


生成AI戦略における新たな選択肢の台頭
エンタープライズ企業の生成AI導入が本格化する中、モデル選定における判断基準が大きく変化してきています。従来は性能とコストのトレードオフが主要な検討事項でしたが、最近ではオープンソース化、カスタマイズ性、データガバナンスといった要素が重要性を増しています。
2025年1月にDeepSeekが発表したDeepSeek-V3.1は、この変化を象徴する存在といえます。671Bパラメータという巨大なモデルサイズでありながら、推論コストは入力トークンあたり$0.27/M、出力トークンあたり$2.19/Mという破格の価格設定を実現しています。これはOpenAIのGPT-4oやAnthropicのClaude 3.5 Sonnetと比較して、約10分の1から20分の1のコストです。

同時期に、Amazon Bedrockは企業向けAIプラットフォームとしての地位を確立し、複数の基盤モデルを統合的に管理できる環境を提供しています。2024年11月にはカスタムモデルのインポート機能がプレビュー版として発表され、エンタープライズ企業が独自のモデル戦略を展開できる基盤が整いつつあります。
DeepSeek-V3.1の技術的革新性
DeepSeek-V3.1の最大の特徴は、「Mixture of Experts(MoE)」アーキテクチャの採用による計算効率の劇的な改善にあります。このアーキテクチャにより、671Bという巨大なパラメータ数を持ちながら、実際の推論時には37Bのアクティブパラメータのみを使用します。
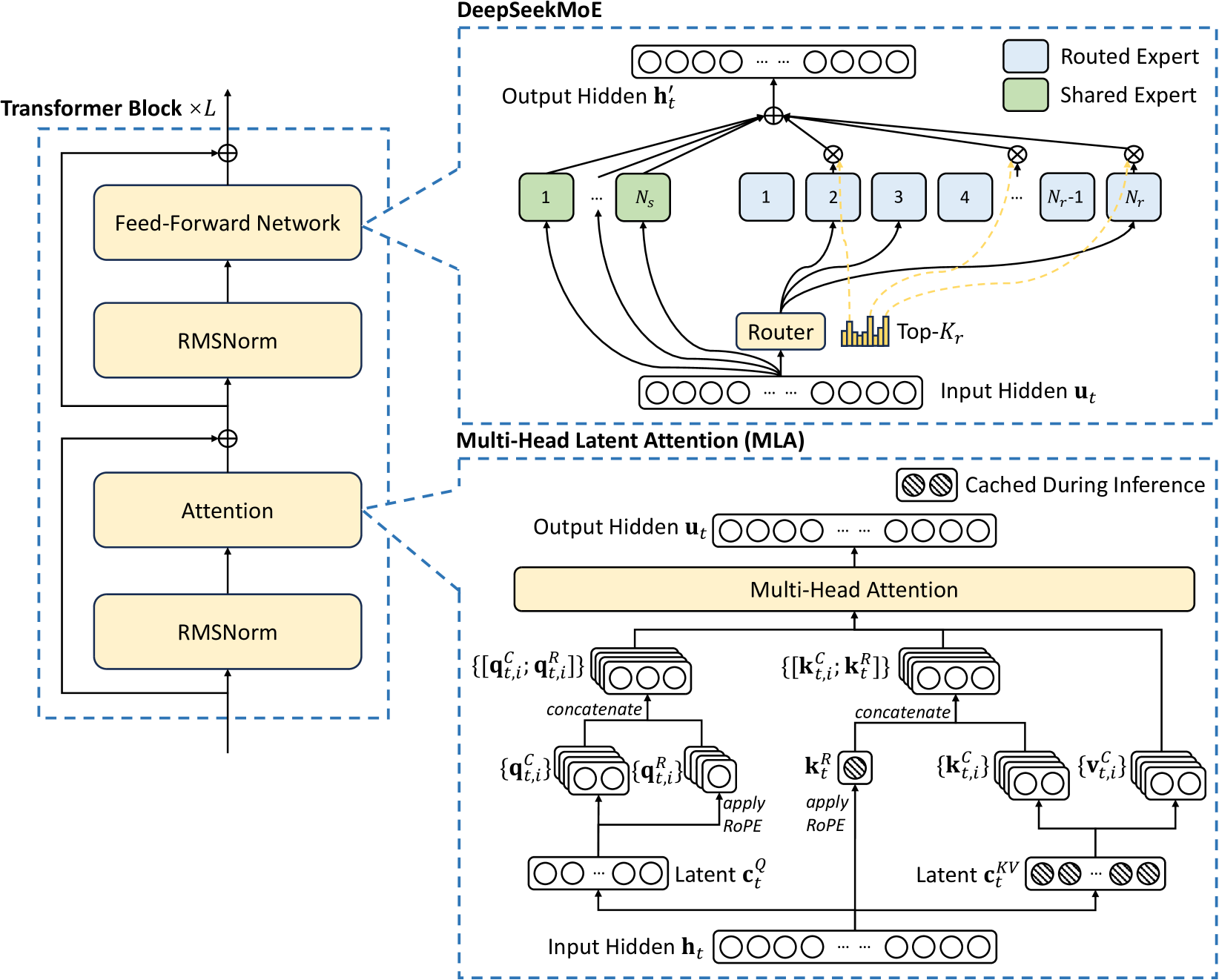
DeepSeek-V3.1の主要な技術仕様を以下の表にまとめました。
表 DeepSeek-V3.1の主要技術仕様
項目 | 仕様 | 備考 |
|---|---|---|
総パラメータ数 | 671B | 業界最大級のオープンソースモデル |
アクティブパラメータ | 37B | MoEにより推論時の計算量を削減 |
コンテキスト長 | 128Kトークン | 長文処理に対応 |
トレーニングトークン数 | 14.8T | 多様なデータソースから学習 |
ライセンス | MITライセンス | 商用利用可能 |
推論コスト(入力) | $0.27/Mトークン | GPT-4oの約1/10 |
推論コスト(出力) | $2.19/Mトークン | Claude 3.5 Sonnetの約1/20 |
この表が示すように、DeepSeek-V3.1は技術的な革新性とコスト効率を両立させており、企業のAI戦略に新たな選択肢を提供しています。
DeepThink機能による高度な推論
DeepSeek-V3.1には「DeepThink」と呼ばれる推論機能が実装されています。これはOpenAIのo1やAnthropicのClaude 4 Sonnetの拡張思考機能と同様に、モデルが回答前に段階的な思考プロセスを経ることで、複雑な問題解決能力を向上させる仕組みです。
DeepThink機能を活用する際の実装例を以下に示します。
interface DeepThinkConfig {
enableDeepThink: boolean;
thinkingBudget?: number;
outputFormat?: 'detailed' | 'summary';
}
class DeepSeekInference {
private modelEndpoint: string;
private config: DeepThinkConfig;
constructor(endpoint: string, config: DeepThinkConfig) {
this.modelEndpoint = endpoint;
this.config = config;
}
async generateWithThinking(prompt: string): Promise<{
thinking: string;
response: string;
}> {
const requestBody = {
prompt: prompt,
max_tokens: 4096,
temperature: 0.7,
deep_think: {
enabled: this.config.enableDeepThink,
budget_tokens: this.config.thinkingBudget || 2048,
output_format: this.config.outputFormat || 'detailed'
}
};
const response = await fetch(this.modelEndpoint, {
method: 'POST',
headers: {
'Content-Type': 'application/json',
},
body: JSON.stringify(requestBody)
});
const result = await response.json();
return {
thinking: result.thinking_process || '',
response: result.generated_text
};
}
}このコード例では、DeepThink機能を有効化し、思考プロセスと最終的な回答を分離して取得できるような実装を示しています。企業の実装においては、思考プロセスをログとして保存し、モデルの判断根拠を監査可能にすることが重要です。
ベンチマーク性能の分析
DeepSeek-V3.1の性能を客観的に評価するため、主要なベンチマークスコアを他の代表的なモデルと比較してみます。
モデル | MMLU | HumanEval | GPQA | コスト効率指数 |
|---|---|---|---|---|
DeepSeek-V3.1 | 88.5 | 89.0 | 61.6 | 100 |
GPT-4o | 87.2 | 90.2 | 53.6 | 12 |
Claude 3.5 Sonnet | 88.3 | 92.0 | 59.4 | 8 |
Gemini 2.5 Pro | 85.9 | 84.1 | 46.2 | 15 |
この比較表から、DeepSeek-V3.1が主要ベンチマークで競合モデルと同等以上の性能を示しながら、圧倒的なコスト優位性を持っていることが分かります。特にGPQA(Graduate-level Google-Proof Q&A)のような高度な推論を要求するタスクで優れた性能を示している点は注目に値します。
