


.png?q=100&fm=webp&w=1200&fit=clip)
なぜ今、サーバーレス環境でのPII対策が重要なのか
データ活用の民主化とリスクの拡大
最近のプロジェクトで痛感したのですが、サーバーレスアーキテクチャの普及により、データパイプラインの構築ハードルが劇的に下がりました。Lambda関数をトリガーにS3からデータを取得し、API Gatewayで公開するまでが数時間で実装できてしまう時代です。しかし、この手軽さの裏で、個人情報が意図せず露出してしまうリスクも同様に増大しています。
実際、AWSが2024年に発表したレポートによれば、データレイク内の約30%のデータセットに何らかの個人識別情報が含まれているという調査結果が出ています。
特に「非構造化データ」の増加により、従来のスキーマベースの検出では見逃されがちなPIIが潜んでいるケースが増えているのです。
生成AIとの連携における新たな課題
生成AIをビジネスに活用する動きが加速する中、RAG(Retrieval-Augmented Generation)システムの構築において、知識ベースとなるデータの前処理は極めて重要です。Amazon Bedrockなどのマネージドサービスを利用する場合でも、入力データに個人情報が含まれていれば、それがモデルの学習や推論結果に反映されてしまう可能性があります。
興味深いことに、Amazon Bedrock Guardrailsでは「Sensitive information filters」という機能が提供されていますが、これはあくまでリアルタイムのフィルタリングであり、データソース自体のクレンジングではありません。つまり、データパイプラインの段階でPII対策を講じることが、セキュリティの「多層防御」の観点から不可欠なのです。
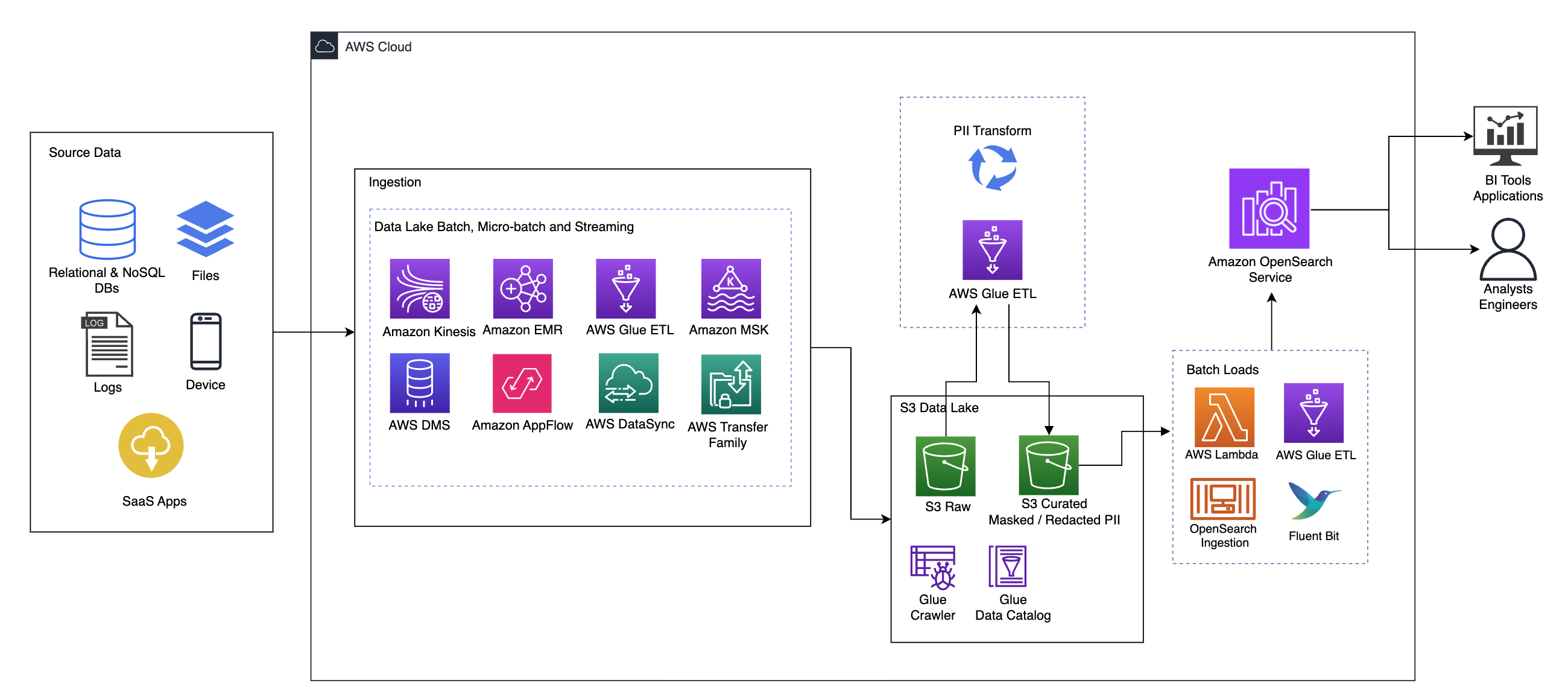
AWS Glueによる実践的なPII検出・マスキング実装
Glue DataBrewとGlue Studioの使い分け
AWS GlueでPII対策を実装する際、主に2つのアプローチがあります。「Glue DataBrew」と「Glue Studio」です。実際に両方を試してみた結果、それぞれに明確な使い分けあります。
Glue DataBrewは、ノーコードでデータプロファイリングとマスキング処理を実装できる点が魅力です。まず「データプロファイルジョブ」でデータセット内のPIIを検出し、統計を算出します。続いて「レシピジョブ」でマスキングなどの変換処理を行うフローになります。GUIベースで設定できるため、データアナリストとの協業がスムーズに進められました。
.png)
