


AWSにおけるリアルタイム障害監視の重要性と課題
現代のシステム運用が直面する監視の複雑さ
クラウドネイティブなアーキテクチャの普及により、システムの構成要素は飛躍的に増加しました。「マイクロサービス」や「サーバレス」といったアーキテクチャパターンでは、数十から数百のコンポーネントが協調動作することも珍しくありません。このような環境では、単一のサーバやアプリケーションを監視するだけでは不十分であり、システム全体の健全性を包括的に把握する必要があります。
実際のところ、私が関わってきたプロジェクトでも、EC2インスタンスの死活監視だけでなく、「アベイラビリティゾーン(AZ)」単位での障害、AWSプラットフォーム自体のサービス障害、ネットワーク遅延の増大など、多層的な監視が求められるケースが増えています。特に金融系やEコマース系のシステムでは、数分のダウンタイムが数千万円規模の損失につながることもあり、リアルタイム性の高い監視体制の構築は避けて通れない課題となっています。
監視における「リアルタイム性」の定義
そもそも「リアルタイム監視」とは何を指すのでしょうか。厳密な意味でのリアルタイムは、イベント発生と同時に検知・通知することを意味しますが、実際のシステム運用では数秒から数分程度の遅延は許容されることが多いです。重要なのは、ビジネスインパクトが顕在化する前に問題を検知し、対処できることです。
AWSの公式ドキュメントによれば、CloudWatchの標準メトリクスは5分間隔、詳細監視を有効にすれば1分間隔でデータを収集できます。さらに高解像度カスタムメトリクスを使えば、最短1秒間隔での監視も可能です。ただし、データ収集の頻度を上げればコストも増加するため、監視対象の重要度に応じて適切な粒度を選択する必要があります。
AWS純正監視サービスの全体像
CloudWatchを中心とした監視エコシステム
AWSは、CloudWatchを中心に据えた包括的な監視サービス群を提供しています。これらのサービスは相互に連携し、インフラストラクチャからアプリケーションまで、さまざまなレイヤーの監視を実現します。
主要なサービスとその役割は以下の通りです。
AWSの主要な監視エコシステム | 概要 |
|---|---|
CloudWatchメトリクス | リソースのパフォーマンス指標を収集・可視化する |
CloudWatch Logs | ログデータを集中管理し、異常パターンを検知する |
CloudWatch Synthetics | 外形監視により、エンドユーザー視点での可用性を確認する |
AWS Health Dashboard | AWSプラットフォーム側の障害情報を提供する |
AWS Config | リソース設定の変更を追跡し、設定ミスによる障害を防ぐ |
Amazon EventBridge | 各種イベントを集約し、自動対応をトリガーする |
AWS X-Ray | 分散トレーシングによりアプリケーションの内部動作を可視化する |
これらのサービスを適切に組み合わせることで、24時間365日の包括的な監視体制を構築できます。
各サービスの連携による多層防御
