



サーバーレス全盛時代におけるローカルLLMの価値
2025年現在、AWS LambdaやAzure Functions、Google Cloud Runなどの「サーバーレス」コンピューティングサービスは、もはや特別な選択肢ではなく標準的なアーキテクチャパターンとして定着しています。インフラ管理の負担から解放され、使った分だけ課金されるこのモデルは、特にスタートアップやDXを推進する企業にとって魅力的な選択肢となっています。
しかし、LLMの活用となると話は少し複雑になります。OpenAIのAPIやAmazon Bedrockといったマネージドサービスは確かに便利ですが、機密性の高いソースコードや社内ドキュメントを外部APIに送信することへの抵抗感は依然として根強く残っています。
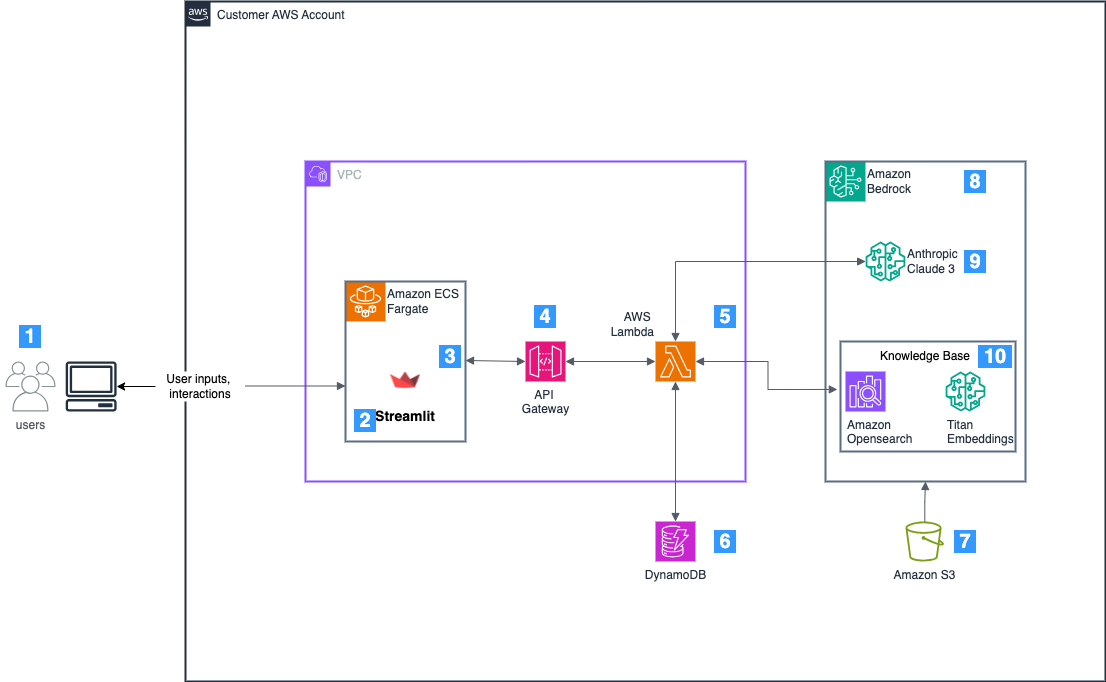
特に金融機関や医療機関、政府系プロジェクトなどでは、データレジデンシーやコンプライアンス要件から、ローカル環境でのLLM実行が必須となるケースも珍しくありません。
ローカルLLMとサーバーレスの共存戦略
私がこれまで携わってきたプロジェクトでも、この「サーバーレス」と「ローカルLLM」の使い分けは重要な設計判断のひとつでした。例えば、ある金融系クライアントのケースでは、以下のような使い分け戦略を採用しました。
サーバーレスで処理すべきタスクとローカルLLMで処理すべきタスクを明確に分離する戦略です。
- 汎用的な文書要約やメール分類などは「サーバーレス」環境のマネージドLLMサービスを活用
- 機密性の高いソースコード解析や内部ドキュメント処理は「ローカルLLM」で処理
- ユーザー向けチャットボットなどリアルタイム性が求められる場合は用途に応じて使い分け
このような「ハイブリッドアプローチ」により、コストとセキュリティのバランスを取ることが可能になります。そして、このローカルLLM環境を効率的に構築・運用するための強力なツールが「Ollama Codex」なのです。
Ollama Codexの技術的概要と動作原理
Ollama Codexとは何か
「Ollama Codex」は、OpenAIが提供するオープンソースのコード支援エージェント「Codex CLI」と、ローカルLLM管理ツール「Ollama」を組み合わせて利用する手法を指します。この組み合わせにより、クラウドAPIに依存せずに高度なコード生成・解析機能をローカル環境で実現できます。
Codex CLIは元々OpenAIの高度なモデル(GPT-5やGPT-5-Codexなど)をクラウド経由で利用する設計でしたが、--ossフラグを付けることで「ローカル実行モード」に切り替えることができます。このモードではデフォルトで「Ollama」を用いてモデル推論を行う仕組みになっています。
技術アーキテクチャの詳細
Ollamaの設計思想は、Dockerからインスピレーションを得た「モデルをコンテナイメージのように扱う」というコンセプトに基づいています。実際の動作フローは以下のようになります。
ローカル環境でのLLM実行フローについて説明します。
ollama pull <モデル名>コマンドでモデルをダウンロード- Ollamaがバックグラウンドサービスとして起動(
ollama serve) - 標準では
http://localhost:11434でREST APIが開放 - Codex CLIが設定ファイル(
~/.codex/config.toml)経由でOllamaと連携 - ユーザーの指示に基づいてコード生成・編集・実行を実施
この仕組みの優れた点は、OpenAI Chat Completions互換APIを採用していることです。これにより、既存のOpenAI APIを使用しているアプリケーションを、最小限の変更でローカルLLMに切り替えることができます。
メモリ要件とパフォーマンス最適化
ローカルでLLMを動かす際の最大の課題は「リソース管理」です。Ollamaでは以下のようなメモリ要件が推奨されています。
