




インシデントの影響を封じ込めるクラウドアーキテクチャの実践!次世代のマイクロアーキテクチャは「セルベースアーキテクチャ」です😎
 2024.06.29
2024.06.29



システム開発において、障害発生時の影響範囲を最小限に抑えることは非常に重要です。
本記事では、システム全体に影響が及ぶ可能性のある障害を防ぐためのアーキテクチャである「セルベースアーキテクチャ」と、特定クライアントからのリクエストによる障害の影響範囲を狭める「シャッフルシャーディング」というテクニックについて解説し、システム全体のレジリエンス向上のための設計ポイントを紹介します。
※ レジリエンス=回復力、復元力、耐久力、再起力、弾力
Webサービスで起きた障害事例

まずは、よくあるWebサービスで発生する障害について、3つの事例を例に見ていきましょう。
※ 以下実例をサンプルとした具体内容となりますが、やや批判内容は含まれますので社名などは伏せます
テスト不足の事例
ある日、コスト削減のためにDynamoDBの不要になったアトリビュートを削除したとします。DynamoDBはNoSQLなので、アトリビュートの数は増減する前提で開発しているため、問題ないだろうと考えていました。
しかし、リリース後にこの削除したアトリビュートがある前提で組まれたロジックが存在していたことが発覚。テスト不足により、この変更が原因でバグが発生し、お客様全体に影響を与える障害が発生してしまいました。
このような障害を防ぐためには、十分にテストを実施することが重要です。例えば、Blue-Green Deploymentを採用することで、すぐに切り戻せるようにするなどの対策が考えられます。しかし、アプリケーションが大規模になったり、開発速度が速いと、テストカバレッジ100%を常に目指すのは非現実的であり、すぐに切り戻せたとしても、お客様全体に影響が出てしまう可能性もあります。
オペレーションミスの事例
デプロイした機能がうまく動かないため、切り分けのために管理者権限でテスト用ポートを緊急で開けて欲しいと開発チームから依頼があったとします。緊急事態なので、今回限りで良いかとセキュリティグループのルール変更をしたところ、誤って既存のルールを削除してしまい、システム全体に影響する障害が発生してしまいました。
このような障害を防ぐためには、本番環境を手動で変更しないことが重要です。CI/CDを導入し、IaC、Policy as Code等で安全ではない変更を阻止するといった対策が考えられます。しかし、絶対にやらないだろうというようなオペレーションでも、長期間サービス提供をしていると発生してしまうという場合も少なくありません。
ポイズン・ピルの事例
あるユーザーが、想定していないデータ型、あるいは頻度のリクエストを送ってきたとします。これにより、バグを踏んだ、あるいは負荷が急増し、システム全体に障害が発生しました。このようなケースを「Poison Pill」と呼びます。
この障害に対しても、様々な対策案が考えられますが、すべての可能性を想定し、対策することは非常に困難です。
なぜそのような事例が発生するのか?
