


バージョン1.7系:エンタープライズ導入の基盤整備
OAuth 2.0対応がもたらす本質的価値
2024年7月23日にリリースされたDify 1.7.0では、ツールプラグインのOAuth 2.0対応が実装されました。この機能は一見すると単純な認証機能の追加に見えますが、企業のAI活用において極めて重要な意味を持ちます。
従来、外部サービスとの連携においては、APIキーやパスワードを直接設定ファイルに記載する方式が一般的でした。しかし、この方式には「権限の細分化ができない」「認証情報の定期更新が困難」「監査ログが取得できない」といった課題がありました。OAuth 2.0対応により、これらの課題が解決され、企業のセキュリティポリシーに準拠した形での外部連携が可能になりました。
特にリフレッシュトークンへの対応は、長期運用を前提とした企業システムにおいて重要です。アクセストークンの有効期限が切れても、自動的に新しいトークンを取得できるため、運用担当者の負担が大幅に軽減されます。
プラグイン自動アップグレード戦略の実装意図
同じく1.7.0で実装された「プラグイン自動アップグレード戦略」は、企業のIT運用における重要な課題に対応しています。この機能では、アップグレードポリシーの設定とロールバック機能が提供されており、以下のような運用シナリオに対応できます。
プラグイン管理における主要な運用パターンは次の通りです。
- セキュリティパッチのみ自動適用し、機能追加は手動で検証後に適用
- 開発環境では最新版を自動適用し、本番環境では検証済みバージョンを固定
- 特定のプラグインのみ自動更新を有効化し、重要なプラグインは手動管理
この機能により、セキュリティと安定性のバランスを取りながら、運用負荷を削減することが可能になりました。実際に私が関わったプロジェクトでも、プラグインの更新管理は大きな課題となっており、この機能の実装は現場のニーズを的確に捉えていると評価できます。
ワークフロー可視化とUX改善の戦略的意味
2024年8月11日にリリースされた1.7.2では、「Relationsパネル」によるワークフローの関係可視化機能が追加されました。この機能は、複雑化するAIワークフローの管理において重要な役割を果たします。
企業のAI活用が進むにつれて、ワークフローは単純な一問一答から、複数のステップを経る複雑な処理へと進化しています。例えば、顧客からの問い合わせに対して、まず意図を分類し、関連する社内文書を検索し、必要に応じて外部APIを呼び出し、最終的に回答を生成するといった多段階の処理が必要になります。
このような複雑なワークフローにおいて、各ノード間の依存関係を視覚的に把握できることは、以下の点で重要です。
- 変更影響の事前評価が可能になり、本番環境での障害リスクを低減
- 新規メンバーの理解速度が向上し、チーム全体の生産性が向上
- パフォーマンスボトルネックの特定が容易になり、最適化の優先順位付けが可能
バージョン1.8系:パフォーマンスとスケーラビリティの革新
非同期実行エンジンがもたらすパラダイムシフト
2024年8月27日にリリースされた1.8.0の最大の特徴は、非同期実行エンジンの実装です。公式発表によると、WorkflowRunとNodeRunの非同期リポジトリ導入により、実行時間が「ほぼ半減」したとされています。
この改善は単なるパフォーマンス向上以上の意味を持ちます。非同期処理の導入により、以下のような新たな可能性が開かれました。
非同期実行エンジンがもたらす具体的なメリットを整理すると次のようになります。
- 複数のAPIコールを並列実行できるため、外部サービス連携を含むワークフローの実行時間が大幅に短縮
- リソースの効率的な利用により、同一ハードウェアでより多くのリクエストを処理可能
