


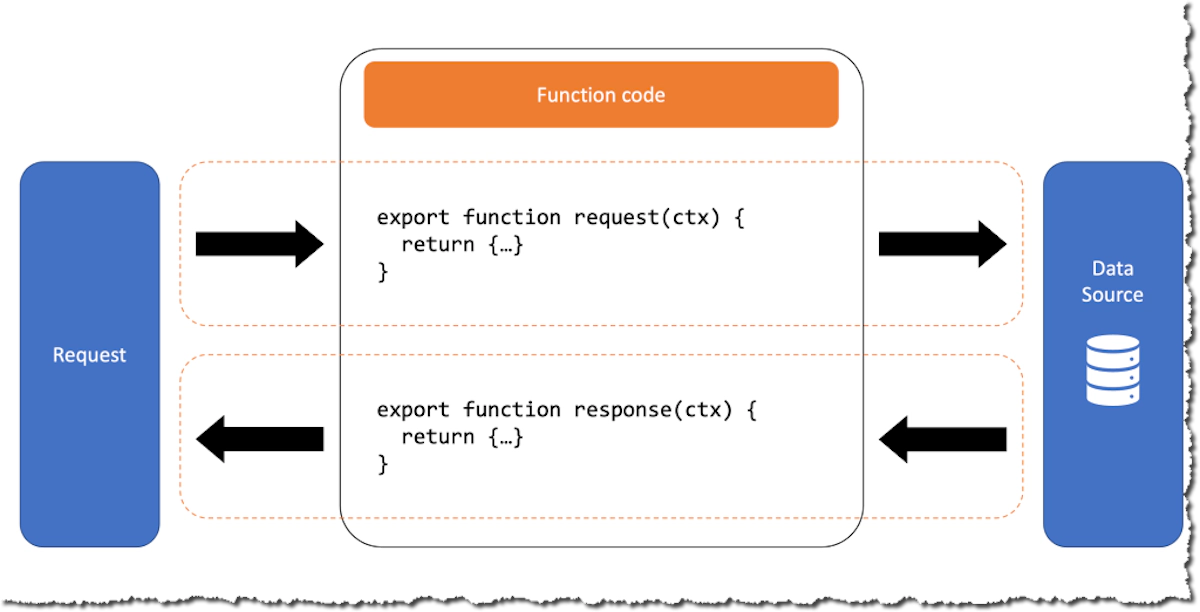
マネージドリゾルバーが生まれた背景と現在の立ち位置
AWS AppSyncのマネージドリゾルバーは、GraphQLリクエストを各種データソースに直接マッピングする仕組みです。従来のアーキテクチャでは、フロントエンドからバックエンドAPIを呼び出す際に、必ずLambda関数のような中間層を経由する必要がありました。しかし、この方式には「コールドスタート」による遅延や、不要なコンピューティングコストという課題があったんですね。
マネージドリゾルバーを使うことで、これらの課題を解決できます。つまり、GraphQLフィールドごとに適切なAWSサービスへ直接クエリやコマンドを発行することで、余計な「サーバーレス」実行のオーバーヘッドを回避できるわけです。
VTLとJavaScriptリゾルバーの使い分け戦略
VTL(Velocity Template Language)の特徴と利点
VTLは、AWS AppSyncの初期から提供されているテンプレート言語です。JavaやApacheプロジェクトで広く使われてきた実績があり、シンプルなデータ変換には非常に効率的です。
VTLを選択すべきケースとして、以下のような状況が挙げられます。
- 単純なCRUD操作のみを行う場合
- 既存のVTLテンプレート資産を活用したい場合
- チーム内にVTLの知見が蓄積されている場合
JavaScript Resolverの登場による変化
2022年11月、AWSはAppSync JavaScript resolversを発表しました。これにより、開発者はより馴染みのあるJavaScriptでリゾルバーロジックを記述できるようになりました。
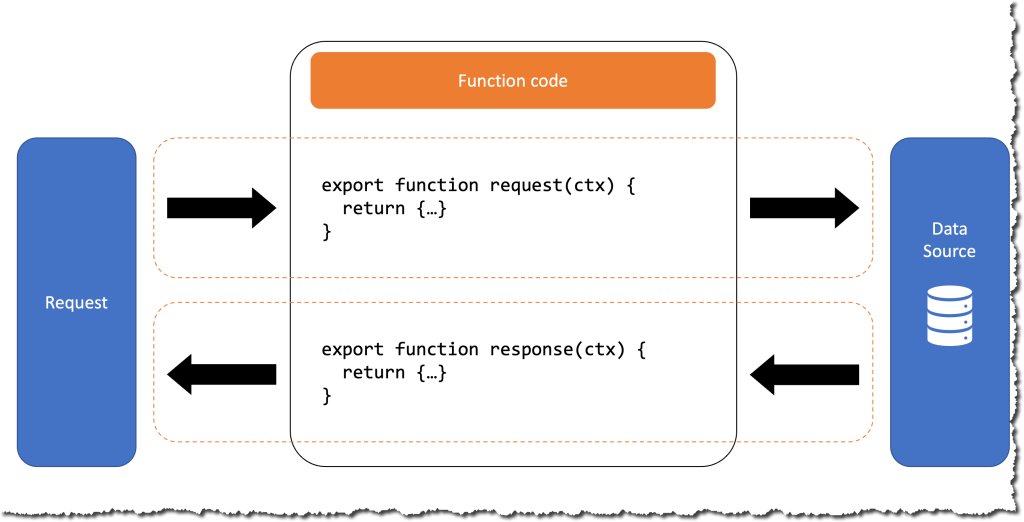
JavaScriptリゾルバーの主な利点は以下の通りです。
- TypeScriptによる型安全な開発が可能
- IDEのサポートが充実(自動補完、リファクタリング機能など)
- npmパッケージの一部機能が利用可能(制限あり)
- デバッグやテストがより容易
個人的には、新規プロジェクトではJavaScriptリゾルバーを採用することが多いですね。特にTypeScriptで統一的に開発できる点は、チーム開発において大きなメリットだと感じています。
DynamoDBデータソースの実装パターン
基本的なCRUD操作の実装
DynamoDBは、AppSyncと最も相性の良いデータソースの一つです。NoSQLの柔軟性と「サーバーレス」アーキテクチャの親和性により、スケーラブルなAPIを簡単に構築できます。
以下は、TodoアプリケーションのGraphQLスキーマ例です。
type Todo {
id: ID!
title: String!
description: String
completed: Boolean!
createdAt: AWSDateTime!
}
input CreateTodoInput {
title: String!
description: String
completed: Boolean! = false
}
type Query {
getTodo(id: ID!): Todo
listTodos(limit: Int): [Todo]
}
type Mutation {
createTodo(input: CreateTodoInput!): Todo
updateTodo(id: ID!, title: String, description: String, completed: Boolean): Todo
deleteTodo(id: ID!): ID
}VTLによるリゾルバー実装
新規Todo作成のリクエストマッピングテンプレート(VTL)を見てみましょう。
#if(!$ctx.args.input.id)
$util.qr($ctx.args.input.put("id", $util.autoId()))
#end
$util.qr($ctx.args.input.put("createdAt", $util.time.nowISO8601()))
{
"version": "2018-05-29",
"operation": "PutItem",
"key": {
"id": $util.dynamodb.toDynamoDBJson($ctx.args.input.id)
},
"attributeValues": $util.dynamodb.toMapValuesJson($ctx.args.input)
}このテンプレートでは、$util.autoId()でUUIDを自動生成し、$util.time.nowISO8601()で現在日時を付与しています。こういった便利なユーティリティ関数が用意されているのもVTLの特徴です。
JavaScriptリゾルバーでの実装
同じ処理をJavaScriptリゾルバーで実装すると、以下のようになります。
import { util } from '@aws-appsync/utils'
export function request(ctx) {
const input = ctx.args.input
if (!input.id) {
input.id = util.autoId()
}
