


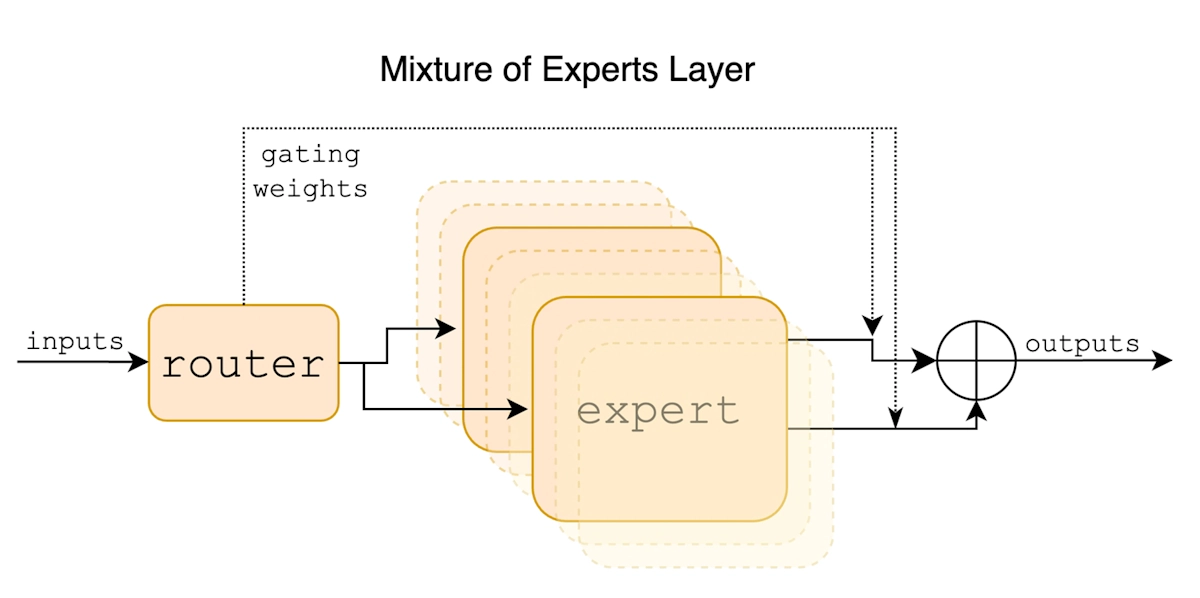
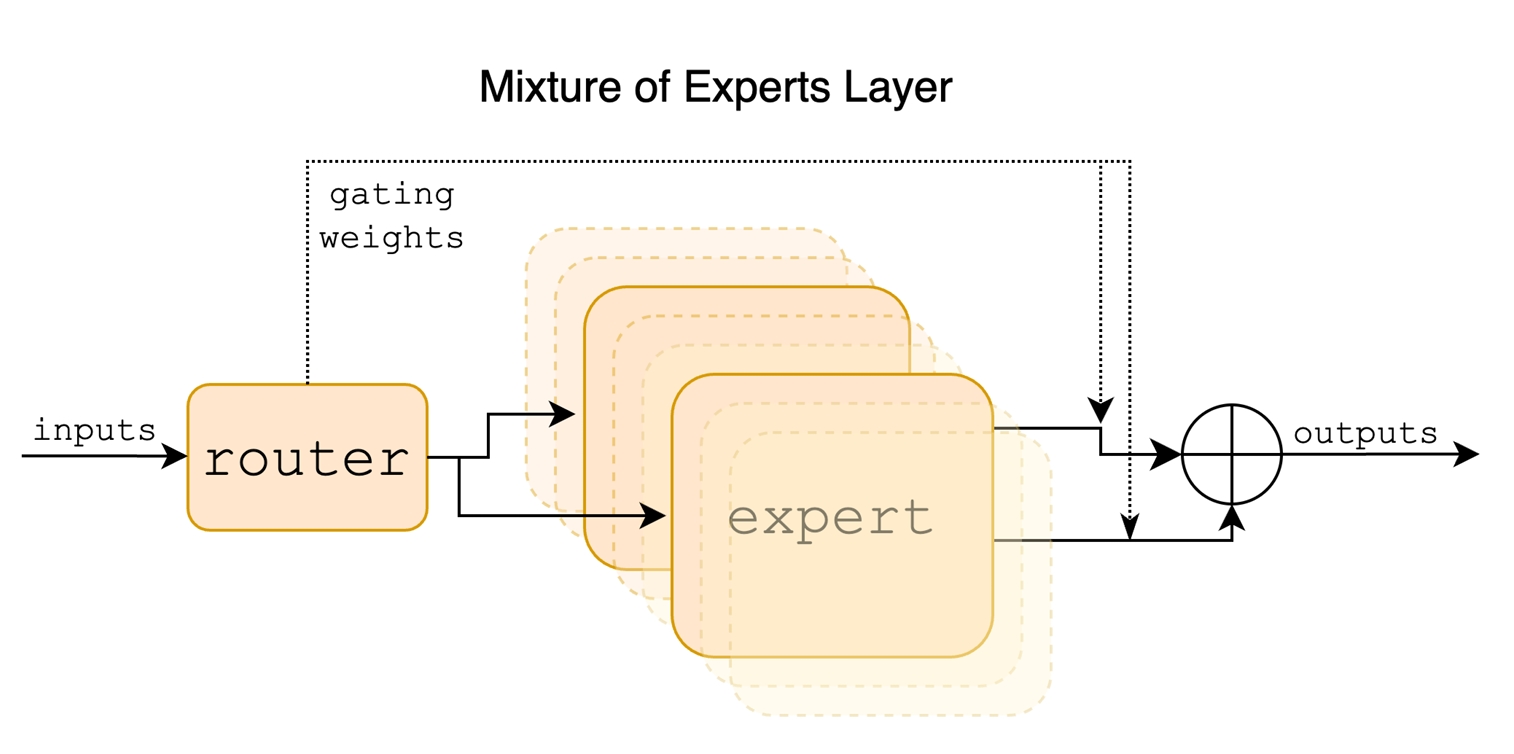
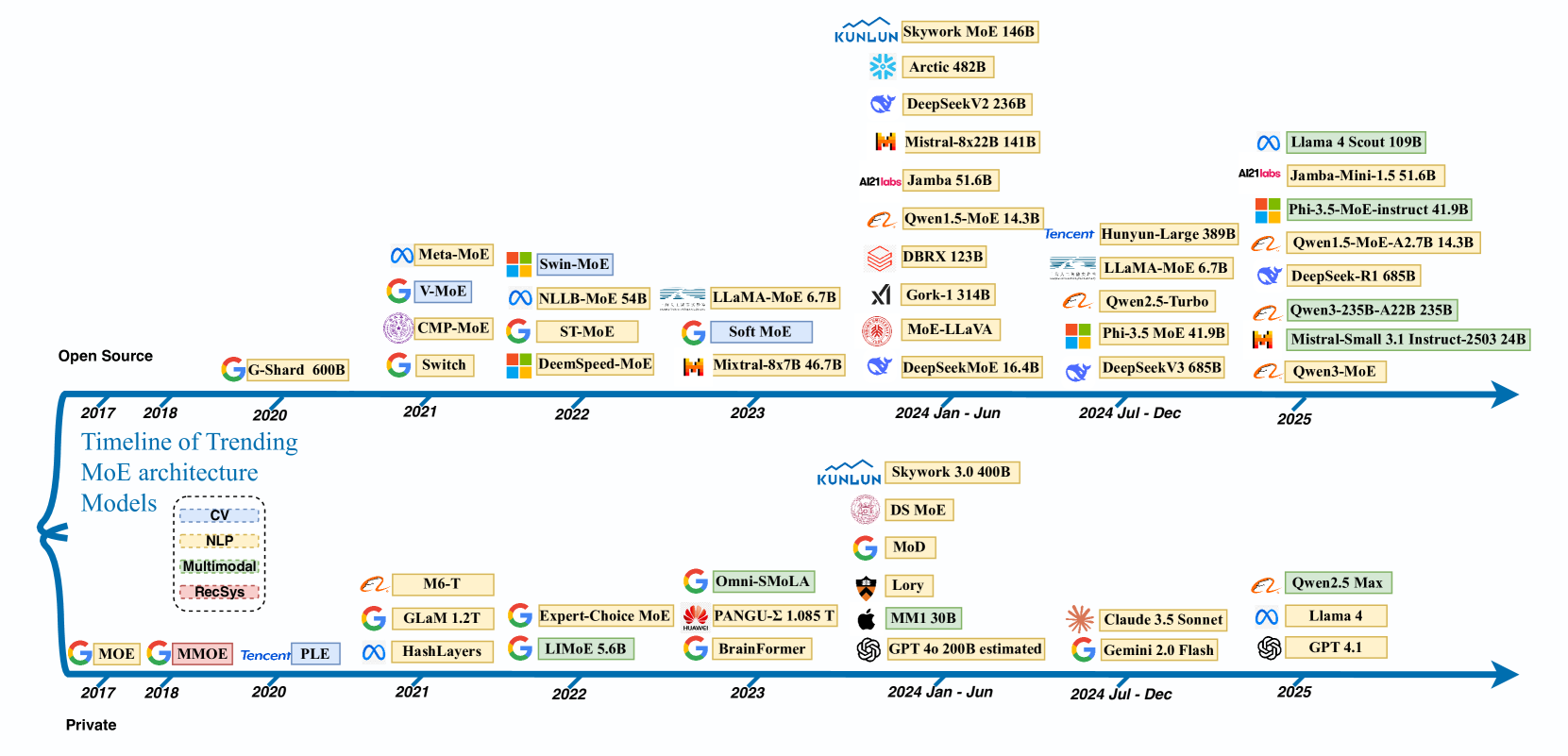
Mixture of Expertsとは何か:専門家による分業という発想
なぜ今MoEが注目されているのか
大規模言語モデルの開発競争が激化する中、モデルサイズと計算コストのジレンマが深刻化しています。パラメータ数を増やせば性能は向上しますが、それに比例して計算資源も膨大になってしまいます。例えば、従来型の「Dense(密結合)モデル」では、1兆パラメータのモデルを動かすには1兆個すべての重みを計算に使う必要があります。
このジレンマを解決する画期的なアプローチとして登場したのが「Mixture of Experts(MoE)」です。MoEは文字通り「複数の専門家の混合」を意味し、巨大なモデルを複数の専門家(エキスパート)に分割し、入力に応じて必要な専門家だけを動的に選択・活性化する仕組みです。
実際、GoogleのGemini 1.5では新しいMixture-of-Expertsアーキテクチャを導入したことで、最大モデル(1.0 Ultra)に匹敵する性能を、より少ない計算コストで実現しました。

Gemini 2.5以降においても、MoEアーキテクチャーが採用されています。
引用 (2P 要約): Gemini 2.5モデルの構造と技術的進化の要約
Gemini 2.5モデルは、テキスト・画像・音声入力に対応したマルチモーダル対応のSparse Mixture-of-Experts (MoE) Transformer。
MoE構造により、各入力トークンに対して一部のエキスパートのみを動的に活性化することで、モデルの総容量とトークンごとの計算・提供コストを分離。
このアーキテクチャの改良により、Gemini 1.5 Proと比較して性能が大幅に向上。
一方で、MoEを含む大規模トランスフォーマーモデルは学習の不安定性に悩まされることが知られている。
Gemini 2.5シリーズでは、大規模学習の安定性、信号伝播、最適化動力学の改善により、事前学習直後から高い性能を発揮。
また、Meta社のLlama 4では総パラメータ約4000億に対して、実際の計算では17億パラメータ分のみを使用することで、効率的な推論を可能にしています。
引用 : Hugging Face に公開された Meta の新世代大規模言語モデル「Llama 4 Maverick」と「Llama 4 Scout」に関する公式発表
“Llama Scout is a full MoE consisting of 16 experts. Llama Maverick uses 128 experts, but MoE and dense layers alternate. Therefore, experts are applied in half of the layers.”
Scout は全層 MoE。
Maverick は MoE 層と密な層(dense layers)を交互に配置
身近な例で理解するMoEの仕組み
MoEの動作原理を理解するために、大学の研究室を例に考えてみます。
