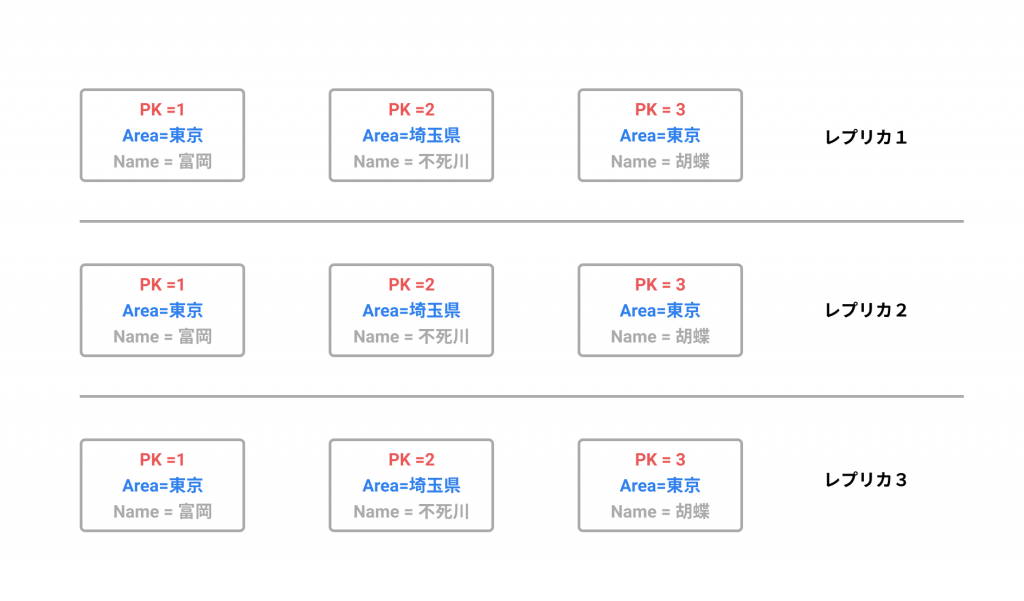
この自動的なレプリケーションのリスクとして、書き込みの際にデータを3つに複製する関係で、読み込みの際に多少のタイムラグを発生させます。
例えば、埼玉県の不死川さんの Area を東京に変更し、その直後3デバイスから読み込みを行ないました。
2台は更新後の東京という値を取得できましたが、1台は更新前の埼玉県を取得してしまったといった状況です。
または、Item 更新に条件が指定が可能なので、特定の属性値が false だったら Item を更新できないようにするなど、工夫して設計しましょう。
ソートキー
RDBMS でいうところの複合キーと似ていますが、異なるのは、DynamoDB はソートキーに指定した順序でデータを格納するということです。
ここではわかりやすく、Order という属性情報をソートキーとしています。
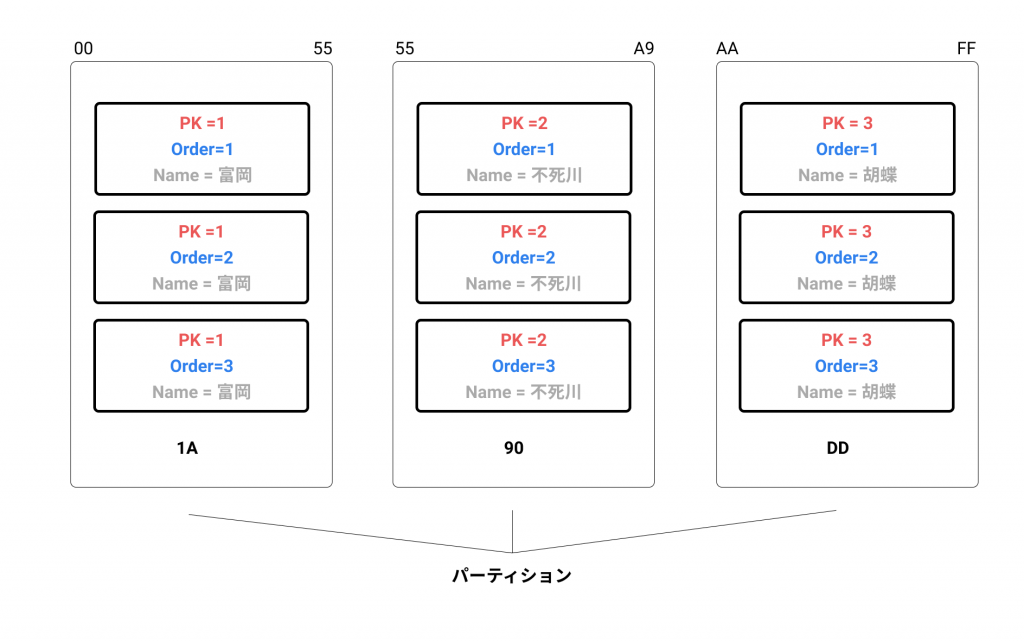
パーティションキーが重複していますが、ソートキーと複合キーになっているのでデータはコンフリクトしません。デフォルトは、ソートキーで昇順にデータは格納されています。
ソートキーに指定した属性情報は、範囲指定などのクエリーが実行可能となりますが、逆に言うとこのままだとソートキー以外で絞り込みや検索を行えません。
厳密にはフルスキャンという方法を用いて、テーブル全体をスキャンする方法もありますが、この方法はインデックスを用いていないのでクエリーが非効率で、レコード量が増えると高レイテンシー を生みます。
では、パーティションキーはそのままにソートキー以外の属性情報を絞り込みで使用したい場合はどのように対応するのでしょうか。そういったケースでは、ローカルセカンダリーインデックスを使用します。
対して、パーティションキー自体を変更して検索を行いたい場合は、グローバルセカンダリーインデックスを使用します。
※訂正とお詫び:GSI(グローバルセカンダリーインデックス)でも同一パーティションキーでソートキーを指定することが可能です。基本的には制約の多い LSI(ローカルセカンダリーインデックス)ではなく、GSI を使用してインデックスを貼り付けるようにしましょう。
セカンダリーインデックス
DynamoDB では、パーティションキーとソートキーに加えて、 ローカルセカンダリーインデックス( LSI )と グローバルセカンダリーインデックス( GSI )といったキー情報を持つことが可能です。
ローカルセカンダリーインデックス(LSI)
- ソートキー以外で絞り込みを行うキーを持つことが可能
- パーティションキーが同一で属性情報を用いて検索を行いたい場合に利用
SNS の友達リストの例を見てみます。
| User(PK) | Friend(SK) | つながり |
| 竈門 | 我妻 | 鬼狩り |
| 竈門 | 富岡 | 鬼狩り |
| 竈門 | 鱗滝 | 師弟 |
竈門くんの友達は問題なく検索できますね。しかし、このままだと竈門くんと鬼狩りつながりの人を検索できません。