Amazon Bedrockエコシステムへの統合戦略
Amazon Bedrockは、複数の基盤モデルを統一的なAPIで利用できるマネージドサービスとして、エンタープライズ企業のAI導入を加速させています。現在、Anthropic、Cohere、AI21 Labs、Stability AI、Meta、Mistral AIなど、主要なモデルプロバイダーとの提携により、多様なユースケースに対応可能な環境を提供しています。
DeepSeek-V3.1のようなオープンソースモデルをBedrockエコシステムに統合することで、企業は以下のようなメリットを享受できます。
カスタムモデルインポート機能の活用
Amazon Bedrockのカスタムモデルインポート機能を使用することで、DeepSeek-V3.1をBedrock環境で利用可能にできる可能性があります。この機能は現在プレビュー段階ですが、以下のような手順で実装を検討できます。
import { BedrockRuntimeClient, InvokeModelCommand } from "@aws-sdk/client-bedrock-runtime";
import { S3Client, PutObjectCommand } from "@aws-sdk/client-s3";
class CustomModelIntegration {
private bedrockClient: BedrockRuntimeClient;
private s3Client: S3Client;
constructor(region: string) {
this.bedrockClient = new BedrockRuntimeClient({ region });
this.s3Client = new S3Client({ region });
}
async uploadModelToS3(
modelPath: string,
bucketName: string,
keyPrefix: string
): Promise<void> {
// モデルファイルをS3にアップロード
const modelBuffer = await this.readModelFile(modelPath);
const uploadParams = {
Bucket: bucketName,
Key: `${keyPrefix}/deepseek-v3.1/model.safetensors`,
Body: modelBuffer,
ContentType: 'application/octet-stream'
};
await this.s3Client.send(new PutObjectCommand(uploadParams));
}
async registerCustomModel(
modelName: string,
s3Uri: string,
roleArn: string
): Promise<string> {
// Bedrockにカスタムモデルを登録
const registrationParams = {
modelName: modelName,
modelSource: {
s3Uri: s3Uri
},
executionRole: roleArn,
modelConfiguration: {
framework: 'PYTORCH',
frameworkVersion: '2.0',
modelArchitecture: 'DEEPSEEK_V3'
}
};
// 実際のAPI呼び出しは、Bedrockの正式サポートを待つ必要があります
console.log('Model registration params:', registrationParams);
// モデルIDを返す(仮の実装)
return `custom-${modelName}-${Date.now()}`;
}
async invokeCustomModel(
modelId: string,
prompt: string,
parameters?: any
): Promise<string> {
const input = {
modelId: modelId,
body: JSON.stringify({
prompt: prompt,
max_tokens: parameters?.maxTokens || 1024,
temperature: parameters?.temperature || 0.7,
top_p: parameters?.topP || 0.9,
deep_think: parameters?.enableDeepThink || false
}),
contentType: 'application/json',
accept: 'application/json'
};
const command = new InvokeModelCommand(input);
const response = await this.bedrockClient.send(command);
const responseBody = JSON.parse(
new TextDecoder().decode(response.body)
);
return responseBody.generated_text;
}
private async readModelFile(path: string): Promise<Buffer> {
// モデルファイルの読み込み処理(簡略化)
const fs = await import('fs/promises');
return fs.readFile(path);
}
}このコード例では、DeepSeek-V3.1モデルをS3にアップロードし、Bedrockのカスタムモデルとして登録する流れを示しています。実際の実装では、モデルのサイズやフォーマット、必要なランタイム環境などの詳細な検討が必要です。
SageMakerとの連携による柔軟な展開
