


なぜ今、RAGシステムの品質評価が重要なのか
従来のRAG評価における3つの課題
企業でRAG(Retrieval Augmented Generation)システムを本番環境に投入する際、品質評価は避けて通れない関門でした。私自身、これまで複数のプロジェクトでRAGシステムの品質管理に携わってきましたが、以下の3つの課題に直面することが多かったです。
まず第一に、「評価基準の標準化」が極めて困難でした。検索精度と生成品質という2つの異なる要素を同時に評価する必要があり、従来のBLEUスコアやROUGEといった機械的な指標では、意味的な正確性を適切に測定できません。実際、AWSのブログでも指摘されているように、単語の重複を機械的に評価するだけでは、誤った回答でも高スコアになってしまうケースが頻発していました。
第二の課題は「評価コストの肥大化」です。専門知識を持つ人員が大量の出力を確認する必要があり、プロジェクトによっては評価フェーズだけで数週間を要することもありました。特にエンタープライズ向けのシステムでは、コンプライアンスや安全性の観点から入念なチェックが求められるため、このコストは無視できません。
第三に、「フィードバックループの遅延」が開発効率を著しく低下させていました。モデルやプロンプトを調整するたびに、その効果を確認するのに数日かかっていては、アジャイル開発のスピード感を保つことは不可能です。
BLUEスコアとは?
英作文テストで「模範解答」と「あなたの解答」がどれくらい単語レベルで一致しているかを採点する仕組みに近いです。
例えば、
- 模範解答が「“I like to eat sushi.”」
- あなたの解答が「“I enjoy eating sushi.”」
といった場合、意味は近いのに単語が一致しないため、BLEUスコアは低くなります。
ROUNGEとは?
テストの「要約問題」で、先生の模範解答と自分の要約がどれくらい同じ単語を使っているかを数えるようなものです。
例えば、
- 模範要約が「“The cat sat on the mat.”」
- 自分の要約が「“The cat is sitting on a mat.”」
といった場合、単語の多くが一致するのでROUGEスコアは高めになります。
サーバーレスアーキテクチャがもたらす解決策
こうした課題に対して、Amazon BedrockのRAG Evaluation機能は「サーバーレス」という切り口から革新的なアプローチを提供しています。評価用のインフラを自前で構築・運用する必要がなく、必要な時に必要なだけリソースを使用できるため、初期投資を抑えながら迅速な品質評価が可能になりました。
Amazon BedrockのRAG Evaluation機能の技術的詳細
アーキテクチャの全体像
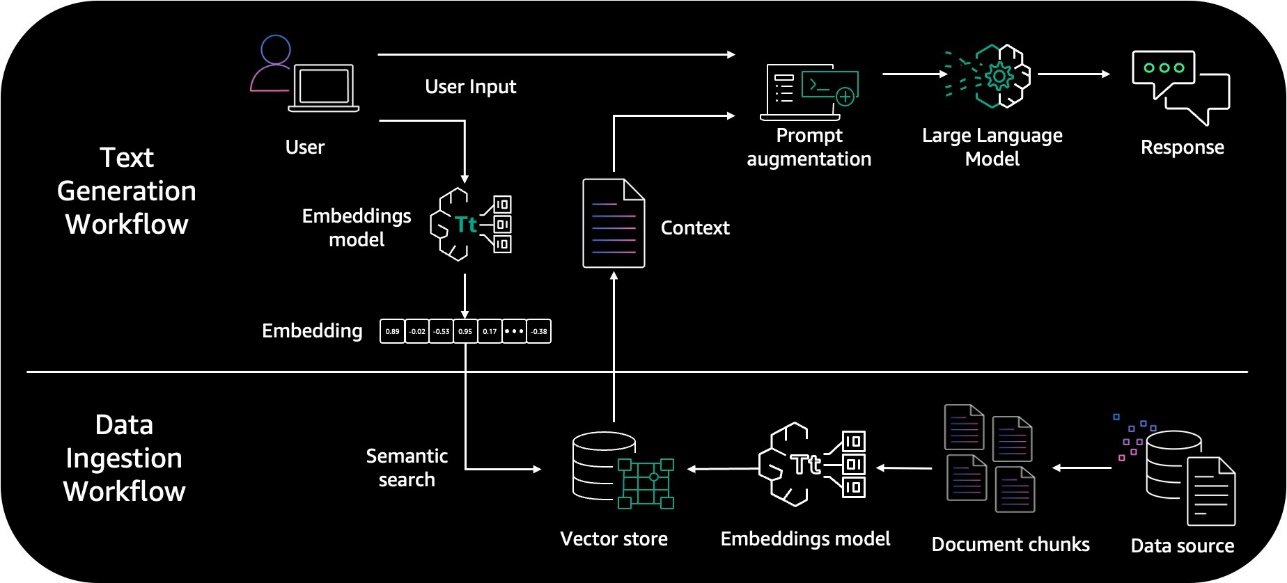
2024年末に初登場し、2025年3月に一般提供が開始されたRAG Evaluation機能は、Bedrock Knowledge Bases上で構築したRAGシステムの品質を自動評価する仕組みです。この機能の最大の特徴は、「LLM-as-a-Judge」というコンセプトを採用している点にあります。