input.createdAt = util.time.nowISO8601()
return {
operation: 'PutItem',
key: util.dynamodb.toMapValues({ id: input.id }),
attributeValues: util.dynamodb.toMapValues(input)
}
}
export function response(ctx) {
if (ctx.error) {
util.error(ctx.error.message, ctx.error.type)
}
return ctx.result
}JavaScriptの方が直感的に理解しやすいと感じる方も多いのではないでしょうか。特に、条件分岐やループ処理が複雑になる場合は、JavaScriptの方が保守性が高くなる傾向があります。
Lambdaデータソースの活用シーン
Lambdaを使うべき場合と避けるべき場合
Lambdaデータソースは柔軟性が高い反面、パフォーマンスとコストの観点から慎重に使う必要があります。私の経験では、以下のようなケースでLambdaが適切です。
- 外部APIとの連携(決済サービス、メール送信など)
- 複雑なビジネスロジックの実装
- 既存システムとの統合(レガシーDBへのアクセスなど)
一方で、単純なCRUD操作にLambdaを使うのは避けるべきです。「サーバーレス」アーキテクチャだからといって、すべてをLambdaで実装するのは、かえってパフォーマンスの低下を招きます。
Lambdaリゾルバーの実装例
外部の天気情報APIを呼び出すLambda関数の例を見てみましょう。
import { AppSyncResolverEvent } from 'aws-lambda'
export const handler = async (event: AppSyncResolverEvent) => {
const { location } = event.arguments
try {
// 外部APIを呼び出し
const response = await fetch(`https://api.weather.com/v1/location/${location}`)
const data = await response.json()
// GraphQLスキーマに合わせて変換
return {
location: data.name,
temperature: data.main.temp,
condition: data.weather[0].main
}
} catch (error) {
console.error('Weather API error:', error)
throw new Error('Failed to fetch weather data')
}
}Lambda関数のベストプラクティス
Lambda関数を使う際の重要なポイントをまとめます。
- コールドスタート対策として、関数のメモリサイズを適切に設定
- 環境変数で設定値を管理し、ハードコーディングを避ける
- エラーハンドリングを適切に実装し、GraphQLエラーとして返す
- CloudWatch Logsでの監視とアラート設定を忘れない
RDS(Aurora)データソースの実装
Aurora Serverlessとの統合
RDSデータソース、特に「Aurora Serverless」との統合は、既存のリレーショナルデータをGraphQL APIとして公開する際に威力を発揮します。Data APIを有効にすることで、VPCの設定なしにAppSyncから直接SQLを実行できるんです。
以下の表は、RDSデータソースとDynamoDBの使い分け基準をまとめたものです。
表 RDSとDynamoDBの使い分け基準
観点 | RDS (Aurora) | DynamoDB |
|---|---|---|
データモデル | リレーショナル(正規化) | NoSQL(非正規化) |
トランザクション | ACID完全準拠 | 条件付きトランザクション |
クエリの柔軟性 | SQL(JOIN、集計関数) | キー条件、フィルタ式 |
スケーラビリティ | 垂直スケール中心 | 水平スケール |
コスト | 常時起動(Serverless v2は自動スケール) | 完全従量課金 |
SQLステートメントの実装パターン
AppSyncでは、1つのリゾルバーで最大2つのSQLステートメントを実行できます。これを活用した実装例を見てみましょう。
{
"version": "2018-05-29",
"statements": [
"INSERT INTO Books (isbn13, title, author, published_year) VALUES (:isbn13, :title, :author, :year)",
"SELECT isbn13, title, author, published_year FROM Books WHERE isbn13 = :isbn13"
],
"variableMap": {
":isbn13": $util.toJson($ctx.args.book.isbn13),
":title": $util.toJson($ctx.args.book.title),
":author": $util.toJson($ctx.args.book.author),
