


SQSとは?分散システムの結合度を下げる仕組み
メッセージキューが解決する現実の課題
「SQSとは」何か、という問いに対する教科書的な答えは「完全マネージドのメッセージキューサービス」ですが、実際のシステム開発においては、それ以上の意味を持っています。
最近携わったプロジェクトで、ECサイトの注文処理システムをモノリシックからマイクロサービスへ移行する案件がありました。当初、各サービス間を同期的なREST APIで繋いでいましたが、決済サービスのレスポンスが遅延すると、注文受付サービス全体がタイムアウトしてしまうという問題に直面しました。この時に導入したのが「Amazon SQS」でした。
SQSを介することで、注文受付サービスは注文情報をキューに投入した時点で即座にユーザーへレスポンスを返せるようになり、決済処理は非同期で確実に実行される仕組みを構築できました。このように、SQSは単なるキューではなく、システム間の「疎結合化」を実現し、全体の可用性と応答性を向上させる重要な基盤となります。
標準キューとFIFOキューの使い分けの実践的指針
SQSには「標準キュー」と「FIFOキュー」の2種類が存在します。この「標準キュー FIFO 違い」を理解することは、適切なアーキテクチャ設計の第一歩です。
標準キューは以下の特性を持ちます。
キュー種類 | 概要 |
|---|---|
標準キュー |
|
FIFOキュー |
|
実際のプロジェクトでは、金融取引のような順序性が絶対条件となる処理にはFIFOキューを選択し、ログ収集やバッチ処理のような大量データを扱う場面では標準キューを採用してきました。
重要なのは、「完璧を求めすぎない」ことです。例えば、ユーザー通知のような処理では、多少の重複や順序の入れ替わりを許容して標準キューを使うことで、システム全体のパフォーマンスを大幅に向上させることができます。
SQS Lambda 連携によるサーバーレスアーキテクチャの構築
イベントソースマッピングによる自動連携の仕組み
「SQS Lambda」の組み合わせは、現代のサーバーレスアーキテクチャにおいて最もパワフルなパターンの一つです。Lambda関数は「SQS Lambda ポーリング」を通じて、キューからメッセージを自動的に取得し、処理を実行します。
AWS Lambda のイベントソースマッピング機能を使用することで、以下のような設定が可能です。
import { SQSHandler, SQSEvent } from 'aws-lambda';
export const handler: SQSHandler = async (event: SQSEvent) => {
for (const record of event.Records) {
const messageBody = JSON.parse(record.body);
try {
// ビジネスロジックの実行
await processOrder(messageBody);
// 成功時は自動的にメッセージが削除される
} catch (error) {
console.error('Processing failed:', error);
// エラー時は可視性タイムアウト後に再処理される
throw error;
}
}
};この設定により、Lambda側でポーリング処理を実装する必要がなくなり、純粋にビジネスロジックに集中できます。また、Lambda の同時実行数を制御することで、後続のデータベースやAPIへの負荷を適切に管理できる点も大きなメリットです。
バッチ処理と並列処理の最適化戦略
「SQS Lambda ポーリング」において、バッチサイズの設定は性能に大きく影響します。私の経験では、以下のような指針で設定を行っています。
表 バッチサイズ設定の推奨値
ユースケース | バッチサイズ | 並列実行数 | 理由 |
|---|---|---|---|
リアルタイム処理 | 1-5 | 10-50 | レイテンシを最小化 |
バッチ処理 | 10-25 | 5-20 | スループット重視 |
重い処理(動画変換等) | 1 | 1-5 | リソース制約を考慮 |
バッチサイズを大きくすれば Lambda の起動回数が減り、コスト効率は向上しますが、処理の失敗時には全メッセージが再処理される可能性があります。このトレードオフを理解し、適切なバランスを見つけることが重要です。
Dead Letter Queue(DLQ)による例外処理の設計
処理に失敗したメッセージを適切に扱うため、Dead Letter Queue の設定は必須です。以下のような TypeScript のコード例で、DLQ への移動条件を制御できます。