こういったケースでは、パーティションキーをそのままに LSI で絞り込みを行います。
| User(PK) | つながり(SK) | Friend |
| 竈門 | 鬼狩り | 我妻 |
| 竈門 | 鬼狩り | 富岡 |
| 竈門 | 師弟 | 鱗滝 |
これで竈門くんと鬼狩りでつながった人を絞り込み可能です。
グローバルセカンダリーインデックス(GSI)
先程の例で、つながりから検索したい場合はどうすればいいでしょうか。
例えば、鬼狩りでつながっている人を検索したい時です。
お察しかと思いますが、パーティションキーをスイッチしないといけません。こういったケースでは、GSI は有効です。
GSI を利用すれば、新たに別テーブルを定義せずにこのような構造を表現することが可能です。
| つながり(PK) | User(SK) | Friend |
| 鬼狩り | 竈門 | 我妻 |
| 鬼狩り | 竈門 | 富岡 |
| 師弟 | 富岡 | 鱗滝 |
| 師弟 | 竈門 | 鱗滝 |
これで、鬼狩りでつながった人を抽出可能です。つまり GSI では、パーティション自体をスイッチすることが可能です。
要するに、DynamoDB の設計 = キー設計
DynamoDB の設計では、データアクセスに対して適切なキー設計を行うことが非常に重要となります。( DynamoDB というより NoSQL 全般にそういえます )
データ構造だけ定義しクエリーを柔軟に発行できた RDBMS と違い、DynamoDB はクエリーが柔軟ではありません。( その代わり NoSQL ならではの低レイテンシーを実現可能 )
RDBMS設計の思考との大きな違いは、検索クエリーが柔軟ではないということです。
そのため、設計段階で各種データへどのようなアクセスがされるかをきちんと考える必要があります。
RDBMS に置き換えていうところ、ORDER BY, WHERE 部分を事前にデータベースレベルで設計する必要という事です。( RDBMS のときはプログラム側でよし何やれましたが、DynamoDB ではスキャンが走ってしまうので非推奨 )
SELECT * FROM users ORDER BY age ASC|DESC;
SELECT * FROM users WHERE name='Tanaka';まとめ
今回は DynamoDB を使用するにあたり、抑えなければいけない知識を紹介しました。
次回は、実際に設計するにあたりどのような設計手法、設計テクニックを紹介したいと思います。
サーバーレス開発については、お気軽にお問い合わせください。
スモールスタート開発支援、サーバーレス・NoSQLのことなら
ラーゲイトまでご相談ください
低コスト、サーバーレスの
モダナイズ開発をご検討なら
 開発 をご希望の企業様
開発 をご希望の企業様 下請け対応可能
Sler企業様からの依頼も歓迎
協業 をご希望の企業様 



ラーゲイトは、世界の最新技術を追い続ける
プロフェッショナルチームです。