- タイムアウト処理やリトライ処理が洗練され、一時的な障害に対する耐性が向上
特に重要なのは、この非同期化が「Queue-based」アーキテクチャと組み合わされている点です。キューベースの設計により、処理の優先度制御やバックプレッシャーの管理が可能になり、企業の本番環境で求められる安定性と予測可能性が実現されています。
マルチモデル管理とMCP統合の先進性
1.8.0で導入された「マルチモデル・クレデンシャルシステム」と「MCP(Model Context Protocol)+ OAuth」の組み合わせは、エンタープライズAI戦略において重要な転換点を示しています。
企業がAIを活用する際、単一のモデルですべての用途をカバーすることは現実的ではありません。例えば、以下のようなモデル使い分けが一般的になっています。
表:企業におけるAIモデル使い分けパターン
用途 | 推奨モデル | 選定理由 | コスト感 |
|---|---|---|---|
高度な推論・分析 | GPT-4 Turbo / Claude 3 Opus | 精度と推論能力を重視 | 高 |
日常的な文書作成 | GPT-3.5 / Claude 3 Haiku | コストパフォーマンスを重視 | 中 |
大量のバッチ処理 | オープンソースLLM(Llama等) | オンプレミス実行でコスト削減 | 低 |
専門領域の処理 | ファインチューニング済みモデル | ドメイン特化の精度向上 | 中〜高 |
リアルタイム応答 | 軽量モデル / エッジAI | レスポンス速度を最優先 | 低 |
マルチモデル管理機能により、これらの使い分けを統一的なインターフェースで管理できるようになりました。また、MCPとOAuthの統合により、各モデルへのアクセス権限を細かく制御できるため、コンプライアンスやコスト管理の観点からも優れた設計となっています。
Flask-RESTXへの移行が示す技術的成熟度
1.8.0でのFlask-RESTXへの移行とSwagger認可の実装は、一見すると地味な変更に見えますが、エンタープライズ環境での採用において重要な意味を持ちます。
Flask-RESTXは、RESTful APIの開発において以下の利点を提供します。
- API仕様の自動生成により、開発者間のコミュニケーションコストが削減
- 入力検証の標準化により、セキュリティホールの発生リスクが低減
- Swagger UIの統合により、API利用者の学習コストが削減
特にSwaggerの認可設定が追加されたことで、APIドキュメント自体へのアクセス制御が可能になりました。これは、企業の内部APIを外部パートナーと選択的に共有する際に重要な機能です。
バージョン2.0ベータ:次世代AI基盤への進化
Knowledge Pipelineが解決する本質的課題
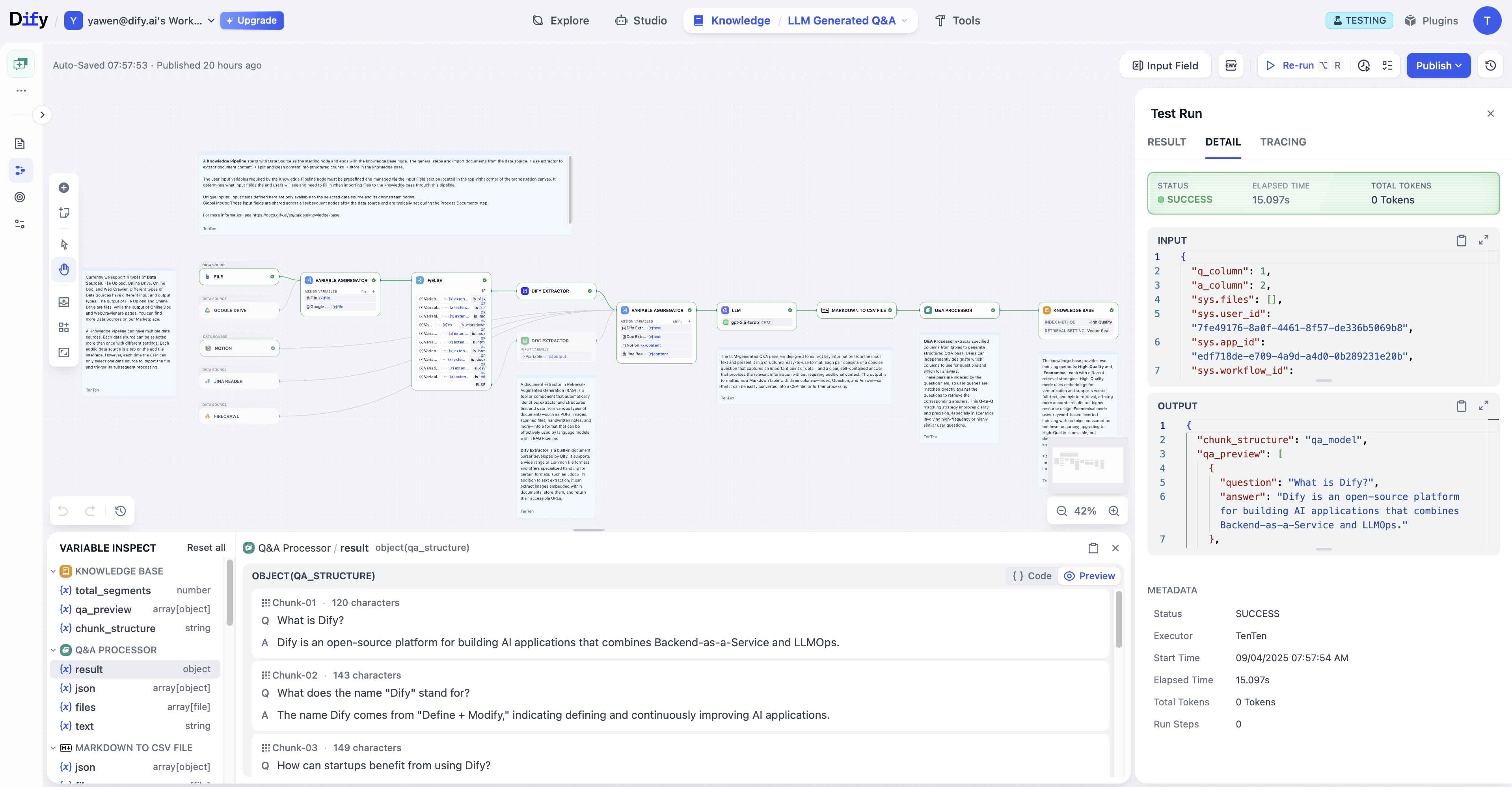
2024年9月4日にリリースされた2.0.0-beta.1で導入された「Knowledge Pipeline」は、RAG実装における根本的な課題に対する包括的なソリューションです。
従来のRAG実装では、データの取り込みから前処理、インデックス化まで の一連の処理が硬直的で、以下のような課題がありました。
- PDFの表や画像が適切に処理されず、重要な情報が欠落
- 異なるデータソースごとに個別の処理ロジックが必要で、保守が困難
- チャンキング戦略が固定的で、文書の特性に応じた最適化ができない
Knowledge Pipelineは、これらの課題に対して「ノードベースのオーケストレーション」というアプローチで対応しています。各処理ステップをノードとして定義し、それらを柔軟に組み合わせることで、データソースや用途に応じた最適な処理パイプラインを構築できます。