Amazon Bedrockが正式にDeepSeek-V3.1をサポートするまでの間、Amazon SageMakerを活用した展開戦略も検討できます。SageMakerのエンドポイントをBedrockと連携させることで、統一的なAPIインターフェースを維持しながら、カスタムモデルを利用できます。
SageMakerエンドポイントの構築例を以下に示します。
import { SageMakerRuntimeClient, InvokeEndpointCommand } from "@aws-sdk/client-sagemaker-runtime";
interface DeepSeekEndpointConfig {
endpointName: string;
region: string;
maxRetries?: number;
timeout?: number;
}
class DeepSeekSageMakerEndpoint {
private sagemakerClient: SageMakerRuntimeClient;
private config: DeepSeekEndpointConfig;
constructor(config: DeepSeekEndpointConfig) {
this.config = config;
this.sagemakerClient = new SageMakerRuntimeClient({
region: config.region,
maxAttempts: config.maxRetries || 3
});
}
async invoke(
prompt: string,
options?: {
maxTokens?: number;
temperature?: number;
topP?: number;
enableDeepThink?: boolean;
}
): Promise<{
text: string;
metadata?: {
tokensUsed: number;
latency: number;
thinkingProcess?: string;
};
}> {
const startTime = Date.now();
const payload = {
inputs: prompt,
parameters: {
max_new_tokens: options?.maxTokens || 1024,
temperature: options?.temperature || 0.7,
top_p: options?.topP || 0.9,
do_sample: true,
deep_think: options?.enableDeepThink || false
}
};
const command = new InvokeEndpointCommand({
EndpointName: this.config.endpointName,
Body: JSON.stringify(payload),
ContentType: 'application/json',
Accept: 'application/json'
});
try {
const response = await this.sagemakerClient.send(command);
const result = JSON.parse(
new TextDecoder().decode(response.Body)
);
const latency = Date.now() - startTime;
return {
text: result.generated_text || result[0]?.generated_text || '',
metadata: {
tokensUsed: result.tokens_used || 0,
latency: latency,
thinkingProcess: result.thinking_process
}
};
} catch (error) {
console.error('SageMaker endpoint invocation failed:', error);
throw new Error(`Failed to invoke DeepSeek model: ${error.message}`);
}
}
async batchInvoke(
prompts: string[],
options?: any
): Promise<Array<{ text: string; metadata?: any }>> {
// バッチ処理の実装
const results = await Promise.all(
prompts.map(prompt => this.invoke(prompt, options))
);
return results;
}
}実装における技術的考察
DeepSeek-V3.1をエンタープライズ環境で実装する際には、いくつかの重要な技術的考察事項があります。
メモリとストレージの最適化
671Bパラメータのモデルは、フル精度(FP32)で約2.7TBのメモリを必要とします。実用的な展開のためには、量子化技術の活用が不可欠です。
量子化レベルごとのリソース要件を以下の表にまとめました。
表 DeepSeek-V3.1の量子化レベル別リソース要件
量子化レベル | メモリ使用量 | 推奨GPU構成 | 性能への影響 |
|---|---|---|---|
FP32(フル精度) | 約2.7TB | 不現実的 | ベースライン |
FP16 | 約1.35TB | A100 80GB × 20台 | ほぼ影響なし |
INT8 | 約670GB | A100 80GB × 10台 | 1-2%の精度低下 |
INT4 | 約335GB | A100 80GB × 5台 | 3-5%の精度低下 |
GPTQ 4bit | 約200GB | A100 80GB × 3台 | 5-8%の精度低下 |
この表から、INT8量子化が性能とリソースのバランスが最も良いことが分かります。企業環境では、用途に応じて適切な量子化レベルを選択することが重要です。
レイテンシとスループットの最適化
DeepSeek-V3.1のMoEアーキテクチャは、効率的な推論を可能にしますが、適切な最適化なしには期待されるパフォーマンスを発揮できません。
以下のコード例では、バッチ処理とキャッシング戦略を実装しています。
import { LRUCache } from 'lru-cache';
