




Amazon Aurora アップデート最新情報「AWS Summit Japan 2024 のセッション」まとめ
 2024.07.01
2024.07.01



本記事では、AWS Summit Japan 2024 のセッション「Amazon Aurora の技術とイノベーション Deep dive」の内容をベースに、Amazon Aurora の魅力的な機能やアーキテクチャについて紹介します。
Amazon Aurora とは?
Amazon Aurora は、MySQL と PostgreSQL 互換のリレーショナルデータベースサービスです。MySQL や PostgreSQL と高い互換性を持っているため、移行も容易に行えます。Aurora の特徴としては、以下が挙げられます。
| 特徴 | 説明 |
|---|---|
| 高いパフォーマンス | 従来の MySQL や PostgreSQL に比べて、最大で 5 倍のパフォーマンスを実現しています。 |
| 拡張性 | データベースのサイズやスループットを、必要に応じて容易にスケールアップ・スケールダウンできます。 |
| 可用性と耐久性 | データは複数のアベイラビリティゾーンに自動的にレプリケートされるため、高い可用性と耐久性を実現しています。 |
| 高い安全性 | ネットワークの分離、データの暗号化、監査ログの記録など、セキュリティ機能が充実しています。 |
| フルマネージド | データベースの運用管理タスクを AWS が代行してくれるため、運用管理の手間を大幅に削減できます。 |
Aurora のアーキテクチャ
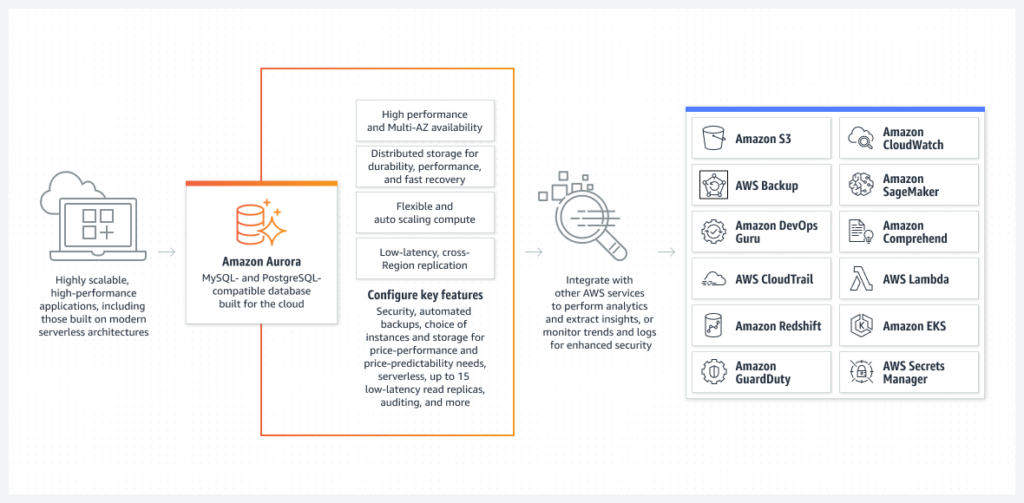
Aurora の特徴である可用性と耐久性を支えるアーキテクチャについて詳しく見ていきましょう。
Aurora ストレージは、3 つのアベイラビリティゾーンにわたって分散されており、6 つの異なる場所にデータが書き込まれます。書き込みが完了するためには、少なくとも 2 つのアベイラビリティゾーン内の 4 つのストレージにアクセスできれば OK です。そのため、1 つのアベイラビリティゾーンに障害が発生した場合でも、システム全体としては稼働し続けることができます。
読み込みに関しては、通常の MySQL や PostgreSQL と同じように、ブロック単位で行われます。
Aurora では、リードレプリカと呼ばれる読み込み専用のデータベースインスタンスを最大 15 台まで作成することができます。リードレプリカは複数のアベイラビリティゾーンに配置することができ、異なるインスタンスタイプを混在させることも可能です。例えば、プロビジョンドインスタンスとサーバーレスインスタンスを必要に応じて組み合わせることができます。
リードレプリカを作成する際は、ライターインスタンスからリードレプリカへ、非同期でログ情報が転送されます。リードレプリカのバッファ上のデータも更新されます。この仕組みにより、リードレプリカは常に最新の状態に保たれます。
Aurora ストレージは、オンデマンドで容量を増減させることができます。事前に必要なストレージ容量を見積もる必要がなく、使った分だけの支払いで済みます。
Amazon Aurora Global Database
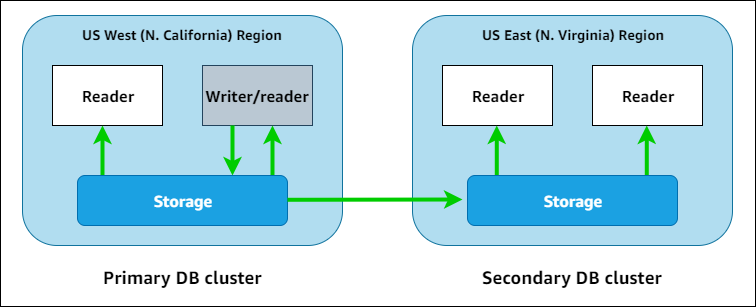