システムの動作フローを整理すると、以下のような3段階のプロセスで評価が実行されます。
STEP 1 | Knowledge Baseからのベクトル検索が行われます。 |
|---|---|
STEP 2 | 取得した文書をコンテキストとして、選択したファウンデーションモデル(Anthropic ClaudeやAmazon Titan系列など)で回答を生成します。 |
STEP 3 | 評価用LLM(ジャッジモデル)が各評価指標に基づいてスコアを算出します。 |
評価指標の詳細と実践的な使い方
RAG Evaluation機能で利用可能な評価指標は、検索評価と回答生成評価の2つのカテゴリーに分類されます。
表 主要な評価指標とその活用シーン
指標カテゴリ | 指標名 | 評価内容 | 実務での活用例 |
|---|---|---|---|
検索評価 | Context Relevance | 検索結果の質問への関連性 | FAQボットの検索精度向上 |
検索評価 | Context Coverage | 期待される答えの網羅性 | 技術文書検索の完全性確認 |
回答生成評価 | Correctness | 事実的な正確性 | 金融・医療分野での誤情報防止 |
回答生成評価 | Faithfulness | 検索コンテキストへの忠実性 | 幻覚(ハルシネーション)の検出 |
回答生成評価 | Harmfulness | 有害コンテンツの有無 | コンプライアンス遵守の確認 |
回答生成評価 | Citation Precision | 引用の正確性 | 法務文書での根拠明示 |
これらの指標を組み合わせることで、多角的な品質評価が可能になります。例えば金融業界のプロジェクトでは、Correctness(正確性)とFaithfulness(忠実性)を重視し、誤った情報や幻覚を徹底的に排除する設定にすることが多いです。
評価データセットの準備と実装のポイント
評価を実施する際は、JSONL形式でデータセットを準備する必要があります。基本的な構造は以下のようになります。
{
"prompt": "質問文",
"referenceResponses": ["期待される回答"],
"retrievedResults": ["検索で取得された文書"],
"citations": ["引用情報"]
}データセット作成時の重要なポイントとして、Context Coverage指標を使用する場合は「referenceResponses」に正解となるテキストを含める必要があります。また、Citation評価を行う場合は、適切な引用フォーマットでデータを準備することが求められます。
エンタープライズでの実装事例:Nippon India Mutual Fundのケース
導入背景と課題
Nippon India Mutual Fundの事例は、RAG Evaluation機能の実践的な価値を示す好例です。以下の図は、実際に構築されたRAGアーキテクチャーとプロセスを示しています。
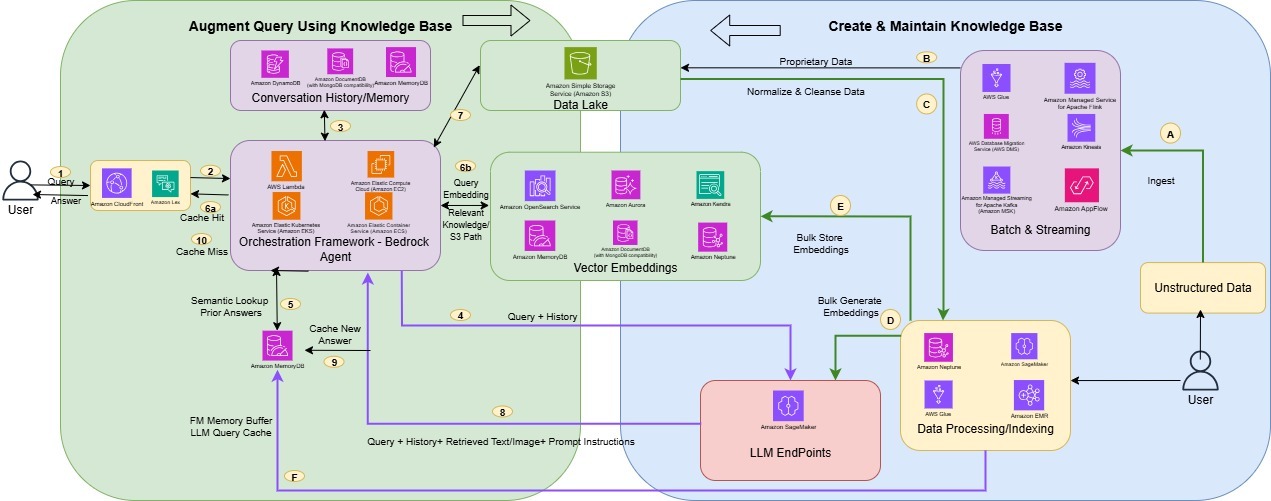
