




ElasticSearchとDynamoStreamの連携/実装方法を解説!すぐに使える実践テクニックを紹介します😎
 2021.02.22
2021.02.22



こんにちは!
DynamoStream と ElasticSearch の連携は、私たちも多くのプロジェクトで使用するテクニックです。DynamoDB は本来 KVS 的な使用が理想なので、複雑な検索は ElasticSearch に任せたいですね。
しかし実際のところ、DynamoDB テーブルの Item の登録・更新・削除への対応や Lambda から ElasticSearch の連携に Assume ロールを使用できないなど、実装では数多くの難関があります。
本記事では、CloudFormation と NodeJS のソースコードを交え、実践で使えるテクニック・ノウハウを紹介します!
想定する読者
- DynamoDB の実装に関わるヒト
- DynamoStream と ElasticSearch の実装方法に悩んでいるヒト
- AWS サーバーレス開発に関わるヒト
ElasticSearch と DynamoDB のユースケース
ElasticSearch と DynamoDB のユースケース(使い分け)は、シンプルに下記の思考方法で検討します。
- KVS 的なデータ取得は、DynamoDB
- 水平軸で検索要件がスケールする箇所では、ElasticSearch
- 強い結果整合性を求める場合は DynamoDB(または異なる DBMS )
例えば、SNS サービスを考えてみましょう。フレンド検索や投稿された記事検索など、水平軸に要件がスケールしそうな検索要件が多く存在するかと思います。もちろんどのようなサービス(というよりもビジネス)なのかで、慎重に DBMSを検討しなければいけないですが、DynamoDB と ElasticSearch に限って言えば、一般的には下記のような使い分けをすることが多いかと感じます。
| フレンド検索 | ElasticSearch |
| 友達検索 | ElasticSearch |
| フレンド・友達の詳細情報取得 | DynamoDB |
また余談ですが、類似するフレンドの検索などには Amazon Neptune を使用するなど、DBMS をユースケースで使い分けるのが今時のクラウド開発のベストプラクティスと言えます。
ElasticSearch は 日本語検索に弱い
SNS の例を出しておいて恐縮ですが、日本語の部分一致などでは上手く検索できないケースがあります。これは、ElasticSearch 内部の日本語のバイナリーの扱い方に依存した問題なので、調整は難しいです。
検索要件が日本語に強く依存するのであれば、事前に日本語での検索を技術検証しておくことを強く推奨します。
DynamoDB のみでサービスをスタートするとAWS 費用は安く抑えられます
スタートアップのプロダクトで、ユーザー数が初期でそこまで見込めていない場合、検索要件にそもそも ElasticSearch を導入しないという選択肢もあります。
ElasticSearch は ElasticSearch インスタンスをホットスタンバイさせる関係で、EC2 に近い、あるいはスペックによっては EC2 よりも高い AWS 月額費用が発生します。
そのため、本来 DynamoDB は水平軸にスケールする検索要件で使用するべきではないですが、テーブルの Item 数がしばらく100にも満たない場合、「ElasticSearch を初期リリースで導入しない」というのも1つの選択肢と言えます。
ElasticSearch と DynamoDBStreamの実装方法の紹介
ではいよいよ本題の実装方法について解説していきます。
ワークフロー
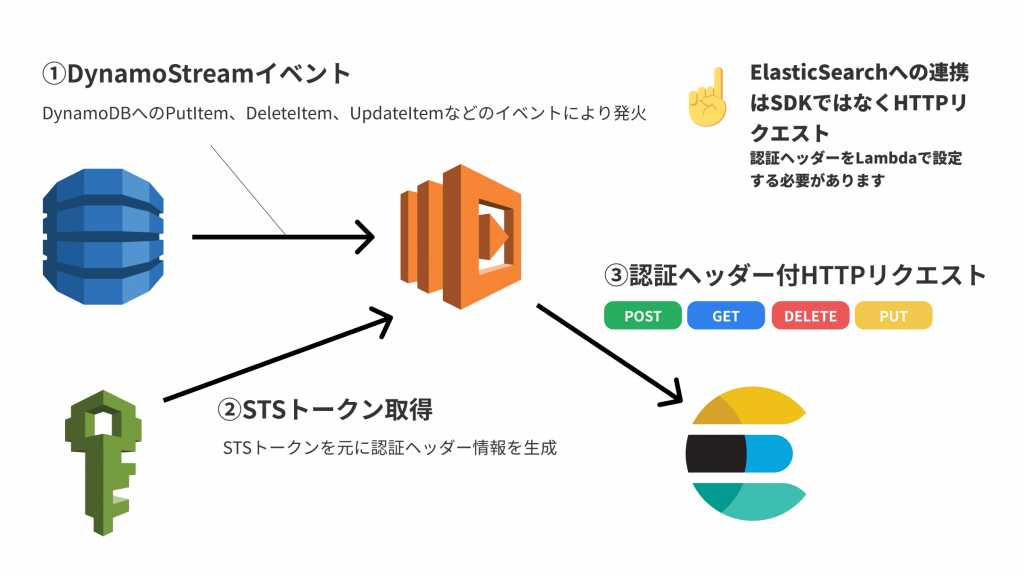
CloudFormation (ServerlessFramework)
まずは、ベースとなる serverless.yml を作成します。
# serverless.yml
service:
name: ElasticSearchWithDynamoStream
plugins:
- serverless-webpack
custom:
webpack:
includeModules: true
packager: 'yarn'
webpackIncludeModules: true
provider:
name: aws
runtime: nodejs12.x
stage: ${opt:stage,"dev"}
region: ap-northeast-1
role: DefaultLambdaRole
environment:
ES_DOMAIN: !GetAtt ElasticsearchDomain.DomainEndpoint
functions: ${file(resources/functions.yml)}
resources:
- ${file(resources/elastic-search.yml)}
- ${file(resources/dynamoDB.yml)}
- ${file(resources/iam-role.yml)}
package:
individually: true
exclude:
- node_modules/**
- resources/**
- package-lock.json
- package.json
- webpack.config.js
- yarn.lock
- README.md
- .git/**
- tmp/**次に、IAM ロールを作成します。ここで肝心なのは、ElasticSearch へのリクエストを許可するポリシーのアタッチです。後述しますが、ElasticSearch は、AWS の SDK で呼び出しをせず HTTP で直接リクエストを行う関係で、「ESHttpPut」のように、HTTP 通信を許可するようなポリシーをアタッチします。