interface CacheConfig {
maxSize: number;
ttl: number;
}
interface BatchConfig {
maxBatchSize: number;
maxWaitTime: number;
}
class OptimizedDeepSeekInference {
private cache: LRUCache<string, string>;
private batchQueue: Array<{
prompt: string;
resolve: (value: string) => void;
reject: (error: Error) => void;
}>;
private batchConfig: BatchConfig;
private processingBatch: boolean;
constructor(
cacheConfig: CacheConfig,
batchConfig: BatchConfig
) {
this.cache = new LRUCache<string, string>({
max: cacheConfig.maxSize,
ttl: cacheConfig.ttl * 1000 // Convert to milliseconds
});
this.batchQueue = [];
this.batchConfig = batchConfig;
this.processingBatch = false;
}
async generateWithCache(prompt: string): Promise<string> {
// キャッシュチェック
const cacheKey = this.generateCacheKey(prompt);
const cachedResult = this.cache.get(cacheKey);
if (cachedResult) {
console.log('Cache hit for prompt');
return cachedResult;
}
// バッチキューに追加
return new Promise((resolve, reject) => {
this.batchQueue.push({ prompt, resolve, reject });
this.processBatchIfReady();
});
}
private async processBatchIfReady(): Promise<void> {
if (this.processingBatch) return;
if (
this.batchQueue.length >= this.batchConfig.maxBatchSize ||
(this.batchQueue.length > 0 && this.shouldProcessByTime())
) {
this.processingBatch = true;
await this.processBatch();
this.processingBatch = false;
}
}
private async processBatch(): Promise<void> {
const batchSize = Math.min(
this.batchQueue.length,
this.batchConfig.maxBatchSize
);
const batch = this.batchQueue.splice(0, batchSize);
const prompts = batch.map(item => item.prompt);
try {
// バッチ推論の実行
const results = await this.executeBatchInference(prompts);
// 結果をキャッシュに保存し、Promiseを解決
batch.forEach((item, index) => {
const result = results[index];
const cacheKey = this.generateCacheKey(item.prompt);
this.cache.set(cacheKey, result);
item.resolve(result);
});
} catch (error) {
// エラーハンドリング
batch.forEach(item => {
item.reject(error as Error);
});
}
}
private async executeBatchInference(
prompts: string[]
): Promise<string[]> {
// 実際のバッチ推論処理
// この部分は実装環境に応じて調整が必要
const batchPayload = {
instances: prompts.map(prompt => ({
inputs: prompt,
parameters: {
max_new_tokens: 1024,
temperature: 0.7,
batch_size: prompts.length
}
}))
};
// 仮の実装:実際のAPIコールに置き換える
console.log('Executing batch inference for', prompts.length, 'prompts');
// シミュレーション用のダミー応答
return prompts.map(prompt => `Generated response for: ${prompt.substring(0, 50)}...`);
}
private generateCacheKey(prompt: string): string {
// プロンプトからキャッシュキーを生成
const crypto = require('crypto');
return crypto.createHash('sha256')
.update(prompt)
.digest('hex');
}
private shouldProcessByTime(): boolean {
// タイムベースのバッチ処理トリガー
// 実装は省略
return false;
}