従来のDenseモデルは、すべての教授に同時に質問するようなものです。量子力学の質問でも、文学の質問でも、全教授が一斉に回答を考え、その総合的な意見を返します。これは確実ですが、非効率的です。
一方、MoEモデルは受付(ルーター)がいる研究室のようなものです。質問内容を聞いた受付が「これは物理学の質問だから物理学科の山田教授と田中教授に聞いてください」と適切な専門家を紹介してくれます。関係ない文学や経済学の教授は関与しません。
このように、MoEでは以下の要素で構成されています。
複数の専門家(エキスパート) | それぞれ特定の知識領域に特化 |
|---|---|
ゲート/ルーター | 入力を分析し、適切な専門家を選択 |
統合メカニズム | 選ばれた専門家の出力を組み合わせて最終結果を生成 |
また、以下の用語について良くネットの記事で登場しますので覚えておきましょう。
- dense MoE → 全専門家が常に動作
- sparse MoE → 入力ごとに限られた専門家のみが動作(例:Top-1/Top-2 routing)
技術的な深堀り、MoEアーキテクチャの詳細
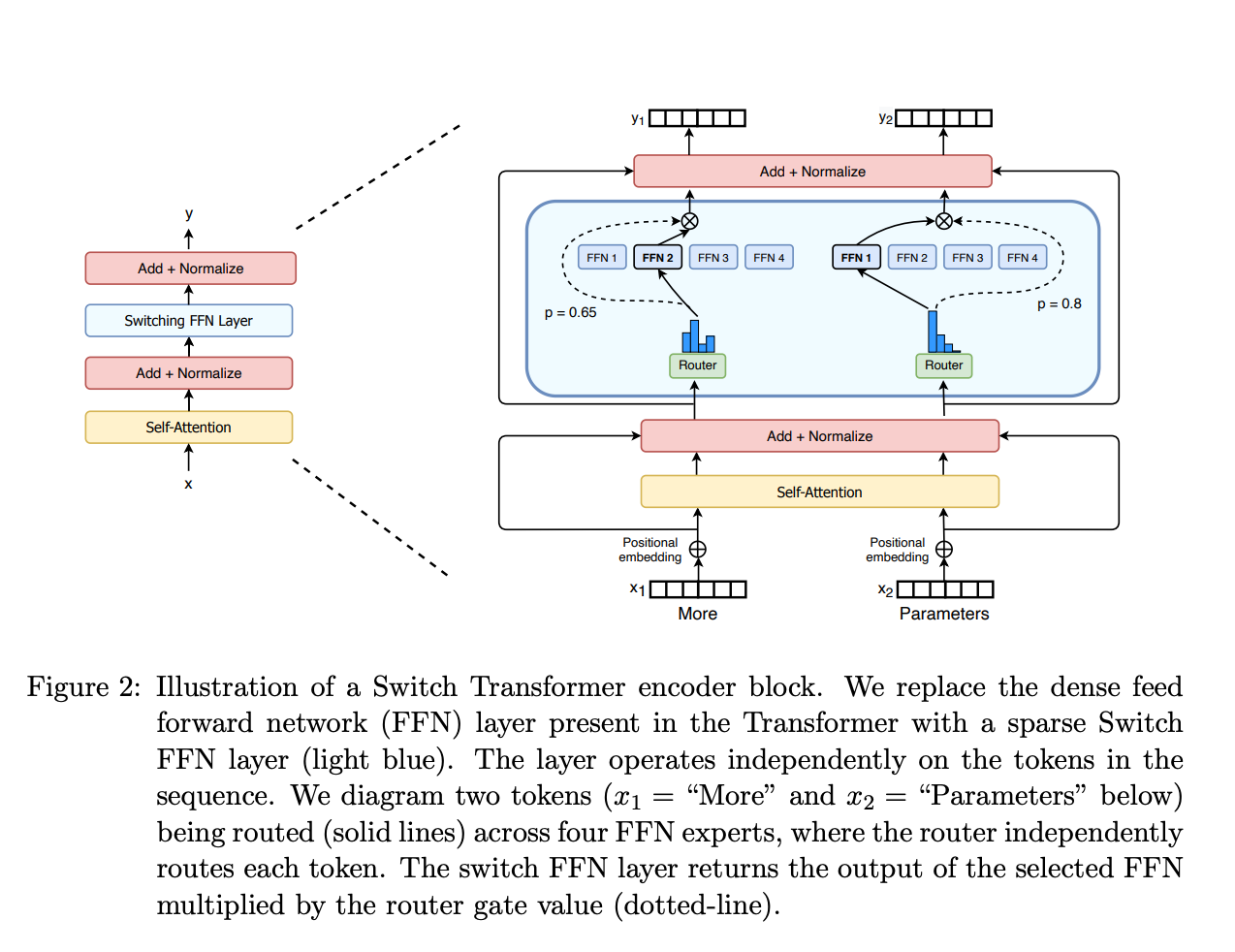
Transformerブロック内でのMoE層の実装
MoE(Mixture of Experts)は、TransformerというAIモデルの中で使われます。特に「FFN層(フィードフォワードネットワーク)」という部分を、複数の専門家(エキスパート)に置き換えることで、より効率よく計算できるようにします。
通常のTransformerでは、以下のプロセスで推論を実行します。
- 「アテンション層」で情報を整理
- 「FFN層」でその情報を処理
一方MoEでは、このFFN層の代わりに、複数の専門家が待機していて、必要な人だけが呼ばれる仕組みになります。
ここで、E_i(x)はi番目のエキスパートの出力、G(x)_iはゲートネットワークが計算したエキスパートiへの重みです。
「各専門家」は「独立した小型DNN(サブネットワーク)」で動作
MoEは、複数のニューラルネット層を並列に配置し、ルーターが動的に一部だけ使う構造です。
- 通常のニューラルネット層(例:Feed-Forward Network, FFN)を複数コピーしたもの
- 例えば「8個の専門家」を持つ層なら、同じ構造を持つFFNが8個あり、それぞれが独自の重みを持つ
- 「共通データベース」にはアクセスしない、 各エキスパートは自分の重み(パラメータ)を内部に保持
- GPUメモリ上に自身の重み(パラメータ)を保持(各専門家を異なるGPUノードに分散して配置)
以下は、GPU分散配置されているイメージを表した表です。
GPU | 保持するエキスパート | 保持パラメータ(約) |
|---|---|---|
GPU0 | Expert 1, Expert 2 | 2 × FFN |
GPU1 | Expert 3, Expert 4 | 2 × FFN |
GPU2 | Expert 5, Expert 6 | 2 × FFN |
GPU3 | Expert 7, Expert 8 | 2 × FFN |
上記の内容を前提にすると、「GPUを増やすほどより多くのエキスパートを「並列配置」できる」=「 モデルが持てる知識・専門性の幅(潜在パラメータ数)」を増やせるという理屈になります。
