



NTTの大規模言語モデル「tsuzumi」2025年の日本語AI最前線
2024年から2025年にかけて、国産の大規模言語モデルが次々と商用化されている中で、特に注目を集めているのがNTTが開発した「tsuzumi(つづみ)」です。2023年11月に発表され、2024年3月から商用提供を開始したこのモデルは、日本語処理に特化した軽量設計で実用的な成果を上げています。実際の導入事例や利用者の声を通じて、tsuzumiがどのような価値を提供しているのか、そして日本の生成AI活用において果たしている役割について詳しく見ていきましょう。
tsuzumiの独自性と技術的アプローチ
軽量化による実用性の追求
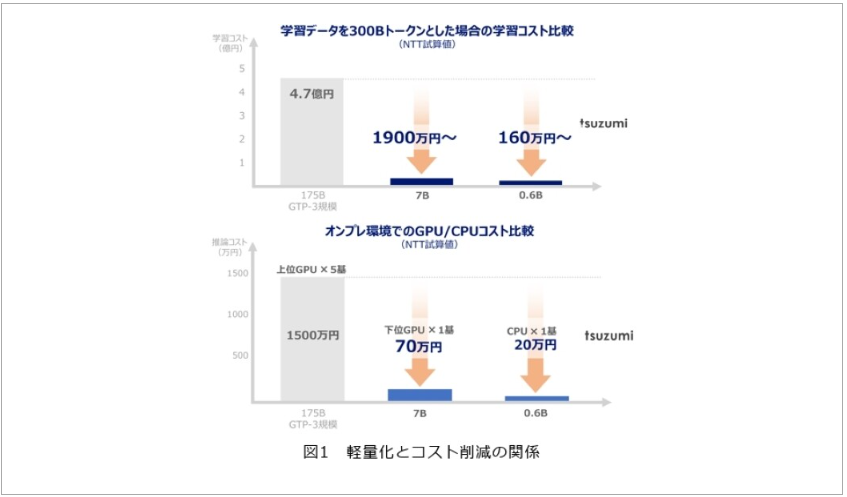
tsuzumiの最大の特徴は、「軽量でありながら高性能」という一見矛盾する要求を実現している点にあります。パラメータ数は70億(7B)の軽量版と6億(0.6B)の超軽量版を用意しており、これはOpenAI GPT-3の約1/25〜1/300の規模です。
実際にこの軽量性がどれほど実用的かというと、軽量版は1台のGPU、超軽量版はCPU上でも高速推論が可能なサイズとなっています。これにより、従来は大規模なGPUクラスタが必要だったLLM活用が、オンプレミス環境や省電力なローカル環境でも実現できるようになりました。
日本語特化の技術的工夫
tsuzumiが小型でも高い日本語性能を実現できている背景には、NTTの40年以上にわたる自然言語処理技術の蓄積があります。特に注目すべきは「単語制約トークナイザ」という独自の日本語処理技術です。
形態素解析の知見を活かして日本語の単語境界を考慮したトークン分割を行うことで、海外LLMで問題となる「日本語が文字単位に細切れになる問題」を解決しています。この技術的工夫により、生成速度と理解精度の両方を向上させることに成功しました。
実際の導入現場での評価と成果
医療分野での具体的な成果
医療現場でのtsuzumi活用は特に注目すべき点かと思います。京都大学医学部附属病院との協力による電子カルテ活用実証では、カルテデータの構造化による統計分析の効率化が実現されています。
2024年11月には三重大学医学部附属病院でも実証実験が開始され、退院時要約(退院サマリー)の作成業務にtsuzumiを活用する取り組みが進んでいます。年間1.5万件の退院サマリー作成において、医師の作業時間短縮と品質向上の両立を目指しています。
医療現場の関係者からは「患者の個人情報をクラウドに出さずに院内でカルテ要約が行える点が大きな安心材料」という声が聞かれており、セキュリティ面での優位性が高く評価されています。
コンタクトセンターでの業務革新
コンタクトセンター分野では、東京海上日動火災保険との協業事例が注目されています。全国で1万人超のオペレーターが対応する事故受付センターにおいて、通話後の内容整理・システム入力作業(アフターコールワーク)の自動化により、年間約80万時間の工数を50%以上削減できると試算されています。