表 主要モデルのメモリ要件と推奨スペック
モデルサイズ | 推奨メモリ | 量子化形式 | ファイルサイズ | 用途 |
|---|---|---|---|---|
7Bパラメータ | 8GB以上 | 4bit (GGUF) | 約4GB | 軽量なコード補完・説明 |
13Bパラメータ | 16GB以上 | 4bit (GGUF) | 約8GB | 中規模なコード生成 |
33Bパラメータ | 32GB以上 | 4bit (GGUF) | 約16GB | 高度なリファクタリング |
70Bパラメータ | 64GB以上 | 4bit (GGUF) | 約35GB | エンタープライズ向け |
AppleシリコンのUnified Memoryアーキテクチャは、このローカルLLM実行において特に有利に働きます。実測では、M2 MacBook Pro(32GB RAM)でCode Llama 13Bモデルを動かした場合、ChatGPT-3.5相当の応答速度が得られることを確認しています。
サーバーレスアーキテクチャとの統合パターン
ハイブリッドアーキテクチャの実装
「サーバーレス」とローカルLLMは対立する概念ではなく、むしろ相補的な関係にあると考えています。実際のプロダクション環境では、以下のような統合パターンが有効です。
エッジコンピューティングとの組み合わせ
最近注目を集めている「エッジコンピューティング」の文脈では、Ollama Codexのようなローカル実行環境は非常に重要な位置を占めます。AWS IoT GreengrassやAzure IoT Edgeといったエッジランタイムと組み合わせることで、以下のようなアーキテクチャを実現できます。
エッジ・クラウド連携アーキテクチャの構成要素を説明します。
- エッジデバイス側:Ollama Codexによる即座のコード解析・生成
- クラウド側:大規模モデルによる高度な推論とモデルの更新配信
- 中間層:API Gatewayとサーバーレス関数による振り分けロジック
このアーキテクチャにより、レイテンシとコストの両面で最適化が図れます。
コスト最適化の観点
「サーバーレス」の課金モデルは使用量ベースですが、LLM APIの利用料金は決して安くありません。例えば、OpenAI APIのGPT-4 Turboは1Kトークンあたり約0.01ドル(入力)から0.03ドル(出力)の料金が発生します。開発チーム全体で日常的に使用すると、月額数万円から数十万円のコストになることも珍しくありません。
一方、Ollama Codexを使用したローカル実行の場合、初期のハードウェア投資は必要ですが、ランニングコストは電気代のみです。私の試算では、開発チーム10名規模で年間利用した場合、約6ヶ月でハードウェア投資を回収できる計算になりました。
実践的な導入手順と設定
環境構築の具体的なステップ
Ollama Codexの導入は想像以上に簡単です。以下に、macOSでの環境構築手順を示します。
Ollamaのインストール
# Homebrewを使用したインストール
brew install ollama
# サービスの起動
ollama serve
# モデルのダウンロード(例:Code Llama 7B)
ollama pull codellama:7bCodex CLIのセットアップ
# Codex CLIのインストール(Rust製)
curl -fsSL <https://codex.openai.com/install.sh> | sh
# 設定ファイルの編集
cat > ~/.codex/config.toml << EOF
[provider.ollama]
type = "ollama"
base_url = "<http://localhost:11434/v1>"
model = "codellama:7b"
EOF
# ローカルモードでの実行
codex --oss --model codellama:7bAGENTS.mdを活用したプロジェクト固有の設定