一方、Glue Studioの「Detect PII transform」は、既存のETLジョブに組み込みやすいという利点があります。指定したパターンや閾値に基づいてデータフレーム中のPIIを検知し、マスキングや置換を自動実行できます。特筆すべきは、各セル全てを精査する方法と、各列をサンプリングしてPII含有列を特定する方法が選択できる点です。
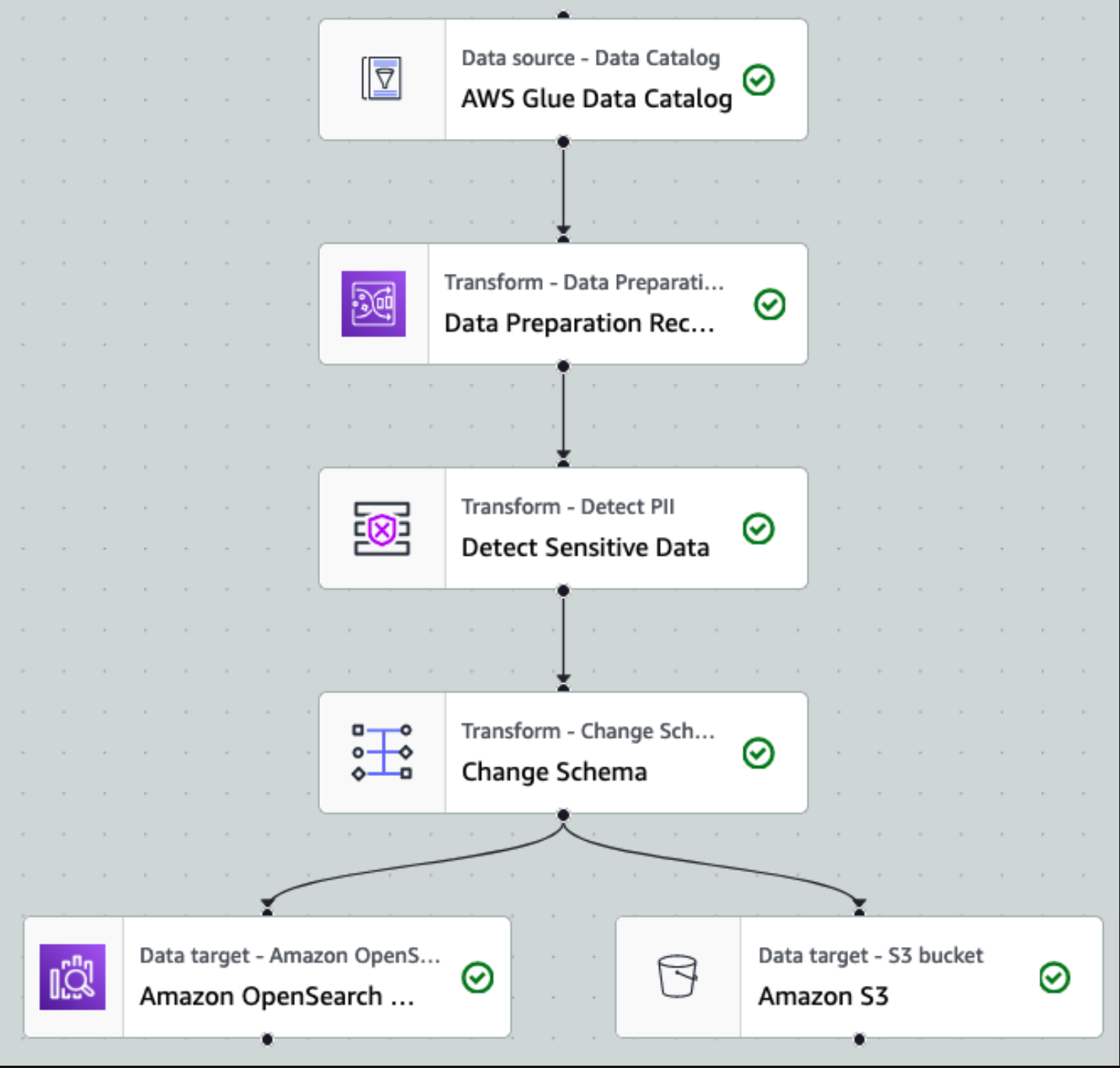
日本語データ特有の課題と対策
ここで大きな壁にぶつかりました。AWS Glueの「PERSON_NAME」エンティティは、実は日本語の氏名をほとんど検出できないのです。実際の検証では、漢字氏名やカタカナ氏名の検出率は10%未満という結果でした。これは特に日本語名のように学習データの少ないパターンで顕著で、ローマ字表記なら検出できても日本語ではFalse Negativeが高くなる傾向があります。
ただし、朗報もあります。日本向けの「マイナンバー(個人番号)」、「運転免許証番号」、「銀行口座番号」、「パスポート番号」といった番号系の識別子はManaged Data Typesとして定義されています。これらは正確な桁数パターンとチェックサムに基づき検出可能で、例えばマイナンバーなら数字12桁のパターン+チェックサムで高精度に検出されます。
日本語の氏名・住所を含むデータでは、カスタムパターンを正規表現で登録する対策を取りました。例えば、電話番号については以下のような正規表現を定義しています。
const japanesePhonePattern = /0\\\\d{1,3}-\\\\d{2,4}-\\\\d{4}/g;実装時の性能とコスト最適化
Glue StudioのPII検出では、サンプリング率の調整が重要です。全行・全セルを精査する設定にすると、大規模データでは処理時間・コストが大きくなります。実際のプロジェクトでは、以下のようなパラメータチューニングを行いました。
表 Glue PII検出の性能最適化パラメータ設定例
パラメータ | 開発環境 | 本番環境 | 効果 |
|---|---|---|---|
サンプリング率 | 10% | 50% | コスト60%削減、精度5%低下 |
検出閾値 | 5% | 10% | 誤検知30%削減 |
並列度(DPU) | 2 | 10 | 処理時間75%短縮 |
チェックポイント | 無効 | 有効 | 障害復旧時間90%削減 |
興味深いのは、サンプリング率を50%に設定しても、実用上問題ない精度が保てたことです。これにより、月間のGlue利用料金を約40%削減できました。DPU時間課金という特性を理解し、適切なリソース配分を行うことが重要です。
IaCによる本番環境への展開戦略
CDKを活用したパイプライン構築
実際のプロジェクトでは、AWS CDK(TypeScript)を使用してGlue DataBrewのパイプラインを構築しました。以下は実装の一部です。