Aurora Global Database は、リージョンをまたぐ DR 構成を必要とするシナリオに最適化された機能です。従来のバックアップを転送するなどの仕組みでは、迅速な復旧が難しいものでしたが、Aurora Global Database は設定を有効にするだけで簡単にリージョンをまたぐ DR 構成を構築することができます。
グローバル規模での可用性を構築できるだけでなく、リードレプリカを追加することでパフォーマンスを向上させることも可能です。
グローバルデータベースを有効にすると、選択した別のリージョンに Aurora のストレージとレプリケーションサーバー(レプリケーションエージェント)がセットアップされます。これらのコンポーネントはユーザーが管理する必要はありません。
従来の MySQL や PostgreSQL では、レプリケーションストリームは単一のものを使用していました。しかし、Aurora ではレプリケーションを並行して行うことができます。このため、大量のデータ転送にも耐えうる構成となり、何千ものスループットがあるようなシステムでも利用可能です。
レプリケーションはプライマリーリージョンからセカンダリーリージョンに非同期で行われます。プライマリーリージョンの Aurora クラスタとレプリケーションサーバーにデータが送られ、エージェントを通じてセカンダリー DB クラスタの Aurora ストレージにデータが転送されます。
フェイルオーバー
リージョンをまたぐ DR 構成を構築できる Aurora Global Database ですが、切り替えには 2 つのパターンがあります。
1 つ目が、別のリージョンにプライマリーを移動させるスイッチオーバーです。こちらは障害からの即時復旧というよりは、障害からの切り替えテストを行う際にトポロジー自体はそのままでリージョンを切り替えることができるかを確認するユースケースで利用されます。
もう 1 つが、障害時に短時間で切り替えを行うフェイルオーバーです。フェイルオーバーは、障害が発生した際に速やかに切り替えを行うために用意されています。
グローバルデータベースのリージョンの切り替えは、switch-over-global-cluster というコマンドによって実行されます。このコマンドを実行すると、プライマリーリージョンであったリージョン A の方が読み取り専用になり、全てのデータがレプリケーションによってセカンダリー DB クラスタと一致していることを確認した上で、セカンダリーであったリージョン B の方をプライマリーに昇格させればスイッチオーバーは完了です。
フェイルオーバーは、障害が発生した際に迅速に切り替えを行うための仕組みです。failover-global-cluster というコマンドを使用して実行されます。このコマンドは、非同期レプリケーションにおいてセカンダリー DB クラスタに足されていないデータがある状態で切り替えを行う可能性があるため、 allow-data-loss という追加のフラグが付いています。フェイルオーバー自体は短時間で実行され、迅速に起動することができます。
フェイルオーバーを実行すると、まず、元のプライマリーリージョンが読み取り専用になります。次に、レプリケーションを再構築します。この際に、プライマリーリージョンだったクラスタのスナップショットを取得しています。これにより、フェイルオーバーの際にキャプチャされなかったデータを後から確認することができます。