同社は膨大な金融ドキュメントを活用したAIアシスタントの構築において、回答精度の定量評価という課題に直面していました。
金融業界特有の要件として、規制遵守や正確性の担保が極めて重要であり、従来の手法では品質保証に多大なリソースを要していました。
RAG Evaluationによる改善プロセス
同社はRAG Evaluation機能を活用して、以下のような段階的な改善プロセスを実施しました。
まず、複数のKnowledge Base設定(埋め込みモデル、チャンク戦略、GraphRAGなど)を用意し、それぞれについて評価ジョブを実行しました。評価指標としてCorrectness、Completeness、Faithfulnessを重点的にモニタリングし、各設定のパフォーマンスを定量的に比較しました。
次に、低スコアとなったケースを詳細に分析し、Knowledge Baseのデータ補強やプロンプト最適化を実施しました。RAG Evaluationは各スコアに対して自然言語での説明も提供するため、問題の原因を素早く特定できました。
さらに、Responsible AI指標(HarmfulnessやStereotyping)も活用し、金融業界のコンプライアンス要件を満たしているかを継続的に確認しました。
事例記事より引用 : Metrics for RAG Evaluation
Because RAG solutions have multiple moving parts, you need to evaluate them against key success metrics to make sure that you get relevant and contextual data from the knowledge base. RAG evaluation should validate the generation of complete, correct, and grounded answers without hallucinations. You also need to evaluate the bias, safety, and trust of RAG solutions.
Amazon Bedrock Knowledge Bases provides built-in support for RAG evaluation, including quality metrics such as correctness, completeness, and faithfulness (hallucination detection); responsible AI metrics such as harmfulness, answer refusal, and stereotyping; and compatibility with Amazon Bedrock Guardrails. Nippon used RAG evaluation to compare against multiple evaluation jobs using custom datasets.