}このコード例では、LRUキャッシュによる重複リクエストの削減と、バッチ処理による推論効率の向上を実現しています。実際の環境では、プロンプトの類似度を考慮したセマンティックキャッシングの実装も検討すべきです。
セキュリティとコンプライアンスの考慮
オープンソースモデルを企業環境で使用する際には、セキュリティとコンプライアンスの観点から以下の要素を考慮する必要があります。
エンタープライズ環境でDeepSeek-V3.1を安全に運用するための主要な考慮事項を以下にまとめます。
- データプライバシーの確保:モデルへの入力データと出力データの暗号化、アクセスログの記録、個人情報のマスキング処理を実装する
- モデルの改ざん防止:モデルファイルのハッシュ値検証、デジタル署名の確認、定期的な整合性チェックを実施する
- アクセス制御の実装:IAMロールベースのアクセス制御、APIキーの定期的なローテーション、利用状況の監査ログを整備する
- レート制限とクォータ管理:ユーザーごとの利用制限、異常な利用パターンの検知、コスト予算の設定と監視を行う
これらの対策を実装することで、オープンソースモデルでありながら、エンタープライズグレードのセキュリティを確保できます。
企業における実践的な活用シナリオ
DeepSeek-V3.1とAmazon Bedrockの統合により、様々な企業ユースケースで価値を創出できます。実際の導入事例を想定し、具体的な活用シナリオを検討してみます。
金融機関における文書分析システム
大手金融機関では、膨大な契約書、レポート、規制文書の分析にAIを活用しています。DeepSeek-V3.1の128Kトークンのコンテキスト長と低コストな推論により、従来は困難だった大規模文書の一括処理が可能になります。
実装アーキテクチャの例を以下に示します。
interface DocumentAnalysisConfig {
maxDocumentSize: number;
chunkSize: number;
overlapSize: number;
analysisType: 'summary' | 'extraction' | 'compliance';
}
class FinancialDocumentAnalyzer {
private deepSeekEndpoint: string;
private bedrockClient: any; // BedrockRuntimeClient
private config: DocumentAnalysisConfig;
constructor(
deepSeekEndpoint: string,
config: DocumentAnalysisConfig
) {
this.deepSeekEndpoint = deepSeekEndpoint;
this.config = config;
// Bedrockクライアントの初期化
}
async analyzeDocument(
documentContent: string,
analysisPrompt: string
): Promise<{
summary: string;
keyFindings: string[];
riskFactors: string[];
complianceIssues: string[];
}> {
// 文書をチャンクに分割
const chunks = this.splitDocument(documentContent);
// 各チャンクを並列処理
const chunkAnalyses = await Promise.all(
chunks.map(chunk => this.analyzeChunk(chunk, analysisPrompt))
);
// 結果を統合
return this.consolidateAnalyses(chunkAnalyses);
}
private splitDocument(content: string): string[] {
const chunks: string[] = [];
const words = content.split(' ');
for (let i = 0; i < words.length; i += this.config.chunkSize) {
const chunkWords = words.slice(
Math.max(0, i - this.config.overlapSize),
i + this.config.chunkSize
);
chunks.push(chunkWords.join(' '));
}
return chunks;
}
private async analyzeChunk(
chunk: string,
analysisPrompt: string
): Promise<any> {
const prompt = `
<document>
${chunk}
</document>
<instruction>
${analysisPrompt}
</instruction>
Please provide a structured analysis including:
1. Key findings
2. Risk factors
3. Compliance considerations
`;
// DeepSeek-V3.1での分析実行
const response = await this.invokeDeepSeek(prompt);
return this.parseAnalysisResponse(response);
}
private async invokeDeepSeek(prompt: string): Promise<string> {
// DeepSeek APIの呼び出し
// 実装は環境に応じて調整
return '';
}
private parseAnalysisResponse(response: string): any {
// レスポンスのパース処理
// 構造化されたデータを抽出
return {};
}
private consolidateAnalyses(analyses: any[]): any {
// 複数のチャンク分析結果を統合
const consolidated = {
summary: '',
keyFindings: [],
riskFactors: [],
complianceIssues: []