そして、フェイルオーバー先のクラスタ内のインスタンスがライターに昇格し、データの同期を再開します。レプリケーション方向は新しいプライマリーリージョンからセカンダリーリージョンに送られるようになります。
Aurora Serverless

Aurora では、管理のしやすさに関しても様々な進化が進んでいます。その 1 つとして、Aurora Serverless があります。
データベースにおけるサーバーレスとは、状況の変化に合わせて 1 秒以内に適切なスケーリングを行うことができるものです。
例えば、Lambda 関数がデータベースに接続されているとします。単一のワークロードの場合は特に問題ありませんが、ワークロードが変化し、多くの Lambda が起動されるようになると、データベース側もメモリや CPU などのリソースを増やす必要があります。
Aurora Serverless はこのような状況の変化に合わせて、1 秒以内に適切なスケーリングを行うことができるため、従来型のプロビジョニングされたインスタンスのように、リソース不足が発生してレイテンシが増加してしまうような状況にも対応できます。
Amazon Redshift と Amazon Aurora ZeroETL 統合
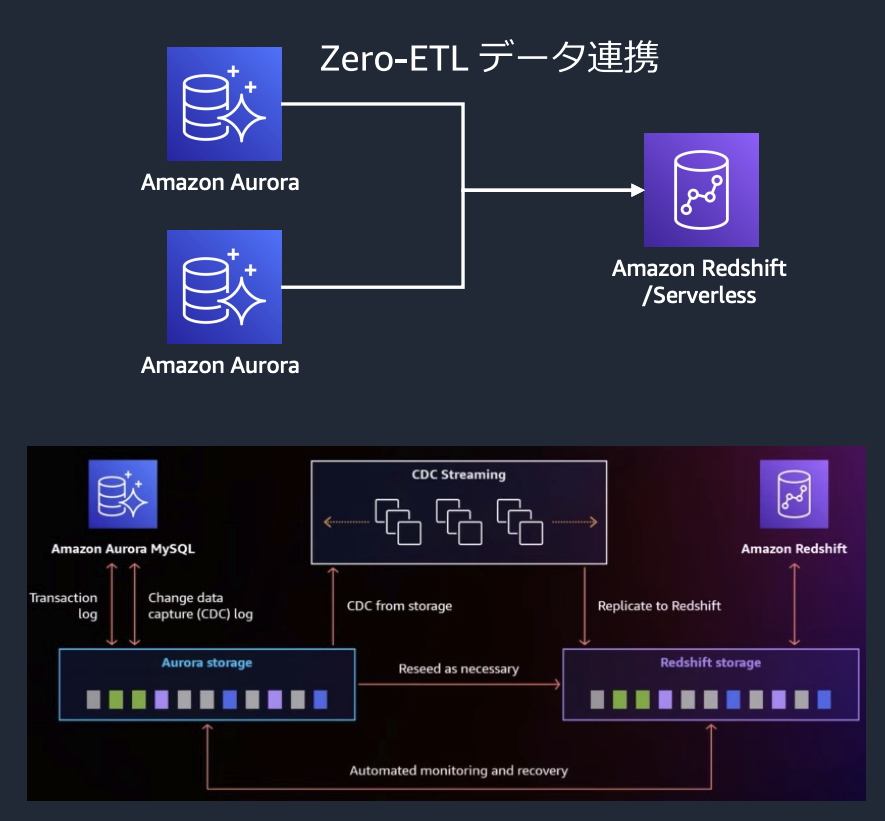
構築が簡単で、安全性が高く、ペタバイト規模のトランザクションデータであっても、ほぼリアルタイムで連携できるものとなっています。
ストレージに関するアップデート
Aurora では新しいストレージタイプが導入されています。
従来のストレージタイプは「スタンダード」と呼ばれ、コンピューティング、ストレージ、そしてストレージへの I/O に対して料金がかかるシンプルな従量課金制でした。
スタンダードの場合、ストレージへの読み込み・書き込みの回数やサイズに応じて料金がかかりますが、コストの見積もりの難しさというところもありました。
そこで新しくコストの予想がしやすく、パフォーマンスの向上も期待できる「IO Optimized」というストレージタイプが追加されました。
IO Optimized の場合、スタンダードに比べると、コンピューティングコストは 30%、ストレージに関しては 125% 価格が増加しますが、スタンダードと違って I/O コストはかからなくなります。
作成または変更を行う際に、スタンダードと IO Optimized のどちらかを選択していただくことになります。IO Optimized が向いているのは、大量の I/O を行うワークロードがある場合です。Aurora の支出総額の 25% 以上を I/O 支出に費やしているような場合は、IO Optimized が有効な選択肢となります。
PG ベクター
PostgreSQL ではこれまで対応する拡張機能の追加もありました。その中で PG ベクターは、AI の活用が広がる中で利用が進んでいる拡張機能の 1 つとなっています。
生成系 AI の活用を考える際に、LLM に基づくデータに基づく回答をさせるラグを構築することがあるかと思いますが、ラグの構築の際には、質問された内容に関連性のある情報を検索できるベクトルデータベースを利用される場合もあるかと思います。
