


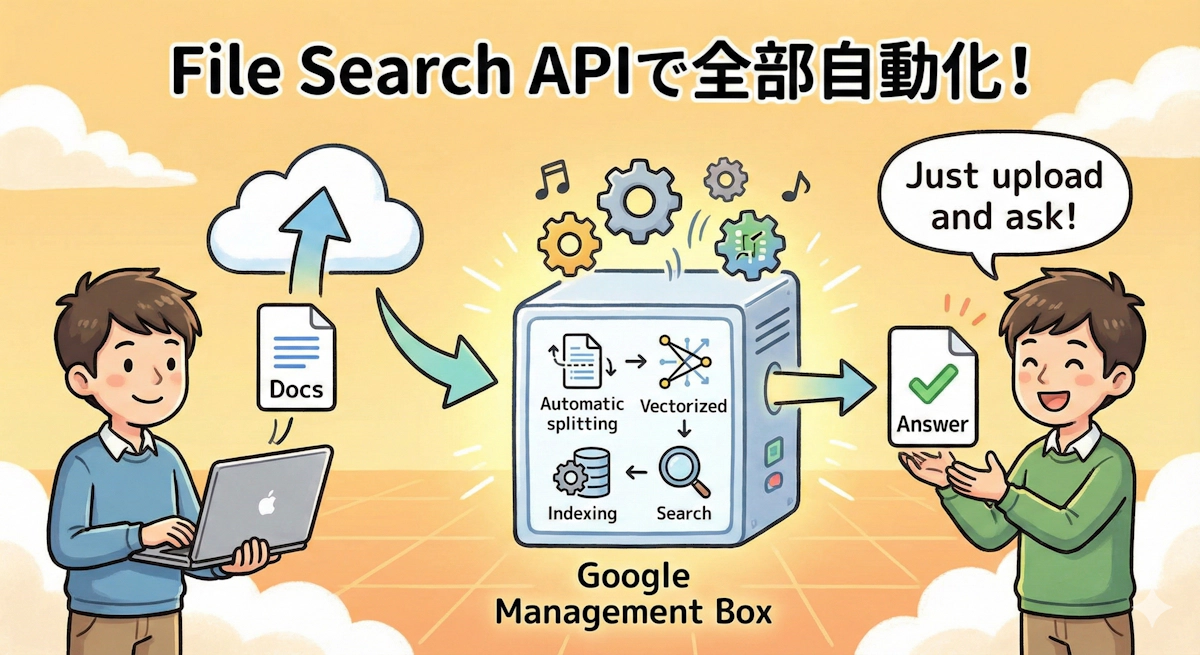
従来のRAG構築がなぜ大変だったか
これまでRAGシステムを作ろうと思ったら、以下のステップを全部自分で実装する必要がありました。
- ドキュメントを適切な単位に分割(チャンク化)
- 各チャンクをベクトル化(エンベディング生成)
- ベクトルデータベースへの保存と管理
- クエリ時のセマンティック検索
- 検索結果をLLMに渡して回答生成
LangChainやLlamaIndexを使えばだいぶ楽にはなりますが、それでもPineconeやWeaviateなどのベクトルDBを別途契約して、スケーリングやメンテナンスを考える必要がありました。
File Search APIで全部自動化
Gemini APIの「File Search」は、上記すべてのステップをGoogleが管理してくれるフルマネージドサービスです。開発者がやることは、ファイルをアップロードして質問するだけ。
from google import genai
from google.genai import types
client = genai.Client()
# File Search Storeを作成
file_search_store = client.file_search_stores.create(
config={'display_name': 'my-knowledge-base'}
)
# ファイルをアップロード
operation = client.file_search_stores.upload_to_file_search_store(
file='technical_manual.pdf',
file_search_store_name=file_search_store.name,
config={'display_name': 'Technical Manual'}
)
# アップロード完了を待機
import time
while not operation.done:
time.sleep(5)
operation = client.operations.get(operation)
# 質問する
response = client.models.generate_content(
model="gemini-2.5-flash",
contents="セットアップ手順を教えて",
config=types.GenerateContentConfig(
tools=[
types.Tool(
file_search=types.FileSearch(
file_search_store_names=[file_search_store.name]
)
)
]
)
)
print(response.text)このコードだけで、PDF文書に基づいた回答が返ってきます。チャンク化?エンベディング?ベクトルDB?全部勝手にやってくれる。
対応ファイル形式が豊富
サポートされるファイル形式がかなり広いのも嬉しいポイントです。
ドキュメント系では、PDF、Word(.docx)、Excel、テキスト、Markdown、HTML、JSON、LaTeXなど。プログラミング言語では、Python、JavaScript/TypeScript、Java、C/C++、SQL、Shell Scriptまで対応しています。
つまり、コードベースとビジネスドキュメントを両方放り込んで、統合的な知識ベースを作れるわけです。
料金体系が革新的
ここが一番驚いたところ。
- ファイルストレージ:無料
- クエリ時のエンベディング生成:無料
- セマンティック検索の実行:無料
- 初期インデックス化:$0.15/100万トークン
要は、最初にファイルを登録するときだけ課金されて、その後はストレージもクエリも無料。従来のPinecone等を使ったRAGでは、ホスティング費用が月額数十ドル〜数千ドルかかっていたことを考えると、かなり破格です。
実際に計算してみると、200ファイル・500万トークンで初期費用が約0.75ドル(110円程度)。その後の維持費は無料です。
自動引用機能がすごい
個人的に一番感動したのがこれ。回答には、その根拠となったドキュメントの該当箇所が自動的に含まれます。
# 引用情報の取得
grounding_info = response.candidates[0].grounding_metadata
