


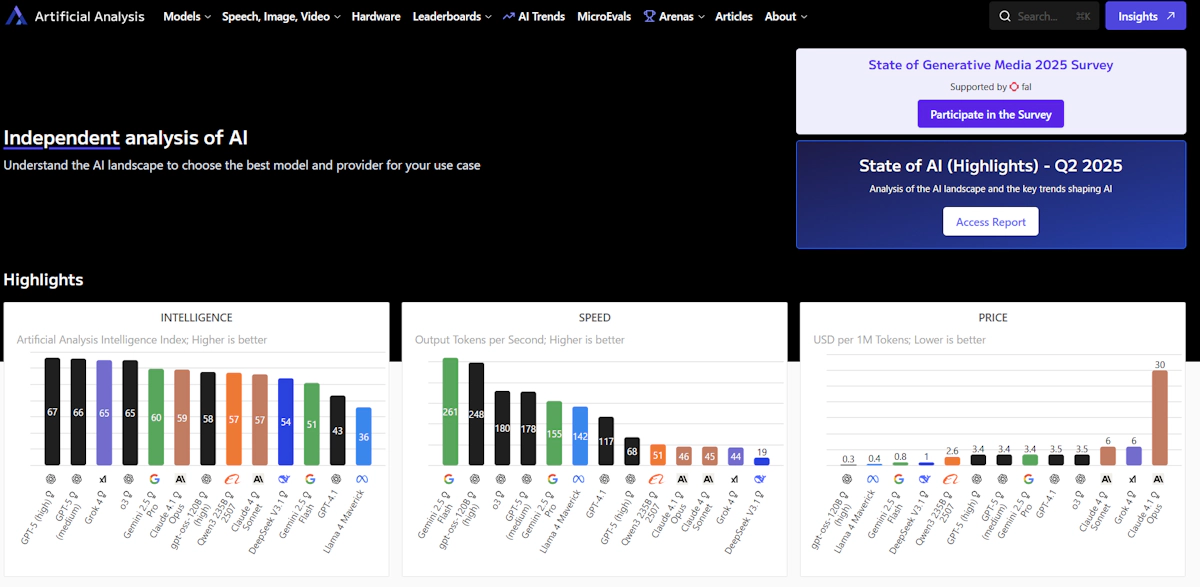
Artificial Analysisとは何か - 独立性がもたらす信頼性
Artificial Analysisは、AIモデル、API、そしてハードウェアシステムの性能を「独立した第三者」として評価し、その結果を可視化するプラットフォームです。
特筆すべきは、評価の透明性にあります。評価データセット、重み付け、温度設定、繰り返し回数、サーバーリージョン、測定頻度まですべて公開されており、再現性と信頼性を担保しています。
従来、AIモデルの選定では各ベンダーが自社に有利な条件で測定したベンチマークを参照せざるを得ませんでした。しかし、Artificial Analysisは「1日8回」という高頻度で実測を行い、「直近72時間のP50値」を代表値として提示することで、リアルタイムに近い性能評価を実現しています。これにより、「カタログスペック」ではなく「実際の性能」に基づいた意思決定が可能になります。
なぜ今、独立評価が必要なのか
AIモデル選定における三つの課題
現在のAIモデル選定において、企業が直面している課題は大きく三つに分類できます。
性能評価の不透明性 | 各ベンダーが独自のベンチマークを公開していますが、測定条件や評価基準がバラバラで、横並びの比較が困難です。例えば、あるモデルはMMLUで高スコアを示しても、実際の長文処理では期待通りの性能を発揮しないケースがあります。 |
|---|---|
コストと性能のトレードオフの見極め | GPT-4oとClaude 3.5 Sonnetのどちらが自社のユースケースにおいてコストパフォーマンスが良いのか、単純な価格表だけでは判断できません。入力トークンと出力トークンの比率、レスポンス速度、そして実際の品質を総合的に評価する必要があります。 |
リアルタイムな性能変動の把握 | APIプロバイダーのインフラ状況により、同じモデルでも時間帯や日によってレスポンス速度が大きく変動することがあります。SLAを守るためには、この変動を把握し、適切なフォールバック戦略を立てる必要があります。 |
独立評価がもたらす価値
Artificial Analysisは、これらの課題に対して「独立性」「透明性」「継続性」という三つの価値を提供します。
引用:Artificial Analysis FAQ 「私たちは、ユーザー(開発者、研究者、事業者)が最適な技術選定と急速に変化するAI動向理解を行えるよう支援することを掲げています」
この理念のもと、すべての評価は統一された基準で実施され、測定環境はGCP us-central1-aで統一されています。また、評価手法の詳細が完全に公開されているため、自社環境での追加検証も可能です。
主要機能の深掘り - エンジニアが注目すべきポイント
Artificial Analysis Intelligence Index (AAII) - 総合知能指標の新基準
