




データ基盤のコスト最適化ベストプラクティス
 2024.08.04
2024.08.04



みなさんこんにちは! 今日はデータ基盤のコスト最適化について、お話したいと思います。
データ基盤って、構築・運用するにあたってどうしてもコストがかかってしまうものなんですよね。でも、適切な設計と運用を心がけることで、コストを大幅に削減できる可能性があるんです。
データ基盤のコスト問題
データ基盤のコスト最適化について考える前に、まずはどんなコストが発生するのか、どんな課題があるのかを把握しておきましょう。
データ基盤のコストは、以下の4つの要素で構成されます。
- ストレージ
- データ転送料金
- データパイプライン
- クエリ
これらのコストは、データ量や処理内容、利用状況によって大きく変動します。そのため、コスト予測が難しく、構築・運用中にコストが想定以上にかかってしまうケースも少なくありません。
| 課題 | 説明 |
|---|---|
| サービス横断でコストが発生する | データ基盤は複数のサービスを組み合わせて構築されるため、各サービスの利用料金を確認するだけでは全体のコストを把握できません。 |
| データ量と処理に強く依存する | データ量や処理内容が増加すると、それに比例してコストも増加します。そのため、データ量や処理内容が変動する場合は、コストの増減にも注意が必要です。 |
| 予測が難しい | データ量や処理内容、利用状況が変動するため、コストを正確に予測することが難しいです。 |
| 適切な設計により大幅なコストカットが可能 | データ基盤の設計次第で、コストを大幅に削減できる可能性があります。適切なストレージクラスの選択、データ転送の効率化、データパイプラインの最適化、クエリのチューニングなど、様々な方法でコスト削減を図ることができます。 |
コストの可視化
コスト最適化の第一歩は、現状把握です。データ基盤のコストがどのように発生しているかを可視化しましょう。
可視化のポイント
データ基盤のコスト可視化には、以下の4つのポイントがあります。
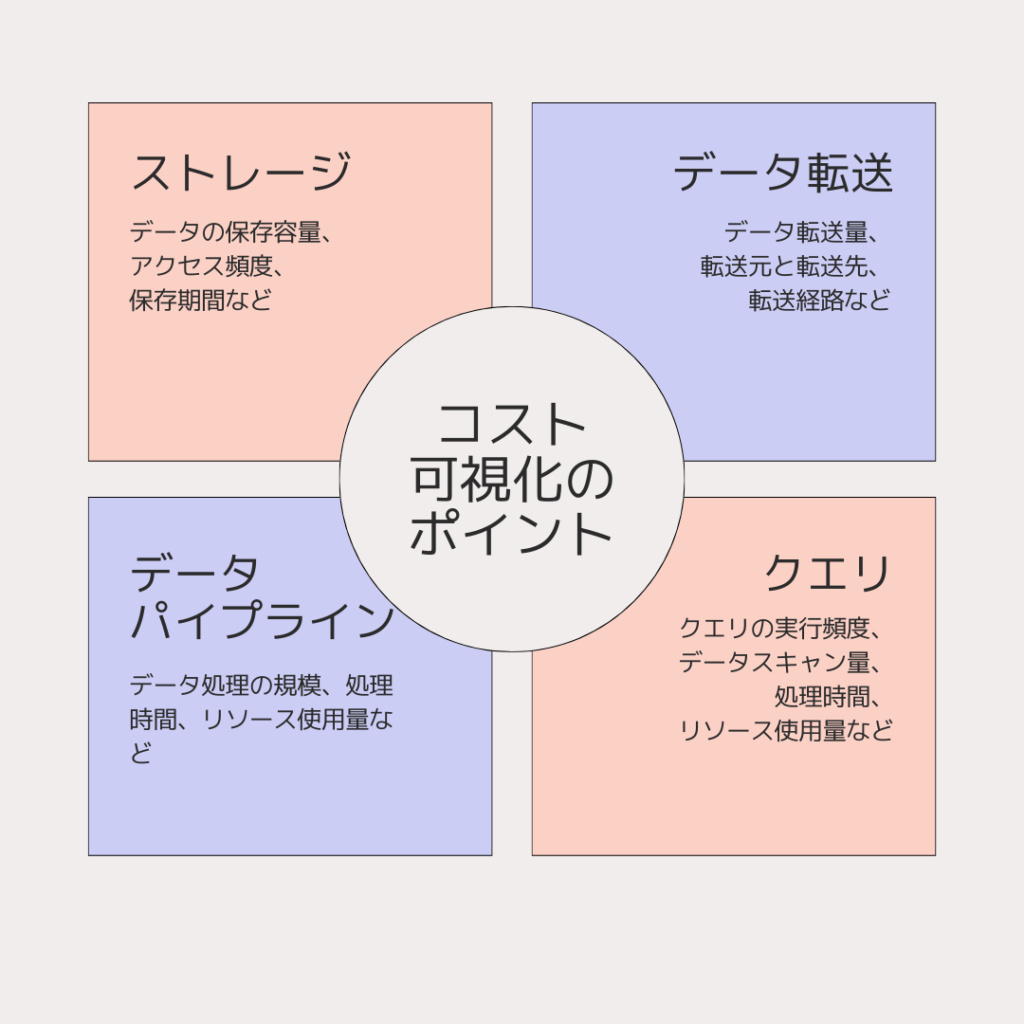
- ストレージ:データの保存容量、アクセス頻度、保存期間などを分析
- データ転送:データ転送量、転送元と転送先、転送経路などを分析
- データパイプライン:データ処理の規模、処理時間、リソース使用量などを分析
- クエリ:クエリの実行頻度、データスキャン量、処理時間、リソース使用量などを分析
これらのポイントを可視化することで、コストの発生源を特定し、最適化のターゲットを絞り込むことができます。
可視化に役立つツール
AWSでは、データ基盤のコスト可視化に役立つ以下のツールを提供しています。
- AWS Cost Explorer:AWS利用料金を可視化・分析するための無料ツール。サービスやリージョンごとのコストを分析できるほか、過去最大38ヶ月分のデータを確認したり、将来12ヶ月分の予測を作成したりすることも可能です。
- S3 Storage Lens:S3ストレージのコストを詳細に可視化するためのツール。アカウントレベル、バケットレベル、プレフィックスレベル、オブジェクトレベルでストレージ利用状況を分析できます。また、ビジュアル化されたダッシュボードで、ストレージ使用量の推移や傾向を把握できます。
これらのツールを活用することで、データ基盤の全体像を把握し、コスト最適化の糸口を見つけることができます。
コストの最適化
可視化によってコストの発生源を特定できたら、次は具体的な最適化に取り組みましょう。

ストレージコストの最適化
データ基盤で利用するストレージ、特にAmazon S3のストレージコストは、データのライフサイクルやアクセス頻度に合わせて最適化することができます。
AWSでは、以下のようなストレージクラスを提供しています。
| ストレージクラス | 説明 | 適用例 |
|---|---|---|
| S3 Standard | 頻繁にアクセスされるデータに最適なストレージクラス | 直近1年間のデータ、頻繁にアクセスされるデータ |
| S3 Standard-IA (Infrequent Access) | アクセス頻度が低いデータに最適なストレージクラス。データ取得に時間がかかっても問題ない場合に利用できます。 | 1~2ヶ月に1回程度アクセスされるデータ |