特に注目すべきは「Q&A向け新チャンク戦略」と「画像抽出・混在回答」機能です。これにより、技術文書やマニュアルなど、図表を多く含む文書からの情報抽出精度が大幅に向上しています。私の経験では、製造業や医療分野のクライアントにおいて、この機能は特に価値が高いと考えられます。
DSLとテンプレートによる再現性の確保
Knowledge PipelineのDSL(Domain Specific Language)Import/Export機能は、企業のAI運用において重要な「再現性」と「ポータビリティ」を提供します。
企業環境では、以下のようなシナリオで再現性が求められます。
- 開発環境で構築したパイプラインを、検証環境、本番環境へと段階的に展開
- 成功したパイプライン設定を、他のプロジェクトや部門で再利用
- 監査やコンプライアンス対応のため、特定時点の設定を正確に再現
DSLによる設定のコード化により、これらの要求に対応できるだけでなく、Gitなどのバージョン管理システムとの統合も容易になります。これは、「Infrastructure as Code」の考え方をAIパイプラインに適用したものと言えます。
Queue-based Graph Engineの革新性
2.0.0-beta.1で導入されたQueue-based Graph Engineは、複雑なワークフローの実行制御において画期的な進化を遂げています。
このエンジンの特徴を技術的観点から分析すると、以下の点が特に優れています。
- 統一キューによる実行管理により、システム全体の負荷分散とスケーリングが容易
- 任意ノードからの部分実行・再開機能により、デバッグ効率が飛躍的に向上
- ResponseCoordinatorによるストリーム統合で、リアルタイム性と確実性を両立
特に「任意ノードからの部分実行」機能は、エンタープライズ環境での運用において極めて重要です。例えば、10段階の処理を含むワークフローで8段階目にエラーが発生した場合、従来は最初から処理をやり直す必要がありましたが、この機能により8段階目から再開できます。これは、処理時間の短縮だけでなく、外部APIのコスト削減にも直結します。
企業AI戦略への示唆
段階的導入戦略の重要性
Difyの1.7から2.0への進化を見ると、明確な段階的アプローチが取られていることがわかります。これは、企業がAIを導入する際の戦略としても参考になります。
推奨される段階的導入アプローチは以下の通りです。
- 基盤整備フェーズ(1.7系相当):認証・認可の確立、運用自動化の基盤構築、可視化ツールの導入
- パフォーマンス最適化フェーズ(1.8系相当):非同期処理の導入、マルチモデル管理、API標準化
- 高度化フェーズ(2.0系相当):Knowledge Pipelineによる知識管理の体系化、高度な実行制御の実装
各フェーズで得られた知見を次のフェーズに活かすことで、リスクを最小化しながら着実にAI活用を進めることができます。
オープンソースAI基盤選定の判断基準
Difyの進化から見えてくる、オープンソースAI基盤を選定する際の重要な判断基準を整理すると以下のようになります。
表:オープンソースAI基盤の評価基準
評価項目 | 重要度 | Difyの対応状況 | 評価のポイント |
|---|---|---|---|
セキュリティ機能 | 高 | OAuth 2.0、TLS/SSL対応 | 企業のセキュリティポリシーへの準拠可能性 |
スケーラビリティ | 高 | 非同期実行、キューベース設計 | 将来的な負荷増加への対応能力 |
運用性 | 高 | 自動アップグレード、可視化ツール | 運用チームの負荷と必要スキルレベル |