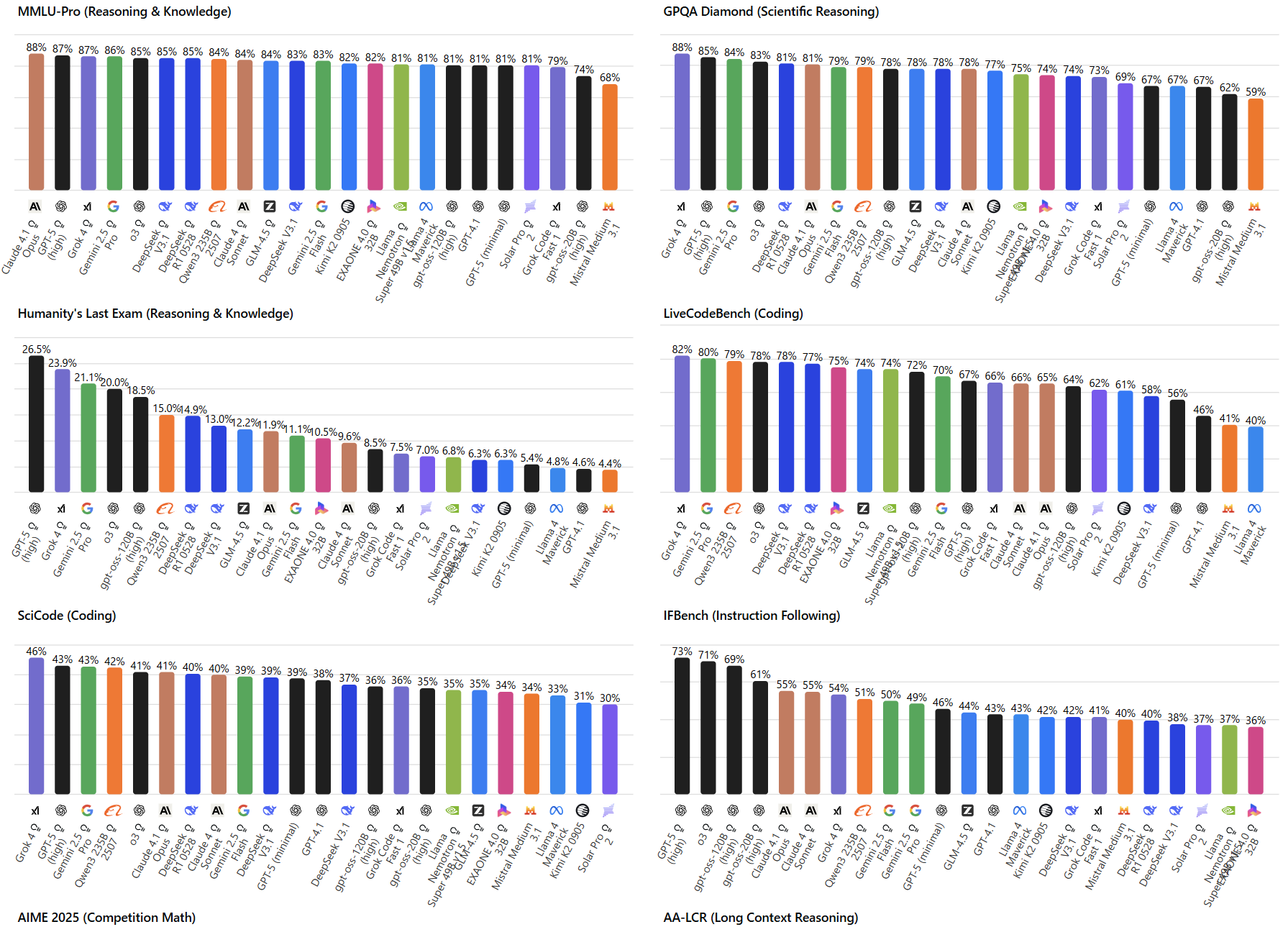
AAIIは、単一のベンチマークに依存せず、MMLU-Pro、HLE、GPQA Diamond、AIME 2025、LiveCodeBench、SciCode、IFBench、長文推論(AA-LCR)の8つの評価を統合した総合指標です。Version 3.0(2025年9月)として公開された最新版では、各評価の重み付けまで明確に定義されています。
特に注目すべきは「AA-LCR(長文コンテキスト推論)」です。10,000から100,000トークンという実務で頻繁に扱う文書サイズに対する情報抽出・合成能力を測定しており、契約書分析や技術文書の要約といった実際のユースケースに直結する評価となっています。
さらに、コーディング能力の評価では「LiveCodeBench」と「SciCode」を採用しています。LiveCodeBenchは競技プログラミングに由来する問題を扱い、SciCodeは科学計算系のタスクを評価対象としており、開発現場での実用性を重視した選定となっています。
System Load Test - ハードウェア投資の意思決定を支援
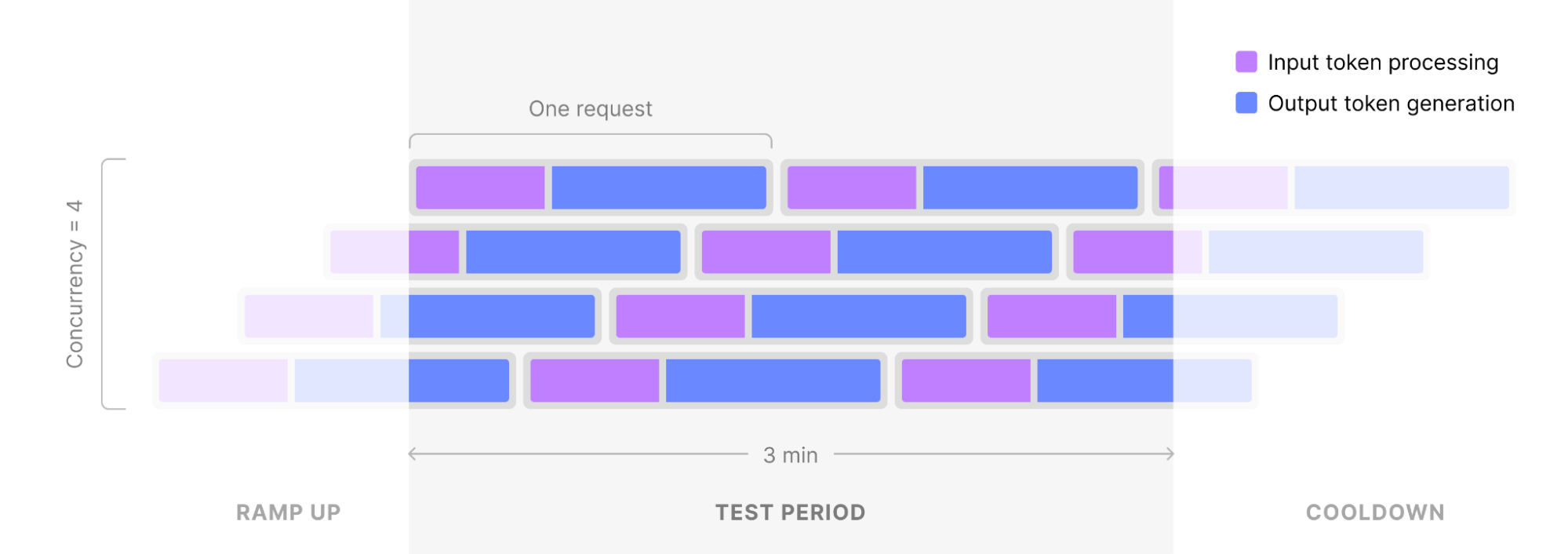
System Load Testは、並行クエリ数を段階的に増やしながらスループットの限界を測定する手法です。1→2→4→...→64→以降64刻みで並列数を増やし、各フェーズで3分間の測定を行います。この評価により、以下の指標を取得できます。
以下の表は、System Load Testで取得可能な主要指標とその活用方法をまとめたものです。
表 System Load Testの主要測定指標と活用シーン
測定指標 | 説明 | 主な活用シーン |
|---|---|---|
システム総出力スループット | 単位時間あたりの処理トークン数 | キャパシティプランニング |
レスポンス率 | 正常応答の割合 | SLA設計・監視閾値設定 |
E2Eレイテンシ | リクエストから完了までの時間 | ユーザー体験の評価 |
クエリ毎の出力速度 | 個別リクエストのTPS | ストリーミング設計の判断 |
これらの指標を活用することで、H200からB200への移行タイミングや、必要なGPUクラスターのサイジングなど、インフラ投資に関する意思決定を定量的に行うことができます。
MicroEvals - 軽量な"バイブチェック"で素早い検証
MicroEvalsは、ユーザーが独自の評価セットを作成し、複数モデルの挙動を素早く比較できる機能です。「バイブチェック」という表現が示すように、厳密なベンチマークではなく、モデルの「クセ」や「傾向」を把握することを目的としています。
実際の活用例として、以下のようなケースが考えられます。
MicroEvalsの実践的な活用方法には以下のような例があります。