達成された成果と学び
この取り組みの結果、以下のような顕著な成果が得られました。
回答の正確性が95%以上に向上し、幻覚(誤った創作情報)の発生を90~95%削減できました。また、従来2日かかっていたレポート作成業務が約10分で完了するなど、業務効率が飛躍的に改善しました。
この事例から学べる重要なポイントは、「継続的な評価と改善のサイクル」の確立です。RAG Evaluationにより、モデルやKnowledge Base設定の変更が品質に与える影響を即座に把握でき、データドリブンな意思決定が可能になりました。
事例記事より引用 : Nippon saw the following improvements after implementing RAG:
- Accuracy was increased by more than 95%
- Hallucination was reduced by 90–95%
- They were able to add source chunks and file links (through file metadata), which improves the user confidence in the response
- The time needed to generate a report was reduced from 2 days to approximately 10 minutes
実装における技術的考察
サーバーレスアーキテクチャの利点と制約
RAG Evaluation機能の「サーバーレス」という特性は、特に以下の点で大きなメリットをもたらします。
インフラ管理が不要であるため、評価環境の構築・運用にかかる工数を大幅に削減できます。必要な時だけリソースを使用する従量課金制により、コスト最適化も容易です。また、評価ジョブのスケーラビリティも自動的に確保されるため、大規模なデータセットでも問題なく処理できます。
一方で、いくつかの制約も認識しておく必要があります。
評価モデル(ジャッジ)への依存度が高く、選択したモデルの性能や特性が評価結果に大きく影響します。小型のモデルを使用すると事実誤りを見逃す可能性があるため、重要な評価では高性能モデルの使用が推奨されます。
また、標準ベンチマークが確立されていないため、評価スコアの絶対的な解釈には注意が必要です。例えば「正確性0.8」というスコアが高いか低いかは、データセットや評価モデルに依存するため、主に自社内での相対比較や推移のモニタリングに活用するのが現実的です。
カスタマイズと拡張性
組み込み指標だけでは自社固有の要件をすべて満たせない場合もあります。そのような場合は、カスタム指標の定義とLLMプロンプトの作成を検討すべきです。
カスタム指標を作成する際は、評価プロンプトの設計が重要になります。例えば、業界特有の専門用語の正確な使用を評価したい場合、そのための評価基準を明確に定義したプロンプトを作成する必要があります。
コスト最適化の戦略
評価にかかるコストを最適化するための実践的なアプローチとして、以下の戦略が有効です。
開発初期段階では小規模なサンプルデータで頻繁に評価を実施し、本番環境への移行前に大規模な評価を行うという段階的アプローチを採用します。また、評価用モデルの選択においても、用途に応じて適切なモデルを使い分けることで、品質とコストのバランスを取ることができます。
今後の展望と実装へのロードマップ
技術トレンドと将来性
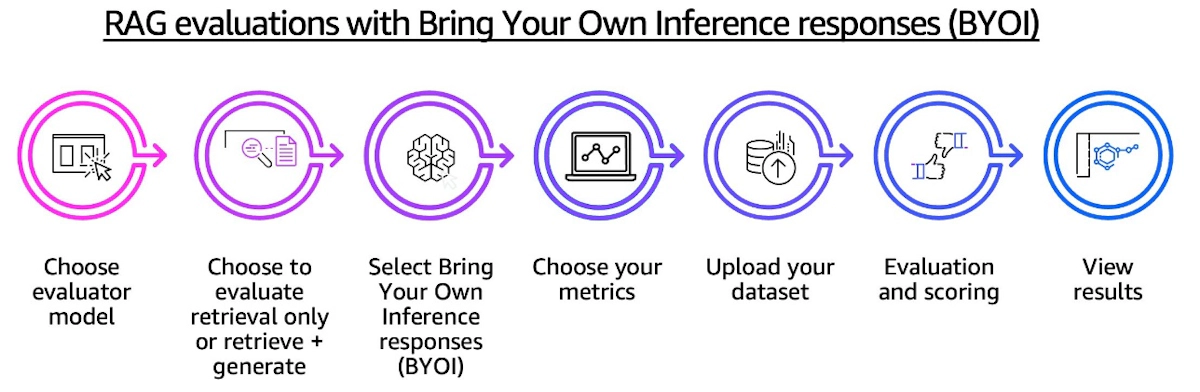
RAG評価技術は急速に進化しており、今後さらなる機能拡張が期待されています。2025年3月のGA(一般提供)開始以降、「Bring Your Own Inference (BYOI)」機能により、Bedrock以外で動作するRAGシステムの評価も可能になりました。