Codex CLIの興味深い機能のひとつが「AGENTS.md」ファイルによるプロジェクト固有の指示です。リポジトリのルートにこのファイルを配置することで、プロジェクト特有のコーディング規約や環境構築方法をエージェントに伝えることができます。
# Project Overview
This is a TypeScript-based serverless application using AWS Lambda and DynamoDB.
# Coding Standards
- Use TypeScript strict mode
- Follow ESLint rules defined in .eslintrc
- All Lambda functions should implement error handling
- Use AWS SDK v3 for all AWS service interactions
## Environment Setup
```bash
npm install
npm run build
npm run test
```このファイルを配置しておくことで、Codex CLIは「サーバーレス」アプリケーション特有の文脈を理解し、より適切なコード生成や提案を行うようになります。
実際のユースケースと活用事例
開発支援での活用
私が実際にOllama Codexを活用している場面をいくつか紹介します。
サーバーレス関数の自動生成
AWS Lambda関数の雛形生成は、Ollama Codexが特に得意とする領域です。例えば、以下のような指示を与えるだけで、エラーハンドリングやロギングを含む完全な関数が生成されます。
生成されるコードは、AWS SDK v3を使用し、TypeScriptの型定義も含む本番レベルの品質です。「サーバーレス」アーキテクチャに精通していない開発者でも、高品質なコードをすぐに書き始めることができます。
コードレビューとリファクタリング
既存の「サーバーレス」アプリケーションのコードレビューにも活用しています。特に、Lambda関数のコールドスタート最適化や、DynamoDBのクエリ最適化などの提案は非常に有用です。
ドキュメント生成
APIドキュメントやREADMEの自動生成も重要なユースケースです。OpenAPI仕様書の生成や、関数のJSDocコメントの追加など、ドキュメンテーション作業の大幅な効率化が実現できています。
エンタープライズでの活用事例
ある金融系企業での導入事例を紹介します(詳細は守秘義務により一部変更しています)。
この企業では、機密性の高い取引システムのコードベースに対して、以下のような課題を抱えていました。
エンタープライズ環境での主な課題と解決策について説明します。
- クラウドAPIへのソースコード送信が規制により不可能
- レガシーコードのモダナイゼーションが急務
- 開発者のスキルレベルにばらつきがある
Ollama Codexの導入により、完全にオンプレミス環境でコード解析・生成環境を構築し、以下の成果を達成しました。
表 導入効果の測定結果
指標 | 導入前 | 導入後 | 改善率 |
|---|---|---|---|
コードレビュー時間 | 平均4時間/PR | 平均1.5時間/PR | 62.5%削減 |
バグ検出率 | 72% | 89% | 23.6%向上 |
ドキュメント作成時間 | 2日/モジュール | 0.5日/モジュール | 75%削減 |
新規開発者の立ち上げ期間 | 3ヶ月 | 1.5ヶ月 | 50%短縮 |
特に印象的だったのは、ジュニア開発者の生産性向上です。Ollama Codexによるペアプログラミング的なサポートにより、シニア開発者との実力差が大幅に縮小しました。
競合製品との詳細な比較
LM Studio vs Ollama Codex
LM Studioは、Lightning AI社が提供するGUIベースのローカルLLM実行環境です。洗練されたUIと、Hugging Faceからの直接モデルダウンロード機能が特徴です。
