



サーバーレスとは何か:インフラ管理からの解放と新たな責任
サーバーレスの本質を理解する
「サーバーレス」という名前を聞くと、サーバーが存在しないかのような印象を受けますが、実際にはサーバーは存在しています。ただし、その管理責任が開発者からクラウド事業者へと移行しているというのが正確な表現です。
AWSが提供するサーバーレスコンピューティングでは、必要なときにだけコンピューティングリソースが自動的に割り当てられ、処理が完了すると自動的に解放される仕組みになっています。
従来のサーバー運用では、OSのパッチ適用、ミドルウェアの更新、キャパシティプランニングなど、多くの運用タスクが必要でした。これらの作業は本来のビジネス価値を生み出すものではありませんが、システムの安定稼働のためには欠かせない作業です。
サーバーレスアーキテクチャでは、これらの「差別化につながらない重労働」(Undifferentiated Heavy Lifting)をクラウド事業者に任せることで、開発チームはビジネスロジックの実装に専念できるようになります。
従来型アーキテクチャとの違い
サーバーレスアーキテクチャと従来型のアーキテクチャの最も大きな違いは、「常時稼働」から「イベント駆動」への思考の転換にあります。従来型では、アプリケーションサーバーは24時間365日稼働し続け、リクエストを待ち受けています。一方、サーバーレスでは、イベントが発生した瞬間にのみ実行環境が起動し、処理を実行します。
この違いを理解するために、レストランの経営に例えてみましょう。従来型は常設レストランのようなもので、お客様が来ても来なくても、店舗の賃料やスタッフの人件費は発生します。一方、サーバーレスはケータリングサービスのようなもので、注文があったときだけ料理を作り、配達します。どちらにも一長一短がありますが、用途に応じて適切に選択することが重要です。
サーバーレスアーキテクチャの動作原理
イベント駆動型実行モデルの仕組み
サーバーレスの動作を理解するために、AWS Lambdaを例に実行フローを詳しく見ていきましょう。以下の4つのステップで処理が進行します。
1.イベントの発生 | HTTPリクエスト、ファイルアップロード、データベースの変更、定期実行など、様々なトリガーがイベントとして機能します。 |
|---|---|
2.実行環境の起動 | イベントを受けて、AWSが自動的にコンテナやマイクロVMなどの実行環境を構築・起動します |