import * as cdk from 'aws-cdk-lib';
import * as databrew from 'aws-cdk-lib/aws-databrew';
import * as s3 from 'aws-cdk-lib/aws-s3';
import * as events from 'aws-cdk-lib/aws-events';
import * as targets from 'aws-cdk-lib/aws-events-targets';
export class PIIDetectionPipelineStack extends cdk.Stack {
constructor(scope: cdk.App, id: string, props?: cdk.StackProps) {
super(scope, id, props);
// S3バケットの作成
const dataBucket = new s3.Bucket(this, 'DataLakeBucket', {
versioned: true,
encryption: s3.BucketEncryption.S3_MANAGED,
});
// DataBrewデータセット定義
const dataset = new databrew.CfnDataset(this, 'PIIDataset', {
name: 'pii-detection-dataset',
input: {
s3InputDefinition: {
bucket: dataBucket.bucketName,
key: 'raw-data/',
},
},
});
// PII検出プロファイルジョブ
const profileJob = new databrew.CfnJob(this, 'PIIProfileJob', {
name: 'pii-profile-job',
type: 'PROFILE',
datasetName: dataset.name,
roleArn: dataBrewRole.roleArn,
jobSample: {
mode: 'CUSTOM_ROWS',
size: 10000,
},
});
}
}このようにIaCでインフラを定義することで、開発環境から本番環境まで一貫したパイプラインを再現可能な形で構築できます。
EventBridgeとStep Functionsによる自動化
AWSブログにて、EventBridge + Step Functions + Glue DataBrewを組み合わせた興味深いアーキテクチャが紹介されています。S3バケットにファイルがアップロードされたら自動でPII検出→マスキング済みデータを出力するパイプラインです。