上記3つのシナリオに共通して言えることは、完全に防ぐことが難しい種類の障害であるということです。
これらの障害は、影響範囲がお客様全体、あるいはアプリケーション全体に及ぶことが課題といえます。そこで、障害の影響範囲を狭めるアプローチが必要になります。
セルベースアーキテクチャとは
セルベースアーキテクチャとは、アプリケーション全体をセル単位で複製して論理的な境界を作成する手法です。
セルベースアーキテクチャでは、まずシステムを「データプレーン」と「コントロールプレーン」に分けます。
| 分離内容 | 説明 |
|---|---|
| データプレーン | セルとセルルーターが存在し、セル同士はデータを含め、 互いに独立したアプリケーションとして稼働します。 すべてのリクエストは、セルルーターで各セルに振り分けられます。 |
| コントロールプレーン | セルの作成、削除、セル間のデータ移動などを実施します。 |
セルベースアーキテクチャのメリット

セルベースアーキテクチャには、以下の3つのメリットがあります。
| メリット | 説明 |
|---|---|
| 障害分離性 | 従来の構成では、バグ、オペレーションミス、Poison Pillなどによる障害の影響範囲がシステム全体に及ぶ可能性が高くなります。 一方、セルベースアーキテクチャでは、変更頻度が高い複雑なビジネスロジックはセルの中に入ります。そのため、障害が発生した場合でも影響範囲をシステム全体の一部に抑えられます。 全体のリクエストが100だとし、10個のセルを作ったと仮定します。そのうち1つのセルが落ちたとしても、9割のリクエストは正常に捌くことができます。 |
| スケール性 | 従来の構成では、スケールアップが中心となるため、解決が難しいパフォーマンス課題が発生する可能性があります。 一方、セルベースアーキテクチャでは、それぞれのデータがすでに分割されているため、スケール時にセルを追加することで、スケールアウトすることができます。 これと組み合わせて、セルごとの規模を一定に抑え、例えばセルもAWSアカウントを分けるといった対策を講じることで、全体の挙動が予測しやすくなり、スケール性が向上します。 |
| テスト性 | 一般的なアーキテクチャでは、通常システムに変更がある際、 Blue-Green Deploymentが利用できますが、データベースの変更はBlue-Green Deploymentに頼らざるを得ない場合があり、 変更による悪影響がシステム全体に影響を与えてしまいます。 一方、セルベースアーキテクチャでは、システム全体の中の一部にだけ本番適用し、本番環境で実際にテストを行うという方針がより取りやすくなります。 本番環境でのテストを簡単にできることで、システム全体の可用性を上げることができます。 |