":year": $util.toJson($ctx.args.book.publishedYear)
}
}この方法により、INSERTの直後に挿入したレコードを取得して返すことができます。トランザクション的な処理が必要な場合は、Auroraのトランザクション機能と組み合わせることも可能です。
OpenSearchデータソースによる高度な検索
全文検索の実装
OpenSearchは、全文検索や複雑な検索条件の実装に最適です。特に、以下のような要件がある場合に選択を検討します。
- キーワードによる全文検索
- ファセット検索(絞り込み検索)
- 地理空間検索
- スコアリングによる関連度順のソート
Multi-match検索の実装例
複数フィールドを対象にした検索クエリの実装例です。
{
"version": "2017-02-28",
"operation": "GET",
"path": "/post/_search",
"params": {
"body": {
"from": 0,
"size": 50,
"query": {
"multi_match": {
"query": "$ctx.args.keyword",
"fields": ["title^2", "content", "author"],
"type": "best_fields"
}
},
"highlight": {
"fields": {
"title": {},
"content": {"fragment_size": 150}
}
}
}
}
}title^2のように重み付けを行うことで、タイトルにマッチした結果を優先的に返すことができます。また、highlightを使えば、検索結果のハイライト表示も簡単に実現できます。
HTTPエンドポイントデータソースの活用
既存REST APIの統合パターン
既存のREST APIをGraphQLでラップする場合、HTTPエンドポイントデータソースが便利です。ただし、現時点ではインターネットからアクセス可能なエンドポイントのみ対応している点に注意が必要です。
HTTPデータソースの実装で気をつけるべきポイントは以下の通りです。
- エラーハンドリングを適切に実装する
- タイムアウトの設定を適切に行う
- レート制限を考慮したリトライ処理を実装する
実装例:外部APIとの連携
{
"version": "2018-05-29",
"method": "POST",
"resourcePath": "/api/v1/users",
"params": {
"headers": {
"Content-Type": "application/json",
"Authorization": "Bearer $ctx.request.headers.authorization"
},
"body": $util.toJson($ctx.args.input)
}
}レスポンステンプレートでは、HTTPステータスコードによる分岐処理を実装します。
#if($ctx.error)
$util.error($ctx.error.message, $ctx.error.type)
#end
#if($ctx.result.statusCode == 200)
$ctx.result.body
#else
$utils.appendError($ctx.result.body, "$ctx.result.statusCode")
#endCloudFormationとCDKによる構築自動化
CDK(TypeScript)での実装例
実際のプロジェクトでは、インフラのコード化が必須です。CDKを使った実装例を見てみましょう。
import * as cdk from 'aws-cdk-lib'
import * as appsync from 'aws-cdk-lib/aws-appsync'
import * as dynamodb from 'aws-cdk-lib/aws-dynamodb'
export class AppSyncStack extends cdk.Stack {
constructor(scope: Construct, id: string, props?: cdk.StackProps) {
super(scope, id, props)
// GraphQL API作成
const api = new appsync.GraphqlApi(this, 'TodoApi', {
name: 'TodoApi',
schema: appsync.Schema.fromAsset('schema.graphql'),
authorizationConfig: {
defaultAuthorization: {
authorizationType: appsync.AuthorizationType.API_KEY,
apiKeyConfig: {
expires: cdk.Expiration.after(cdk.Duration.days(365))
}
}
},
xrayEnabled: true, // X-Ray統合を有効化
logConfig: {
fieldLogLevel: appsync.FieldLogLevel.ALL,
excludeVerboseContent: false
}
})
// DynamoDBテーブル作成