以下はMixtral 8×7Bの対応関係を表した図です。Mistral社の 「Mixtral 8×7B」 という名称は、MoE構造のパラメータ設計(=専門家の数と各専門家の規模) を表しています。
部分 | 意味 | 説明 |
|---|---|---|
8 | 専門家(エキスパート, experts)の数 | Transformerブロック内に8個のFeed-Forward Network(FFN)専門家が存在する。 |
7B | 各専門家のパラメータ規模(7 Billion parameters) | 各エキスパートのFFN部分が約70億パラメータ相当の規模で構成されている。 |
例えるなら、「Mixtral 8×7B」は、7B規模の教授が8人いる大学のようなものです。
質問(入力)ごとに、ルーター(事務局)が最も適した2人の教授に相談を振り分ける。全教授の知識総量は膨大(47B)だが、実際に動くのは常に2人分(13B規模)だけ、という仕組みです。
どのような専門家が存在するのか?
MoE専門家の分類と特徴一覧
分類軸 | 専門家タイプ | 主な役割・特徴 | 代表的モデル例 | 備考 |
|---|---|---|---|---|
① ドメイン特化型 | 言語/知識領域別エキスパート | 法律・医療・科学技術・ニュースなど特定分野に特化して学習。 | Mixtral 8×7B, GLaM, Llama 4 MoE | 各エキスパートが異なる語彙・文脈を自然に担当。 |
② モダリティ特化型 | マルチモーダルエキスパート | 入力モード(テキスト・画像・音声・動画など)に応じて専門家を分離。 | Google Gemini 2.5, DeepSeek V3 | Transformer内に「画像専用」「テキスト専用」専門家を持つ。 |
③ 機能特化型 | 処理機能別エキスパート | 文脈理解・推論・生成・計算など、 | Switch Transformer, Gemini Deep Think | ルーターがタスク文脈を解析し、 |
④ 階層型(Hierarchical MoE) | 大分類→小分類の2段階選択 | 言語群・モダリティ群など上位分類を経て、 | Meta NLLB-200, Gemini 2.5 | 多言語・マルチモーダルで効率的にルーティング。 |
⑤ タスク適応型(Task-Adaptive MoE) | 動的エキスパート構成 | プロンプトやタスク内容に応じ、動的に専門家を割り当てる。 | GPT-5(推定), Gemini Deep Think | 汎用LLMにおける次世代MoE設計。 |
⑥ 異構造混合型(Mixture of Functions) | 構造自体が異なる専門家 | CNN・MLP・Transformerなど異構造を混在させる。 | 研究段階 | モーダル混合や異種タスク向けの先進研究領域。 |
技術的観点からの専門家の位置づけ
項目 | 内容 |
|---|---|
専門家の学習方式 | 教師なし・自己組織化的分化(ルーターと負荷分散損失で自律形成) |
配置方法 | 各エキスパートは独立したFFN(Feed-Forward Network)としてGPUに分散配置 |
ルーティング方式 | Top-k(通常 k=1 or 2)で各入力トークンを最適なエキスパートに送る |