私の経験上、単一のサービスだけですべての障害をカバーすることは困難です。例えば、CloudWatchメトリクスだけでは、アプリケーション内部のエラーや外部からの接続性の問題を検知できない場合があります。そこで重要になるのが、複数のサービスを連携させた「多層防御」の考え方です。
具体的には、CloudWatchでインフラレベルの監視を行いつつ、X-Rayでアプリケーション内部の処理を追跡し、Syntheticsで外部からの疎通を確認する、といった組み合わせが効果的です。さらに、これらの監視結果をEventBridgeに集約し、統一的なアラート処理を実装することで、運用の効率化も図れます。
主要サービスの詳細と実装パターン
Amazon CloudWatchによる基礎的な監視基盤
メトリクス監視の実装
CloudWatchメトリクス監視は、AWS監視の基礎となる機能です。EC2インスタンスやRDS、ELBなど、主要なAWSサービスは自動的にメトリクスをCloudWatchに送信します。しかし、デフォルトの設定では見逃してしまう障害も少なくありません。
例えば、EC2インスタンスの「StatusCheckFailed」メトリクスは、インスタンスの死活状態を示す重要な指標です。このメトリクスには「StatusCheckFailed_Instance」と「StatusCheckFailed_System」の2種類があり、前者はOSレベルの問題、後者は物理ホストの問題を示します。実装時には、両方のメトリクスに対してアラームを設定し、System障害の場合は自動復旧(Auto Recovery)アクションを紐付けることが推奨されます。
表 EC2ステータスチェックメトリクスと対応アクション
メトリクス名 | 検知する障害 | 推奨アラーム閾値 | 自動対応アクション |
|---|---|---|---|
StatusCheckFailed_Instance | OS/ソフトウェア障害 | 2回連続失敗(2分間) | インスタンス再起動 |
StatusCheckFailed_System | 物理ホスト障害 | 1回失敗(1分間) | Auto Recovery実行 |
CPUUtilization | 高負荷状態 | 80%以上が5分継続 | Auto Scaling起動 |
NetworkIn/Out | ネットワーク断 | 0バイトが3分継続 | SNS通知+調査開始 |
上記の表は、EC2監視における基本的なメトリクスとアラーム設定の例を示しています。実際の閾値は、システムの特性や要件に応じて調整する必要がありますが、出発点としてこれらの設定から始めることをお勧めします。
ログ監視による異常検知
CloudWatch Logsは、アプリケーションログやシステムログを収集・分析する強力なツールです。単にログを保存するだけでなく、「メトリクスフィルター」機能を使って特定のパターンを検知し、アラームを発報することができます。
実装のポイントは、エラーパターンの適切な定義です。単純に"ERROR"という文字列を検索するだけでは、誤検知が多くなる可能性があります。アプリケーションの特性を理解し、本当に対処が必要なエラーパターンを絞り込むことが重要です。
