



Amazon S3 にオブジェクト本体を書き換えずにクエリ可能なメタデータをアタッチできる「アノテーション」が2026年6月16日に一般提供を開始しました。基本概念から API 操作、運用上の注意点、Ragate ならではの活用観点までを整理します。
Amazon S3 アノテーションとは
Amazon S3 アノテーションは、オブジェクト本体を書き換えることなく、オブジェクトへ名前付きのデータペイロードをアタッチできるメタデータ機能です。専用の API でアノテーションを作成・取得・一覧・削除でき、オブジェクトを再アップロードする必要はありません。いつでも変更・削除が可能なため、付随するコンテキストを最新の状態に保てます。
アノテーションはオブジェクトと同じ耐久性・整合性のプロパティを持ち、コピーやレプリケーションの際にオブジェクトと一緒に移動し、オブジェクトを削除すると合わせて削除されます。
S3 には従来からオブジェクトタグやユーザー定義メタデータがあります。ユーザー定義メタデータ(x-amz-meta-)はアップロード時に設定して以降は不変であるのに対し、アノテーションはアップロード後に付与でき後から変更できる点が異なります。オブジェクトタグとアノテーションの主な違いは次のとおりです。
特性 | オブジェクトタグ | アノテーション |
|---|---|---|
オブジェクトあたり最大数 | 10/オブジェクトバージョン | 1,000/オブジェクトバージョン |
最大サイズ | キー128文字+値256文字 | 名前512バイト+ペイロード1 MiB |
データ形式 | キー・バリュー文字列ペア | 任意の UTF-8 テキスト(JSON, XML, YAML など) |
変更可否 | 可(PutObjectTagging) | 可(PutObjectAnnotation) |
アップロード時に設定 | 可(PutObject, POST) | 不可(アップロード後の PutObjectAnnotation のみ) |
使い分けの目安として、構造化データを扱いたい場合、256文字を超えるペイロードが必要な場合、10件を超えるメタデータを付けたい場合はアノテーションが向いています。一方で、IAM ポリシー連携やライフサイクルルールのフィルタ、コスト配分レポートが必要な場合はオブジェクトタグを選ぶとよいでしょう。あわせて S3 Metadata との関係も重要です。アノテーションは「データの実体」、S3 Metadata のアノテーションテーブルは「クエリ可能にする仕組み」という役割分担です。テーブルを有効化すると、内容が Apache Iceberg テーブルとして自動で最新化され、Amazon Athena などから大規模にクエリできます。
主なユースケース
アノテーションの活用は、データ管理、ガバナンス、検索という3つの観点に整理できます。いずれも、オブジェクトに付随する文脈を別システムで管理する代わりに、オブジェクトそのものへ直接ひも付けられる点が共通の利点です。
データ管理の観点では、ペタバイト規模のメディアアセットに対して、トランスクリプトや字幕、ライセンス情報といったメタデータを別システムで同期させることなくオブジェクトへ直接付与できます。ETL や処理パイプラインのステータスの併記、データリネージュや監査証跡の保持といった用途にも適しています。
ガバナンスやコンプライアンスの観点では、PII フラグや保持ポリシーといったコンプライアンスラベルを付与できます。ライフサイエンス分野での規制ステータスや承認履歴の付与、金融分野での AI 生成サマリーの付与といった使い方が挙げられています。アーカイブ済みのデータセットでも、オブジェクトを復元せずにアノテーションをクエリできる点は運用上の利点です。
検索や AI データディスカバリの観点では、アノテーションテーブルと Athena を組み合わせた大規模クエリが可能になります。ML 推論結果や AI 生成のエンベディング、コンテンツモデレーションのラベル、文書分類の出力などを格納しておけば、AI エージェントがデータを発見しやすくなります。AWS は S3 Tables MCP server 経由の自然言語クエリにも触れています。
