


AWS Athenaのアーキテクチャを理解する - Prestoエンジンの分散処理メカニズム
Athenaの基盤技術とPrestoエンジンの役割
AWS Athenaは、オープンソースの分散SQLエンジン「Presto」を基盤として構築されています。実際にプロジェクトでAthenaを使い始めた当初、単純にS3上のファイルを読み込んでいるだけだと思っていましたが、裏側では驚くほど洗練された分散処理が行われていることを知りました。
Prestoは「コーディネーターノード」と複数の「ワーカーノード」から構成される分散アーキテクチャを採用しています。ユーザーがSQLクエリを発行すると、コーディネーターがクエリを解析してプランニングを行い、各ワーカーに処理を割り振ります。この際、全ワーカーがメモリ内でパイプライン処理を実行することで、大規模データに対して高速な並列クエリ実行を実現しています。
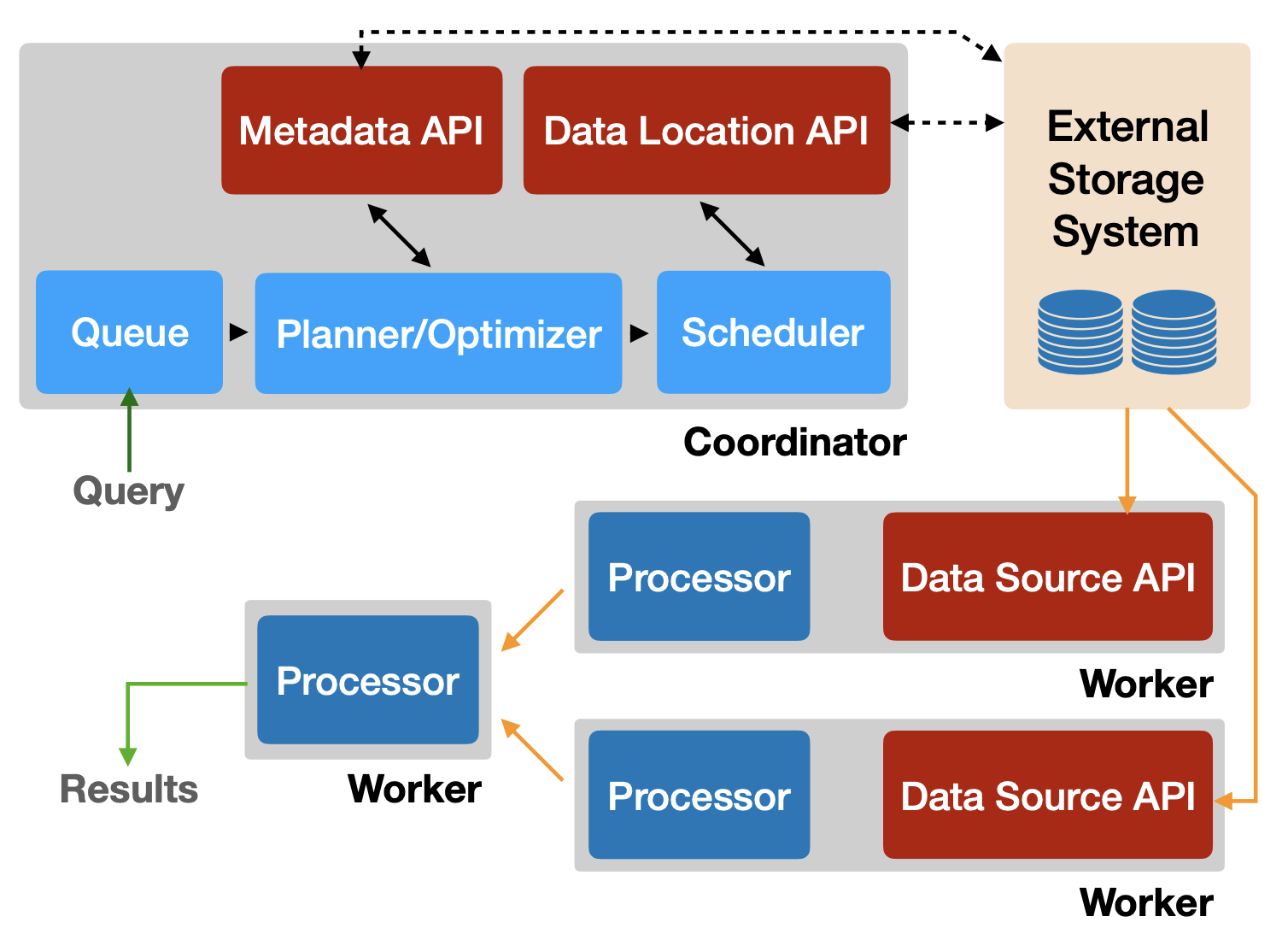
Athenaの最大の魅力は、これらの基盤インフラを一切意識する必要がない点です。サーバーレスサービスとして提供されているため、自前でクラスタを構築・管理する手間が省けます。クエリ実行に必要なリソースはAWS側で自動的に割り当てられ、利用者は単にデータの場所を指定してスキーマを定義するだけで即座に分析を開始できるのです。
データの読み込みとスキャン方式の仕組み
Athenaはデータレイク上のファイルを直接スキャンしてクエリ処理を行う「スキーマ・オン・リード方式」を採用しています。これは従来のデータウェアハウスとは大きく異なるアプローチです。データを事前にロードする必要がなく、S3上に保存されたCSV、JSON、Parquet、ORC、Avroなどのファイルに対して直接SQLを実行できます。
クエリ実行時の処理フローは以下のようになります。
- 対象データファイルを内部で複数のスプリット(データ範囲)に分割する
- これらのスプリットを並列に各ワーカーノードに割り当てて読み込む
- 特にParquetやORCのようなカラムナフォーマットは内部でブロックごとに圧縮・インデックスされており、効率的な並列読み込みが可能
実際のプロジェクトで経験したのですが、gzip圧縮されたCSVファイルは分割不可能なため、ファイル全体を単一ノードで順次読み込むことになり、並列処理効率が著しく低下しました。このような経験から、Athenaで効率よく処理するには適切なフォーマット選択とファイルサイズの調整が極めて重要だということを学びました。
パーティションとデータカタログの活用
AthenaはHadoop/Hiveと同様のパーティション概念をサポートしており、大量データを日付やカテゴリ別にS3内のサブプレフィックス(フォルダ)に区切って保存できます。
テーブル定義時にパーティションキーを指定すると、AthenaはAWS Glue Data Catalog(Hiveメタストア相当)にテーブルスキーマやパーティション情報を登録します。クエリ実行時には、まずカタログから該当テーブルのパーティション情報を取得し、WHERE句の条件に基づき不要なパーティションをプルーニング(読み飛ばし)します。