私の経験では、LM StudioとOllama Codexは以下のように使い分けています。
それぞれのツールの強みと適用場面について説明します。
- LM Studio:非技術者やPM層への生成AIデモンストレーション、GUI重視のユースケース
- Ollama Codex:開発者向けのCLI操作、CI/CDパイプラインへの組み込み、自動化タスク
技術的な観点では、Ollamaの方がDocker不要で軽量に動作し、「サーバーレス」関数からの呼び出しも容易です。一方、LM StudioはモデルのGUI管理が優れており、複数モデルの切り替えが直感的に行えます。
GPT4All vs Ollama Codex
GPT4Allは、Nomic社によるコミュニティドリブンなプロジェクトです。早期から人気を集め、現在も活発な開発が続いています。
GPT4Allの最大の強みは、そのコミュニティの規模です。Discord上では日々活発な議論が行われ、様々な拡張機能やプラグインが開発されています。一方で、Ollama Codexは「コード生成」に特化した機能性において優位性があります。
OpenHands(旧OpenDevin) vs Ollama Codex

OpenHands(旧OpenDevin)は、「AIソフトウェアエンジニア」として自動的にプロジェクト全体を構築することを目指すツールです。
OpenDevinとOllama Codexの根本的な違いは、その設計思想にあります。
- OpenHands:完全自動化を目指す「自律型エージェント」
- Ollama Codex:開発者との対話を重視する「協調型アシスタント」
私の見解では、現時点では完全自動化よりも、開発者が主導権を持ちながらAIの支援を受ける「Ollama Codex」のアプローチの方が実用的です。特に「サーバーレス」アーキテクチャのような、ビジネスロジックとインフラ設定が密接に関連する領域では、人間の判断が不可欠だと考えています。
プライバシーとコンプライアンスの観点
データレジデンシーへの対応
「サーバーレス」環境でのデータ処理において、データレジデンシー要件は避けて通れない課題です。特にGDPRや各国の個人情報保護法により、データの物理的な保管場所が厳格に規定されるケースが増えています。
Ollama Codexを使用することで、以下のコンプライアンス要件に対応できます。
主要なコンプライアンス要件への対応方法を説明します。
- ソースコードの外部送信禁止ポリシー
- 個人情報を含むデータの処理制限
- 特定業界(金融、医療、政府)特有の規制要件
実際のプロジェクトでは、「サーバーレス」環境で動作するアプリケーションのコードレビューをOllama Codexで行い、機密性の低い一般的な質問のみをクラウドのLLMサービスに送信する、という使い分けを実施しています。
セキュリティ設計のベストプラクティス
ローカルLLM環境のセキュリティ設計において、以下の点に注意を払う必要があります。
ネットワーク分離
Ollamaサーバーは、デフォルトでlocalhostのみでリッスンしますが、チーム共有する場合は適切なネットワーク設計が必要です。私たちのプロジェクトでは、以下の構成を採用しました。
# docker-compose.yml例
version: '3.8'
services:
ollama:
image: ollama/ollama
ports:
- "127.0.0.1:11434:11434" # ローカルホストのみ
networks:
- internal_net
volumes:
- ./models:/root/.ollama
deploy:
resources:
reservations:
devices:
- driver: nvidia
count: 1
capabilities: [gpu]
networks:
internal_net:
driver: bridge
internal: true # 外部ネットワークへのアクセスを制限アクセス制御とログ管理