API 操作の基本
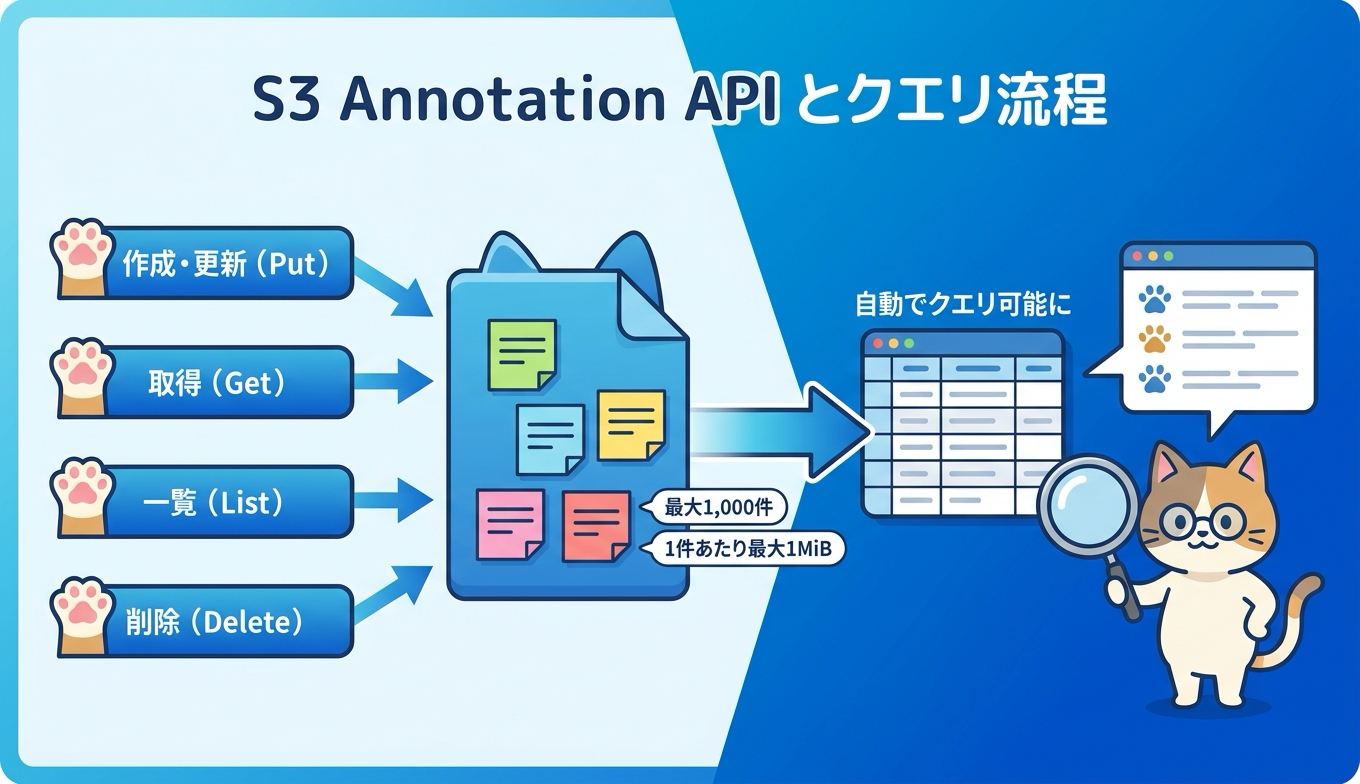
アノテーションには専用の API が用意されています。作成または上書きには PutObjectAnnotation、取得には GetObjectAnnotation、一覧には ListObjectAnnotations、削除には DeleteObjectAnnotation を使います。PutObjectAnnotation は同じ名前で再度呼び出すと内容を更新します。AWS CLI からは次のように操作できます。
aws s3api put-object-annotation \
--bucket my-media-bucket \
--key videos/documentary-2026.mp4 \
--annotation-name mediainfo \
--annotation-payload ./mediainfo.jsonaws s3api get-object-annotation \
--bucket my-media-bucket \
--key videos/documentary-2026.mp4 \
--annotation-name mediainfo \
./mediainfo-output.jsonaws s3api list-object-annotations \
--bucket my-media-bucket \
--key videos/documentary-2026.mp4aws s3api delete-object-annotation \
--bucket my-media-bucket \
--key videos/documentary-2026.mp4 \
--annotation-name mediainfo制限値も把握しておきましょう。1つのオブジェクトバージョンあたり最大1,000個のアノテーションを付与できます。名前は UTF-8 で1バイトから512バイトまでで、文字・数字・アンダースコア・ピリオド・ハイフンが使えますが、aws または s3 で始まる名前は使えません。ペイロードは1バイトから1 MiB までで有効な UTF-8 テキストとし、バイナリは Base64 エンコードして格納します。オブジェクトあたりの総ストレージは最大1 GiB です。これらは公式ユーザーガイドの MiB・GiB 表記で、約1MB・約1GB に相当します。
IAM については、付与に s3:PutObjectAnnotation、取得に s3:GetObjectAnnotation のアクションが必要であることが明記されています。一覧や削除(ListObjectAnnotations / DeleteObjectAnnotation の操作)に対応する IAM アクション名は参照情報で明示されていないため、ここでは断定せず操作名で示します。レプリケーションを行う場合は、送信元バケットの権限に s3:GetObjectVersionAnnotationForReplication を追加し、レプリケーションを拒否したい場合は s3:ReplicateObjectAnnotation を deny します。
S3 Metadata 連携とクエリ、運用上の注意点
アノテーションテーブルを有効化すると、アノテーションが Apache Iceberg 形式のテーブルとして自動で最新化され、Amazon Athena から SQL でクエリできます。特定のアノテーションを持ち、その JSON 内の値が条件を満たすオブジェクトを抽出するクエリは次のように書けます。
SELECT DISTINCT bucket, object_key
FROM "s3tablescatalog/aws-s3"."b_my_media_bucket"."annotation"
WHERE name = 'mediainfo'