以下は効果的なメトリクスフィルターの設定例です。
- 特定の例外クラス名を含むログ(例:NullPointerException、TimeoutException)
- HTTPステータスコード5xxの連続発生
- データベース接続エラーの急増
- 認証失敗の異常な増加(セキュリティ監視)
CloudWatch Syntheticsによる外形監視
ユーザー視点の可用性確認
CloudWatch Syntheticsは、「カナリア」と呼ばれるスクリプトを定期的に実行し、Webサイトやエンドポイントの可用性を監視します。内部の監視では正常に見えても、外部からアクセスできない状況は珍しくありません。DNS障害、CDNの問題、リバースプロキシの設定ミスなど、エンドユーザーに影響を与える問題を早期に発見できます。
.webp)
カナリアスクリプトは、単純なURL監視から複雑なユーザーシナリオのシミュレーションまで、幅広い監視パターンに対応できます。私がよく実装するパターンとして、以下のようなものがあります。
- ログインから主要機能の実行まで一連の操作を再現する統合テスト型カナリア
- APIエンドポイントのレスポンスタイムとペイロードの妥当性を検証するAPIモニタリング
- 静的リソース(画像、CSS、JavaScript)の配信状況を確認するアセット監視
実装時の注意点
Syntheticsを実装する際に気をつけたいのは、監視頻度とコストのバランスです。1分間隔で実行すれば障害検知は早くなりますが、その分コストも増加します。クリティカルなエンドポイントは1分間隔、それ以外は5分や10分間隔にするなど、重要度に応じた設定が必要です。
AWS Health Dashboardの活用
プラットフォーム障害への対応
AWS Health Dashboard(Personal Health Dashboard)は、AWS側のサービス障害や計画メンテナンスの情報を提供します。自分たちがどれだけ完璧な監視体制を構築しても、AWSプラットフォーム自体の障害は防げません。Health Dashboardの情報を活用することで、自システムへの影響を早期に把握し、適切な対応を取ることができます。
特に重要なのは、EventBridgeとの連携です。Health イベントをEventBridge経由で受け取り、内容に応じて自動的にSlackやPagerDutyに通知する仕組みを構築することで、AWS側の問題も含めた包括的な監視体制を実現できます。
サードパーティツールとの比較と使い分け
DatadogやNew Relicとの機能比較
AWS純正サービスとサードパーティ製の監視ツールには、それぞれ長所と短所があります。私自身、プロジェクトの要件に応じて使い分けており、その経験から得た知見を共有します。
表 AWS純正サービスとサードパーティツールの比較
評価項目 | AWS純正(CloudWatch) | サードパーティ(Datadog/New Relic) |
|---|---|---|
初期導入コスト | 低い(従量課金) | 高い(基本料金あり) |
AWSサービス統合 | 完璧(自動連携) | APIベース(設定必要) |