# resources/iam-role.yml
Resources:
DefaultLambdaRole:
Type: AWS::IAM::Role
Properties:
RoleName: '${self:provider.stage}-${self:service.name}-defaultlambda-role'
AssumeRolePolicyDocument:
Version: '2012-10-17'
Statement:
- Effect: Allow
Principal:
Service:
- lambda.amazonaws.com
Action:
- sts:AssumeRole
Path: '/'
Policies:
- PolicyName: LambdaRolePolicy
PolicyDocument:
Version: '2012-10-17'
Statement:
- Effect: Allow
Action:
- logs:CreateLogGroup
- logs:CreateLogStream
- logs:PutLogEvents
Resource: arn:aws:logs:*:*:*
- Effect: Allow
Action:
- dynamodb:DescribeStream
- dynamodb:GetRecords
- dynamodb:GetShardIterator
- dynamodb:ListStreams
Resource: '*'
- Effect: Allow
Action:
- es:ESHttpGet
- es:ESHttpPost
- es:ESHttpPut
- es:ESHttpDelete
Resource: '*' # サンプルなので全指定
Tags: '${self:custom.tags.cloudFormation}'各種データストア( DynamoDB と ElasticSearch )を作成します。
# resources/dynamoDB.yml
Resources:
UserTable:
Type: AWS::DynamoDB::Table
Properties:
TableName: '${self:provider.stage}-${self:service.name}-User'
AttributeDefinitions:
- AttributeName: Id
AttributeType: S
KeySchema:
- AttributeName: Id
KeyType: HASH
ProvisionedThroughput:
ReadCapacityUnits: 1
WriteCapacityUnits: 1
StreamSpecification:
StreamViewType: NEW_IMAGEElasticSearch の作成の際のポイントは、AccessPolicies にDefaultLambdaRole のアクセスを許可している点です。これを有効にすることで、特定の Lambda のアクセスしか受け付けなくなります。(正確には、特定の IAM ロールのアクセストークン付きの HTTP アクセスしか受け付けなくなります)
この AccessPolicies の挙動は、リソースベースポリシーと類似していると私たちは感じます。
# resources/elastic-search.yml
Resources:
ElasticsearchDomain:
Type: AWS::Elasticsearch::Domain
Properties:
# 28文字以内に収めること
DomainName: '${self:provider.stage}-eswithdynamo-es'
ElasticsearchVersion: '7.9'
# クラスターの設定
ElasticsearchClusterConfig:
InstanceCount: 1
InstanceType: t2.small.elasticsearch
# 専用マスターノードの数
#DedicatedMasterEnabled: true
#DedicatedMasterType: INSTANCE_TYPE
#DedicatedMasterCount: 1
# 複数のAZを利用する場合
#ZoneAwarenessEnabled true
#ZoneAwarenessConfig:
# AvailabilityZoneCount: 2
# EBSの設定
EBSOptions:
EBSEnabled: true
Iops: 0
VolumeSize: 10
VolumeType: standard
# 自動スナップショット設定
SnapshotOptions:
AutomatedSnapshotStartHour: 0
# ElasticSearchのアクセスポリシー
AccessPolicies:
Version: '2012-10-17'
Statement:
- Effect: Allow
Principal:
AWS: !GetAtt DefaultLambdaRole.Arn
Action: 'es:*'
Resource: '*'最後に Lambda 関数を構築します。(ソースコードは後述)
ポイントは、先ほど構築した UserTable テーブルの Dynamo ストリームイベントを受け付けている点です。
# resources/functions.yml
HandleEsIndexOnUserTableStream:
handler: src/functions/handleEsIndexOnUserTableStream.handler
name: '${self:provider.stage}-handleEsIndexOnUserTableStream'
description: '${self:service.name}'
memorySize: 128
