




OpenSearchとDynamoDBストリーム連携!サーバーレスエンジニアがDynamoDBファセット単位でのインデックス登録も解説します!
 2022.11.11
2022.11.11



こんにちは!
今回は OpenSearch と DynamoDBストリームの連携を解説していきます!合わせて DynamoDB ファセット単位でのインデックス登録も解説していきますので、よろしくお願いいたします!
想定する読者
- OpenSearch を利用しているヒト
- OpenSearchを使いこなしたいヒト
- OpenSearchと DynamoDB を連携したいヒト
はじめに
DynamoDB ストリームとは、DynamoDB テーブル内の項目レベルの変更に関するシーケンスを時間順にキャプチャしてくれる機能のことです。使い道として、AWS ドキュメントには以下のような記載があります。
DynamoDB Streams は、ストリーミングレコードをほぼリアルタイムで書き込むため、これらのストリーミングを使用し、内容に基づいてアクションを実行するアプリケーションを構築できます。
引用元:DynamoDB Streams の変更データキャプチャ
この機能を用いて、リアルタイムに OpenSearch にデータを送信することができます。それでは早速連携していきましょう。
ElasticSearchとOpenSearchの違い
OpenSearchは、OSS化されているElasticSearchをフォークして作成されたプロジェクトです。そのため、2022年4月25日現時点では、両者に機能的な乖離はほぼありません。
ただし、今後AWS社がOpenSearchを独自路線でカスタムした場合、仕様的乖離が発生する可能性があります。
OpenSearch + DynamoDB ストリーム
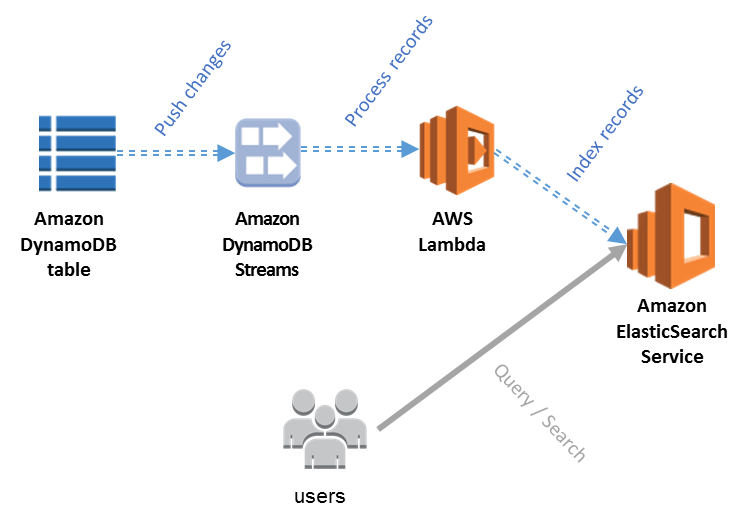
引用元:Indexing Amazon DynamoDB Content with Amazon Elasticsearch Service Using AWS Lambda
連携に必要なのは、以下のリソースとなります。
- DynamoDB
- OpenSearch
- Lambda
- IAMロール(Lambda用)
Lambda は、DynamoDB ストリームのキャプチャをトリガーに実行され OpenSearch にデータを送信するために必要なものとなります。具体的に連携の順序を説明していきます。
- DynamoDB ストリームが変更されたデータをキャプチャ
- DynamoDB ストリームに設定した Lambda が実行される
- Lambda が実行されたことにより、OpenSearch にインデックスが作成される
これにより OpenSearch + DynamoDB の連携が可能となります。
CloudFormation での実装
CloudFormationでは、通常の DynamoDB と OpenSearch 、Lambda の構築に加え、以下のようなコードを追記します。
DynamoDB:ストリームの設定を加える
Resources:
UserTable:
Type: AWS::DynamoDB::Table
Properties:
TableName: 'User'
AttributeDefinitions:
- AttributeName: Id
AttributeType: S
KeySchema:
- AttributeName: Id
KeyType: HASH
ProvisionedThroughput:
ReadCapacityUnits: 1
WriteCapacityUnits: 1
# DynamoDBストリームの設定
StreamSpecification:
StreamViewType: NEW_IMAGEOpenSearch:Lambda 用の IAM ロールをアクセス許可する
Resources:
OpenSearchDomain:
Type: AWS::OpenSearchService::Domain
Properties:
DomainName: 'demo-es'
EngineVersion: '7.9'
ClusterConfig:
InstanceCount: 1
InstanceType: t2.small.opensearch
EBSOptions:
EBSEnabled: true
Iops: 0
VolumeSize: 10
VolumeType: standard
SnapshotOptions:
AutomatedSnapshotStartHour: 0
# OpenSearchのアクセスポリシー
AccessPolicies:
Version: '2012-10-17'
Statement:
- Effect: Allow
Principal:
AWS: !GetAtt DefaultLambdaRole.Arn
Action: 'es:*'
Resource: '*'IAMロール:Lambda 用
Resources:
DefaultLambdaRole:
Type: AWS::IAM::Role
Properties:
RoleName: 'dynamodbstream-defaultlambda-role'
AssumeRolePolicyDocument:
Version: '2012-10-17'
Statement:
- Effect: Allow
Principal:
Service:
- lambda.amazonaws.com
Action:
- sts:AssumeRole
Path: '/'
Policies:
- PolicyName: LambdaRolePolicy
PolicyDocument:
Version: '2012-10-17'
Statement:
- Effect: Allow
Action:
- logs:CreateLogGroup
- logs:CreateLogStream
- logs:PutLogEvents
Resource: arn:aws:logs:*:*:*
- Effect: Allow
Action:
- dynamodb:DescribeStream
- dynamodb:GetRecords
- dynamodb:GetShardIterator
- dynamodb:ListStreams
Resource: '*'
- Effect: Allow
Action:
- es:ESHttpGet
- es:ESHttpPost
- es:ESHttpPut
- es:ESHttpDelete
Resource: '*'Lambda:イベントの追加
以下は serverless framework を用いたテンプレートとなります。