拡張性 | 中 | プラグインシステム、DSL対応 | 独自要件への対応可能性 |
コミュニティ活性度 | 中 | 月次アップデート、活発な開発 | 長期的なサポートの期待可能性 |
ドキュメント充実度 | 中 | API仕様自動生成、移行ガイド | 導入・運用の学習コスト |
内製化vs外部サービス利用の判断ポイント
Difyのようなオープンソース基盤を使った内製化と、ChatGPT APIなどの外部サービス利用の選択は、企業のAI戦略において重要な意思決定です。
内製化が適している条件として、以下が挙げられます。
- 機密性の高いデータを扱う必要があり、外部送信が困難
- 大量のリクエストが予想され、外部APIのコストが課題になる
- 独自のビジネスロジックや処理フローが必要で、汎用サービスでは対応困難
- 長期的な運用を前提とし、ベンダーロックインを回避したい
一方で、内製化には「初期構築コスト」「運用体制の確立」「継続的なアップデート対応」といった課題もあります。Difyの最新アップデートは、これらの課題を軽減する方向に進化していますが、それでも一定の技術力と体制は必要です。
技術的考察と今後の展望
エンタープライズAI基盤の成熟度評価
Difyの1.7から2.0への進化を、エンタープライズ向けAI基盤としての成熟度という観点で評価すると、以下の点で大きな前進が見られます。
まず、セキュリティ面では、OAuth 2.0対応とTLS/SSL証明書認証により、企業のセキュリティ要件を満たすレベルに到達しています。これは、金融機関や医療機関といった規制の厳しい業界でも採用可能なレベルです。
次に、パフォーマンス面では、非同期実行エンジンの導入により、実用的なレスポンス速度を実現しています。「実行時間がほぼ半減」という改善は、ユーザー体験の向上だけでなく、インフラコストの削減にも直結します。
運用面では、プラグイン自動アップグレードやDSLによる設定管理など、DevOpsの考え方が取り入れられています。これにより、継続的な改善とリリースのサイクルを回すことが可能になっています。
残された技術的課題と対応の方向性
一方で、エンタープライズ環境での本格的な採用に向けて、まだいくつかの課題が残されています。
現時点で認識される主要な技術課題は以下の通りです。
- マルチテナント対応の強化(リソース分離、課金管理など)
- 高可用性構成のサポート(アクティブ-アクティブ構成、自動フェイルオーバーなど)
- 監視・アラート機能の充実(SLO/SLAの定義と追跡)
- バックアップ・リストア機能の体系化
- コンプライアンス対応機能(監査ログ、データ保持ポリシーなど)
2.0.0-beta.1のロードマップを見ると、「可視デバッガ」「ブレークポイント」「Human-in-the-Loop」といった機能が計画されており、これらの課題に対する対応が進められていることがわかります。
AIネイティブアーキテクチャへの進化
Difyの進化を俯瞰すると、従来のアプリケーション開発の考え方から「AIネイティブアーキテクチャ」への移行が見て取れます。
AIネイティブアーキテクチャの特徴として、以下の要素が挙げられます。
- 処理の不確実性を前提とした設計(リトライ、フォールバック、グレースフルデグラデーション)
- コンテキスト管理の重要性(セッション管理、メモリ管理、コンテキストウィンドウの最適化)
- ハイブリッド処理の標準化(ルールベース処理とAI処理の組み合わせ)
- 継続的な品質改善のループ(フィードバック収集、ファインチューニング、A/Bテスト)
Difyの最新アップデートは、これらの要素を実装レベルで具現化しており、AIネイティブアプリケーション開発のベストプラクティスを示していると評価できます。