3.関数の実行 | 事前にデプロイされたコードが呼び出され、ビジネスロジックが処理されます |
4.実行環境の解放 | 処理完了後、実行環境は一定時間保持された後、自動的に解放されます |
この一連の流れにおいて、開発者が意識する必要があるのは3番目の「関数の実行」部分のみです。インフラの準備や片付けは全てAWSが自動的に処理してくれます。
コールドスタートとウォームスタートの理解
サーバーレスを実装する上で避けて通れないのが「コールドスタート」問題です。これは、しばらく使用されていなかった関数を初めて実行する際に、実行環境の起動に時間がかかる現象を指します。
実行環境が既に起動している状態で関数が呼び出される「ウォームスタート」では、数ミリ秒で応答が返ってきます。しかし、コールドスタートの場合、言語やランタイムによっては数百ミリ秒から数秒の遅延が発生することがあります。AWSの公式ブログでも、この問題への対処法が詳しく解説されています。
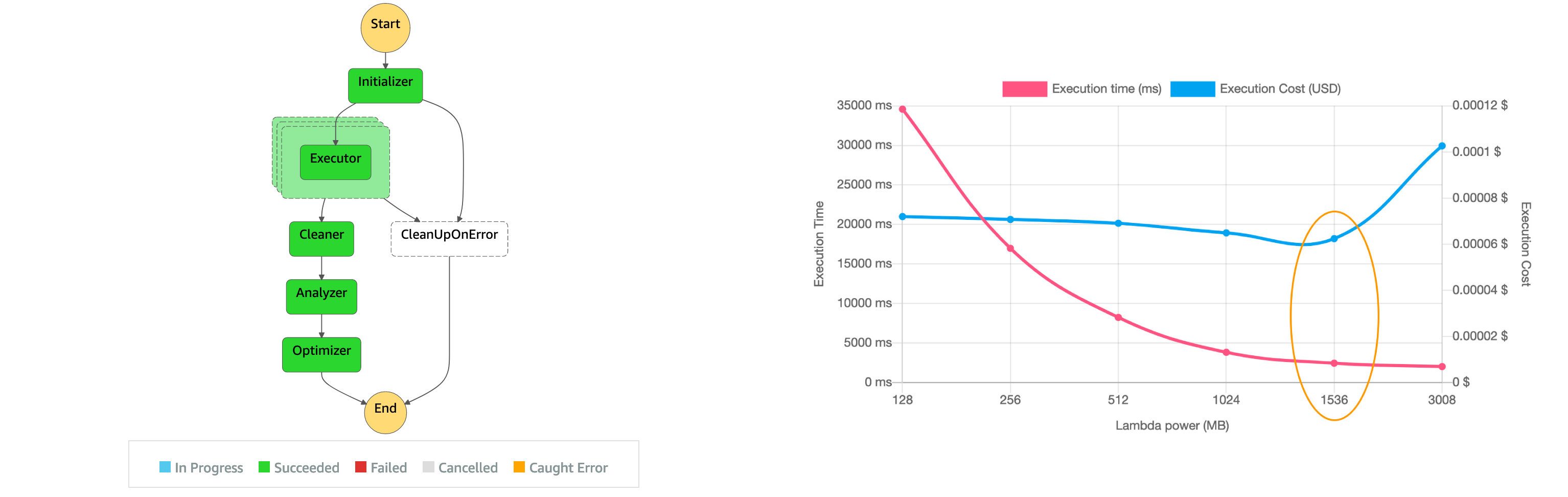
特にJavaやC#などのJVMベースの言語では、初期化に時間がかかる傾向があります。一方、PythonやNode.jsなどのスクリプト言語は比較的高速に起動します。実際のプロジェクトでは、この特性を理解した上で適切な言語選択を行うことが重要です。
NoSQLデータベースの基礎と実践
NoSQLとは:RDBMSとの本質的な違い
「NoSQL」は"Not Only SQL"の略で、リレーショナルデータベース(RDBMS)とは異なるデータモデルを採用したデータベースの総称です。RDBMSが厳格なスキーマと「ACID特性」(原子性、一貫性、独立性、永続性)を重視するのに対し、NoSQLデータベースは柔軟性とスケーラビリティを優先します。
NoSQLデータベースには主に以下の4つのタイプが存在します。
NoSQLの主要なタイプとその特徴を理解することで、適切な選択が可能になります。
- キー・バリュー型:最もシンプルな構造で、キーと値のペアでデータを管理
- ドキュメント型:JSON形式などの半構造化データを扱い、入れ子構造も表現可能
- カラムファミリー型:大量のカラムを効率的に管理し、ビッグデータ分析に適している
- グラフ型:ノードとエッジでデータの関係性を表現し、ソーシャルネットワーク分析などに活用
Amazon DynamoDBの特徴と活用シーン
