



Amazon S3のアーキテクチャと最新機能を徹底解説! 高速アクセス、低コスト、そして安心のデータ保護を実現😎
 2024.06.24
2024.06.24



みなさん、こんにちは! 今回は、AWSの基盤を支える重要なコンポーネントであるAmazon S3について深掘りしていきます。
S3はオブジェクトストレージサービスとして、単純なAPIを介してデータを保存・取得できます。
一見シンプルに見えますが、裏側では様々な工夫が凝らされ、膨大な量のデータを効率的に管理しています。
本記事では、Amazon S3のアーキテクチャについて、現役エンジニアが分かりやすく解説します。
フロントエンド、インデックス、ストレージ層といったS3の裏側の仕組みを理解することで、S3をより効果的に活用できるようになるでしょう。
さらに、最新のストレージクラスであるAmazon S3 Express One Zoneについても触れていきます。
S3を深く理解したいエンジニア必見の内容です!
Amazon S3の3つの歩み

Amazon S3は、サービス開始から18年間、進化を続けてきました。
当初はギガバイトクラスのストレージでしたが、現在ではエクサバイト規模のデータを管理しています。
この進化の過程で、Amazon S3チームは大きく分けて3つの段階を経てきました。
| リアクティブ | 初期のS3チームは、トラブルやパフォーマンス問題が発生してから対応する、リアクティブな働き方をしていました。 これは、サービスの規模がまだ小さかったため、問題が発生してから対応しても大きな影響はなかったためです。 |
| 教訓モデリング | 利用者が増加し、データ量がギガバイトからテラバイト、ペタバイト、そしてエクサバイトへと爆発的に増加するにつれて、リアクティブな対応では限界がくるようになりました。 そこで、S3チームは過去のトラブルや障害の経験をドキュメント化し、共有することで、同様の問題が発生するリスクを軽減する取り組みを始めました。 この段階では、過去の教訓をモデリングし、サービスの改善に反映させていくことが重要視されました。 |
| プロアクティブ | 現在では、S3チームはさらに進化し、プロアクティブな働き方へと移行しています。 これは、将来発生する可能性のあるトラブルや障害を予測し、事前に対策を講じるというものです。 具体的には、データの増加やアクセスパターンの変化などを分析し、将来的なボトルネックを予測することで、サービスの安定稼働を実現しています。 |
Amazon S3のアーキテクチャを深掘り! フロントエンド・インデックス・ストレージ層