目的 | 専門化による性能向上とスパース化による計算効率化 |
近年の傾向 | モダリティ×ドメイン特化のハイブリッド構成(例:Gemini 2.5) |
ルーティング戦略と負荷分散の課題
MoE導入における最大の技術的チャレンジの一つが「ルーティングの最適化」です。単純に最も得意なエキスパートだけを選んでいると、特定のエキスパートに負荷が集中し、他が遊休状態になってしまう問題が発生します。
この課題に対して、研究者たちは様々な工夫を凝らしてきました。
Switch Transformerのアプローチ
GoogleのSwitch Transformerでは、各トークンを1つのエキスパートにのみルーティングする「トップ1戦略」を採用しつつ、バッチ内でエキスパートが均等に選ばれるような補助損失(auxiliary loss)を導入しています。これにより、計算効率を最大化しながら負荷分散も実現しています。
Noisy Top-K Gatingの手法
多くの実装では、ゲートの出力に擬似乱数ノイズを加えることで、スコアを意図的に揺らす手法が採用されています。これにより、常に同じエキスパートが選ばれることを防ぎ、学習中により多様な専門家が活用されるようになります。
階層型MoEの可能性
MetaのNLLB-200では、階層型MoEという興味深いアプローチを採用しています。まず「汎用エキスパート vs 専門エキスパート集合」を選び、その後で専門家内から特定言語群のエキスパートを選ぶという二段構えです。この手法により、極めて多数のエキスパートを効率よく扱うことが可能になります。
パラメータ効率と計算効率のトレードオフ
MoEの最大の魅力は「総パラメータ数は大きく、実際の計算量は小さい」という理想的なスケーリングを実現できる点です。
例えば、Mistral社のMixtral 8×7Bは総パラメータ約470億を持ちながら、各トークンの処理では約130億パラメータ分(約28%)の計算しか行いません。それでいて性能はLlama 2 70BやGPT-3.5 Turboを上回るタスクもあり、特に数学・コード生成・多言語ベンチマークで優位性を示しています。
引用 : 論文Mixtral of Experts(by Mistral)
論文内は比率の数値を直接「28%」とは書いていませんが、「総47B・アクティブ13B」を明記しているため(=13/47≒27.7%)、ユーザーの「約28%」はこの事実に基づく算出です。根拠となる該当記述は上記アブストラクトと表2「Active Params=13B」、節“Size and Efficiency”(4ページ)にまとまっています。
ただし、注意すべき点もあります。MoEモデルは全エキスパートの重みをメモリ(VRAM)に保持する必要があるため、メモリ使用量は総パラメータ数に比例して増加します。Mixtral 8×7Bを動かすには47億相当のモデルをロードする必要がありますが、計算量自体は13億のDenseモデル程度で済むという特性があります。
特定の専門家に対する負荷が集中した場合のリスクエキスパート・インバランス問題(Expert Imbalance Problem」
「ルーティング不均衡(Routing Imbalance)」として知られているこの現象を、以下技術的な観点から詳しく解説します。
