




今からでも遅くない!Amazon SageMaker Canvasで始める機械学習
 2024.07.31
2024.07.31



「機械学習って難しそうだな」「機械学習を導入してみたいけど、専門知識がないし、何から始めればいいか分からない」
そう思っている方は多いのではないでしょうか?
機械学習は、近年注目を集める技術ですが、実際に導入するには、専門知識やスキルが必要で、敷居が高いと感じている方も多いと思います。
しかし、AWSから提供されているAmazon SageMaker Canvas を使えば、コードを書くことなく、誰でも簡単に機械学習モデルを作成することができます。
本記事では、Amazon SageMaker Canvas の特徴や、機械学習プロジェクトを進めるワークフローについて解説し、コードを書かずに機械学習モデルの構築を始める方法についてご紹介します。
機械学習プロジェクトを始めるのに役立つAmazon SageMaker Canvas
Amazon SageMaker Canvasは、機械学習モデルの構築、トレーニング、デプロイを、視覚的なインターフェースで簡単に行うことができる、ノーコードの機械学習サービスです。
データサイエンティストの知識がなくても、ビジネスユーザーが簡単に機械学習モデルを構築して、ビジネス課題を解決することができます。
Amazon SageMaker Canvasが解決してくれる悩み
- 機械学習の専門知識やスキルがない
- 専門の機械学習チームを持っていない
- 機械学習モデルを構築してみたいけど、何から始めればいいか分からない
- コードを書くのが難しい
Amazon SageMaker Canvasは、このような悩みを持つ方にとって、機械学習への入り口となるサービスです。
Amazon SageMaker Canvasのワークフロー
Amazon SageMaker Canvasを利用して機械学習プロジェクトを進めるワークフローは以下のようになります。
| フェーズ | 内容 | 説明 |
|---|---|---|
| ビジネスゴールの特定 | どんなビジネス課題を解決したいかを明確にする | どんなビジネス課題を解決したいかを明確にし、その課題を解決するための具体的な目標を設定します。例えば、営業チームが「顧客の離反を予測して、離反を防ぎたい」と考えた場合、ビジネスゴールは「顧客の離反率を10%削減する」といった具体的な数値目標を設定することになります。 |
| データ収集 | 課題解決に必要なデータを収集する | 機械学習モデルの精度を高めるためには、十分な量のデータが必要です。目的のビジネス課題を解決するために必要なデータの種類や量を把握し、それらを収集します。 |