AWSが提供する「Amazon DynamoDB」は、完全マネージド型のNoSQLデータベースサービスです。DynamoDBの公式ドキュメントによれば、ミリ秒単位の一貫したパフォーマンスと99.999%の可用性を提供しています。
DynamoDBの最大の特徴は、そのスケーラビリティにあります。秒間数千万リクエストを処理できる能力を持ちながら、使用した分だけ課金される「オンデマンドモード」も選択できます。これにより、トラフィックの予測が困難なスタートアップから、大規模なエンタープライズシステムまで、幅広い用途で活用されています。
実際の設計において重要なのは、「パーティションキー」と「ソートキー」の設計です。RDBMSのように後から自由にインデックスを追加することは制限があるため、アクセスパターンを事前に十分に検討する必要があります。例えば、ECサイトの注文データを管理する場合、ユーザーIDをパーティションキーに、注文日時をソートキーに設定することで、特定ユーザーの注文履歴を効率的に取得できます。
サーバーレス導入で得られる具体的なメリット
運用負荷の劇的な削減
サーバーレスアーキテクチャ最大のメリットは、インフラ運用の負荷が大幅に削減されることです。従来のシステムでは、深夜のサーバー障害対応、定期的なOSパッチ適用、ログローテーションの設定など、多くの運用タスクが必要でした。
実際にサーバーレスを導入した企業の事例を見てみましょう。FINRA(米国金融業規制機構)では、AWS Lambdaを活用して毎日750億件もの市場イベントデータを分析しています。もし従来型のアーキテクチャで同じ処理を実現しようとすれば、数百台のサーバーを24時間365日運用する必要があったでしょう。しかし、サーバーレスアーキテクチャを採用することで、インフラ運用チームなしで、この膨大な処理を実現しています。

コスト最適化の実現
サーバーレスの「従量課金制」は、特に変動の大きいワークロードにおいて大きなコスト削減効果を発揮します。例えば、月末月初だけアクセスが集中する経費精算システムや、キャンペーン時だけ負荷が高まるECサイトなどでは、ピーク時に合わせてサーバーを準備する必要がなくなります。
AWS Lambdaの無料利用枠を活用すれば、月間100万リクエスト、約40万GB秒の実行時間まで無料で利用できます。小規模なAPIや定期バッチ処理であれば、ほぼゼロコストで運用することも可能です。実際、私が関わったあるスタートアップでは、月間数十万アクセスのWebサービスを月額数ドルで運用していました。