実際のケースでパーティション条件を追加しただけで68.1GBスキャンしていたクエリが35.4MBのスキャンで済むようになり、処理時間も大幅に短縮された例があります。これほどまでに劇的な改善が見られるため、パーティション設計は真剣に検討する価値があります。
パーティション管理における重要なポイント
パーティション情報の管理において、以下の点に注意が必要です。
- 新規データ追加時にはGlueのクローラーや
MSCK REPAIR TABLEコマンドでカタログを更新する - Glue Data Catalogを介することで、AthenaだけでなくAmazon EMRやRedshift Spectrumなど他サービスともメタデータを共有できる
- 極端にパーティション数が多いテーブルでは、パーティション索引(Partition Index)機能や動的パーティション投影を活用する
エンジンの進化と最新機能
Athenaエンジン自体も継続的に進化しており、2020年代にはPrestoのオープンソース版であるTrino(旧称PrestoSQL)の機能も取り込みつつエンジンバージョン2以降が提供されています。
近年のAthenaは従来の静的ファイルに対するクエリだけでなく、Apache HudiやApache Icebergといったトランザクション対応のテーブル形式にも対応しました。これにより、データレイク上でのレコード単位の更新・削除やタイムトラベルクエリといった高度な操作も、Athena経由で実行可能になっています。
さらに、Athenaは連携クエリ(Federated Query)機能によって、S3以外のデータソース(RDSやDynamoDB、CloudWatch Logsなど)にもLambdaをコネクタとして介しクエリを投げることができます。このようにAthenaはオープンソースエンジンの利点を活かしつつ、AWSサービスとの統合や拡張機能によってデータ分析基盤としての柔軟性を高めています。
パフォーマンスとコスト最適化の実践テクニック
従量課金モデルを理解した上での最適化戦略
Athenaは従量課金制(Pay-Per-Query)のサービスであり、クエリ実行ごとにスキャンしたデータ量に基づいて料金が発生します。その料金は$5/TB(圧縮後データ)が基本となっており、1クエリあたり最低10MBまでの読み取りが課金対象です。
したがって、クエリ性能の向上はそのままコスト削減に直結します。Athenaでは適切なデータレイアウトやクエリ設計によって、データスキャン量を可能な限り減らすことが重要になります。
パーティションによる劇的なコスト削減
時系列ログ分析においてパーティションを活用することで劇的にI/Oを削減できます。私たちの実例として、ある結合クエリで日付条件を追加することで、全スキャンが大幅に削減され、実行時間も短縮されたケースがあります。
パーティション最適化における主要な戦略は以下の通りです。
- 必ずパーティション列で絞り込むことで不要データの読み取りを避ける
- Glue Data Catalogのパーティション索引(Partition Index)機能を活用する
- 数万~数百万といった極端にパーティション数が多いテーブルでは動的パーティション投影を利用する
カラムナ形式と列プルーニングによる最適化
入力データを列指向ストレージ形式(ParquetやORC)に変換することで、Athenaは必要なカラムだけを読み込む「列プルーニング」が可能になります。