const todoTable = new dynamodb.Table(this, 'TodoTable', {
partitionKey: {
name: 'id',
type: dynamodb.AttributeType.STRING
},
billingMode: dynamodb.BillingMode.PAY_PER_REQUEST,
stream: dynamodb.StreamViewType.NEW_AND_OLD_IMAGES,
pointInTimeRecovery: true
})
// データソース追加
const todoDS = api.addDynamoDbDataSource('TodoDataSource', todoTable)
// JavaScriptリゾルバー設定
todoDS.createResolver({
typeName: 'Query',
fieldName: 'getTodo',
runtime: appsync.FunctionRuntime.JS_1_0_0,
code: appsync.Code.fromAsset('resolvers/getTodo.js')
})
}
}CloudFormationテンプレートによる定義
CloudFormationを直接使う場合の例も示しておきます。
Resources:
TodoApi:
Type: AWS::AppSync::GraphQLApi
Properties:
Name: TodoApi
AuthenticationType: API_KEY
LogConfig:
CloudWatchLogsRoleArn: !GetAtt AppSyncServiceRole.Arn
FieldLogLevel: ALL
TodoDataSource:
Type: AWS::AppSync::DataSource
Properties:
ApiId: !GetAtt TodoApi.ApiId
Name: TodoDataSource
Type: AMAZON_DYNAMODB
ServiceRoleArn: !GetAtt AppSyncServiceRole.Arn
DynamoDBConfig:
TableName: !Ref TodoTable
AwsRegion: !Ref AWS::Region
GetTodoResolver:
Type: AWS::AppSync::Resolver
Properties:
ApiId: !GetAtt TodoApi.ApiId
TypeName: Query
FieldName: getTodo
DataSourceName: !GetAtt TodoDataSource.Name
Runtime:
Name: APPSYNC_JS
RuntimeVersion: 1.0.0
Code: |
export function request(ctx) {
return {
operation: 'GetItem',
key: util.dynamodb.toMapValues({ id: ctx.args.id })
}
}
export function response(ctx) {
return ctx.result
}パフォーマンス最適化とベストプラクティス
キャッシング戦略
AppSyncには、レスポンスキャッシュ機能が組み込まれています。適切に設定することで、データソースへの負荷を軽減し、レスポンス時間を大幅に改善できます。
キャッシングを設定する際のポイントは以下の通りです。
- TTLは更新頻度に応じて適切に設定する
- ユーザー固有のデータには
@aws_authディレクティブを使用 - キャッシュキーの設計を慎重に行う
type Query {
getPopularPosts: [Post] @aws_api_cache(ttl: 300)
getUserPosts(userId: ID!): [Post] @aws_api_cache(ttl: 60)
}バッチリゾルバーによる最適化
N+1問題を回避するため、バッチリゾルバーの活用が重要です。例えば、投稿一覧を取得する際に、各投稿の著者情報も合わせて取得する場合です。
export function request(ctx) {
const userIds = ctx.source.items.map(item => item.userId)
return {
operation: 'BatchGetItem',
tables: {
UsersTable: {
keys: userIds.map(id => util.dynamodb.toMapValues({ id })),
consistentRead: true
}
}
}
}エラーハンドリングのパターン
GraphQLでは、部分的な成功を返すことができます。これを活用したエラーハンドリングのパターンを実装しましょう。
export function response(ctx) {
const errors = []
const results = []
ctx.result.forEach((item, index) => {
if (item.error) {
errors.push({
message: item.error.message,
path: [`users`, index]
})