セルベースアーキテクチャのデメリット
メリットが多いセルベースアーキテクチャですが、デメリットも存在します。
ハードウェア故障確率増加の可能性
セルベースアーキテクチャでは、セルルーターやコントロールプレーンといった要素が追加となるため、その分ハードウェア故障確率が増加する可能性があります。
例えば、一般的な構成において、データベースに単一で容量の大きいディスクを利用し、その故障率が0.01%だったとします。
セルベースアーキテクチャでは、ディスクが増えるため、セル数だけ故障率が増えるという可能性があります。
複雑性・コスト増
セルルーターやコントロールプレーンの追加により、システムの複雑性が増し、コストも増加する可能性があります。
このデメリットを軽減するためには自動化の仕組みを構築することが重要になります。
Amazon EBSの事例
AWSのサービスの中でも、セルベースアーキテクチャは積極的に採用されています。
Amazon EBSの内部での事例を具体的に見ていきましょう。
Amazon EBSは、EC2インスタンスにアタッチできるブロックストレージサービスです。EBSボリュームが稼働するプライマリストレージサーバーに書き込まれたデータは、セカンダリストレージサーバーに常にレプリケーションされます。
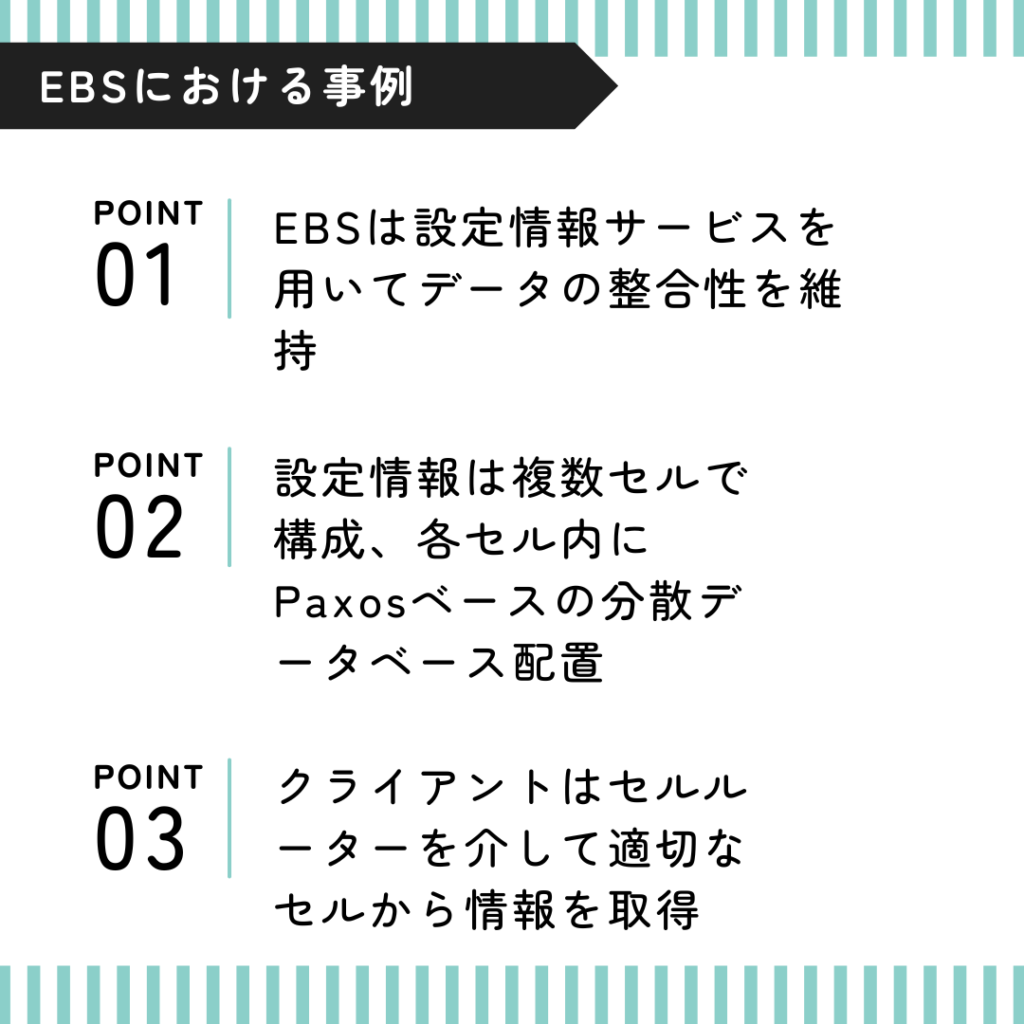
EC2インスタンスやEBSボリュームが稼働するプライマリーサーバーは、「設定情報サービス」からプライマリーの情報を得ることでデータの整合性を保っています。
何か障害があった際に、セカンダリにデータが書き込まれてしまうといったことを防ぐために、設定情報サービスの可用性が重要になります。
設定情報サービスにおいて、セルの内部ではプライマリーの情報を保持しているPaxosベースの分散データベースが稼働しています。
クライアントはセルルーターに対して問い合わせを行い、適切なセルの情報を聞いた上で、セルへプライマリーの情報を取得しにいく構成となっています。
この仕組みは非常に効果的で、EBSのプライマリーノードから見た視点での設定情報サービスの可用性を飛躍的に向上させました。
この事例からも、セルベースアーキテクチャのメリットを感じていただけたのではないでしょうか?