- 自社のドメイン特有の専門用語を含むプロンプトでの応答品質確認
- ブランドトーンに合わせた文章生成能力のチェック
- エラーメッセージやユーザーガイドの生成における一貫性の検証
この機能により、PoCフェーズでの高速な仮説検証が可能になり、本格的な評価に入る前にモデルの適合性を判断できます。
実務での活用戦略 - 三つのフェーズで考える
フェーズ1:初期選定における活用
プロジェクトの初期段階では、無料API(1,000リクエスト/日)を活用して、候補となるモデルのスクリーニングを行います。APIからは、モデルID、ベンチマーク結果、価格(入出力/ブレンド)、速度(TPS・TTFT/TTFA)などの情報を取得できます。
特に重要なのは「3:1ブレンド価格」という指標です。これは(3×入力価格 + 出力価格) / 4という計算式で算出され、一般的なユースケースにおける実際のコスト感を反映しています。チャットボットのような対話型アプリケーションでは、ユーザーの入力に対して長い応答を生成することが多いため、この比率が実態に即しています。
フェーズ2:詳細評価と比較検証
%20.png)
候補を絞り込んだ後は、具体的なユースケースに応じた詳細評価を行います。
例えば、コード生成を主目的とする場合はLiveCodeBenchとSciCodeのスコアを重視し、長文ドキュメントの処理が中心となる場合はAA-LCRのスコアを参照します。
この段階で重要なのは、「TTFT(Time To First Token)」と「TPS(Tokens Per Second)」のバランスです。ストリーミング応答を実装する場合、TTFTが短ければユーザーの待機時間を減らせますが、TPSが低いと最終的な応答完了までの時間が長くなります。Artificial Analysisでは、これらの指標を「直近72時間のP50値」として提供しているため、実運用時の性能を予測しやすくなっています。
フェーズ3:運用監視とコスト最適化
本番運用開始後は、APIを活用した継続的な監視体制を構築します。
モデルの性能は時間とともに変化する可能性があります。APIプロバイダーのインフラ増強により改善することもあれば、利用者の増加により劣化することもあります。Artificial AnalysisのAPIを定期的に呼び出し、性能指標の変化を監視することで、以下のような対応が可能になります。
継続監視により実現できる最適化施策の例を挙げます。
- 性能劣化を検知した場合の自動フォールバック
- コスト効率の良い新モデルへの自動切り替え
- 時間帯別のモデル使い分けによるコスト最適化
導入時の注意点と対策
データの解釈における留意事項
Artificial Analysisが提供するデータは非常に有用ですが、いくつかの制約があることを理解しておく必要があります。