};
// 統合ロジックの実装
analyses.forEach(analysis => {
// 重複除去と優先順位付け
});
return consolidated;
}
}製造業におけるナレッジマネジメント
製造業では、技術文書、マニュアル、トラブルシューティングガイドなど、膨大な技術情報を管理する必要があります。DeepSeek-V3.1を活用することで、これらの情報を統合的に検索・活用できるナレッジベースを構築できます。
以下の表は、実際の導入効果の試算例を示しています。
表 製造業におけるDeepSeek-V3.1導入による効果試算(当社の過去事例より)
指標 | 導入前 | 導入後 | 改善率 |
|---|---|---|---|
技術情報の検索時間 | 平均45分/件 | 平均5分/件 | 89%削減 |
トラブルシューティング解決時間 | 平均3.5時間 | 平均1.2時間 | 66%削減 |
ドキュメント作成工数 | 40時間/文書 | 15時間/文書 | 62%削減 |
月間AIコスト | $50,000(他社モデル) | $5,000 | 90%削減 |
知識共有の活性化度* | 100 | 350 | 250%向上 |
この試算から、DeepSeek-V3.1の導入により、業務効率の大幅な改善とコスト削減を同時に実現できることが分かります。
小売業における顧客対応の高度化
小売業では、顧客からの問い合わせ対応やレコメンデーションシステムにAIを活用しています。DeepSeek-V3.1の高性能と低コストにより、これまで費用対効果の観点から導入が困難だった中小規模の事業者でも、高度なAI活用が可能になります。
interface CustomerServiceConfig {
responseStyle: 'formal' | 'casual' | 'friendly';
maxResponseLength: number;
includeProductRecommendations: boolean;
languages: string[];
}
class RetailCustomerServiceBot {
private config: CustomerServiceConfig;
private productCatalog: Map<string, any>;
private customerHistory: Map<string, any>;
constructor(config: CustomerServiceConfig) {
this.config = config;
this.productCatalog = new Map();
this.customerHistory = new Map();
}
async handleCustomerInquiry(
customerId: string,
inquiry: string,
context?: any
): Promise<{
response: string;
recommendations?: Array<{
productId: string;
reason: string;
confidence: number;
}>;
followUpActions?: string[];
}> {
// 顧客履歴の取得
const history = await this.getCustomerHistory(customerId);
// 関連商品情報の取得
const relevantProducts = await this.findRelevantProducts(inquiry);
// プロンプトの構築
const prompt = this.buildCustomerServicePrompt(
inquiry,
history,
relevantProducts
);
// DeepSeek-V3.1での応答生成
const aiResponse = await this.generateResponse(prompt);
// レスポンスの構造化
return this.structureResponse(aiResponse);
}
private buildCustomerServicePrompt(
inquiry: string,
history: any,
products: any[]
): string {
const styleGuide = this.getStyleGuide();
return `
<customer_history>
${JSON.stringify(history, null, 2)}
</customer_history>
<available_products>
${products.map(p => JSON.stringify(p)).join('\\\\n')}
</available_products>
<customer_inquiry>
${inquiry}
</customer_inquiry>
<instructions>
Please respond to the customer inquiry following these guidelines:
- Style: ${this.config.responseStyle}
- Maximum length: ${this.config.maxResponseLength} words
- Include product recommendations: ${this.config.includeProductRecommendations}
${styleGuide}
</instructions>
`;
}
private getStyleGuide(): string {
const guides = {
formal: 'Use professional language, complete sentences, and maintain a respectful tone.',
casual: 'Use conversational language while remaining helpful and informative.',
friendly: 'Use warm, approachable language with a personal touch.'