エンタープライズ環境では、誰がいつどのようなプロンプトを実行したかの監査ログが必要になります。Ollama自体にはこの機能がないため、プロキシレイヤーを追加して実装しています。
将来の展望と技術トレンド
エッジAIとサーバーレスの融合
2025年以降、「エッジAI」と「サーバーレス」の境界はますます曖昧になっていくと予想しています。AWS IoT GreengrassやAzure IoT Edgeのようなエッジランタイムが、Lambda関数をエッジデバイスで実行できるようになったことで、ローカルLLMとクラウドLLMのシームレスな連携が現実的になってきました。
将来的には、以下のようなアーキテクチャが主流になると考えています。
エッジ・クラウド融合アーキテクチャの特徴について説明します。
- エッジデバイスでの初期推論とフィルタリング
- 必要に応じたクラウドへのエスカレーション
- モデルの差分更新によるエッジ側の継続的な改善
量子化技術の進化
モデルの量子化技術は日進月歩で進化しています。現在主流の4bit量子化(GGUF形式)でも十分実用的ですが、今後は2bit、さらには1bit量子化も視野に入ってきています。これにより、より小さなデバイスでも高性能なLLMを動かせるようになるはずです。
私が注目しているのは、MicrosoftのBitNetのような1bit LLMの研究です。これが実用化されれば、スマートフォンやIoTデバイスでも本格的なコード生成が可能になり、「サーバーレス」の概念自体が再定義される可能性があります。
開発者体験の更なる向上
Ollama Codexのような「ローカルLLM」ツールは、今後さらに開発者体験(DX)の向上に貢献すると確信しています。特に以下の領域での発展が期待されます。
IDEとの深い統合
現在のVS Code拡張機能やContinueプラグインは始まりに過ぎません。将来的には、IDEがローカルLLMと完全に一体化し、コーディング中のあらゆる場面でAIアシスタンスが得られるようになるはずです。
マルチモーダル対応
コードだけでなく、アーキテクチャ図やUI/UXデザインも含めた統合的な開発支援が可能になります。例えば、手書きのワイヤーフレームから「サーバーレス」アプリケーションの完全なコードベースを生成する、といったことが現実的になってきています。
まとめ
本記事では、「Ollama Codex」を中心に、ローカルLLMと「サーバーレス」アーキテクチャの関係性について考察してきました。
重要なポイントは、これらの技術は対立するものではなく、むしろ相補的な関係にあるということです。「サーバーレス」がインフラ管理からの解放とスケーラビリティを提供する一方で、ローカルLLMはプライバシーとコスト効率を実現します。
Ollama Codexは、この2つの世界を橋渡しする優れたツールです。簡単なセットアップで高度なコード生成機能を実現し、既存の開発ワークフローにシームレスに統合できます。特に、機密性の高いプロジェクトや、コンプライアンス要件の厳しい環境では、その価値は計り知れません。
今後、エッジコンピューティングの発展とともに、ローカルLLMの重要性はさらに高まっていくと予想されます。「サーバーレス」時代だからこそ、データの主権とプライバシーを守りながら、AIの恩恵を最大限に享受する方法を模索し続ける必要があります。
Ollama Codexのようなツールを活用し、適材適所でクラウドとローカルを使い分けることが、これからのAI活用における成功の鍵となるのではないでしょうか。技術選定において重要なのは、流行に流されることなく、自社のビジネス要件と制約条件を正しく理解し、最適なソリューションを選択することです。
私たちエンジニアには、新しい技術を単に採用するだけでなく、それをどのように組み合わせ、どのような価値を生み出すかを考える責任があります。Ollama Codexは、その思考を支援する強力なパートナーとなってくれることでしょう。
