実際にtsuzumiを使った要約機能を体験した現場オペレーターからは「長時間の事故ヒアリング内容を的確に要約してくれるため、記録作成の負担が大幅に軽減された」との評価が得られています。
教育現場での先進的な取り組み
東京通信大学では、日本の高等教育機関として初めてtsuzumiを授業支援に活用することを発表しました。通信制大学の特性を活かし、24時間リアルタイムの質疑応答環境を整備することで、学生一人ひとりに対応した質の高い学習コンテンツ提供を目指しています。
教育現場からは「学生の多様な質問に日本語で的確に回答できる対話能力」に期待が寄せられており、AI学習アシスタントとしての機能拡張も計画されています。
利用者から見たtsuzumiの実用性
安全性とカスタマイズ性の両立
実際にtsuzumiを導入した企業からの評価で特に高いのは、「データを外部に出さずにLLMを活用できる安心感」です。機密情報を扱う金融・保険業界や医療機関では、この点が導入の決定要因となっているケースが多く見られます。
また、「アダプタ」技術による柔軟なカスタマイズも実用面で高く評価されています。モデル全体を再学習することなく、業界特有の用語や文体を追加学習させることで、短時間・低コストでの専門特化が可能になっています。
日本語処理の精度への評価
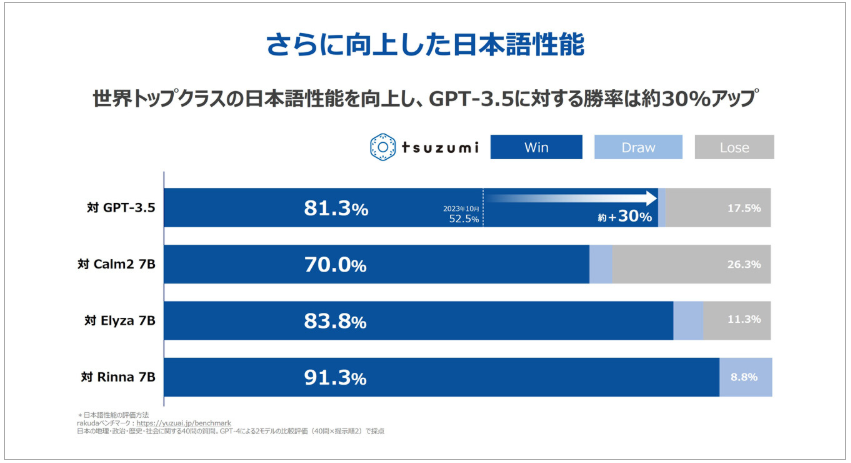
利用者からの技術的評価では、日本語処理の精度の高さが頻繁に言及されています。Rakudaベンチマークでは2024年3月時点でGPT-3.5に対して81.3%の勝率を記録しており、これは2023年10月の52.2%から大幅に向上した結果です。
特に「細かな言い回しのニュアンスや文脈理解」において、ChatGPTなど海外LLMで課題だった部分での優位性が実感されています。医療現場では「患者ごとに適した治療の提案ができる精度」、コンタクトセンターでは「丁寧な聞き取り内容から事故状況を要約する能力」として、その精度の高さが評価されています。
技術的な限界と今後の展望
現在の制約と対応策
一方で、軽量モデルゆえの制約も指摘されています。7Bという規模上、超大規模モデルと比較して知識カバレッジに限りがあるのは事実です。この点についてNTTは、「1つの巨大LLMに全知識を詰め込むより、専門性や個性を持った小さなLLMの集合知で課題を解決する世界」を目指すアプローチを明示しています。
実際の対応策として、外部知識ベースと組み合わせる「Retrieval Augmented Generation(RAG)」手法の活用や、業界特化モデルの開発を進めています。NTTデータによる保険業界向けの特化生成AIモデルの検証では、RAGと組み合わせたQAタスクで良好な成果を上げています。
マルチモーダル対応と将来計画
技術的な発展として、tsuzumiは言語以外の情報源(画像や音声など)を扱えるマルチモーダル対応にも注力しています。2023年11月のNTT R&Dフォーラムでは、グラフや表を含む文書画像を読み取って質問に答えるデモが披露されました。