セルベースアーキテクチャの設計ポイント

セルベースアーキテクチャの設計ポイントとして、以下の3つの要素を考慮する必要があります。
- セルルーター
- セル
- コントロールプレーン
セルルーター設計
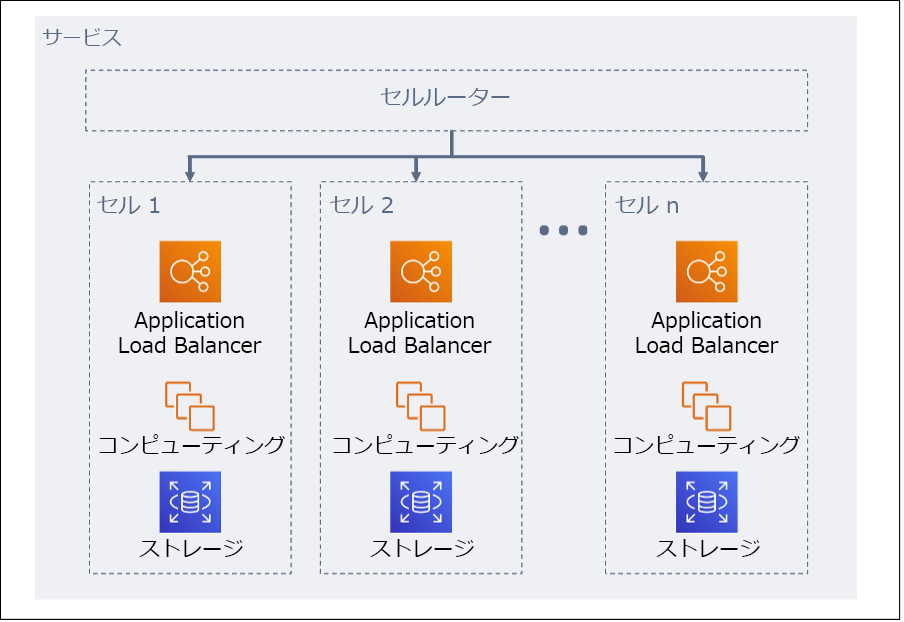
前述の通り、セルベースアーキテクチャではデータが分割されており、すべてのリクエストを振り分ける機能として「セルルーター」があります。
DNSに対してどのセルにアクセスするべきかを問い合わせ、返ってきたIPアドレスベースでアクセスするという方法があります。
この方法は、公開前提のパーティションキーが利用できる場合に非常に有効です。例えば、S3バケットでは、バケットごとにグローバルでユニークなURLが割り当てられています。
このようなパターンでは、非常に採用しやすい方法だと言えるでしょう。
クライアント側で持っている情報とDNS名のマッピングのために、クライアント側の追加での処理が必要な場合もあります。このマッピング処理が実装できない場合は、「API Gatewayパターン」を利用できます。
API Gatewayを例えばDynamoDBのプロキシとして利用する方法です。
その他にも、API Gatewayの各機能を活用できるというメリットもあります。
- SLAはこちらの通りなので、必要に応じてマルチリージョン化などの検討が必要です。
- より高い冗長性が求められる場合は、独自のコンピュータを用意し、クライアントからのルート問い合わせを処理するというパターンも考えられます。この場合、可用性を担保するためにコンピュータ自体も耐障害性を高めておくことが重要となります。
セル設計
各セルに格納されるデータは「パーティションキー」でまず分割されます。
各セルは、通常はレプリケーションを行わず、可能な限り依存関係をなくすように設計するのが理想的です。
- データやリクエストの偏りによる影響が出ないように、適切なパーティションキーを設定することが重要です。典型例としては、カスタマーIDやデバイスIDなどが挙げられます。
データやリクエストが特定のカスタマーIDに偏る場合は、複数の種類のキーを組み合わせたものを利用するといった工夫も有効です。 - 単一セルにどこまでのデータを寄せるのかという点も検討する必要があります。セル同士は通常はレプリケーションを行わず、可能な限り依存関係をなくす設計が推奨されます。
そのため、単一セルの特性を理解した上で、セルのサイズと数を決定していく必要があります。 - セルの上限に対して一定のバッファを常に保てるように、パーティションキー用度セルに配置するかといったことを考えて決定する必要があります。
例えば、お客様が増えた場合や、使用リソースがしきい値を超えてしまうといった場合は、セルの数を増やしてスケールアウトします。 - 既存のセルに割り当てられているリソースを超えそうな顧客がいる場合、追加でセルの移動を検討します。ここで、変更に備えてセルの再配置方式をコントロールプレーンの設計に最初から盛り込んでおくことが重要です。
セルの移動・再配置について、具体的な方法を以下に紹介します。
- まずは、移行元と移行先において、該当パーティションキーに関するデータのレプリケーションを実施します。
- この時、2つのセルの間に依存関係を作る事になるので、たくさんのコピーを同時に発生させないように注意が必要です。ある程度コピーが完了したら、どこかのタイミングで書き込みを停止します。例えば、isMigratedのようなフラグを該当項目に対して立てて、アプリケーションから書き込み前の条件付き確認でそこをチェックし、弾くといったイメージです。
- その後、データの同期が完全に完了したことを確認します。
- 今回は移行先セルでリクエストを捌けるようにします。このとき、DNSやクライアント側で残っているキャッシュを想定して、移行元セルにリクエストが来た場合は、クライアントに対して新規セルを教える設定をした上で、セルルーターの設定変更を行います。