日本企業への適用における留意点
日本企業がDifyを採用する際には、いくつか特有の考慮事項があります。
まず、日本語処理の品質です。最新バージョンでは国際化対応が強化されていますが、日本語特有の処理(形態素解析、敬語処理など)については、追加のカスタマイズが必要な場合があります。特にKnowledge Pipelineでのチャンキング戦略は、日本語文書の特性に合わせた調整が重要です。
次に、既存システムとの統合です。日本企業の多くは、長年運用されてきたレガシーシステムを抱えています。これらのシステムとDifyを連携させる際には、文字コードの変換やデータフォーマットの調整など、細かな対応が必要になることがあります。
また、運用体制の構築も重要な課題です。日本企業では、AIシステムの運用経験を持つエンジニアがまだ少ないのが現状です。Difyの導入と並行して、運用チームの教育や体制整備を進める必要があります。
まとめ:エンタープライズAI基盤としてのDifyの可能性
戦略的評価
Difyの1.7から2.0への進化を総合的に評価すると、エンタープライズ向けAI基盤として必要な要素が着実に整備されていることがわかります。特に以下の3点は高く評価できます。
第一に、セキュリティと運用性のバランスが取れた設計になっている点です。OAuth 2.0対応や自動アップグレード機能により、セキュリティを維持しながら運用負荷を削減できます。
第二に、段階的な機能拡張により、安定性を保ちながら革新的な機能を導入している点です。1.7での基盤整備、1.8でのパフォーマンス改善、2.0での根本的な再設計という流れは、実運用を重視した現実的なアプローチです。
第三に、オープンソースでありながら、エンタープライズグレードの品質を実現している点です。テストの充実、ドキュメントの整備、移行ツールの提供など、商用製品に劣らないレベルのサポートが提供されています。
導入推奨シナリオ
現時点でのDifyの成熟度を考慮すると、以下のようなシナリオでの導入が推奨されます。
推奨される導入シナリオと段階的アプローチ:
- フェーズ1:部門レベルでのPoC実施(1.8.1の安定版を使用)
- フェーズ2:限定的な本番導入(特定業務での活用、ユーザー数を限定)
- フェーズ3:2.0正式版での本格展開(全社展開に向けた準備)
特に、カスタマーサポート、社内ヘルプデスク、ドキュメント検索といった用途から始めることで、リスクを抑えながら効果を実証できます。
今後の展望と期待
Difyのロードマップを見ると、さらなる進化が計画されています。特に期待される機能として、以下が挙げられます。
- Human-in-the-Loop機能による、人間の判断を組み込んだワークフロー
- サブグラフ対応による、ワークフローの再利用性向上
- 多モーダル埋め込みによる、画像や音声を含む統合的な処理
これらの機能が実装されれば、Difyはエンタープライズ向けAI基盤として、商用製品と肩を並べる存在になる可能性があります。
私の見解では、Difyは「オープンソースAI基盤の新たなスタンダード」となる可能性を秘めています。特に、企業が自社のデータとノウハウを活用してAIアプリケーションを構築する際の、有力な選択肢となるでしょう。ただし、2.0はまだベータ版であり、本番環境への適用には慎重な検証が必要です。まずは1.8系の安定版で経験を積み、2.0の正式リリースに備えることをお勧めします。
エンタープライズAIの実装において、技術選定は戦略的意思決定です。Difyの進化は、その選択肢を大きく広げるものであり、今後の動向に注目していく価値があると考えます。
