開発速度の向上とビジネスアジリティ
サーバーレスアーキテクチャでは、インフラの準備を待つことなく、すぐに開発を開始できます。新しい機能を追加する際も、新たなLambda関数を作成してデプロイするだけで、自動的にスケーラブルな実行環境が用意されます。
Thomson Reuters社の事例では、サーバーレスアーキテクチャを採用することで、わずか5ヶ月で大規模な分析基盤を本番稼働させました。従来型のアーキテクチャでは、インフラの調達と構築だけで数ヶ月かかることを考えると、この開発速度の向上は驚異的です。
引用:AWS Lambda事例
Thomson Reuters は、サーバーレスアーキテクチャを活用して、自社の使用状況分析サービスで 1 秒あたり最大 4,000 個のイベントを処理しています。このサービスは、通常のトラフィックの 2 倍のスパイクを確実に処理し、高い耐久性を備えています。同社は、AWS の使用を開始してからわずか 5 か月で、このサービスを本番環境にデプロイしました。
サーバーレスの落とし穴:デメリットとリスクの正しい理解
実行時間制限という制約
AWS Lambdaには15分という実行時間の上限があります。この制限は、長時間実行されるバッチ処理や、大量のデータを処理する分析ジョブには大きな制約となります。
実際のプロジェクトで経験した失敗例をご紹介しましょう。ある企業で、夜間バッチで数百万件のデータを集計する処理をLambdaで実装しようとしたケースがありました。開発環境のテストデータでは問題なく動作していましたが、本番環境の大量データでは15分の制限に引っかかり、処理が途中で強制終了してしまいました。結果的に、このバッチ処理はECS Fargateで実装し直すことになりました。
このような失敗を避けるために、以下のような処理はサーバーレスには不向きであることを理解しておく必要があります。
長時間実行が必要な処理の代替案を検討する際の選択肢を整理します。
- 動画のエンコーディングなど、CPU集約的で時間のかかる処理
- 大規模なデータマイグレーション
- 機械学習モデルの学習処理
- リアルタイムストリーミング処理
ベンダーロックインという現実
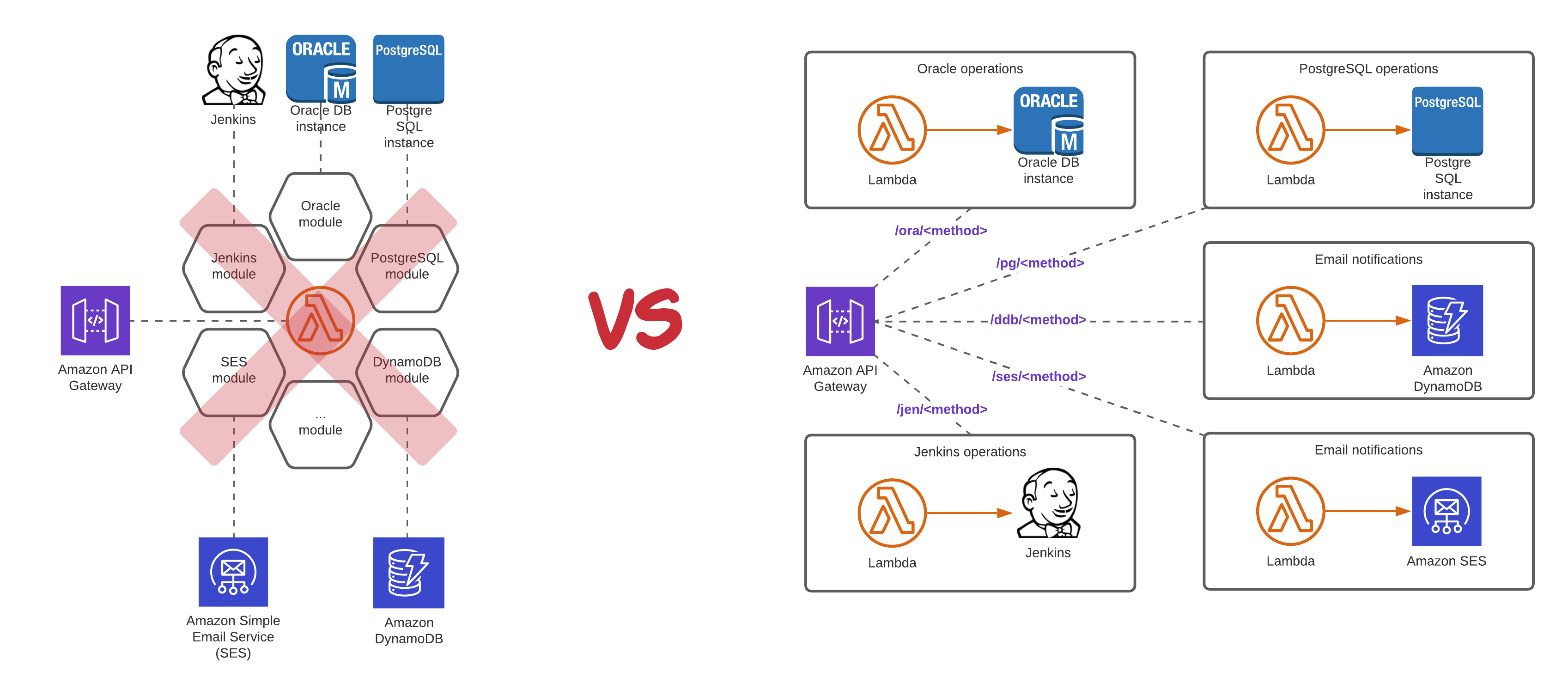