service: OpenSearchWithDynamoStream
provider:
name: aws
runtime: nodejs12.x
stage: ${opt:stage,"dev"}
region: ap-northeast-1
role: DefaultLambdaRole
functions:
HandleEsIndexOnUserTableStream:
handler: src/functions/handleEsIndexOnUserTableStream.handler
name: 'handleEsIndexOnUserTableStream'
description: 'DynamoDB Streams'
memorySize: 128
timeout: 60
# イベントを追加、DynamoDBテーブルを指定
events:
- stream:
arn: !GetAtt UserTable.StreamArn
type: dynamodb
batchSize: 100
enabled: True
startingPosition: LATEST
resources:
- ${file(resources/open-search.yml)}
- ${file(resources/dynamodb.yml)}
- ${file(resources/iam-role.yml)}なお、CloudFormation では以下のような記述になります。
Resources:
LambdaFunction:
Type: "AWS::Lambda::Function"
Properties:
Description: "DynamoDB Streams"
FunctionName: "handleEsIndexOnUserTableStream"
Handler: "src/functions/handleEsIndexOnUserTableStream.handler"
Code:
S3Bucket: !Ref LambdaZipsBucket
S3Key: handleEsIndexOnUserTableStream.zip
MemorySize: 128
Role: !GetAtt IAMRole.Arn
Runtime: "nodejs12.x"
Timeout: 60Lambda の実装は以下のようになります。内容は単純に DynamoDB ストリームからキャプチャされた内容をインデックスに登録しているものとなります。
const AWS = require('aws-sdk');
const _ = require('lodash');
const {putEsDocument, updateEsDocument, removeEsDocument} = require('../services/openSearchService');
const ES_DOMAIN = process.env.ES_DOMAIN;
const ES_INDEX_KEY = 'Id';
const ES_INDEX_NAME = 'user';
exports.handler = async (event, context, callback) => {
const records = event.Records;
const _putEsDocument = _.curry(putEsDocument)(ES_DOMAIN, ES_INDEX_NAME, ES_INDEX_KEY);
const _updateEsDocument = _.curry(updateEsDocument)(ES_DOMAIN, ES_INDEX_NAME, ES_INDEX_KEY);
const _removeEsDocument = _.curry(removeEsDocument)(ES_DOMAIN, ES_INDEX_NAME);
await Promise.all(_.map(records, async r => {
switch (r.eventName) {
case "INSERT":
return await _putEsDocument(AWS.DynamoDB.Converter.unmarshall(r.dynamodb.NewImage));
case "MODIFY":
return await _updateEsDocument(AWS.DynamoDB.Converter.unmarshall(r.dynamodb.NewImage));
case "REMOVE":
return await _removeEsDocument(
_.get(AWS.DynamoDB.Converter.unmarshall(r.dynamodb.Keys), ES_INDEX_KEY)
);
}
}))
};
これにより連携することができます!コメント部分のところが重要なポイントとなりますので、ぜひ参考にしてください。
ファセット単位でのインデックス登録
DynamoDB ではテーブル内にあるデータを分類するために、ファセットを設計します。そのため OpenSearch におけるインデックスの登録は、ファセット単位にしておくのがおすすめです。
OpenSearch はインデックス作成の際にシャード数を設定しますが、あとから変更することができません。そのためテーブル単位でインデックスを作成するよりかは、データの増加を考慮し小さくインデックスを作成するほうが安全となります。
なおファセット単位で行うには、DynamoDB ストリーム用の Lambda のロジックを書き換えてください。
関連記事
- ElasticSearchとDynamoStreamの連携/実装方法を解説!すぐに使える実践テクニックを紹介します😎
- DynamoDB VS ElasticSearch!🤔データアクセス思考なDBMS使い分けの思考方法を解説します!😎
- DynamoDBのファセットを解説😎ファセットを使いこなしてしてDynamoDB設計の上級者へ!
まとめ
OpenSearch + DynamoDBストリーム + Lambda の構成は定番パターンとなります。ぜひ構築時の参考にしてください!
このブログでは、AWS の記事をどんどん公開しておりますので、ご興味のある方は他の記事もご覧いただければと思います。
AWS に関する開発は、お気軽にお問い合わせください。
スモールスタート開発支援、サーバーレス・NoSQLのことなら
ラーゲイトまでご相談ください
低コスト、サーバーレスの
モダナイズ開発をご検討なら
 開発 をご希望の企業様
開発 をご希望の企業様 下請け対応可能
Sler企業様からの依頼も歓迎
協業 をご希望の企業様 



ラーゲイトは、世界の最新技術を追い続ける
プロフェッショナルチームです。