MoEでは、各トークン(またはサンプル)が「ゲート(router)」ネットワークによって複数の専門家(エキスパート)のうち、上位K個(例:Top-2)にルーティングされます。
しかし、訓練初期やタスクによって入力分布が偏っていると、特定の入力パターンに対応するエキスパートが「人気」になり、他よりも多くのトークンを受け取る現象が発生します。
集中が生じる主な原因
要因 | 内容 |
|---|---|
ルーターの初期偏り | 初期重みが偏ると、 |
データ分布の非均一性 | ある専門領域(例:英語コードや数学的文脈)が全体の大部分を占めると、 |
ゲーティングの確率的特性 | SoftmaxやTop-K選択が一度学習で固定的になると、 |
バッチサイズの制約 | 分散トレーニング環境で、各デバイスにエキスパートが分割配置されていると、 |
リスクとして現れる具体的な問題
リスクの種類 | 説明 |
|---|---|
計算負荷の集中 | 一部エキスパートが多くのトークンを処理するため、GPU間でのロードバランスが崩れ、スループットが低下。 |
学習の不安定化 | 負荷の大きいエキスパートが過学習/飽和し、他のエキスパートが十分に訓練されず、性能低下。 |
収束の遅延 | 特定のルートばかりが更新されるため、全体の表現空間が偏り、勾配が不安定になる。 |
メモリオーバーフロー | 高負荷のエキスパートが処理しきれず、分散環境でのOOM(Out of Memory)を引き起こすことがある。 |
ルーティング崩壊(Router Collapse) | モデルが最終的に“全てのトークンを1つのエキスパートに送る”状態になることがある(Switch Transformer論文で報告)。 |
現在の対策状況(2024〜2025)
実装 | 負荷対策の採用状況 |
|---|---|
Switch Transformer (Google) | Auxiliary Loss + Capacity Factor を導入。 |
GLaM (Google) | Sinkhorn的なルーティング安定化を追加。 |
Mixtral 8×7B (Mistral) | Top-2 gating + load balancing loss(Switchと同様の補助損失)を採用。 |
DeepSpeed-MoE (Microsoft) | Token Drop + Load balancing + Sinkhorn。 |
Llama 4 MoE (Meta) | Router Load Loss + capacity controlを採用(公式仕様より)。 |
主要ベンダーの採用状況と戦略
OpenAIのGPT-4における秘められた革新
OpenAI自体はモデルの詳細を公表していませんが、業界ではGPT-4が8個の約2200億パラメータの専門モデルを組み合わせて総パラメータ1兆以上を実現しているという説が有力視されています。
興味深いことに、GPT-4のAPI応答が温度0でも決定的でない(同一入力でも出力が異なる)現象が観察されており、これはSparse MoEモデル特有の非決定性によるものとの分析があります。OpenAIの研究者にはGoogle在籍時にMoEの基礎となる論文を執筆したNoam Shazeer氏のような先駆者もおり、内部的にMoE技術を活用している可能性は高いと考えられます。
Googleの研究から製品への橋渡し