PG ベクターを使うことで、データの保管にベクトルデータ型を利用できるようになり、Aurora をベクトルデータベースとして活用できます。また、インデックスの作成には、近似検索に適した IVF Flat と HNSW という 2 つのインデックスタイプが用意されています。
検索では、完全最近傍と呼ばれる正確性を求める手法と、近似最近傍 (ANN) と呼ばれる計算速度を重視した手法をとることができます。
また、メタデータの保管も埋め込みベクトルと同じ場所に保管することができます。
距離演算子も利用でき、ユークリッド距離、コサイン距離、内積などが利用可能です。
PG ベクターを利用することで、使い慣れた PostgreSQL を生成系 AI に関わるビジネスにも活用できるようになります。また、AWS では生成系 AI で使われるサービスのベッドロックの中に、ナレッジベースというラグを構築するための機能がございますが、ナレッジベースではベクトルデータベースとして PG ベクターを利用した Aurora PostgreSQL と連携できます。
実際にどのように利用するかですが、まず、テーブルの作成について、埋め込みベクトルを保管するために、赤枠にあるようなベクトルデータ型の列を作成します。次にインデックスの作成部分です。ここでは IVF Flat のインデックスを作成しています。最後のセレクトについては、距離演算子を使ってベクトルデータの検索を行い、最適なアイテムを見つけ出すことができます。
まとめ
Amazon Aurora のアーキテクチャや新機能について解説しました。特に以下の点が重要です。
- Aurora ストレージは 3 つのアベイラビリティゾーンに分散され、高い可用性と耐久性を実現していること
- リードレプリカを活用することで、読み込みパフォーマンスを向上させることができること
- グローバルデータベースを使うことで、リージョンをまたぐ DR 構成を容易に構築できること
- Aurora Serverless を利用することで、瞬発的なリソース不足にも対応できること
- Managed Blue/Green Deployment を活用することで、ダウンタイムを短縮したメンテナンス作業を行うことができること
- IO Optimized を利用することで、I/O コストを削減し、パフォーマンスを向上させることができること
- Optimized Read を利用することで、大量の I/O を行うワークロードのパフォーマンスを向上させることができること
- PG ベクターを活用することで、Aurora PostgreSQL をベクトルデータベースとして活用することができること
これらの機能を活用することで、よりセキュアで可用性の高い、そしてパフォーマンスに優れたデータベースシステムを構築することができます。
AWSモダナイズ・スモールスタート開発支援、基幹業務システムのUI.UX刷新はお気軽にお問い合わせください。
スモールスタート開発支援、サーバーレス・NoSQLのことなら
ラーゲイトまでご相談ください
低コスト、サーバーレスの
モダナイズ開発をご検討なら
 開発 をご希望の企業様
開発 をご希望の企業様 下請け対応可能
Sler企業様からの依頼も歓迎
協業 をご希望の企業様 



ラーゲイトは、世界の最新技術を追い続ける
プロフェッショナルチームです。