interface DLQConfig {
maxReceiveCount: number; // 最大受信回数
deadLetterTargetArn: string; // DLQのARN
}
const setupDLQ = (config: DLQConfig): void => {
// CloudFormation や CDK での設定例
const dlqPolicy = {
deadLetterTargetArn: config.deadLetterTargetArn,
maxReceiveCount: config.maxReceiveCount || 5
};
// 5回の処理失敗後、自動的にDLQへ移動
};DLQに移動したメッセージは別途調査・分析を行い、システムの改善点を見つける貴重な情報源となります。実際、あるプロジェクトでは、DLQのメッセージ分析から、特定の文字エンコーディングに起因する処理エラーを発見し、システム全体の品質向上に繋げることができました。
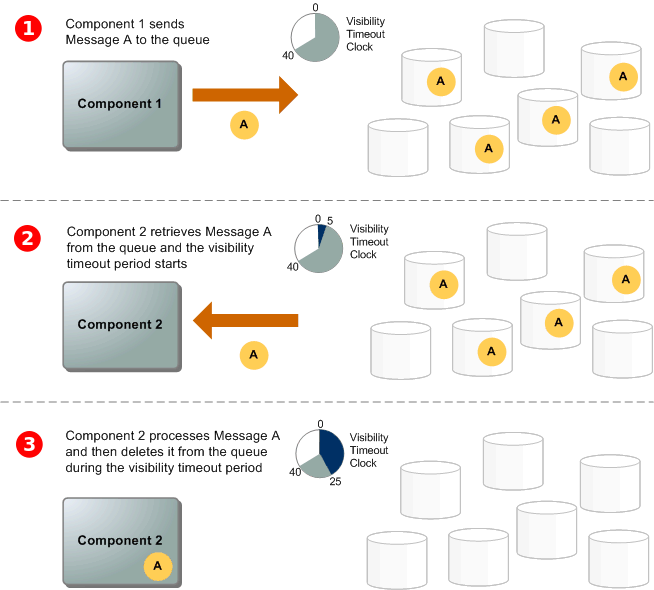
可視性タイムアウトとポーリング戦略の最適化
可視性タイムアウトの適切な設定方法
「可視性タイムアウト」は、メッセージが一度コンシューマーに渡ってから、再び他のコンシューマーに見えるようになるまでの待ち時間です。この設定は処理の性質によって慎重に調整する必要があります。
実務での経験から、以下のような設定基準を採用しています。
- 処理時間が予測可能な場合:処理時間の1.5〜2倍の値を設定
- 処理時間が変動する場合:最大処理時間+バッファ(30秒〜1分)を設定
- 長時間処理の場合:処理中に定期的に ChangeMessageVisibility API を呼び出してタイムアウトを延長
import { SQS } from '@aws-sdk/client-sqs';
const sqs = new SQS({ region: 'ap-northeast-1' });
const extendVisibilityTimeout = async (
queueUrl: string,
receiptHandle: string,
extensionSeconds: number
): Promise<void> => {
await sqs.changeMessageVisibility({
QueueUrl: queueUrl,
ReceiptHandle: receiptHandle,
VisibilityTimeout: extensionSeconds
});
};長ポーリングによるコスト最適化
SQSでは「長ポーリング」を使用することで、空振りのAPI呼び出しを大幅に削減できます。WaitTimeSeconds を20秒(最大値)に設定することで、以下のメリットが得られます。
- API呼び出し回数の削減によるコスト削減
- メッセージ到着時の即座の応答によるレイテンシ改善
- CPU使用率の低減
実際のコスト比較を行ったところ、短ポーリングから長ポーリングへ切り替えることで、月間のSQS関連コストを約40%削減できました。
サーバーレスアーキテクチャにおける実装上の注意点
冪等性の確保とメッセージ重複への対処
標準キューでは「At-Least-Once」配信のため、同じメッセージが複数回配信される可能性があります。そのため、処理の「冪等性」を確保することが極めて重要です。
以下のようなアプローチで冪等性を実現しています。
interface ProcessingRecord {
messageId: string;
processedAt: Date;
result: any;
}
const processMessageIdempotently = async (
messageId: string,
messageBody: any
): Promise<void> => {
// DynamoDBなどでメッセージIDをチェック
const existingRecord = await getProcessingRecord(messageId);
if (existingRecord) {
console.log(`Message ${messageId} already processed`);
return;
}
// 処理を実行
const result = await executeBusinessLogic(messageBody);
// 処理済みとして記録(条件付き書き込みで重複を防ぐ)