| S3 Glacier Instant Retrieval | アーカイブ用途で、即時データ取得が必要な場合に最適なストレージクラス | 1年に数回程度アクセスされるデータ |
| S3 Glacier Flexible Retrieval | アーカイブ用途で、データ取得に数分から数時間かかる場合に最適なストレージクラス | 数ヶ月に1回程度アクセスされるデータ |
| S3 Glacier Deep Archive | アーカイブ用途で、データ取得に12時間以上かかる場合に最適なストレージクラス | 年に1回程度アクセスされるデータ |
| S3 Intelligent-Tiering | アクセスパターンに基づいてストレージクラスを自動的に選択するストレージクラス。アクセスパターンが事前にわからない場合や予測が困難な場合に利用できます。 | アクセスパターンが不明なデータ |
ストレージコストの最適化には、以下の3つのポイントを考慮しましょう。
- アクセス頻度:頻繁にアクセスされるデータはS3 Standardに、アクセス頻度が低いデータはS3 Standard-IAやS3 Glacierなどの低コストなストレージクラスに保存することで、コストを削減できます。
- 保存期間:保存期間が明確に決まっているデータは、ライフサイクル設定で適切なストレージクラスに自動的に移行または削除することで、コストを削減できます。
- データ取得の性能:データ取得の性能要件に合わせて、適切なストレージクラスを選択する必要があります。例えば、即時データ取得が必要な場合は、S3 Glacier Instant Retrievalを選択する必要があります。
データ転送コストの最適化
データ転送コストは、データの転送量や転送経路によって大きく変動します。
AWSでは、同一の Availability Zone 内のデータ転送やインターネットからのデータ転送にはデータ転送料金がかかりませんが、インターネットへのデータ転送や、リージョンを跨いでのデータ転送にはデータ転送料金が発生します。
データ転送コストの最適化には、以下のポイントを考慮しましょう。
- データ転送経路:データ転送経路を最適化することで、データ転送料金を削減できます。例えば、VPC 内の EC2 インスタンスから S3 にデータをアップロードする場合、NAT ゲートウェイを経由せずに S3 の Gateway Endpoint を利用することで、インターネットゲートウェイを経由するコストを削減できます。
- データのローカリティ:データの場所を考慮することで、リージョン間のデータ転送を削減できます。例えば、データを利用するユーザーに近いリージョンにデータを配置することで、データ転送料金を削減できます。
- データ転送の効率化:データの圧縮や差分転送などを行うことで、データ転送量を削減できます。
データパイプラインコストの最適化
データパイプラインコストは、主に以下の2つの要素で構成されます。
- リソース使用量:データ処理に必要なコンピューティングリソースの使用時間やデータスキャン量に応じて課金されます。
- データ転送料金:データパイプライン内で発生するデータ転送量に応じて課金されます。
データパイプラインコストの最適化には、以下のポイントを考慮しましょう。
- 料金プラン:データパイプラインで利用するサービスの料金プランを適切に選択しましょう。
- オンデマンドインスタンス:長時間にわたるバッチ処理やストリーミング処理など、ステートフルな処理に適しています。
- スポットインスタンス:短時間のバッチ処理など、ステートレスなワークロードに適しています。
- Savings Plans:予測可能なワークロードで長期のコミットメントが可能な場合は、Savings Plansの利用を検討しましょう。
- サーバーレス:サーバーレスサービスを利用することで、継続的なリソースの保有をせずにコストを抑えられます。
- リソースのキャパシティ:データパイプラインで利用するリソースのキャパシティを最適化しましょう。
- オーバープロビジョニング:必要以上に大きなリソースを割り当ててしまうと、コストが無駄になります。
- アンダープロビジョニング:小さすぎるリソースを割り当ててしまうと、処理性能が低下し、結果的にコストが増加する可能性があります。