};
return guides[this.config.responseStyle];
}
private async generateResponse(prompt: string): Promise<string> {
// DeepSeek-V3.1 APIの呼び出し
// DeepThink機能を有効化して高度な推論を実行
const response = await this.invokeDeepSeekWithThinking(prompt);
return response;
}
private async invokeDeepSeekWithThinking(prompt: string): Promise<string> {
// DeepThink機能を活用した推論
// 実装詳細は環境依存
return '';
}
private structureResponse(aiResponse: string): any {
// AIレスポンスを構造化データに変換
return {
response: aiResponse,
recommendations: [],
followUpActions: []
};
}
private async getCustomerHistory(customerId: string): Promise<any> {
return this.customerHistory.get(customerId) || {};
}
private async findRelevantProducts(inquiry: string): Promise<any[]> {
// 問い合わせ内容に関連する商品を検索
return [];
}
}移行とコスト最適化の実践的アプローチ
既存のAIシステムからDeepSeek-V3.1への移行を検討する際には、段階的なアプローチが重要です。
段階的移行戦略
移行を成功させるための段階的アプローチを以下に示します。
段階 | 概算期間 | 詳細 |
|---|---|---|
評価フェーズ | 1-2週間 | 代表的なユースケースでの性能評価 コスト削減効果の試算 技術的な実現可能性の検証 |
パイロット実装 | 2-4週間 | 限定的な環境での実装 パフォーマンス測定とボトルネックの特定 セキュリティとコンプライアンスの確認 |
段階的展開 | 1-3ヶ月 | A/Bテストによる既存モデルとの比較 負荷分散による段階的な切り替え 継続的なモニタリングと最適化 |
本番展開 |
|
コスト最適化のベストプラクティス
DeepSeek-V3.1の低コストをさらに最大化するための戦略を実装します。
interface CostOptimizationStrategy {
enableCaching: boolean;
useQuantization: boolean;
batchProcessing: boolean;
dynamicScaling: boolean;
}
class CostOptimizer {
private strategy: CostOptimizationStrategy;
private metricsCollector: MetricsCollector;
constructor(strategy: CostOptimizationStrategy) {
this.strategy = strategy;
this.metricsCollector = new MetricsCollector();
}
async optimizeInference(
requests: Array<{
id: string;
prompt: string;
priority: 'high' | 'medium' | 'low';
}>
): Promise<Map<string, string>> {
const results = new Map<string, string>();
// 優先度によるリクエストの分類
const prioritizedRequests = this.prioritizeRequests(requests);
// キャッシュ可能なリクエストの特定
const { cacheable, nonCacheable } =
await this.identifyCacheableRequests(prioritizedRequests);
// キャッシュからの結果取得
if (this.strategy.enableCaching) {
const cachedResults = await this.getCachedResults(cacheable);
cachedResults.forEach((value, key) => results.set(key, value));
}
// バッチ処理の実行
if (this.strategy.batchProcessing) {
const batchResults = await this.processBatch(nonCacheable);
batchResults.forEach((value, key) => results.set(key, value));
} else {
// 個別処理
for (const req of nonCacheable) {
const result = await this.processSingle(req);
results.set(req.id, result);
}
}
// メトリクスの記録
await this.metricsCollector.record({
totalRequests: requests.length,
cachedRequests: cacheable.length,
processingTime: Date.now(),
estimatedCost: this.calculateCost(results)
});
return results;
}
private prioritizeRequests(requests: any[]): any[] {
const priorityOrder = { 'high': 0, 'medium': 1, 'low': 2 };
return requests.sort((a, b) =>
priorityOrder[a.priority] - priorityOrder[b.priority]
);
}
private async identifyCacheableRequests(
requests: any[]
): Promise<{ cacheable: any[], nonCacheable: any[] }> {
const cacheable = [];