まず、測定環境がGCP us-central1-aに固定されているため、他のリージョンから利用する場合はネットワークレイテンシの差を考慮する必要があります。特にTTFTは、ネットワーク遅延の影響を受けやすい指標です。
また、「トークナイザーの差」も重要な考慮事項です。各モデルで使用されるトークナイザーが異なるため、同じテキストでも消費トークン数が変わり、実際のコストに差が生じる可能性があります。Artificial Analysis自身もこの点を認識しており、今後の改善項目として挙げています。
セキュリティとコンプライアンスの観点
企業での導入を検討する際は、以下の点を確認しておく必要があります。
まず、Artificial AnalysisのAPIを利用する場合、自社のシステムから外部サービスへの通信が発生します。セキュリティポリシーによっては、この通信を許可リストに追加する必要があるかもしれません。
次に、MicroEvalsを使用する場合、評価用のプロンプトがArtificial Analysisのサーバーを経由することになります。機密情報を含むプロンプトは使用を避け、汎用的な評価セットを準備することが推奨されます。
他の評価プラットフォームとの比較
LMSYS Chatbot Arenaとの相違点
LMSYS Chatbot Arenaは、人間による二者比較投票でELOレーティングを算出する方式を採用しています。これは対話品質の「好ましさ」を評価する上で優れたアプローチですが、コストや速度といった定量的な指標は提供されません。
一方、Artificial Analysisは「品質」「速度」「価格」を同一基準で評価し、さらにAPIでのデータ提供も行っています。両者は競合というより補完的な関係にあり、用途に応じて使い分けることが重要です。
MLCommons MLPerfとの位置づけ
MLCommons MLPerf Inferenceは、ハードウェアベンダーが自社製品の性能を標準化された方法で測定・公開するためのフレームワークです。これに対し、Artificial AnalysisのSystem Load Testは、エンドユーザーの視点から実際のAPI利用時の性能を測定します。
MLPerfが「理論的な最大性能」を示すのに対し、Artificial Analysisは「実際に体感できる性能」を示すという違いがあります。インフラ投資を検討する際は、両方のデータを参照することで、より確実な意思決定が可能になります。
実践例:あるスタートアップでの活用事例
ここで、架空のスタートアップ企業での活用事例を通じて、Artificial Analysisの実践的な価値を説明します。
この企業は、契約書レビューの自動化サービスを開発していました。当初はGPT-4を利用していましたが、処理コストが想定を上回り、ビジネスモデルの見直しを迫られていました。
Artificial Analysisを活用した結果、以下のような最適化を実現しました。
モデル選定の最適化プロセスと成果を以下に示します。