print(f"使用されたソース: {grounding_info}")これにより「この回答、本当に正しいの?」という疑問に対して、「ここに書いてあります」と即座に答えられます。ハルシネーション(AIの嘘)対策としてめちゃくちゃ有効。
NotebookLMを使ったことがある人なら、あの「引用付きの回答」がそのまま自分のアプリに組み込めると思ってもらえれば。
メタデータフィルタリングで絞り込み
ファイルにカスタムメタデータを付けて、検索時に絞り込むことも可能です。
# メタデータ付きでインポート
operation = client.file_search_stores.import_file(
file_search_store_name=file_search_store.name,
file_name=sample_file.name,
custom_metadata=[
{"key": "department", "string_value": "engineering"},
{"key": "version", "numeric_value": 2.0}
]
)
# 検索時にフィルタリング
response = client.models.generate_content(
model="gemini-2.5-flash",
contents="認証の仕組みについて教えて",
config=types.GenerateContentConfig(
tools=[
types.Tool(
file_search=types.FileSearch(
file_search_store_names=[file_search_store.name],
metadata_filter='department="engineering" AND version >= 2.0'
)
)
]
)
)部署別、バージョン別など、検索対象を限定できるのはエンタープライズ用途で必須の機能です。
実際のパフォーマンス
Googleの内部事例として、Phaser Studio社の「Beam」というゲーム開発プラットフォームでは、File Search導入後に並列クエリ処理時間が数時間から2秒未満に短縮されたそうです。99%以上の削減。
もちろん環境によって差は出ますが、セルフマネージドRAGと比較して遜色ない(むしろ速い)パフォーマンスが期待できます。
制限事項を押さえておく
とはいえ、いくつか制限があります。
まずパブリックプレビュー段階なので、SLA(サービス品質保証)がありません。本番環境にいきなり投入するのはリスキー。
技術的な制約としては、エンベディングモデルがgemini-embedding-001に固定されていて、他のモデルを使えません。また、ベクトルDBの詳細はブラックボックスで、検索スコアの確認や埋め込みベクトルの検査ができません。
ストレージ容量は無料枠で1GB、Tier 3で1TBまで。1プロジェクトあたり最大10個のFile Search Storeを作成可能です。
セルフマネージドRAGとの使い分け
File Search APIが向いているケース:
- プロトタイピングやPoC
- インフラ管理のリソースが限られている
- 一般的なRAG要件で十分
- コスト最適化重視
セルフマネージドRAG(LangChain + Pinecone等)が向いているケース:
- 極めて高精度な検索が必須
- カスタムエンベディングモデルが必要
- 特殊なReranking戦略が必要
- ベクトルDBへの直接アクセスが必要
個人的には、まずFile Searchでプロトタイプを作って、本当に細かいカスタマイズが必要だとわかったらセルフマネージドに移行する、という流れが現実的だと思います。
導入のおすすめステップ
- まずGoogle AI Studioで非機密情報のドキュメントを使って試す
- 精度と速度を評価
- 社内ツール向けのPoCを構築
- GA化を待って本番導入を検討
特に機密性の高い企業文書をアップロードする場合は、法務・コンプライアンス部門との事前協議が必須です。
まとめ
- Gemini File Search APIは、RAG構築に必要な全工程をフルマネージドで提供
- ストレージとクエリが無料という革新的な料金体系
- 自動引用機能でハルシネーション対策も万全
- 現時点ではパブリックプレビューでSLAなし、本番投入は慎重に
