results.push(null)
} else {
results.push(item.data)
}
})
if (errors.length > 0) {
util.appendError(errors)
}
return results
}実運用での課題と対処法
モニタリングとロギング
本番環境では、適切なモニタリング設定が不可欠です。AppSyncは「CloudWatch」と統合されており、以下のメトリクスを監視できます。
モニタリングすべき重要なメトリクスは以下の通りです。
- 4XXError(クライアントエラー)
- 5XXError(サーバーエラー)
- Latency(レスポンス時間)
- GraphQLErrors(GraphQLレベルのエラー)
AWS X-Rayとの統合を有効にすることで、リクエストの詳細なトレースも可能になります。
セキュリティ考慮事項
AppSyncのセキュリティ設定で特に重要なポイントをまとめます。
表 AppSyncセキュリティチェックリスト
項目 | 推奨設定 | 理由 |
|---|---|---|
認証方式 | Cognito User Pools + API Key併用 | 本番環境では必ず認証を実装 |
フィールドレベル認証 | @aws_authディレクティブ使用 | きめ細かいアクセス制御 |
WAF統合 | 有効化 | DDoS攻撃やSQLインジェクション対策 |
VPC内リソースアクセス | VPCエンドポイント使用 | プライベート接続の確保 |
データ暗号化 | 転送時・保管時ともに有効 | コンプライアンス要件対応 |
コスト最適化のアプローチ
「サーバーレス」だからといって、コストを無視してはいけません。AppSyncのコストは主に以下の要素で決まります。
- リクエスト数
- データ転送量
- リアルタイム接続時間(サブスクリプション)
- キャッシュの使用量
コスト削減のための具体的な施策は以下の通りです。
- 不要なフィールドを取得しない(GraphQLの特性を活かす)
- キャッシングを積極的に活用
- バッチ処理でリクエスト数を削減
- CloudWatch Logsの保存期間を適切に設定
SQSとの連携による非同期処理パターン
SQSをデータソースとして活用する際の考慮点
現時点でAppSyncにはSQSの直接的なデータソースサポートはありませんが、Lambdaリゾルバーを介してSQSと連携することで、非同期処理パターンを実装できます。
import { SQSClient, SendMessageCommand } from '@aws-sdk/client-sqs'
const sqsClient = new SQSClient({})
export async function handler(event) {
const { input } = event.arguments
// SQSにメッセージを送信
const command = new SendMessageCommand({
QueueUrl: process.env.QUEUE_URL,
MessageBody: JSON.stringify({
action: 'PROCESS_ORDER',
data: input
}),
MessageGroupId: input.customerId // FIFOキューの場合
})
const result = await sqsClient.send(command)
// 即座にレスポンスを返す
return {
id: result.MessageId,
status: 'PROCESSING',
message: 'Your order is being processed'
}
}このパターンを使うことで、重い処理を非同期化し、ユーザー体験を向上させることができます。
まとめ
AWS AppSyncのマネージドリゾルバーを使いこなすことで、「サーバーレス」GraphQL APIを効率的に構築できます。本記事で紹介した各データソースの特性を理解し、プロジェクトの要件に応じて適切に使い分けることが重要です。
最後に、技術選定の際の判断基準をまとめておきます。
表 データソース選定クイックリファレンス
ユースケース | 推奨データソース | 理由 |
|---|---|---|
シンプルなCRUD | DynamoDB | 低レイテンシ、完全マネージド |
複雑なトランザクション | RDS (Aurora) | ACID準拠、SQLの柔軟性 |
全文検索 | OpenSearch | 高度な検索機能 |
外部API連携 | HTTP or Lambda | 既存システムとの統合 |
非同期処理 | Lambda + SQS | スケーラブルな処理 |
VTLとJavaScriptリゾルバーについても、チームのスキルセットと要件に応じて選択しましょう。個人的には、新規プロジェクトではJavaScriptリゾルバーをベースにし、パフォーマンスクリティカルな部分のみVTLで最適化するアプローチがバランスが良いと感じています。
技術は日々進化していますが、本質的に重要なのは「ビジネス価値を最速で提供すること」です。AppSyncのマネージドリゾルバーは、その実現を強力にサポートしてくれるツールです。皆さんのプロジェクトでも、ぜひ活用してみてください。
