実際の効果を測定したところ、数百列あるデータでもクエリで使う十数列分だけをS3から取得すればよいため、同じデータを行指向のCSVで保存した場合に比べ30~90%もスキャン量を削減できました。
表 主要ファイル形式のパフォーマンス比較
ファイル形式 | スキャン効率 | 並列処理適性 | 圧縮率 | Athena推奨度 |
|---|---|---|---|---|
CSV(非圧縮) | 低 | 高 | なし | △ |
CSV(gzip圧縮) | 低 | 低(分割不可) | 高 | △ |
JSON | 低 | 中 | なし | △ |
Parquet | 高(列プルーニング可) | 高 | 高 | ◎ |
ORC | 高(列プルーニング可) | 高 | 高 | ◎ |
この表が示すように、ParquetやORCのような列指向かつ圧縮された形式で保存することがAthenaのベストプラクティスとなります。
ファイル圧縮とサイズの最適化
データファイルを圧縮することでファイルサイズが小さくなり、その分S3から読み出すデータ量も減少し、クエリ料金も下がります。またネットワーク帯域の節約にもなり全体の処理時間短縮につながります。
ファイルサイズと個数の最適化において重要なポイントは以下の通りです。
- 1ファイルあたり128MB程度を目安スプリットサイズとして推奨
- 極端に巨大なファイルは単一ノードに処理が偏る可能性がある
- 逆に小さすぎるファイルが大量にある状態も非効率(メタデータ読み込みやS3リクエストのオーバーヘッド増加)
- 圧縮形式としてはSnappyやZstandard(zstd)が圧縮率と速度のバランスが良い
CTASとUNLOADを活用したデータ変換と最適化
CTAS(CREATE TABLE AS SELECT)の活用
Athenaはクエリ結果を新たなテーブルとしてS3に書き出すCTAS構文をサポートしています。この機能を使い、生データの変換・前処理やサマリーテーブルの作成を行うことが可能です。
CTAS時に出力フォーマットとしてParquetやORC、圧縮コーデック、パーティション鍵やバケット数を指定できるため、大量の非最適な生ログ(例:圧縮されていないJSONやCSVの集まり)から、分析に適したパーティション列付きのParquetテーブルを生成するといった利用がされています。
CTASによるデータ変換は一種のバッチETL処理であり、AthenaをETLエンジン代わりに使ってデータレイク内のデータを再編成・最適化する手法です。AWS Glueによる変換が難しい場合でも、AthenaのSQLだけで簡易的な加工ができる点は現場で重宝されています。
UNLOADによる結果出力最適化
従来Athenaのクエリ結果はデフォルトでCSV形式でS3に出力されていましたが、2022年よりUNLOAD文が導入され、クエリ結果を直接Parquet・ORC・Avro・JSONなどの好きな形式・圧縮でS3出力できるようになりました。
UNLOADを使うと、結果データを後続処理や機械学習で再利用する際に、わざわざCSVをパースし直す必要がなくなり便利です。実際、私たちの過去の事例で、大規模クエリの結果をSnappy圧縮付きParquetで書き出したところ、248GBのCSV相当データが62GBまで圧縮され、75%ものストレージ節約になった事があります。