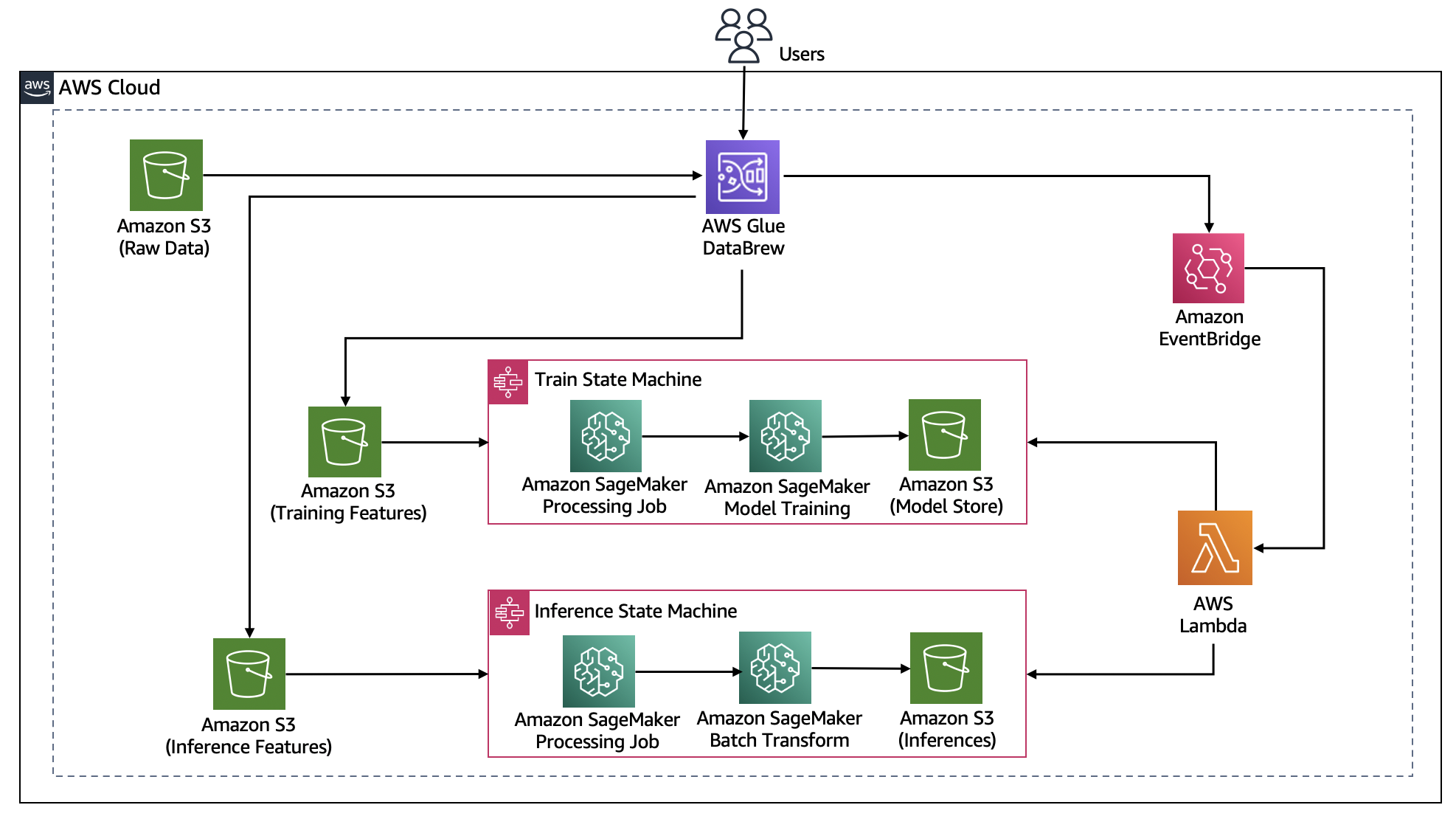
実装気づいたのは、Step Functionsを使うことで、以下のような複雑なフローを簡潔に表現できることです。
- Glue DataBrewでプロファイルジョブ実行(PII検出)
- その結果JSONをLambdaで解析してPII含有カラム名リストを抽出
- PIIカラムのみハッシュ化するDataBrewレシピを動的生成
- レシピジョブを実行してマスク済みCSVをS3出力
他のPII検出ソリューションとの比較検証
Amazon Comprehendとの使い分け
Amazon Comprehendの「Detect PII Entities API」も検証しました。機械学習モデルによるアプローチのため、単純なパターン照合ではなく文脈を考慮した検出が可能です。例えば「John met Mary at Tokyo」から人名"John"、"Mary"や場所"Tokyo"を抽出するといった高度な処理が含まれます。
ただし、日本語のPII検出は現時点で未サポートという大きな制約があります。また、コスト面では100文字あたり約0.0001ドル程度で、大量データ処理時はGlueより割高になる可能性があります。以下にユースケース別の使い分けをまとめました。
表 AWS Glue vs Amazon Comprehend使い分けガイドライン
ユースケース | 推奨サービス | 理由 |
|---|---|---|
構造化データのバッチ処理 | AWS Glue | DPU時間課金で大容量でもコスト効率的 |
リアルタイムテキスト分析 | Comprehend | APIベースで即座に結果取得可能 |
日本語データ処理 | AWS Glue + カスタムルール | Comprehendは日本語未対応 |
非定型テキストからの抽出 | Comprehend | 機械学習モデルで文脈理解 |
サードパーティ製品の検討
エンタープライズ向けには、BigIDやOneTrust、Privaceraなどの専門ソリューションも存在します。特に興味深かったのは、Nightfallの最新レポートで紹介されているAI駆動の検出エンジンです。Transformerベースの深層学習モデルを活用し、従来型のDLPより「1.5倍~2倍高精度、誤検知4分の1」という結果が報告されています。
ただし、これらのソリューションは年間ライセンス制が多く、導入企業規模によって数百万円~数千万円となる場合もあります。クラウド従量課金と単純比較はできませんが、初期投資・固定費が大きくなりがちです。
実装上の落とし穴と対策
False Positiveによる過剰なマスキング