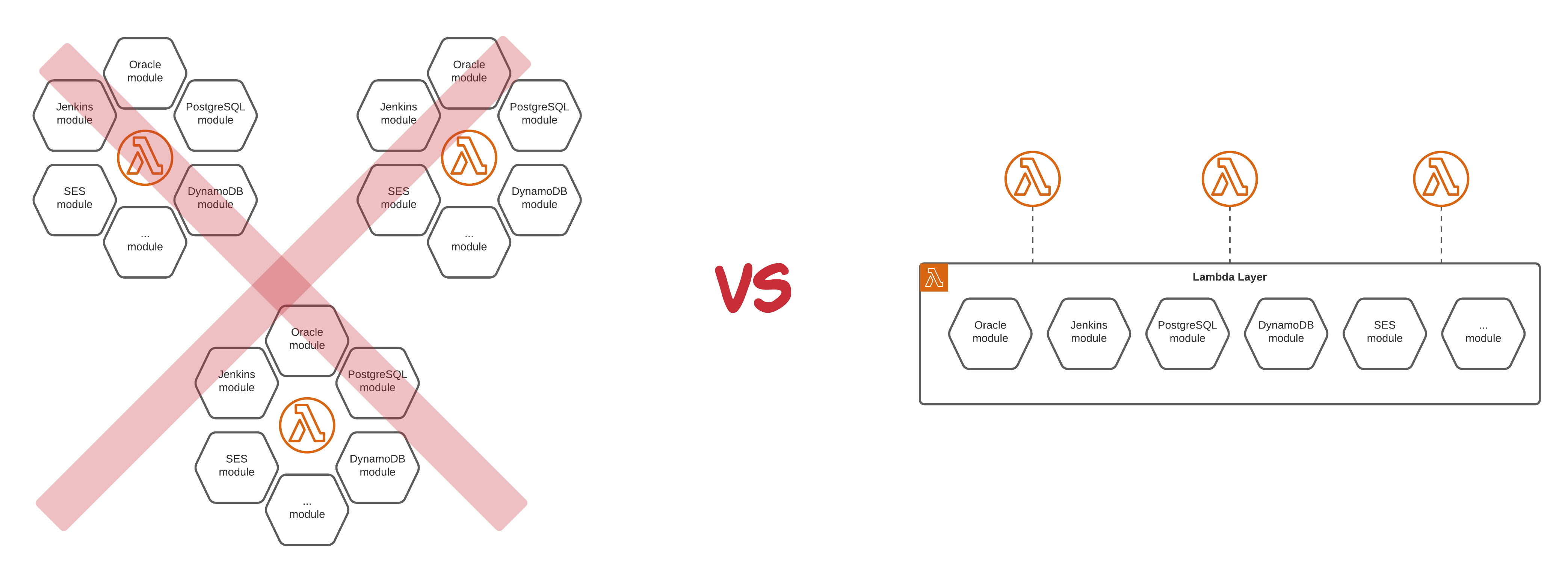
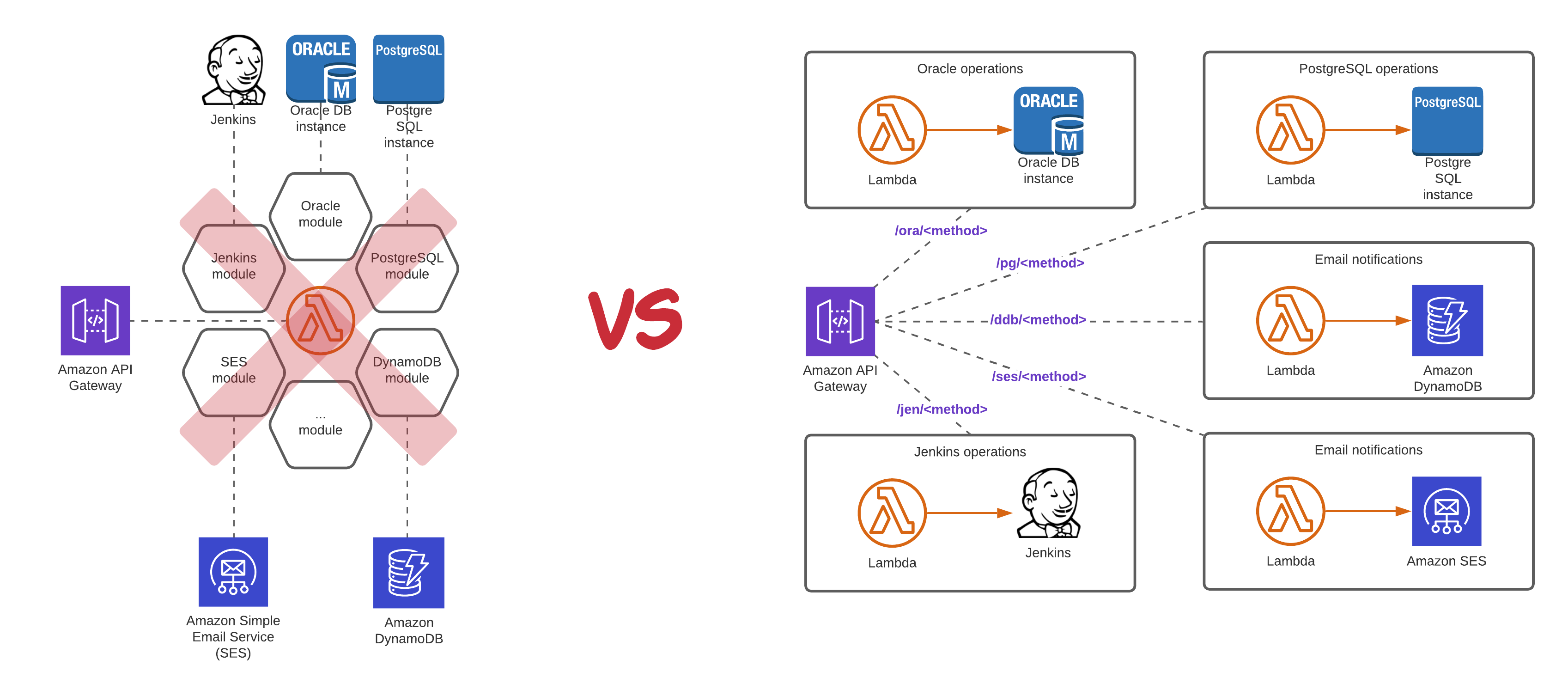
サーバーレスアーキテクチャを採用する際、避けて通れないのが「ベンダーロックイン」の問題です。AWS Lambda、API Gateway、DynamoDBといったサービスは、AWSに特化した実装となるため、将来的に他のクラウドプロバイダへ移行することは容易ではありません。
ただし、ベンダーロックインは必ずしも悪いことではありません。特定のクラウドプロバイダに最適化することで、そのプラットフォームが提供する高度な機能を最大限活用できます。重要なのは、この制約を理解した上で、意図的な選択を行うことです。
予期せぬコスト増大のリスク
サーバーレスの従量課金制は諸刃の剣です。正常に動作している限りはコスト効率的ですが、バグや設定ミスにより予期せぬコスト増大が発生する可能性があります。
実際に起きた「課金事故」の事例として、Lambda関数のバグによる無限ループが発生し、10日間で28億回以上も関数が実行され、約30万円の予期せぬ請求が発生したケースがあります。このような事態を防ぐために、以下の対策が必要です。
コスト管理のための具体的な対策を実施することで、予期せぬ支出を防ぐことができます。
- AWS Budgetsでコストアラートを設定
- Lambda関数の同時実行数に上限を設定
- CloudWatchアラームで異常な実行回数を検知
- 定期的なコストレビューの実施
デバッグとトラブルシューティングの複雑さ
分散型のサーバーレスアーキテクチャでは、複数のサービスが連携して動作するため、問題の原因特定が困難になることがあります。従来のモノリシックなアプリケーションでは、単一のログファイルを追跡すれば問題を特定できましたが、サーバーレスでは複数のサービスのログを横断的に分析する必要があります。
この課題に対処するために、「オブザーバビリティ」の確保が重要になります。AWS X-Rayによる分散トレーシングや、CloudWatch Logsによる統合ログ管理など、適切な監視・分析ツールの導入が不可欠です。
実践的な設計パターンと失敗を避けるための指針
アーキテクチャ設計の基本原則
サーバーレスアーキテクチャを成功させるための設計原則として、以下の点を常に意識する必要があります。
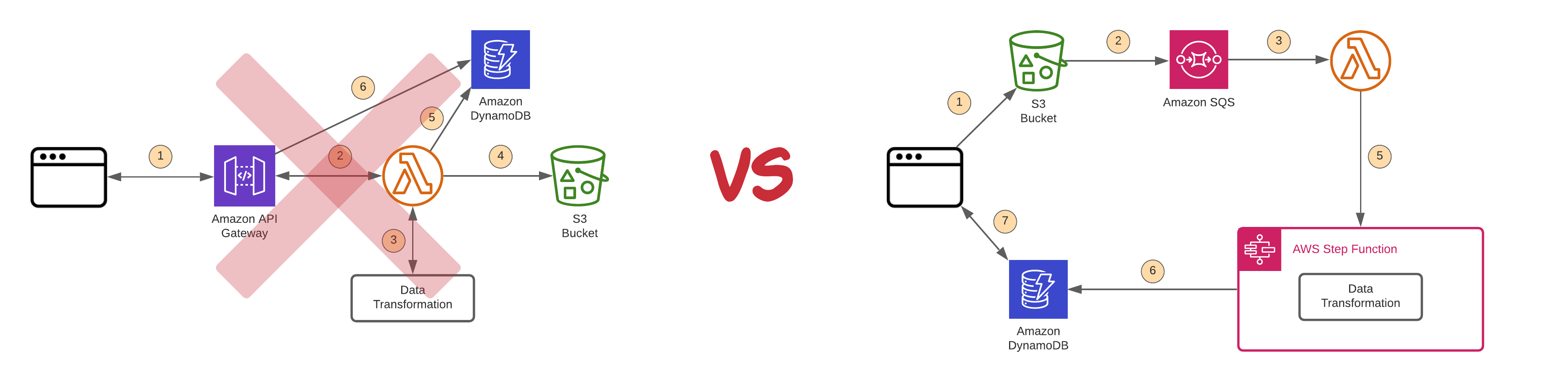