マルチクラウド対応 | 限定的 | 優れている |
UI/UXの使いやすさ | 標準的 | 洗練されている |
カスタマイズ性 | 高い(要開発) | 高い(GUI設定可) |
データ収集粒度 | 1分〜5分 | 15秒〜 |
サポート体制 | AWSサポート依存 | 専門サポートあり |
この表が示すように、AWS環境に特化したシンプルな監視であればCloudWatchで十分ですが、マルチクラウドや高度な可視化が必要な場合はサードパーティツールが有利です。
ハイブリッド運用の実践
実際の運用では、CloudWatchとサードパーティツールを併用するケースが多く見られます。例えば、基本的なインフラ監視はCloudWatchで行い、アプリケーションパフォーマンス管理(APM)や高度な分析はDatadogで実施する、といった使い分けです。
この場合のポイントは、データの重複収集を避けることです。DatadogはCloudWatchメトリクスをAPI経由で取得できるため、基礎データはCloudWatchに集約し、Datadogでは追加の分析や可視化に専念する構成が効率的です。
実践的な監視構成の構築
エンタープライズ向け監視アーキテクチャ
ここからは、実際のプロジェクトで構築した監視アーキテクチャの例を紹介します。対象は、EC2とRDSで構成されたWebアプリケーションで、一部オンプレミスのシステムとも連携している環境です。
監視の実装は以下の順序で進めました。
- 基礎インフラ監視(CloudWatchメトリクス+アラーム)
- ログ集約と分析(CloudWatch Logs+メトリクスフィルター)
- 外形監視(CloudWatch Synthetics)
- 分散トレーシング(AWS X-Ray)
- イベント集約と自動対応(EventBridge+Lambda)
- インシデント管理(AWS Incident Manager)
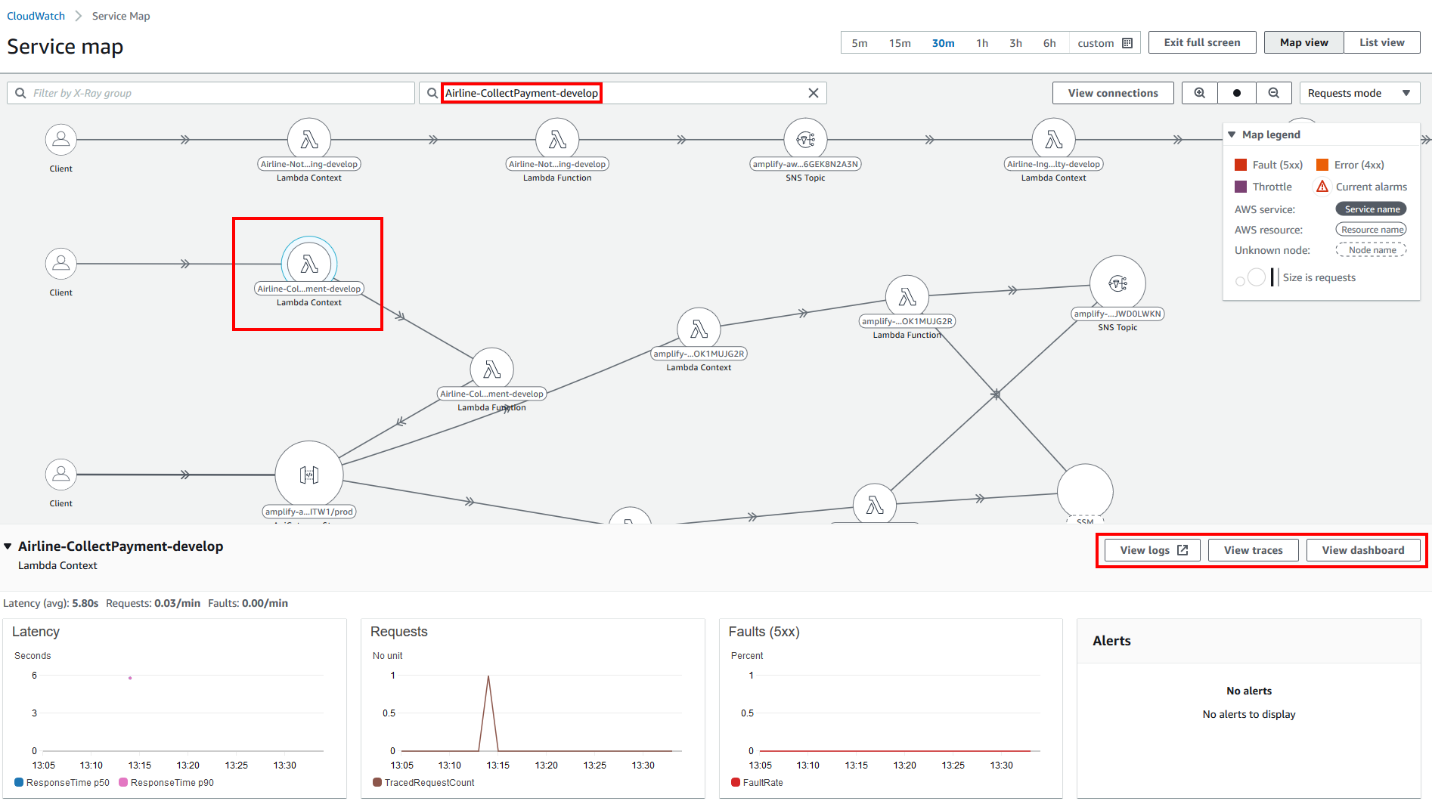
各レイヤーの実装において重要なのは、段階的なアプローチです。最初からすべてを完璧に実装しようとすると、設定の複雑さに圧倒されてしまいます。まずは死活監視から始め、徐々に監視の粒度を細かくしていく方法が現実的です。
アラート設計のベストプラクティス
通知疲れを防ぐ工夫
監視システムを構築する際によく陥る問題が「アラート疲れ」です。些細な問題でも頻繁にアラートが飛ぶようになると、本当に重要な通知を見逃してしまう危険があります。
私が実践している対策は以下の通りです。
- アラートの重要度を3段階(Critical/Warning/Info)に分類する
- 重要度に応じて通知チャネルを変える(Critical:電話、Warning:Slack、Info:メール)
- 一時的な異常を除外するため、複数データポイントでの評価を設定する
- 定期メンテナンス時はアラームを自動的に無効化する仕組みを作る
エスカレーションフローの設計
AWS Incident Managerを使用したエスカレーションフローの設計も重要です。単に通知を送るだけでなく、対応者が不在の場合の二次エスカレーション、対応開始までの時間制限、自動的な関係者への情報共有など、インシデント対応の全体フローを事前に定義しておく必要があります。