timeout: 60
events:
- stream:
arn: !GetAtt UserTable.StreamArn
type: dynamodb
batchSize: 100
enabled: True
startingPosition: LATESTStream イベントを受け付ける Lambda 関数
公式ドキュメントをベースに、私たちのコード文化に合わせて修正を加えたソースコードを紹介します。私たちは関数型プログラミングをテーマに実装を行う事例が多数なので、関数型プログラミング的なサンプルコードとなっています。
// src/functions/handleEsIndexOnUserTableStream.js
const AWS = require('aws-sdk');
const _ = require('lodash');
const {putEsDocument, updateEsDocument, removeEsDocument} = require('../services/elasticSearchService');
const ES_DOMAIN = process.env.ES_DOMAIN;
const ES_INDEX_KEY = 'Id';
const ES_INDEX_NAME = 'user';
exports.handler = async (event, context, callback) => {
const records = event.Records;
const _putEsDocument = _.curry(putEsDocument)(ES_DOMAIN, ES_INDEX_NAME, ES_INDEX_KEY);
const _updateEsDocument = _.curry(updateEsDocument)(ES_DOMAIN, ES_INDEX_NAME, ES_INDEX_KEY);
const _removeEsDocument = _.curry(removeEsDocument)(ES_DOMAIN, ES_INDEX_NAME);
await Promise.all(_.map(records, async r => {
switch (r.eventName) {
case "INSERT":
return await _putEsDocument(AWS.DynamoDB.Converter.unmarshall(r.dynamodb.NewImage));
case "MODIFY":
return await _updateEsDocument(AWS.DynamoDB.Converter.unmarshall(r.dynamodb.NewImage));
case "REMOVE":
return await _removeEsDocument(
_.get(AWS.DynamoDB.Converter.unmarshall(r.dynamodb.Keys), ES_INDEX_KEY)
);
}
}))
};const AWS = require('aws-sdk');
const _ = require('lodash');
const DOC_TYPE_NAME = '_doc';
const SEARCH_TYPE_NAME = '_search';
const awsHttpClient = new AWS.HttpClient();
/**
* ElasticSearchへのリクエスト処理実行
* @param {AWS/HttpRequest} request
* @returns {Promise<Object>}
* @private
*/
const _requestToElasticSearch = (request) => new Promise((resolve, reject) => {
const credentials = new AWS.EnvironmentCredentials('AWS');
const signer = new AWS.Signers.V4(request, 'es');
signer.addAuthorization(credentials, new Date());
awsHttpClient.handleRequest(request, null, (response) => {
console.log(response.statusCode + ':' + response.statusMessage);
let responseBody = '';
response.on('data', (chunk) => {
responseBody += chunk;
});
response.on('end', (chunk) => {
console.log('Response body: ' + responseBody);
resolve(responseBody);
});
}, (error) => {
console.error('Error: ' + error);
reject(error);
})
});
/**
* ElasticSearchの指定ドキュメントへ新規インデックス追加
* @param {String} esDomain
* @param {String} esDocIndexName
* @param {String} esDocIndexKey
* @param {Object} esDocValue
* @returns {Promise<Object>}
*/
const putEsDocument = async (esDomain, esDocIndexName, esDocIndexKey, esDocValue) => {
const documentData = _.transform(esDocValue, (result, value, key) => {