また、将来的には「中型版」(約130億パラメータ)の開発も計画されており、より高度な推論や知識量が要求されるタスクへの対応力向上が期待されています。
Microsoft Azureでの提供開始による影響
開発者コミュニティへの開放
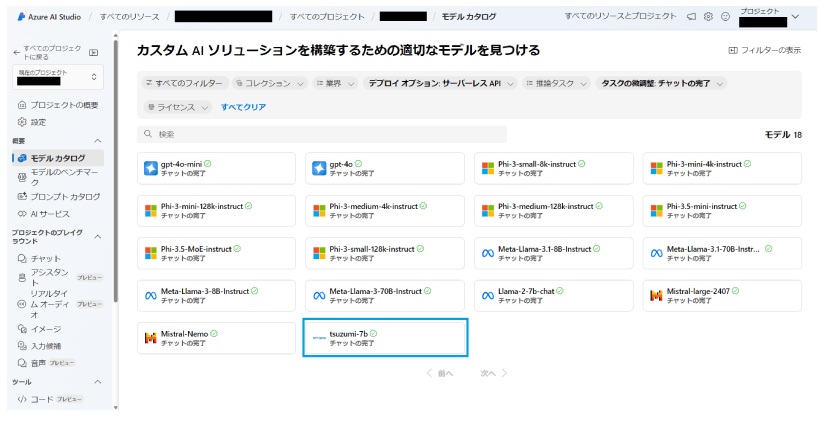
2024年11月からMicrosoft Azure上でtsuzumiの提供が開始されたことは、大きな転換点となっています。これまでNTTとの個別契約や専用環境構築が必要だったtsuzumiが、Azureマーケットプレイス経由で広範な開発者コミュニティに開放されました。
Azure上では従量課金制で提供され、利用者はAzure AI StudioというGUI上でモデルの設定・デプロイ・推論実行が可能になっています。また、専用のファインチューニング機能も用意されており、自社データで追加学習させたカスタムtsuzumiモデルの構築も容易になりました。
エコシステム形成への期待
Azure経由の提供により、スタートアップ企業や研究者でも手軽に日本語特化LLMを試用できるようになったことで、新たなアプリケーション開発や研究が促進される可能性があります。Azure OpenAIサービスなどと同様にクラウド上で使えることで、既存の業務システムやアプリケーションとの統合も容易になっています。
まとめ
国産生成AIエコシステムにおける役割
2025年現在、tsuzumiは「日本語に強い、省リソース型LLM」という独自ポジションを確立しつつあります。海外の超大規模モデルとは異なるアプローチで、実用性と効率性を重視した設計思想が、特に企業での業務活用において支持を得ています。
NTT自身も「満を持してデビューした」と表現するように、技術面・実応用面ともに着実な進展を見せており、国内生成AI市場での存在感を増しています。
今後への期待
今後は中型版の投入、多言語化、マルチモーダル対応の強化により、さらに性能と用途の幅が広がることが期待されています。同時に、安全性への配慮やエコシステム形成を進めることで、企業・公共・教育など様々な分野で信頼して使える国産LLMとしての地位を築くことが期待されます。
「tsuzumi」が日本発の生成AI活用を力強く先導していく姿は、今後も注目に値するでしょう。特に、データプライバシーを重視する業界や、きめ細かい日本語対応が必要な現場において、海外モデルでは実現困難な価値を提供し続けることが期待されています。
実際に様々な現場の声を見てtsuzumiを活用した経験を通じて感じるのは、「技術的な優秀さ」と「実用性」のバランスの良さです。必ずしも最大・最強である必要はなく、現場のニーズに適切に応える技術こそが真に価値のあるソリューションであることを、tsuzumiの成功事例は物語っているのではないでしょうか。
