- キャッシュも次第に切れ、古いセルへ該当データに関するアクセスが無くなったところで、元のセルにあるデータを削除します。
このようにしてセルの再配置、移動を実施します。
具体的な実現方法は、システムや利用しているデータベースエンジンなどのテクノロジーに強く依存するため、あらかじめその方法を考えておくことが重要です。
コントロールプレーン設計
セルベースアーキテクチャの特性を活かすためには、セルを利用した段階的なデプロイを採用し、それを自動化していくことが重要です。
例えば、本番環境へのデプロイを考えた時に、まず最初は特定のセルだけにデプロイを実施し、その様子が良さそうであれば、他のセルに対しても加速的に展開していくといったアプローチが有効です。
あらかじめログにセル情報を付与しておいたり、メトリクスに関してもセルを意識した監視ができるようにしておくことが重要です。
例えば、全体可用性だけをモニタリングしていたとして、まずは1つ目のセルに変更をデプロイした後にアラートが上がっていないからと、他のセルへ変更をデプロイしてしまった場合、すべてのサービスが落ちてしまうといったことが考えられます。
コントロールプレーンにはセルの状態を監視した上で、複雑なオーケストレーションを行うロジックが入っており、何かの拍子でコントロールプレーンのコンピュータが落ちてしまう可能性があります。
仮に、古いデータしか見つからなかった場合に、データプレーンの挙動として、例えば最新情報をいち早く再計算してサービス復旧を早めるといったことを目的として、セルマッピングの計算に必要な情報があるソースのDBにアクセスする実装が考えられます。
また、その間データが古いので、クライアントからのルーティングのリクエストに対してはエラーを返すといった実装も考えられます。
これらの挙動は、障害時に通常時とは異なる挙動をする、いわゆるバイモーダルな挙動となっており、レジリエンスという観点ではアンチパターンとされているため、注意が必要です。
このような実装はサービス規模が大きくない場合はあまり問題になりませんが、サービスが成長すると、データプレーンの規模はコントロールプレーンの規模よりもはるかに大きい場合が出てきます。
これにより、ソースのDBも過負荷となり、コントロールプレーンの障害範囲の拡大につながります。
また、クライアントにはエラーが返されるため、クライアントからたくさんリトライされてしまうという特性を持ったサービスが多くなります。これによって結果的にデータプレーンも落ちてしまうという可能性があります。
その代わりに、セルルーターのデータプレーンは元のデータベースを見に行くのではなく、クライアントには古いデータを常に返却しながらポーリングをし続けるという方が、障害範囲を広げずに済み、データプレーンの可用性も結果的に高く保ち続けられるといったことが考えられます。
こういった障害時でも、仕事量を変えないシンプルなロジックを実装することが、全体のレジリエンス向上につながります。
また、システムにおいて規模の不一致がある場合は、より規模の小さい方が全体をハンドリングさせる方が、システムのレジリエンス向上に寄与するベストプラクティスも存在します。
シャッフルシャーディングとは

例えば、ユニコーンという動物が使用するシステム(ワークロード)が、例えば8つのワーカーで処理されているといったケースを考えます。
ここで、Poison Pillのリクエストを送ってきたと仮定します。
一般的なアーキテクチャでは、クライアントからのリクエストは全体に到達するため、Poison Pillが他のワーカーにも流入し、全体障害が発生します。この場合の影響範囲は100%ということになります。
セルベースアーキテクチャでは、クライアントは特定のセルにアサインされています。
ここでまた、ユニコーンがPoison Pillを送ってきたとします。
そうすると、Poison Pillの影響範囲はセルにとどまるため、ワーカーが8つで4つのセルに対してワーカーが2つずつアサインされていたとすると、障害の影響範囲は全体の25%となります。