const currentLowerKey = _.camelCase(key);
_.assign(result, {
[currentLowerKey]: value
});
}, {});
// ElasticSearchへのリクエスト情報生成
const endpoint = new AWS.Endpoint(esDomain);
const request = new AWS.HttpRequest(endpoint, 'ap-northeast-1');
request.method = 'POST';
request.path += esDocIndexName + '/' + DOC_TYPE_NAME + '/';
request.body = JSON.stringify(documentData);
request.path += esDocValue[esDocIndexKey] + '/';
request.headers['host'] = esDomain;
request.headers['Content-Type'] = 'application/json';
return await _requestToElasticSearch(request);
}
/**
* ElasticSearchの指定ドキュメントの既存インデックス更新
* @param {String} esDomain
* @param {String} esDocIndexName
* @param {String} esDocIndexKey
* @param {Object} esDocValue
* @returns {Promise<Object>}
*/
const updateEsDocument = async (esDomain, esDocIndexName, esDocIndexKey, esDocValue) => {
const documentData = _.transform(esDocValue, (result, value, key) => {
const currentLowerKey = _.camelCase(key);
_.assign(result, {
[currentLowerKey]: value
});
}, {});
// ElasticSearchへのリクエスト情報生成
const endpoint = new AWS.Endpoint(esDomain);
const request = new AWS.HttpRequest(endpoint, 'ap-northeast-1');
request.method = 'POST';
request.path += esDocIndexName + '/' + DOC_TYPE_NAME + '/';
request.body = JSON.stringify(documentData);
request.path += esDocValue[esDocIndexKey] + '/';
request.headers['host'] = esDomain;
request.headers['Content-Type'] = 'application/json';
return await _requestToElasticSearch(request);
}
/**
* ElasticSearchの指定ドキュメントの既存インデックス削除
* @param {String} esDomain
* @param {String} esDocIndexName
* @param {String} keyValue
* @returns {Promise<Object>}
*/
const removeEsDocument = async (esDomain, esDocIndexName, keyValue) => {
// ElasticSearchへのリクエスト情報生成
const endpoint = new AWS.Endpoint(esDomain);
const request = new AWS.HttpRequest(endpoint, 'ap-northeast-1');
request.method = 'DELETE';
request.path += esDocIndexName + '/' + DOC_TYPE_NAME + '/' + keyValue;
request.headers['host'] = esDomain;
request.headers['Content-Type'] = 'application/json';
request.headers['Content-Length'] = Buffer.byteLength(request.body);
return await _requestToElasticSearch(request);
}
module.exports = {
putEsDocument,
updateEsDocument,
removeEsDocument
}実際のプロジェクトに合わせてソースコードは変更してみてください。
まとめ
ElasticSearch と DynamoStream の実装を身につけることで、検索要件への対応幅が大きく広がります。特に ElasticSearch はログ解析に最適ですね。
ただし、本記事でも触れていますが、日本語の検索要件には注意しましょう。
ElasticSearch 、サーバーレスな開発はお気軽にお問い合わせください。
スモールスタート開発支援、サーバーレス・NoSQLのことなら
ラーゲイトまでご相談ください
低コスト、サーバーレスの
モダナイズ開発をご検討なら
 開発 をご希望の企業様
開発 をご希望の企業様 下請け対応可能
Sler企業様からの依頼も歓迎
協業 をご希望の企業様 



ラーゲイトは、世界の最新技術を追い続ける
プロフェッショナルチームです。