クエリチューニングの実践的アプローチ
Athena自体のクエリオプティマイザはコストベース最適化など高度化してきていますが、ユーザー側でもSQLの書き方で性能を左右できます。
実際のプロジェクトで効果があったチューニングテクニックは以下の通りです。
ORDER BY ... LIMIT Nの形にすると分散ソート+早期停止により効率が大幅に向上する- 結合順序は基本的に左側に大きなテーブル、右側に小さなテーブルを置く方が有利
- 結合キーの分布に偏りがないか確認(極端に偏っていると一部ノードに処理が集中しボトルネックになる)
- 結合と同時にパーティション条件も指定する
最近Athenaは実行プランの可視化ツールも提供しており、GUI上で各ステージのデータ規模や実行順序を確認しボトルネック分析ができるようになりました。こうした分析を通じて、必要な列だけ選択する、不要な重複計算を避ける、など一般的なSQLチューニングも適用できます。
セキュリティと権限管理の実装パターン
IAMによるアクセス制御の基本設計
Amazon AthenaはAWSの他サービス同様、AWS IAM(Identity and Access Management)ポリシーによって利用をコントロールできます。
Athena自体の操作権限(クエリ実行やDDL実行など)はサービス別のAthena APIアクションに対するIAM許可で制御されます。また、Athenaでクエリを行う際には実際にデータが置かれているS3バケットに対するアクセス権限が必要です。
実際の権限設計で重要になるのは、以下のような階層的なアクセス制御です。
- Athena自体へのアクセス権限(クエリ実行権限)
- S3バケット/プレフィックスに対する
GetObject許可 - クエリ結果バケット(
aws-athena-query-results-<AccountID>-<Region>)へのPutObject許可
この仕組みにより、データレベルのアクセス制御はS3権限と連動して管理可能となります。
データ暗号化の実装
Athenaで扱うデータの暗号化は主にS3側の設定によります。AthenaはSSE-S3(S3管理鍵によるサーバサイド暗号化)、SSE-KMS(KMS管理鍵によるサーバサイド暗号化)、およびクライアント側の暗号化データに対応しています。
暗号化実装における重要なポイントは以下の通りです。
- 該当データにアクセスするための適切なKMS権限がユーザーにあれば暗号化されたオブジェクトも透過的にクエリ可能
- クエリ結果の出力先もオプションでSSE-KMS暗号化でき、結果データの保護を強化できる
- 送受信中のデータはTLS暗号化されるが、クライアントが独自にデータを復号する場面はない
Lake Formationとの統合によるファインガレイン権限制御
大規模なデータレイク環境では、テーブルごとのアクセス権限や列単位・行単位でのマスキング等、より細かなデータアクセス制御が求められます。
AthenaはAWS Lake Formationと統合することで、これらデータレイクのファインガレイン権限を実現できます。Lake Formationはデータカタログ上に定義されたデータベース・テーブル・列に対して、IAMユーザーやグループごとに許可ポリシーを設定できるサービスです。