- オートスケーリング:オートスケーリング機能を利用することで、ワークロードに合わせて自動的にリソースを調整できます。
- アイドルリソース:アイドル状態のリソースはコストの無駄になります。サーバーレスサービスを活用したり、アイドル状態のリソースを自動的に停止する仕組みを導入するなどして、アイドルリソースを削減しましょう。
- ジョブのパフォーマンスボトルネック:パフォーマンスの低下は、処理時間の増加につながり、コスト増加の原因となります。ジョブの設定をチューニングして、パフォーマンスとコストのバランスを最適化しましょう。
- 処理対象のデータ量:処理対象のデータ量を削減することで、必要なコンピューティングキャパシティを減らし、コストを削減できます。データの洗い替えを行う際には、更新対象の範囲を必要最小限に抑えることを検討しましょう。
- データの変換処理:データの変換処理に、一部の重複演算や不要なデータ変換が含まれてしまうと、想定以上のコンピューティングキャパシティが必要となってしまい、コスト増加につながります。
- 不正なデータ:欠損したデータや壊れたデータが含まれてしまうと、そのデータの再取得が必要になったり、誤ったデータを反映してしまい、無駄なコストにつながってしまう場合があります。データクオリティ管理を導入することで、あらかじめデータクオリティをチェック済みデータのみを扱うことができます。
クエリコストの最適化
クエリコストは、主にデータスキャン量に応じて課金されます。
Amazon Athena SQL の料金モデルには、以下の2つのプランがあります。
- ペイパークエリ(クエリごとの料金プラン):クエリでスキャンしたデータサイズに対して課金されます。
- キャパシティ予約:あらかじめコンピューティングキャパシティを確保し、その利用時間に対して料金が発生します。
クエリコストの最適化には、以下のポイントを考慮しましょう。
- データスキャン量の削減:
- パーティショニング/バケッティング:データのレイアウトを最適化することで、クエリに必要なデータのみを効率的にスキャンできます。
- データ形式/圧縮フォーマット:データ形式や圧縮フォーマットをクエリの特性に合わせて最適化することで、クエリを高速化できます。
- クエリのチューニング:クエリ自体を最適化することで、データスキャン量を削減できます。
- クエリの再利用:同じクエリが繰り返し実行されるような状況では、クエリ結果を再利用することで、データスキャンを回避できます。これにより、処理時間を短縮しつつ、追加のスキャンを発生させずにコストを削減できます。
- データの移動:データソースのデータを、なんらかのデータレイクやデータウェアハウスなどのストレージに移動することは一般的です。一方で、あるデータに一度だけクエリする場合、わざわざロードする必要はおそらくないでしょう。こういったデータソースに定頻度で、あるいは一度きりクエリしたい場合は、データをロードするのではなく、Federated Query によって、直接目的のデータソースにアクセスすることも考えていきましょう。
まとめ
本記事では、データ基盤のコスト最適化について解説しました。
- データ基盤のコストは、ストレージ、データ転送、データパイプライン、クエリの4つの要素で構成されます。
- コスト最適化の第一歩は、AWS Cost Explorer や S3 Storage Lens を活用してコストを可視化することです。
- 可視化によってコストの発生源を特定できたら、ストレージクラスの選択、データ転送の効率化、データパイプラインの最適化、クエリのチューニングなど、様々な方法でコスト削減に取り組みましょう。
- コストの最適化は、一度やって終わりではありません。継続的に段階的にコストを最適化していくことが重要です。
AWSモダナイズ・スモールスタート開発支援、基幹業務システムのUI.UX刷新はお気軽にお問い合わせください。
スモールスタート開発支援、サーバーレス・NoSQLのことなら
ラーゲイトまでご相談ください
低コスト、サーバーレスの
モダナイズ開発をご検討なら
 開発 をご希望の企業様
開発 をご希望の企業様 下請け対応可能
Sler企業様からの依頼も歓迎
協業 をご希望の企業様 



ラーゲイトは、世界の最新技術を追い続ける
プロフェッショナルチームです。