まず、「関数の単一責任原則」を徹底することです。一つのLambda関数に複数の責務を持たせると、メンテナンスが困難になり、スケーラビリティも損なわれます。例えば、「ユーザー登録」という機能を実装する場合、バリデーション、データベース登録、メール送信をそれぞれ別の関数として実装し、Step Functionsなどで連携させる設計が推奨されます。
次に、「非同期処理の活用」です。同期的な処理の連鎖は、全体のレスポンス時間を増大させ、タイムアウトのリスクを高めます。Amazon SQSやEventBridgeを活用して、処理を非同期化することで、システム全体の耐障害性とパフォーマンスを向上させることができます。
DynamoDBの設計における注意点
NoSQLデータベースの設計は、RDBMSとは根本的に異なるアプローチが必要です。特にDynamoDBでは、「アクセスパターン駆動設計」が重要になります。
実際のプロジェクトでよく見る失敗パターンは、RDBMSの設計思想をそのままDynamoDBに適用してしまうことです。例えば、正規化されたテーブル構造をそのまま移植すると、複数テーブルへのアクセスが必要になり、パフォーマンスが大幅に低下します。
DynamoDBでは、「単一テーブル設計」というアプローチが推奨されることがあります。これは、複数のエンティティを一つのテーブルに格納し、パーティションキーとソートキーの組み合わせでデータを管理する手法です。以下に、ECサイトの注文管理を例にした設計パターンを示します。
表:DynamoDBの単一テーブル設計例
パーティションキー | ソートキー | エンティティタイプ | 属性 |
|---|---|---|---|
12345 | PROFILE | ユーザープロフィール | name, email, address |
12345 | ORDER#2024-001 | 注文情報 | orderDate, totalAmount, status |
12345 | ORDER#2024-001#ITEM#001 | 注文明細 | productId, quantity, price |
この設計により、特定ユーザーの全注文を1回のクエリで取得できる一方、商品情報も同じテーブルで管理できます。
エラーハンドリングとリトライ戦略
サーバーレスアーキテクチャでは、分散システム特有の「一時的な障害」が発生することを前提とした設計が必要です。