Amazon S3は、クライアントから見ると、APIを通してデータを操作するだけのシンプルなサービスに見えます。
しかし、その裏側には、高度なアーキテクチャが隠されています。
主な構成要素としては、フロントエンド、インデックス、ストレージ層の3つがあります。
| コンポーネント | 説明 |
|---|---|
| フロントエンド | Webサーバー、DNS、ネットワークなど、クライアントからのリクエストを処理する部分。負荷分散を行い、大量のリクエストを効率的に処理します。 |
| インデックス | ストレージ層へのKey-Valueマップ。どのデータがどこに配置されているかを管理する、いわば巨大なデータベースのようなものです。 |
| ストレージ層 | すべてのデータの永続化を担う部分。大量のデータを安全に保管するために、冗長性やデータ整合性などの仕組みが実装されています。 |
これらの要素が連携することで、Amazon S3は高いパフォーマンスと信頼性を実現しています。
フロントエンドの負荷分散
Amazon S3のフロントエンドは、大量のリクエストを処理するために負荷分散を行っています。
ピーク時のトラフィックは1ペタバイト/秒を超えるため、複数のWebサーバーに負荷を分散することで、安定したパフォーマンスを提供しています。
具体的には、マルチパートアップロードやレンジGET、複数のIPアドレスへのリクエスト分散といった仕組みが用いられています。
インデックスの役割
インデックスは、ストレージ層に保存されているオブジェクトのメタデータを管理しています。
クライアントからリクエストが来ると、フロントエンドはインデックスを参照して、必要なオブジェクトがどのストレージサーバーに保存されているかを特定します。
インデックスは、高速なデータアクセスを実現するために、Key-Valueストアとして実装されています。
ストレージ層の冗長性とデータ整合性
ストレージ層は、複数のAvailability Zone (AZ)にデータを分散して保存することで、高い冗長性を実現しています。
これにより、1つのAZに障害が発生した場合でも、他のAZからデータにアクセスすることができ、サービスの継続性を確保しています。
また、ストレージ層では、データの整合性を確保するために、チェックサムやイレージャーコーディングといった技術が用いられています。
チェックサムは、データの破損を検出するために、データの内容に基づいて計算される値です。
イレージャーコーディングは、複数のストレージデバイスにデータを分散して保存することで、一部のデバイスに障害が発生した場合でも、データを復元できるようにする技術です。
最新のストレージクラス Amazon S3 Express One Zone
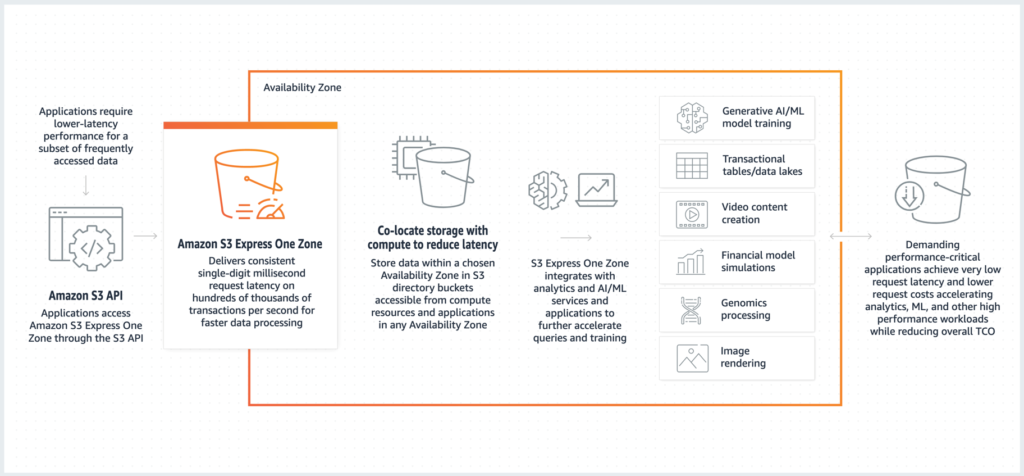
Amazon S3は、用途やアクセス頻度に応じて最適なストレージクラスを選択できます。
近年では、高速なデータアクセスが求められる機械学習用途に最適化された新しいストレージクラス「Amazon S3 Express One Zone」がリリースされました。
従来の「Amazon S3 Standard」と比較して、より高速なデータアクセスと低レイテンシーを実現しています。
Amazon S3 Express One Zoneは、1つのAZにデータを保存するため、マルチAZ構成のAmazon S3 Standardと比べて耐久性は劣ります。
ただし、性能面では優れており、機械学習のように高速なデータアクセスが求められる用途に適しています。
また、料金もAmazon S3 Standardよりも安価に設定されているため、コストパフォーマンスに優れた選択肢と言えます。
誤削除への対策
Amazon S3は、データの誤削除を防ぐための様々な機能を提供しています。
代表的な機能としては、以下のようなものがあります。
- バージョンニング
オブジェクトの変更履歴を保存する機能。誤ってオブジェクトを削除した場合でも、以前のバージョンを復元することができます。 - オブジェクトロック
オブジェクトの削除や上書きを一定期間禁止する機能。コンプライアンス要件や規制に対応するために利用されます。 - レプリケーション
オブジェクトを他のリージョンやバケットに複製する機能。データのバックアップや災害対策に有効です。 - AWS Backup
AWS Backupは、S3を含む様々なAWSサービスのバックアップを一元管理できるサービスです。定期的なバックアップやリストアを自動化することができます。
まとめ
本記事では、Amazon S3のアーキテクチャと最新のストレージクラス、誤削除への対策について解説しました。
ポイントを以下にまとめます。
- Amazon S3は、フロントエンド、インデックス、ストレージ層の3つの要素で構成され、高いパフォーマンスと信頼性を実現しています。
- 負荷分散、Key-Valueストア、冗長性、データ整合性などの技術が、S3の安定稼働を支えています。
- 新しいストレージクラス「Amazon S3 Express One Zone」は、機械学習用途に最適化されており、高速なデータアクセスと低レイテンシーを実現しています。
- データの誤削除を防ぐためには、バージョンニング、オブジェクトロック、レプリケーション、AWS Backupなどの機能を活用しましょう。
Amazon S3は、AWSの基盤を支える非常に重要なサービスです。
本記事で解説した内容を理解することで、S3をより効果的に活用できるようになるでしょう。
AWSモダナイズ・スモールスタート開発支援、基幹業務システムのUI.UX刷新はお気軽にお問い合わせください。
スモールスタート開発支援、サーバーレス・NoSQLのことなら
ラーゲイトまでご相談ください
低コスト、サーバーレスの
モダナイズ開発をご検討なら
 開発 をご希望の企業様
開発 をご希望の企業様 下請け対応可能
Sler企業様からの依頼も歓迎
協業 をご希望の企業様 



ラーゲイトは、世界の最新技術を追い続ける
プロフェッショナルチームです。