Lake Formation統合モードでの実装例は以下のようになります。
- 社員データベースのテーブルから個人識別情報の列だけをマスキング設定
- 権限のないユーザーがAthenaでクエリしてもその列はNULL等で返される
- RowレベルフィルタやセルレベルFinal暗号化も可能
実際にLake Formationを導入したプロジェクトでは、従来のIAM権限だけでは実現できなかった細かな権限制御が可能になり、コンプライアンス要件を満たしつつデータ活用を推進できました。
ネットワークとその他のセキュリティ対策
Athenaは完全マネージドサービスであり、ユーザー側でEC2インスタンス等を管理しないため、ネットワークの観点ではAthenaサービスエンドポイントへのアクセスを制御する形になります。
追加のセキュリティ対策として以下を実装できます。
- AWS PrivateLinkエンドポイントを利用してVPC内からプライベートアクセス
- CloudTrailで操作ログを監査(誰がいつどのクエリを実行したか記録)
- ワークグループ設定で意図しないユーザーがクエリ結果を閲覧できないよう制御
主要なユースケースと実践的な適用例
大規模ログ分析・データレイク分析の実装
Athenaの代表的なユースケースの一つが、S3に蓄積された巨大なログデータの対話的分析です。
実際のプロジェクトでは、以下のようなログ分析パターンを実装しました。
- CloudTrailのAPIログをAthenaでSQL検索し、全AWSリソースの操作履歴を横断的に調査
- CloudFrontやALB/ELBのアクセスログから人気コンテンツやユーザー行動を集計
- VPCフローログを分析して不正アクセスの兆候を検知
- アプリケーションのエラーログをフィルタして特定期間の不具合を洗い出す
従来であればログ解析のためにHadoopクラスターやElasticsearchを用意してインデックスを作成する手間がありましたが、Athenaなら「データをS3に置くだけで、あとは必要な時にSQLを投げる」という手軽さで数百GB~数TB規模のログも短時間で集計可能です。
特にイベント発生時のみ分析を行うような場合、常時サーバを稼働させておく必要がないAthenaはコスト効率の良いログ分析基盤となります。
セキュリティ分野での活用
AWS公式もAthenaを用いたログ分析ソリューションを多数提案しており、セキュリティ分野では以下のような連携パターンが実装できます。
- GuardDutyやSecurity Hubと連携して検知イベントをAthenaで掘り下げ調査
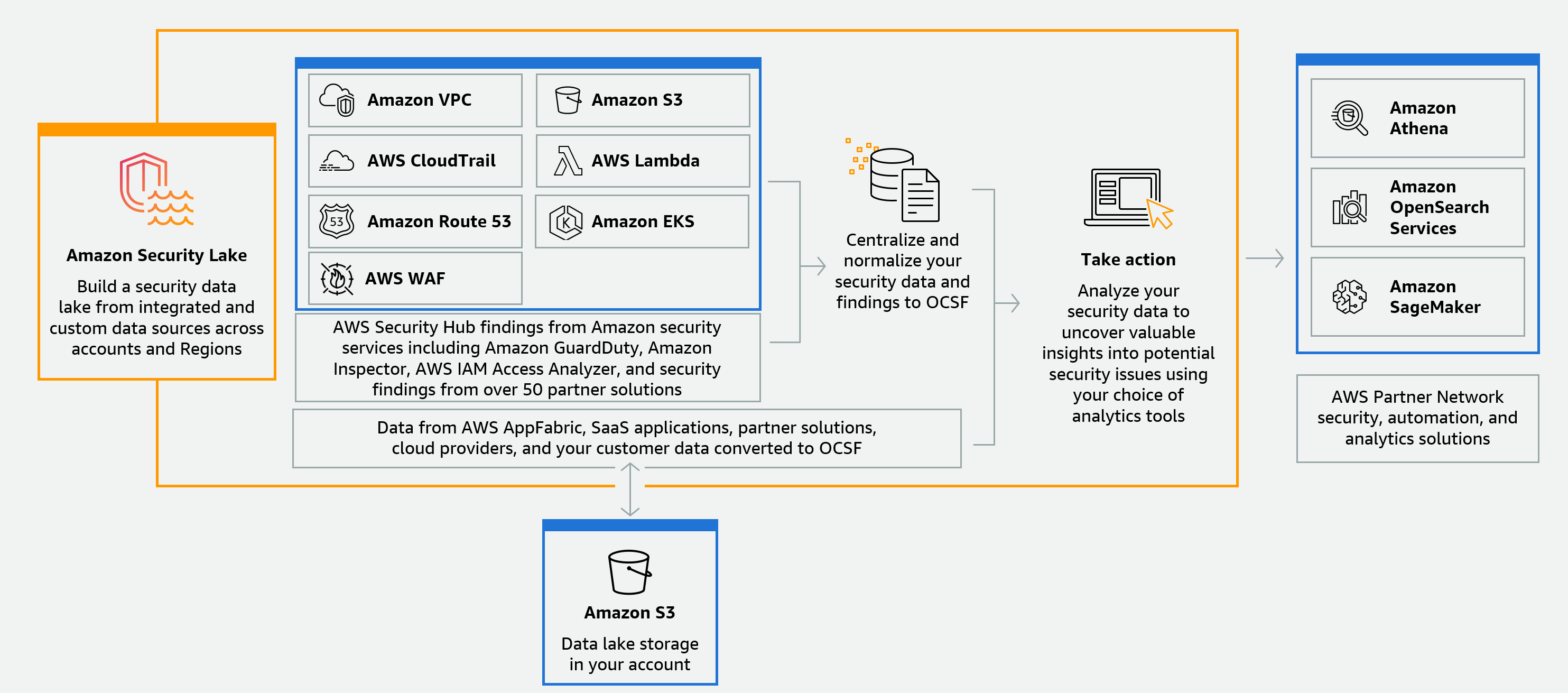
- Amazon Security Lakeサービス(各種セキュリティログをS3に統合管理)からAthenaで横断検索
実際にSecurity Lakeを導入したプロジェクトでは、複数のAWSアカウントやセキュリティツールからのログを一元化して分析できるようになり、インシデント対応時間が大幅に短縮されました。
BIツールとの連携実装パターン
Amazon QuickSightとのネイティブ統合