この拡張により、マルチクラウド環境やハイブリッドクラウド環境でのRAGシステム評価が現実的になり、より柔軟な品質管理戦略を立てられるようになっています。
実装に向けた段階的アプローチ
RAG Evaluation機能を自社のプロジェクトに導入する際は、以下のような段階的アプローチを推奨します。
最初のフェーズでは、既存のRAGシステムの現状把握から始めます。小規模な評価データセットを作成し、基本的な指標(Correctness、Faithfulness)で現在の品質レベルを測定します。
次に、業務要件に応じた評価指標の選定と重み付けを行います。例えば、カスタマーサポート向けのシステムであればHelpfulnessを重視し、法務文書を扱うシステムであればCitation Precisionを重視するといった具合です。
その後、継続的な評価プロセスを確立し、CI/CDパイプラインへの組み込みを検討します。モデルやKnowledge Baseの更新時に自動的に評価が実行される仕組みを構築することで、品質の劣化を早期に検出できます。
エンタープライズ導入における成功要因
私がこれまで関わってきたプロジェクトの経験から、RAG Evaluation機能の導入を成功させるためには以下の要因が重要だと考えています。
まず、経営層を含めた組織全体での品質指標に対する共通認識の確立が不可欠です。RAG Evaluationが提供する定量的な指標を活用して、品質目標を明確に設定し、KPIとして管理することで、継続的な改善活動を推進できます。
また、評価結果を単なる数値として捉えるのではなく、ビジネス価値との関連性を明確にすることも重要です。例えば、「Correctnessが10%向上すれば、顧客からの問い合わせが20%削減される」といった形で、技術指標とビジネス成果を紐付けて説明することで、投資対効果を明確に示せます。
さらに、評価プロセスの自動化と人間によるレビューのバランスを適切に保つことも成功の鍵となります。RAG Evaluationによる自動評価で効率化を図りつつ、重要な判断には人間の専門知識を活用するハイブリッドアプローチが、現時点では最も現実的な選択肢だと考えています。
まとめ
Amazon BedrockのRAG Evaluation機能は、生成AIシステムの品質管理に革新的な変化をもたらしています。「サーバーレス」というアーキテクチャの利点を活かし、従来は人手に頼っていた評価プロセスを自動化・効率化することで、開発サイクルの高速化とコスト削減を同時に実現できます。
Nippon India Mutual Fundの事例が示すように、適切に活用すれば回答精度の大幅な向上と業務効率の劇的な改善が可能です。しかし同時に、評価モデルへの依存や標準ベンチマークの不在といった制約も存在するため、これらを理解した上で戦略的に導入することが重要です。
今後、RAG評価技術はさらに進化し、より高度な品質管理が可能になることが期待されています。エンタープライズにおける生成AI活用が本格化する中で、RAG Evaluation機能のような品質保証の仕組みは、もはや「あれば良い」ではなく「なくてはならない」存在になりつつあります。
私たちエンジニアには、こうした新しい技術を適切に評価し、ビジネス価値に変換していく責任があります。RAG Evaluation機能は、その責任を果たすための強力なツールとなることでしょう。まずは小規模な評価から始めて、段階的に活用範囲を広げていくことをお勧めします。
品質管理の自動化は、単なる効率化ではなく、AIシステムの信頼性向上という本質的な価値をもたらします。この機会に、自社のRAGシステムの品質管理戦略を見直してみてはいかがでしょうか。
