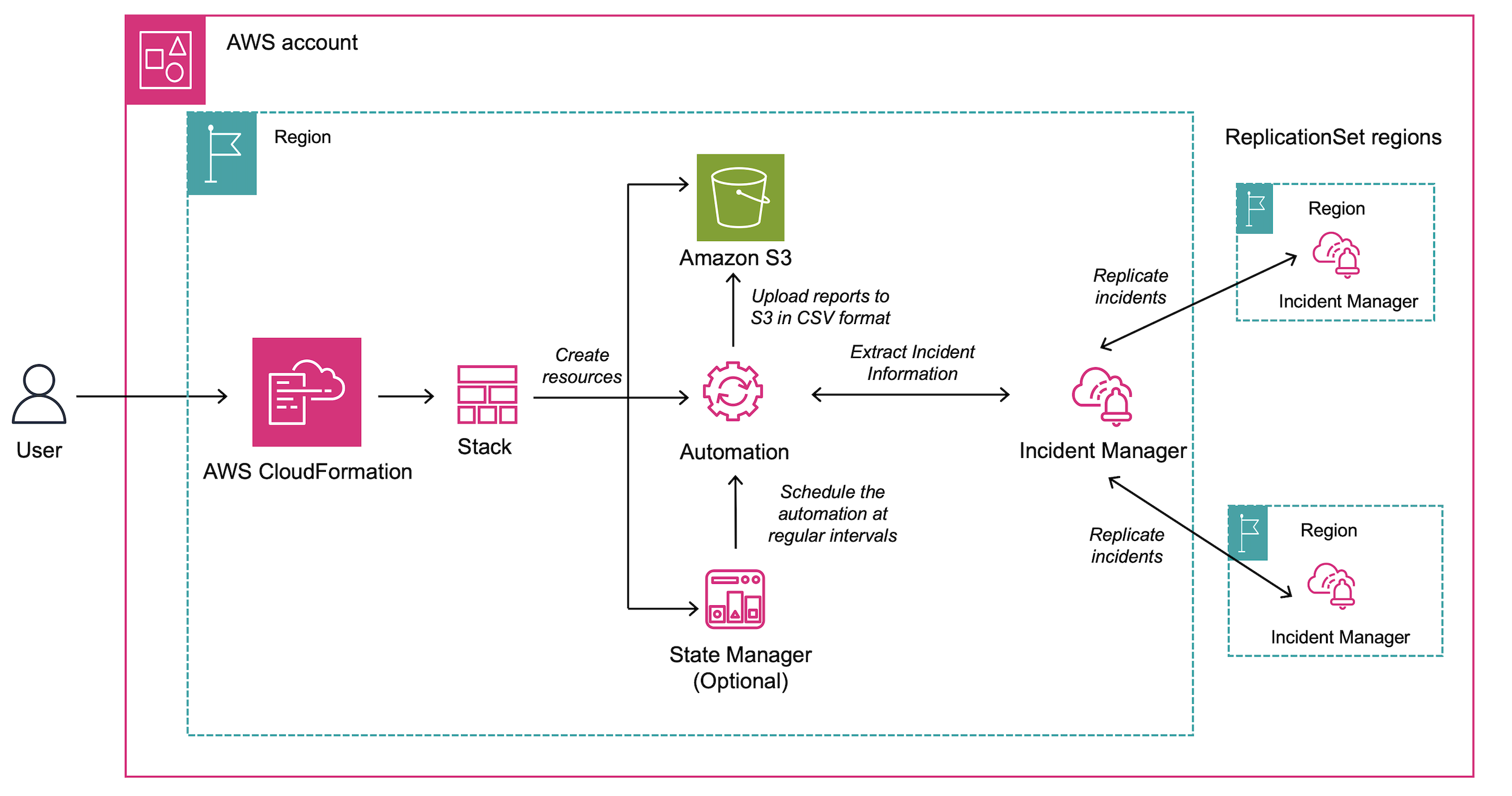
実装例として、以下のようなフローを構築しました。
- 重大障害検知(CloudWatchアラーム)
- Incident Manager起動、一次対応者に電話通知
- 5分以内に応答がない場合、二次対応者にエスカレーション
- 同時にSlackチャネル自動作成、関連情報を投稿
- 対応者がRunbook(手順書)に従って復旧作業実施
- 復旧確認後、ポストモーテム用のレポート自動生成
このような自動化されたフローにより、深夜の障害でも迅速な対応が可能になります。
運用の最適化とコスト管理
監視コストの最適化
CloudWatchをはじめとするAWS監視サービスは従量課金制のため、設定次第でコストが大きく変動します。特に、カスタムメトリクスやログの収集量が増えると、予想外の請求が発生することがあります。
コスト最適化のポイントは以下の通りです。
- メトリクスの収集頻度を重要度に応じて調整する(全てを詳細監視にしない)
- ログの保持期間を適切に設定する(古いログはS3にアーカイブ)
- 不要なダッシュボードやアラームを定期的に棚卸しする
- CloudWatch Logs Insightsのクエリを最適化し、スキャンするデータ量を削減する
継続的な改善プロセス
監視システムは、一度構築したら終わりではありません。システムの成長や変化に合わせて、継続的に改善していく必要があります。私が実践している改善プロセスは以下の通りです。
- 月次でアラートの発報状況をレビューし、誤検知や検知漏れを分析する
- 四半期ごとに監視カバレッジを評価し、新たな監視項目を追加する
- インシデント発生後は必ずポストモーテムを実施し、監視の改善点を洗い出す
- 新しいAWSサービスや機能がリリースされたら、既存の監視体制への組み込みを検討する
まとめ
AWS純正サービスを活用したリアルタイム障害監視は、適切に実装すれば非常に強力な武器となります。CloudWatchを中心に、Synthetics、X-Ray、Health Dashboard、Incident Managerなどを組み合わせることで、インフラからアプリケーション、さらにはAWSプラットフォーム自体の問題まで、包括的に監視できる体制を構築できます。
一方で、すべてをAWS純正サービスで賄う必要はありません。要件に応じてDatadogやNew Relic、PagerDutyといったサードパーティツールを組み合わせることで、より効率的で使いやすい監視システムを実現できます。重要なのは、自社のシステムとチームの特性を理解し、最適な組み合わせを見つけることです。
本記事で紹介した内容が、皆さんの監視体制構築の一助となれば幸いです。24時間365日の安定稼働を実現するには、技術的な実装だけでなく、運用プロセスの整備、チームの教育、継続的な改善といった総合的なアプローチが必要です。一歩ずつ着実に監視体制を強化し、ビジネスを支える信頼性の高いシステム運用を実現していきましょう。
