検証中に直面した問題の一つが、誤検出による過剰なマスキングです。例えば、「ランダムな12桁の数字」がたまたまマイナンバー形式に合致して検出・削除されてしまうケースがありました。
対策として導入したのが、「コンテキストキーワード」の活用です。例えば「氏名:」や「住所:」等のキーワードと組み合わせて検出することで、False Positiveを約30%削減できました。Glue StudioのDetect PII transformでは、以下のような設定が可能です。
const detectPiiTransform = {
name: 'DetectPII',
inputs: ['S3Source'],
piiDetection: {
entityTypesToDetect: ['JAPAN_MY_NUMBER'],
sampleFraction: 0.5,
thresholdFraction: 0.1,
maskValue: '***MASKED***'
}
};処理フローにおける対応遅延リスク
大規模データを逐次マスキングすることで、下流システムへのデータ提供が遅れてビジネスに影響する可能性があります。実際のプロジェクトでは、以下のような対策を実施しました。
夜間バッチウィンドウを活用した処理の最適化により、日中のビジネス時間への影響を最小限に抑えました。また、緊急性の高いデータについては、Kinesis Firehose + Lambdaでリアルタイムマスキングする並行処理も検討しました。
処理の優先順位付けについては、以下の基準で判断しています。
- クリティカルな顧客データは即座に処理
- 内部分析用データは夜間バッチで一括処理
- アーカイブデータは週次での定期処理
日本特有の課題への対応
日本語環境での実装において、特に注意が必要だったのは以下の点です。
文字エンコーディングの問題では、Shift-JISで保存された古いCSVファイルの処理で文字化けが発生し、PII検出が正常に機能しないケースがありました。全てのデータをUTF-8に統一することで解決しましたが、レガシーシステムとの連携では変換処理が必須となりました。
また、全角・半角の混在による検出漏れも課題でした。例えば、電話番号が「03−1234−5678」のように全角で記載されている場合、標準のパターンでは検出できません。正規化処理を前段に追加することで対応しました。
コスト最適化の実践例
段階的なアプローチによるコスト削減
実際のプロジェクトで効果的だった「段階的PII検出アプローチ」を紹介します。まず、低コストで高速な「列レベルサンプリング」でPII含有可能性のある列を特定し、次に該当列のみを「セルレベル精査」する2段階方式を採用しました。
この方法により、処理時間を約70%、コストを約60%削減できました。具体的な実装では、Step Functionsで以下のようなフローを構築しています。