GoogleはMoE研究のパイオニアとして知られ、2017年の「Outrageously Large Networks (Sparsely-Gated MoE)」発表以来、Switch Transformer、GShard、GLaMなど多数の研究成果を発表してきました。
最新のGemini 2.5では「Sparse MoE Transformer」であることが明記され、テキスト・画像・音声入力にネイティブ対応しています。Gemini 2.5ではMoEのルーティング安定性向上にも取り組み、学習安定性の課題を克服して性能を大きく伸ばしたと報告されています。
Googleの取り組みは、研究レベルの成果を実製品に落とし込む好例であり、Jeff Dean氏も「今後のAIモデルはよりモジュール化・専門化が進む」と述べており、社内でのMoE重視を示唆しています。
Metaのオープンソースでの民主化
Metaは従来、大規模言語モデルをできるだけ小さく効率良く作る方針でしたが、近年MoEにも積極的に取り組み始めました。Llama 4はMetaが公式に提供した初の大規模MoE LLMであり、17Bの計算コストで400B規模のモデル性能を引き出す挑戦的な試みです。
Llama 4 Maverickは各層128個のエキスパートを持ち、各トークンあたり17億の重みのみ計算に参加する構造で、総計約4000億パラメータの容量を持ちながら推論コストは17億規模に抑えています。同様にScoutは16エキスパートで総1090億/アクティブ17億という設計です。
Anthropicの独自路線の追求
Anthropic は “Claude 4 System Card (Opus 4 & Sonnet 4)” を公開しており、モデルの安全性評価や仕様の概略が記されています。しかしその System Card には、アーキテクチャレベルで MoE/スパース活性化を使っていると明記された記述は見当たりません。
言い換えれば、現時点では Claude 4 は MoE 非採用(あるいは少なくとも公表されていない) という仮説が最も妥当です。
ただし「MoE である可能性を排除する証拠」も存在しないため、将来的な内部実装や非公開仕様で MoE を含む可能性は否定できません。
オープンウェイトモデルにおけるMoE対応
Mixtralが切り開いた新しい地平
Mistral社のMixtral 8×7Bは、オープンウェイトで利用可能な最も大規模かつ高性能なMoE LLMの一つです。各層に8個のFFNエキスパートを持ち、各トークンでその中から2個だけを計算する(トップ2ルーティング)設計になっています。
MixtralはApache 2.0ライセンスで公開され、誰でも利用・改変可能です。これはオープンソースコミュニティにとって画期的な出来事であり、研究者や開発者が実際のMoEモデルで実験・応用を行える環境が整いました。
中国勢の積極的な参入
Alibaba社のQwenシリーズでは、Qwen-2に57B-A14B (MoE)というモデルが含まれており、総パラメータ570億・アクティブ140億という構成のMoE版がHugging Face上でも公開されています。
さらにQwen 2.5-Maxでは20兆トークンで事前学習した大規模MoEモデルを開発中と述べており、中国圏でのMoE技術の民主化に貢献しています。