Lambda関数のエラーハンドリングには、以下の3つのレベルでの対策が必要です。
関数内でのエラーハンドリング | 予期される例外を適切にキャッチし、ログ出力と共に適切なエラーレスポンスを返す |
|---|---|
DLQ(Dead Letter Queue)の設定 | 処理に失敗したメッセージを別のキューに移動し、後で分析・再処理できるようにする |
サーキットブレーカーパターンの実装 | 連続的な失敗が発生した場合、一時的に処理を停止し、システム全体への影響を防ぐ |
パフォーマンスチューニングの実践
サーバーレスアプリケーションのパフォーマンスを最適化するために、以下の手法を活用します。
まず、Lambda関数のメモリ割り当ての最適化です。メモリサイズはCPU性能と比例するため、処理内容に応じて適切なメモリサイズを選択する必要があります。AWS Lambda Power Tuningツールを使用することで、コストとパフォーマンスのバランスが取れた最適なメモリサイズを見つけることができます。
次に、コールドスタート対策として「Provisioned Concurrency」の活用があります。これは事前に指定した数の実行環境を温めておく機能で、レスポンス時間の一貫性が求められるAPIエンドポイントなどで有効です。ただし、常時課金が発生するため、コストとのバランスを考慮する必要があります。
まとめ
サーバーレスアーキテクチャとNoSQLデータベースは、適切に活用すれば、開発速度の向上、コスト削減、スケーラビリティの確保といった大きなメリットをもたらします。しかし、本記事で紹介したように、実行時間の制限、ベンダーロックインといったデメリットも存在します。
重要なのは、これらの特性を正しく理解し、自社のシステム要件と照らし合わせて適切な選択を行うことです。全てをサーバーレスで実装する必要はありません。長時間実行が必要なバッチ処理はECSやEC2で、リアルタイム性が求められるAPIはLambdaで、といったハイブリッドなアーキテクチャも有効な選択肢です。
技術選択に「銀の弾丸」は存在しません。サーバーレスもまた、多くの選択肢の一つに過ぎません。しかし、その特性を理解し、適切に活用すれば、ビジネスの成長を加速させる強力な武器となることは間違いありません。本記事が、皆様のサーバーレス導入の一助となれば幸いです。
