AND CAST(json_extract_scalar(text_value, '$.audio_tracks') AS INTEGER) > 8更新タイミングについては、ジャーナルテーブルがニアリアルタイムで更新されるのに対し、アノテーションテーブルは約1時間以内に更新されると案内されています。これは SLA ではなく目安と捉えるとよいでしょう。アノテーションの作成・更新・削除は s3:ObjectAnnotation:Put および s3:ObjectAnnotation:Delete のイベント通知として受け取れます。
運用上はいくつかの挙動と制約を押さえておく必要があります。アノテーションは親オブジェクトと同じ暗号化方式で保存時に暗号化され、SSE-S3・SSE-KMS・DSSE-KMS を継承し S3 Bucket Keys にも対応しますが、SSE-C は非対応です。アノテーションは特定のオブジェクトバージョンにひも付くため、新しいバージョンを作成しても前バージョンのアノテーションはコピーされません。追加・更新・削除を行っても親オブジェクトの ETag は変わりません。バージョニングを有効にしていても、アノテーションの削除は恒久的かつ不可逆で、削除マーカーやバージョン履歴は残らない点に注意が必要です。
機能面では、S3 Express One Zone(ディレクトリバケット)に非対応であるほか、S3 Inventory レポートや S3 Storage Lens、S3 on Outposts などでも利用できません。CopyObject は5 GiB 未満であれば単一操作でアノテーションも一緒にコピーされますが、マルチパートコピーでは既定でコピーされないため --copy-props all による明示的な指定が必要です。料金は、親オブジェクトが S3 Glacier など別のストレージクラスにあっても常に S3 標準のレートで課金され、オブジェクトを復元せず取り出し料金を払うことなくクエリや操作ができるとされています。具体的な単価は告知本文に記載がないため S3 の料金ページで確認してください。提供リージョンは、Middle East(UAE)と Middle East(Bahrain)を除く商用リージョンおよび中国リージョン(北京・寧夏)です。
Ragate の視点での活用ポイント
クラウドと AI 開発に取り組む立場から見ると、S3 アノテーションはデータ基盤と AI 活用の両面で扱いやすい機能です。現実的な切り口を3つ挙げます。
第一に、データ基盤の整備です。オブジェクトの文脈情報を別のデータベースやサイドカーファイルで管理していたケースでは、その同期処理が運用の負担になりがちでした。アノテーションはオブジェクトと一緒に移動し削除時に合わせて消えるため、文脈情報をオブジェクト側に寄せることで、同期のずれや孤立した管理データの発生を抑えやすくなります。
第二に、AI や RAG での活用です。ML 推論結果や文書分類の出力、コンテンツモデレーションのラベルをアノテーションに格納し、アノテーションテーブルを通じて Athena でクエリすれば、RAG の検索対象を絞り込む前処理を S3 側で完結させやすくなります。ペイロード上限が1 MiB、総量1 GiB である点を踏まえ、何をアノテーションに置き何をベクトルストアに置くかを設計段階で切り分けると現実的です。
第三に、ガバナンス運用です。PII フラグや保持ポリシー、規制ステータスといったコンプライアンスのコンテキストを付与しておけば、アーカイブ済みのデータでも復元せず状態を確認できます。ただし、IAM ポリシーのフィルタやライフサイクルルールの条件にはオブジェクトタグが向いているため、ポリシー制御に使う属性はタグ、リッチな文脈情報はアノテーション、という役割分担を意識した設計が有効です。削除が不可逆であることや SSE-C・S3 Express One Zone に非対応であることも、あらかじめ運用ルールへ織り込んでおくとよいでしょう。Ragate では、こうした特性を踏まえ、お客様のデータ基盤や AI 活用に無理なく組み込む設計を検討していきます。









.webp?q=65&fm=webp&w=400&h=260&fit=crop)