OSSエコシステムの充実
技術基盤も着実に整備されています。GPT-NeoXはMegatron-LMとDeepSpeedを基盤としてMoE層のサポートを実装し、最新版ではStanford開発の「Megablocks」ライブラリを用いたDropless MoE (DMoE)に対応しています。
FacebookのFairseqにはMoE-LMの公式実装例が提供され、MicrosoftのDeepSpeed-MoEもGitHubで公開されています。これらの動きにより、以前は研究室レベルに限られていたMoEが、広くOSSコミュニティで再現・応用できる技術になりつつあります。
MoEの適用領域と限界
MoEが向いているケース
MoEは以下のようなケースで特に効果を発揮します。
超大規模モデルの構築
総パラメータ数が数千億から数兆に及ぶようなモデルを構築する場合、MoEはほぼ必須の技術となります。計算資源の制約を回避しながらモデル容量を拡大できるため、フロンティアモデルの開発には欠かせません。
マルチタスク・マルチドメインの統合
異なるドメインや言語を扱う統合モデルでは、各エキスパートが特定の領域に特化することで、全体として高い汎用性と専門性を両立できます。例えば、多言語翻訳モデルでは言語グループごとに専門エキスパートを配置することが効果的です。
高スループット環境での推論
データセンターやクラウド環境で大量のリクエストを処理する場合、MoEの効率性が最大限に活かされます。バッチ処理やパイプライン並列と組み合わせることで、スループットを大幅に向上させることができます。
MoEが不向きなケース
一方で、以下のような状況ではMoEの採用を慎重に検討する必要があります。
エッジデバイスでの動作
スマートフォンやIoTデバイスなど、メモリが限られた環境では、全エキスパートの重みを保持する必要があるMoEは不向きです。総パラメータ数分のメモリが必要になるため、小型化を重視する場合は従来のDenseモデルの方が適しています。
決定論的な出力が求められる場合
MoEのルーティングは本質的に非決定的な要素を含むため、完全に再現可能な出力が必要なアプリケーションでは注意が必要です。金融取引や医療診断など、監査や検証が重要な領域では、この特性が問題になる可能性があります。
学習の安定性が重要な場合
MoEの学習は従来モデルよりも不安定になりやすく、特に初期段階でのハイパーパラメータ調整が難しいという課題があります。限られたリソースで確実に学習を成功させたい場合は、より成熟した手法を選ぶ方が賢明かもしれません。
LLMのデファクトスタンダードになるだろうと推測
技術的な進化の方向性
MoE技術は今後さらに洗練されていくことが予想されます。現在研究が進んでいる方向性として、以下のような取り組みが注目されています。
動的エキスパート生成
現在のMoEは固定数のエキスパートを持ちますが、タスクに応じてエキスパートを動的に生成・削除する研究が進んでいます。これにより、より柔軟で効率的なモデル設計が可能になるでしょう。
量子化との組み合わせ
QMoEという手法では、1.6兆パラメータのSwitch Transformerを1ビット未満/重みまで量子化し、3.2TB相当のモデルを160GBに圧縮するデモが報告されています。このような極限的な圧縮技術との組み合わせにより、MoEの実用性がさらに高まることが期待されます。