AthenaはビジネスインテリジェンスB(BI)/可視化ツールのデータソースとしても活用されています。Amazon純正のBIサービスであるQuickSightはAthenaとネイティブ統合されており、QuickSight上でAthenaのデータソースを設定すれば、ダッシュボードのクエリ発行時にリアルタイムでAthenaがS3データを読み込み結果を返します。
実装における注意点は以下の通りです。
- 頻繁な更新が必要なリアルタイムダッシュボードにはあまり向かない(都度課金が発生)
- 日次・週次レポートや低頻度の経営指標モニタリングなどには手軽でコスト効率も良い
- データレイク上の売上データをAthenaで集計しQuickSightで可視化することで、DWHを持たずとも経営ダッシュボードを実現可能
サードパーティBIツールとの接続
QuickSight以外にもAthenaは標準のJDBC/ODBCドライバーを提供しているため、TableauやPowerBI、Superset等あらゆるサードパーティBIツールから接続可能です。
実際にTableauとの連携を実装した際の設定手順は以下の通りでした。
- AthenaのJDBCドライバーをTableauサーバーにインストール
- データソース設定でAthenaのエンドポイントとIAM認証情報を設定
- Glue Data Catalogのテーブル定義を自動的に認識し、TableauからSQLクエリを発行可能に
データサイエンス・機械学習前処理での活用
Athenaはデータサイエンティストが手元のノートブックから使う対話型分析エンジンとしても便利です。
実際の機械学習プロジェクトでの活用パターンは以下の通りです。
- JupyterやZeppelinといったノートブック環境からAthenaのJDBC経由でクエリを実行
- 大量データ全体の集計はAthenaにSQLで任せ、結果のサンプルをPySparkやpandasで詳細分析
- UNLOAD機能を使ってAthenaで作成した特徴量データセットを直接S3にParquet出力し、Amazon SageMakerの学習ジョブに連携
Athenaはトランザクション処理や複雑な更新には不向きですが、データレイク上の生データに素早く集計・抽出処理をかける点でデータサイエンスの初期データ探索や特徴量計算フェーズに適しています。
競合サービスとの詳細比較と使い分け戦略
Google BigQueryとの比較
アーキテクチャの違い
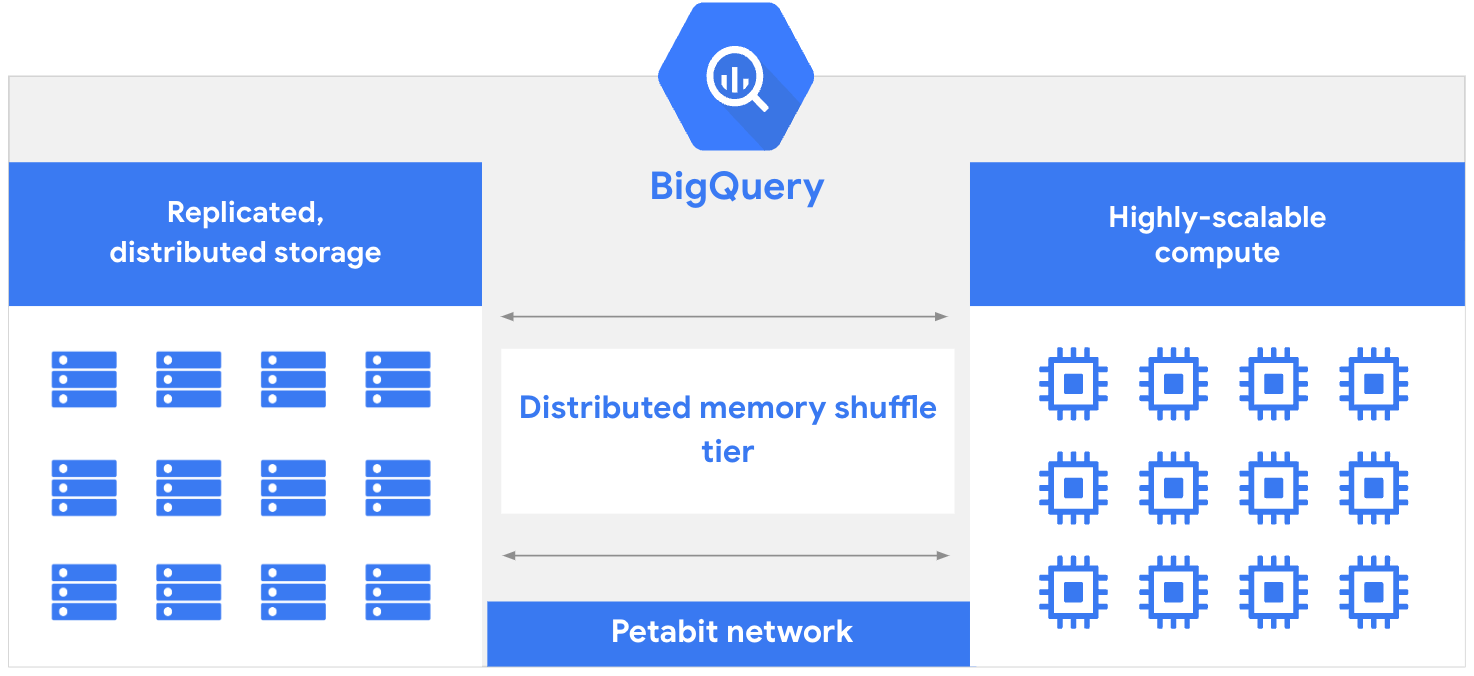
BigQueryはGoogle Cloudが提供するフルマネージドのクラウドDWHサービスで、Athenaと同様にストレージとコンピュートが分離したサーバーレスアーキテクチャを持ちます。
主要な違いは以下の通りです。
- BigQueryのクエリエンジンはGoogle社内で開発されたDremelという大規模分散クエリ基盤をベース
- データは事前にBigQueryのストレージにロードするか、外部テーブル機能を使って外部ストレージ参照を定義する必要がある
- AthenaがS3上の生データを直接スキャンするのに対し、BigQueryは内部ストレージに最適化格納されたデータに対して高速クエリを実行
性能とコストの比較
表 AthenaとBigQueryの主要指標比較