しかしながら、このケースでは既存のワークロード全体がユニコーンの影響を受けてしまいます。この回避策として「シャッフルシャーディング」というテクニックがあります。
シャッフルシャーディングは、ハッシュ関数などを利用して、特定クライアントに対して、全体ワークロードが均等になるように、複数のシャードに割り当てて組み合わせるという方式になります。
この場合、ユニコーンと同じワーカーを、キリンとイヌも利用していますが、キリンやイヌは別のワーカーもアサインされているので、そこで処理を済ませられます。
ただし前提として、クライアントからリトライであるとか、迅速なフェイルオーバーと同じことが複数のワーカーで実現できるといった前提が必要です。
シャッフルシャーディングは、特定セルの中でさらに分割を分ける方式として採用したり、セルルーターやログ収集サービス、レコメンデーションサービスなどのステートレス、あるいは柔らかいステートを持つようなサービスで相性がいいものになります。
ただ、このような処理をした際の障害影響範囲に関しては、こんな形で計算ができます。
今回、8つのうち2つのワーカーを選択する組み合わせは全体で28通りあるので、クライアントが全体で100人いたとした場合、ユニコーンと完全に同じワーカーの組み合わせを持っているのは、100人中4人しかいません。
セルベースアーキテクチャと比較すると、シャッフルシャーディングではPoison Pillがインフラ全体に与える影響範囲は変わらないまま、ワーカーの数もそのままとなり、劇的にお客様への影響範囲を狭められます。
また、クライアントに割り当てるワーカーの数や、ワーカー自体が増えると、加速度的に有効性が上がっていくという点も魅力です。
まとめ
本記事では、セルベースアーキテクチャとシャッフルシャーディングにより、障害の影響範囲を狭めることができることを紹介しました。
セルベースアーキテクチャとは
アプリケーション全体をセル単位で複製し論理的な境界を作成することで、障害の影響範囲をセルに閉じ込めるアーキテクチャです。
- メリット:障害分離性、スケール性、テスト性
- デメリット:ハードウェア故障確率の増加、複雑性やコスト増
- セルベースアーキテクチャの設計ポイント:セルルーター、セル、コントロールプレーン
シャッフルシャーディングとは
ハッシュ関数などを利用して特定クライアントに対して、全体ワークロードが均等になるように複数のシャードに割り当てることで、影響範囲を均等に分散させる仕組みです。
- メリット:特定クライアントのリクエストによる障害の影響範囲をさらに抑えることができる
- デメリット:複雑性やコスト増
- 採用に適したサービス:ステートレスなワークロード、柔らかいステートを持つサービス
セルベースアーキテクチャやシャッフルシャーディング、およびレジリエンスに関するベストプラクティスは、世の中の事例や資料などでも紹介されていますので、ぜひ参考にしてみてください。
より具体的なサンプルを見てみたいという場合には、AWS SolutionsにCDKのサンプルがありますので、そちらもご確認ください。
システム開発において、障害発生時の影響範囲を最小限に抑え、システム全体のレジリエンスを向上させることは非常に重要です。
複雑性やコスト増加といったトレードオフはありますが、それを乗り越えていくだけの価値があると言えるでしょう。
AWSモダナイズ・スモールスタート開発支援、基幹業務システムのUI.UX刷新はお気軽にお問い合わせください。
スモールスタート開発支援、サーバーレス・NoSQLのことなら
ラーゲイトまでご相談ください
低コスト、サーバーレスの
モダナイズ開発をご検討なら
 開発 をご希望の企業様
開発 をご希望の企業様 下請け対応可能
Sler企業様からの依頼も歓迎
協業 をご希望の企業様 



ラーゲイトは、世界の最新技術を追い続ける
プロフェッショナルチームです。