エキスパートの統合と蒸留
学習はMoEで行い、推論時は単一モデルに変換する手法も提案されています。これにより、MoEの学習効率の恩恵を受けつつ、デプロイメントの複雑さを回避できる可能性があります。
デファクトスタンダード化への道筋
2025年時点で、Mixture of Expertsは大規模言語モデル設計の重要な選択肢として確固たる地位を築きつつあります。Google GeminiやMeta Llama 4といった最先端モデルが続々とMoEを採用しており、「もはやMoE抜きでは超巨大モデルを効果的に訓練・運用できない」というコンセンサスが生まれつつあります。

ただし、すべてのLLMがMoEに移行するわけではないでしょう。小〜中規模モデルや特定用途に特化したモデルでは、従来のDenseアーキテクチャが引き続き有効です。MoEは「超大規模モデル」「マルチタスク統合」「高スループット推論」といった特定の要件において真価を発揮する技術であり、適材適所での使い分けが重要になります。
エコシステムの成熟に向けて
MoEがより広く普及するためには、以下の要素が重要になってきます。
ツールチェーンの整備
現在、MoEモデルの訓練や推論には専門的な知識が必要ですが、より使いやすいフレームワークやライブラリの開発が進んでいます。Hugging FaceのMoE解説ブログでも紹介されているように、コミュニティによる教育コンテンツも充実してきています。
ハードウェアの最適化
NVIDIAをはじめとするハードウェアベンダーも、MoE向けの最適化を進めています。特に、エキスパート間の動的なロードバランシングを効率的に行うための専用アクセラレータの開発が期待されています。
標準化の推進
MLPerfベンチマークでMixtralが採用されるなど、業界標準としての位置づけも進んでいます。今後、より多くのベンチマークやコンペティションでMoEモデルが採用されることで、技術の成熟と普及が加速するでしょう。
まとめ
Mixture of Expertsは、単なる技術的な最適化手法を超えて、AIモデルの設計思想そのものに変革をもたらしています。「すべてを知る巨大な単一モデル」から「専門性を持つ複数のエキスパートの協調」へという転換は、人間の知識体系や組織構造により近い形とも言えるでしょう。
MoEの採用により、これまで計算資源の制約で実現できなかった規模のモデルが現実的になりつつあります。同時に、各エキスパートが特定の領域に特化することで、モデル全体としての解釈可能性や制御可能性が向上する可能性も秘めています。
技術的な課題は残されているものの、主要ベンダーの積極的な採用とオープンソースコミュニティの活発な開発により、MoEは着実に成熟度を高めています。今後数年のうちに、MoEは大規模言語モデルの標準的なアーキテクチャの一つとして定着し、さらなるAIの発展を支える基盤技術となることでしょう。
私たちエンジニアとしては、この技術の可能性と限界を正しく理解し、適切な場面で活用していくことが重要です。MoEは万能薬ではありませんが、適切に使えば計算効率とモデル性能の両立という、これまで相反していた目標を実現できる強力なツールです。今後もMoEの動向に注目しながら、実プロジェクトでの活用方法を探っていきたいと思います。
