比較項目 | AWS Athena | Google BigQuery |
|---|---|---|
クエリ性能(大規模) | 良好 | 優秀(ペタバイト級も秒〜分) |
同時実行数 | 制限あり(共有リソース) | 100並列以上可能 |
キャッシュ機能 | なし | 自動キャッシュあり |
マテリアライズドビュー | なし | あり |
オンデマンド料金 | $5/TB | $5/TB(+ストレージ料金) |
定額プラン | なし(最近DPU予約購入追加) | スロット購入で使い放題 |
BigQueryは特に大規模集計や多者結合でもDremelの大規模並列処理によりスループットが高く、Athenaでは難しい高い同時実行クエリ数にも対応可能です。一方でBigQueryはクエリ実行時に内部で多段のシャッフルや永続化を行うため、低レイテンシ(サブ秒レベル)の応答にはあまり向いていません。
Amazon Redshift Spectrumとの比較
Redshift SpectrumはAWSのデータウェアハウスRedshiftに組み込まれた機能で、RedshiftクラスターからS3上のデータに対して直接SQLクエリを実行できるサービスです。
利用シーンの使い分け
Redshift Spectrumを選択すべきケースは以下の通りです。
- 既にRedshiftを運用しており追加でS3データも分析したい
- S3上の巨大な事実テーブルとRedshift内のディメンションテーブルを結合するような複雑なクエリ
- 自前クラスタ内の処理なので安定性・予測可能性が必要
一方、Athenaが適しているケースは以下の通りです。
- 常時DWHは不要だがS3データを時々分析したい
- 低頻度・スポット的な分析
- 完全サーバーレス志向でインフラ管理を避けたい
実際のプロジェクトでは、定常的なBI基盤にはRedshift Spectrum、アドホックな調査や開発時の検証にはAthenaという使い分けをすることが多いです。
Snowflakeとの比較
Snowflakeはクラウド上で提供されるフルマネージドのデータウェアハウスで、ストレージと計算リソースを分離した新世代アーキテクチャを採用しています。
Snowflakeの特徴とAthenaとの違い
Snowflakeの最大の違いは、データをあらかじめSnowflake内部にロードする必要がある点です。その代わり一度取り込まれたデータはSnowflake側で自動的に統計情報や圧縮が管理され、高速なクエリが可能になります。
Snowflakeが優位な点は以下の通りです。
- エンタープライズ向けに設計されており、大規模クエリの性能と同時実行処理に優れる
- 自動で結果キャッシュを利用し、直前に実行されたクエリと全く同じ結果になる場合は即座にキャッシュ結果を返す
- マテリアライズドビューやクラスタキー(ソートキー)の設定が可能
- 自動チューニングにより、インデックス管理や真の意味でのパーティション管理は不要
一方でSnowflakeの課金はクレジット制で、仮想ウェアハウスのサイズと稼働時間に応じて消費されるため、スポット的利用には割高です。
Presto/Trinoとの比較
PrestoおよびそのコミュニティフォークであるTrinoは、Athenaの基盤でもある分散SQLエンジンを自前で運用したい場合の選択肢です。