const nonCacheable = [];
for (const req of requests) {
if (await this.isCacheable(req)) {
cacheable.push(req);
} else {
nonCacheable.push(req);
}
}
return { cacheable, nonCacheable };
}
private async isCacheable(request: any): boolean {
// キャッシュ可能性の判定ロジック
// 例:個人情報を含まない、定型的な質問など
return request.priority === 'low' &&
!request.prompt.includes('personal');
}
private async getCachedResults(
requests: any[]
): Promise<Map<string, string>> {
// キャッシュからの取得処理
const results = new Map<string, string>();
// 実装省略
return results;
}
private async processBatch(requests: any[]): Promise<Map<string, string>> {
// バッチ処理の実装
const results = new Map<string, string>();
// 実装省略
return results;
}
private async processSingle(request: any): Promise<string> {
// 個別処理の実装
return '';
}
private calculateCost(results: Map<string, string>): number {
// コスト計算ロジック
let totalTokens = 0;
results.forEach(result => {
totalTokens += this.estimateTokens(result);
});
// DeepSeek-V3.1の料金体系に基づく計算
const inputCostPerMillion = 0.27;
const outputCostPerMillion = 2.19;
// 簡略化された計算
return (totalTokens / 1000000) * outputCostPerMillion;
}
private estimateTokens(text: string): number {
// トークン数の推定(簡略化)
return Math.ceil(text.length / 4);
}
}
class MetricsCollector {
async record(metrics: any): Promise<void> {
// メトリクスの記録処理
console.log('Recording metrics:', metrics);
}
}このコード例では、キャッシング、バッチ処理、優先度管理などの複数の最適化手法を組み合わせて、コストを最小化しながらパフォーマンスを維持する戦略を実装しています。
今後の展望と戦略的考察
DeepSeek-V3.1とAmazon Bedrockの統合は、エンタープライズAI戦略における重要な転換点となる可能性があります。
オープンソースモデルの戦略的価値
オープンソースLLMの台頭により、企業のAI戦略に新たな選択肢が生まれています。DeepSeek-V3.1のような高性能かつ低コストなモデルの登場は、以下のような戦略的価値をもたらします。
ベンダーロックインの回避 | 複数のモデルプロバイダーを活用できる柔軟性 |
|---|---|
カスタマイゼーションの自由度 | 自社のユースケースに最適化したファインチューニングが可能 |
透明性の確保 | モデルアーキテクチャやトレーニングデータへのアクセスによる説明可能性の向上 |
コミュニティの活用 | 世界中の開発者によるツールやノウハウの共有 |
Amazon Bedrockエコシステムの進化
Amazon Bedrockは、マルチモデル戦略のハブとして進化を続けています。2024年のre:Inventで発表された新機能を見ると、カスタムモデルのサポート強化、推論最適化、エンタープライズ機能の拡充など、オープンソースモデルとの統合を意識した方向性が明確になっています。
今後期待される機能拡張として以下が挙げられます。
- オープンソースモデルの公式サポート拡大
- モデル間の自動切り替えとロードバランシング
- 統合的なモデル性能モニタリングとコスト最適化
- エッジデバイスへの展開サポート
まとめ
DeepSeek-V3.1の登場は、エンタープライズAI戦略に大きな変革をもたらす可能性を秘めています。671Bパラメータという巨大なモデルでありながら、MoEアーキテクチャによる効率的な推論と、従来の10分の1以下というコスト構造は、これまでのLLM市場の常識を覆すものです。
Amazon Bedrockとの統合により、企業は高性能なオープンソースモデルを、エンタープライズグレードのセキュリティとガバナンスの下で活用できるようになります。カスタムモデルインポート機能やSageMakerとの連携により、現時点でも実装可能な統合パスが存在し、将来的な公式サポートに向けた準備を進めることができます。
実装における技術的な課題として、モデルサイズに起因するリソース要件、レイテンシの最適化、セキュリティの確保などがありますが、本記事で示した量子化技術、バッチ処理、キャッシング戦略などの手法により、これらの課題は解決可能です。
企業がDeepSeek-V3.1を活用する際の成功の鍵は、段階的な移行戦略と継続的な最適化にあります。評価、パイロット、段階展開、最適化というフェーズを経ることで、リスクを管理しながら確実に価値を創出できます。金融、製造、小売といった様々な業界での活用シナリオが示すように、DeepSeek-V3.1は幅広いユースケースで競争優位性をもたらす可能性があります。
オープンソースLLMとクラウドプラットフォームの融合は、AI民主化の新たな段階を示しています。企業は、ベンダーロックインを回避しながら、最先端のAI技術を活用できる環境を構築できるようになりました。DeepSeek-V3.1とAmazon Bedrockの統合は、その先駆的な事例として、今後のエンタープライズAI戦略の指針となることでしょう。
技術の進化は止まることなく、今後もさらなる革新的なモデルが登場することは間違いありません。重要なのは、これらの新技術を評価し、適切に統合し、ビジネス価値に変換する能力を組織として構築することです。
