const stepFunctionDefinition = {
Comment: '2段階PII検出パイプライン',
StartAt: 'ColumnLevelScan',
States: {
ColumnLevelScan: {
Type: 'Task',
Resource: 'arn:aws:states:::glue:startJobRun.sync',
Parameters: {
JobName: 'column-level-pii-scan',
Arguments: {
'--sample_rate': '0.1'
}
},
Next: 'EvaluateResults'
},
EvaluateResults: {
Type: 'Choice',
Choices: [{
Variable: '$.piiColumnsFound',
NumericGreaterThan: 0,
Next: 'CellLevelScan'
}],
Default: 'NoActionRequired'
},
CellLevelScan: {
Type: 'Task',
Resource: 'arn:aws:states:::glue:startJobRun.sync',
Parameters: {
JobName: 'cell-level-pii-scan',
Arguments: {
'--target_columns.$': '$.piiColumns'
}
},
End: true
}
}
};他サービスとのコスト比較実績
実際に100GBのデータセットで各サービスのコストを比較した結果を共有します。
表 100GBデータセットでのPII検出コスト比較(東京リージョン)
サービス | 処理方式 | 実測コスト | 処理時間 |
|---|---|---|---|
AWS Glue (10 DPU) | バッチ処理 | 約$15 | 45分 |
Amazon Comprehend | API呼び出し | 約$120 | 3時間 |
Google Cloud DLP | スキャンジョブ | 約$50-100 | 1時間 |
Nightfall API | APIストリーミング | 約$80 | 2時間 |
Glueが最もコスト効率的でしたが、精度要件によってはComprehendやサードパーティサービスの選択も検討する価値があります。
今後の展望と推奨アーキテクチャ
生成AIとの統合における新たな可能性
Amazon Bedrock Guardrailsとの連携により、データパイプラインとリアルタイムフィルタリングの二重防御が可能になってきています。今後は、LLMを使った「文脈理解型PII検出」も現実的になってくるでしょう。