自前運用のメリット・デメリット
Presto/Trinoを選択する理由は以下の通りです。
- Athenaよりも柔軟なカスタマイズや様々なデータソースの統合ができる
- オープンソースであるため、細かなチューニングを行って特定クエリに最適化できる
- 最新機能やプラグインを取り込める
ただし、自前Presto/Trinoの運用負荷はかなり高く、以下の作業が発生します。
- クラスタノードのプロビジョニング
- ソフトウェアのインストール・アップデート
- ジョブの監視、ログ管理、スケーリング
- 障害時の切り分けやチューニングナレッジの蓄積
大規模で複雑なデータ基盤を社内で制御したい場合はPresto/Trino、自前管理を避けスピード重視ならAthenaという選択になるでしょう。
Databricksとの比較
DatabricksはApache Sparkをベースにしたクラウド統合分析プラットフォームで、近年Lakehouseアーキテクチャを提唱しています。
Databricksの適用領域
Databricksが適しているケースは以下の通りです。
- 大規模なバッチETLや機械学習前処理
- Delta Lakeフォーマットを使ったACIDトランザクションや高効率なアップサート
- Spark SQLだけでなくストリーミング・機械学習まで含めた統合プラットフォームが必要
一方、Athenaが適しているケースは以下の通りです。
- シンプルなSQL専用エンジンで十分
- スポット的な単発クエリや即席分析
- 完全サーバーレスで運用負荷を最小化したい
実際のプロジェクトでは、定常パイプライン処理はDatabricks、スポット的なSQL分析はAthenaという使い分けも見られます。
まとめ
ここまでAWS Athenaの技術詳細から実践的な活用方法まで解説してきました。Athenaはサーバーレスかつ従量課金という手軽さからデータレイク分析の入り口として非常に有用であり、特にログ分析やスポットクエリで真価を発揮します。
一方でトランザクション処理や低遅延連続クエリには適さず、そのような用途ではRedshiftやSnowflake、Elasticsearchなど専用ソリューションの方が適しています。
Athenaを最大限活用するために重要なポイントを改めて整理すると以下のようになります。
- 適切なデータレイアウト(パーティション、ファイル形式、圧縮)によってスキャン量を抑える
- CTASやUNLOADを活用してデータ変換・最適化を行う
- Lake FormationやIAMを使った適切な権限管理を実装する
- BIツールや機械学習パイプラインとの連携を戦略的に設計する
- Athenaの不得意分野を見極めて他のツールと補完し合う
Athena自体もエンジン強化や新機能追加が続いているため、最新情報をウォッチしつつ最適なデータ分析基盤を設計していくことが求められるでしょう。
個人的な見解としては、Athenaは「必要な時にすぐ、大量データにSQLでアクセスできる」という利便性が最大の価値であり、この特性を活かした使い方をすることが成功の鍵だと考えています。
過度にAthenaに期待せず、適材適所で活用することで、コスト効率の良いデータレイク分析基盤を実現できるはずです。
