- AA-LCRスコアを基準に、長文処理に強いモデルを特定
- 3:1ブレンド価格での比較により、コスト効率の良いモデルを選定
- MicroEvalsで法務用語の理解度を独自評価
- 最終的にClaude 3 Haikuを採用し、コストを60%削減しながら品質を維持
さらに、APIを活用した監視システムを構築し、性能劣化時には自動的に上位モデルにフォールバックする仕組みを実装しました。これにより、SLAを守りながらコスト最適化を実現しています。
今後の展望と期待
マルチモーダル評価の拡充

Artificial Analysisは、テキスト生成だけでなく、画像、動画、音声のアリーナも提供しています。これらの領域でも、ELOレーティングによる相対評価が可能です。
今後、マルチモーダルAIの普及に伴い、これらの評価がより重要になることが予想されます。例えば、Vision-Language Modelの評価や、音声認識・生成の品質評価など、より複雑な評価基準が必要になるでしょう。
エージェント評価への対応
AIエージェントの実用化が進む中、単一のプロンプト-レスポンスではなく、複数ステップにわたる対話やタスク実行の評価が求められるようになります。
Artificial Analysisは、有料レポートで「Enterprise Agents」の分析を提供していることから、この領域への関心の高さがうかがえます。将来的には、エージェントの自律性や問題解決能力を評価する新たな指標が追加される可能性があります。
まとめ
Artificial Analysisは、AIモデル選定における「勘と経験」から「データドリブン」への転換を促すプラットフォームです。独立した第三者による透明性の高い評価により、ベンダーロックインを避けながら、最適なモデル選定が可能になります。
特に印象的なのは、評価手法の完全な公開です。ブラックボックス化せず、すべての情報を開示することで、ユーザーが自身で検証・判断できる環境を提供しています。これは、エンジニアリングの本質である「再現性」と「検証可能性」を重視する姿勢の表れだと感じます。
実務での活用においては、単にベンチマークスコアを比較するだけでなく、自社のユースケースに合わせた評価基準を設定し、継続的にモニタリングすることが重要です。MicroEvalsやAPIを活用することで、この一連のプロセスを効率化できます。
AIの進化スピードが加速する中、「どのモデルを選ぶか」という意思決定の重要性はますます高まっています。Artificial Analysisは、この意思決定を支援する強力なツールとして、今後さらに存在感を増していくでしょう。エンジニアリングマネージャーとして、このようなツールを戦略的に活用し、チームの生産性向上とコスト最適化を両立させていくことが、これからのAI時代における重要な責務だと考えています。
