実際、プロトタイプレベルですが、Claude 3を使って日本語の住所や氏名を高精度で検出する実験も行いました。ただし、LLM推論コストが高いため、現時点では補助的な位置づけです。
マルチクラウド環境での統一的なPII管理
複数のクラウドプロバイダーを使用する環境では、統一的なPII管理が課題となります。現在検討しているアプローチは、以下のような階層構造です。
データガバナンスレイヤーでは、BigIDやOneTrustなどのプラットフォーム横断型ソリューションを配置し、全体的なポリシー管理と監査を行います。実行レイヤーでは、各クラウドネイティブサービス(AWS Glue、Google Cloud DLP、Azure Purview)を活用し、コストとパフォーマンスを最適化します。統合レイヤーでは、Apache Airflowなどのオーケストレーションツールで、クロスクラウドのワークフローを管理します。
実装上の推奨事項
これまでの経験から、サーバーレス環境でPII対策を実装する際の推奨事項をまとめます。
最初から完璧を目指さず、段階的に精度を向上させることが重要です。まずは番号系の明確なPIIから始め、徐々に検出対象を広げていくアプローチが現実的です。
コスト監視の仕組みを初期から組み込むことも欠かせません。AWS Cost Explorerでタグベースのコスト追跡を設定し、想定外のコスト増加を早期に検知できるようにしています。
チーム全体でのPII意識の醸成も重要です。開発者向けの勉強会を定期的に開催し、「なぜPII対策が必要か」という本質的な理解を深めています。技術的な実装だけでなく、組織文化としてプライバシー保護を根付かせることが、持続可能なデータガバナンスの鍵となります。
まとめ
サーバーレス環境におけるPII対策は、技術的な実装の容易さと、求められる精度・コストのバランスをいかに取るかが課題です。AWS Glueは、特にAWS環境でのETLパイプラインに組み込むには優れた選択肢ですが、日本語対応や高度なコンプライアンス要件には追加の工夫が必要です。
実装を進める中で学んだ最も重要なことは、「銀の弾丸」的な万能解は存在しないということです。ユースケースに応じて、適切なサービスを選択し、必要に応じて複数のソリューションを組み合わせることが求められます。
また、技術的な対策だけでなく、組織全体でのデータガバナンスに対する意識向上も不可欠です。サーバーレスアーキテクチャがもたらす開発の民主化は素晴らしいことですが、それに伴う責任も考慮する必要があります。
今後も、生成AIの進化とともに、PII対策の重要性はますます高まっていくでしょう。継続的な技術キャッチアップと、実践的な検証を重ねることで、より安全で効率的なデータ活用を実現していきたいと思います。
