| データ前処理 | 収集したデータを機械学習モデルに利用可能な形式に変換する | 機械学習モデルは、数値データしか扱えません。そのため、テキストデータや画像データなどの非数値データを数値データに変換する処理が必要になります。また、データのノイズや欠損値を処理する必要もあります。 |
| 特徴量エンジニアリング | データからモデルの精度を高めるために役立つ特徴量を抽出する | 特徴量エンジニアリングは、データからモデルの精度を高めるために役立つ特徴量を抽出する作業です。例えば、顧客の離反を予測するために、顧客の年齢や購買履歴などのデータから、離反率に影響を与えると考えられる特徴量を抽出します。 |
| 学習・デプロイ | 作成したモデルを学習させ、システムに組み込む | 特徴量エンジニアリングで抽出した特徴量を使って、機械学習モデルを学習させます。学習が終わったら、モデルをシステムに組み込みます。 |
| 監視 | モデルの精度を継続的に監視する | 機械学習モデルは、常に最新のデータに基づいて学習し続ける必要があります。そのため、モデルの精度を継続的に監視し、必要に応じてモデルを再学習する必要があります。 |
Amazon SageMaker Canvasを使って、機械学習プロジェクトをスムーズに進めよう
上記のように、Amazon SageMaker Canvasは、機械学習プロジェクトを、誰でも簡単に始められるように支援するサービスです。
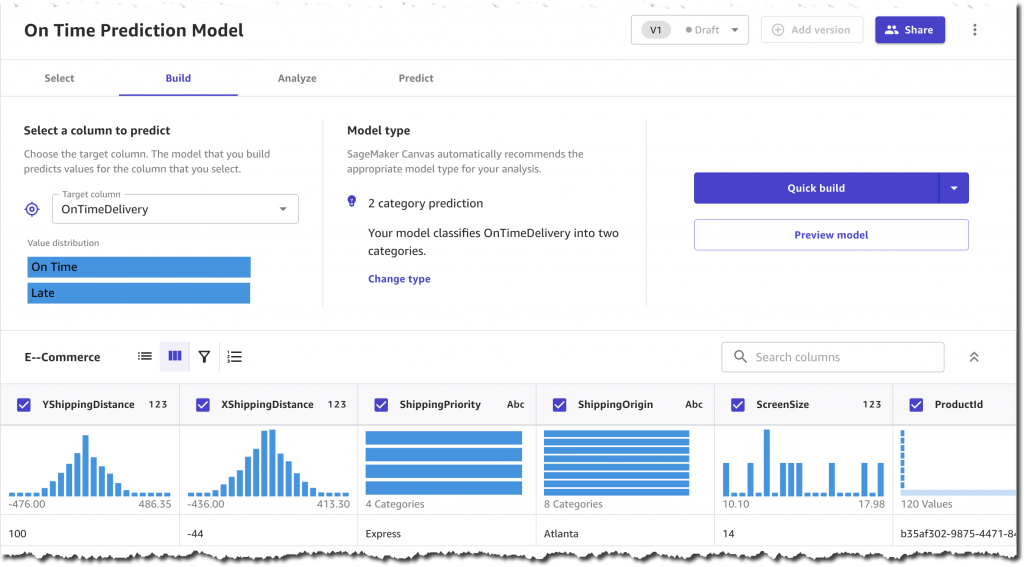
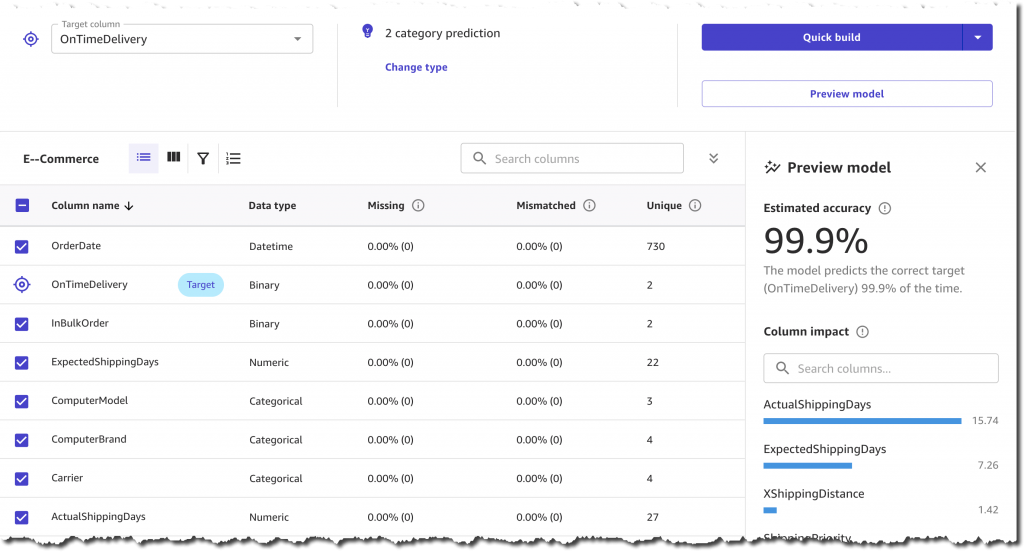
Amazon SageMaker Canvasを使うことで、コードを書くことなく、直感的な操作で機械学習モデルを構築し、ビジネス課題を解決することができます。
まとめ
Amazon SageMaker Canvasは、機械学習の知識やスキルがなくても、誰でも簡単に機械学習モデルを構築できるノーコードのサービスです。
ビジネスゴールの特定から、データの収集・前処理、特徴量エンジニアリング、学習・デプロイ、監視まで、機械学習プロジェクト全体のワークフローを支援します。
Amazon SageMaker Canvasは、機械学習の導入を検討している企業にとって、非常に有効なツールです。
AWSモダナイズ・スモールスタート開発支援、基幹業務システムのUI.UX刷新はお気軽にお問い合わせください。
スモールスタート開発支援、サーバーレス・NoSQLのことなら
ラーゲイトまでご相談ください
低コスト、サーバーレスの
モダナイズ開発をご検討なら
 開発 をご希望の企業様
開発 をご希望の企業様 下請け対応可能
Sler企業様からの依頼も歓迎
協業 をご希望の企業様 



ラーゲイトは、世界の最新技術を追い続ける
プロフェッショナルチームです。