await saveProcessingRecord({
messageId,
processedAt: new Date(),
result
});
};エラーハンドリングとリトライ戦略
サーバーレス環境では、一時的な障害に対する適切なリトライ戦略が重要です。以下の階層的なアプローチを採用しています。
エラーの種類に応じた処理方針を定めます。
- 一時的エラー(ネットワークエラー等):指数バックオフでリトライ
- ビジネスロジックエラー:即座にDLQへ移動
- リソース不足エラー:アラート発報後、一定時間待機してリトライ
enum ErrorType {
TRANSIENT = 'TRANSIENT',
BUSINESS_LOGIC = 'BUSINESS_LOGIC',
RESOURCE_EXHAUSTED = 'RESOURCE_EXHAUSTED'
}
const categorizeError = (error: Error): ErrorType => {
if (error.message.includes('Network')) {
return ErrorType.TRANSIENT;
}
if (error.message.includes('Invalid')) {
return ErrorType.BUSINESS_LOGIC;
}
if (error.message.includes('Throttled')) {
return ErrorType.RESOURCE_EXHAUSTED;
}
return ErrorType.TRANSIENT;
};スケーリングとコスト管理のバランス
サーバーレスアーキテクチャでは、自動スケーリングが大きな利点ですが、無制限にスケールさせるとコストが跳ね上がる可能性があります。
Lambda の同時実行数制限を適切に設定することで、以下のバランスを取ります。
表 環境別の同時実行数推奨設定
環境 | 同時実行数上限 | 理由 |
|---|---|---|
開発環境 | 5 | リソース節約 |
ステージング環境 | 20 | 本番相当のテスト |
本番環境 | 100-500 | ビジネス要件に応じて調整 |
AWS のコスト最適化に関する公式ガイダンスでも、適切なリソース制限の重要性が強調されています。
実践的な活用事例と今後の展望
マイクロサービス間の非同期通信パターン
実際のプロジェクトで構築した、注文処理システムのアーキテクチャを例に説明します。
// 注文サービスからのメッセージ送信
const sendOrderToQueue = async (order: Order): Promise<void> => {
const message = {
orderId: order.id,
customerId: order.customerId,
items: order.items,
timestamp: new Date().toISOString()
};
await sqs.sendMessage({
QueueUrl: process.env.ORDER_QUEUE_URL!,
MessageBody: JSON.stringify(message),
MessageAttributes: {
orderType: {
DataType: 'String',
StringValue: order.type
}
}
});
};このパターンにより、注文サービス、在庫サービス、配送サービスがそれぞれ独立してデプロイ・スケール可能となり、システム全体の保守性が大幅に向上しました。
イベント駆動アーキテクチャへの発展
SQS は単体でも強力ですが、Amazon EventBridge や AWS Step Functions と組み合わせることで、より洗練されたイベント駆動アーキテクチャを構築できます。
最近取り組んでいるプロジェクトでは、以下のような複合的なアーキテクチャを採用しています。
- EventBridge でイベントのルーティングとフィルタリング
- SQS でメッセージのバッファリングと確実な配信
- Step Functions でワークフローのオーケストレーション
- Lambda でビジネスロジックの実行
このアプローチにより、複雑なビジネス要件にも柔軟に対応できるようになりました。
サーバーレスアーキテクチャの今後の進化
サーバーレス技術は急速に進化しており、SQS と Lambda の連携もより高度になっています。2024年後半には Lambda の SnapStart が Python にも対応し、コールドスタート時間が大幅に改善されました。
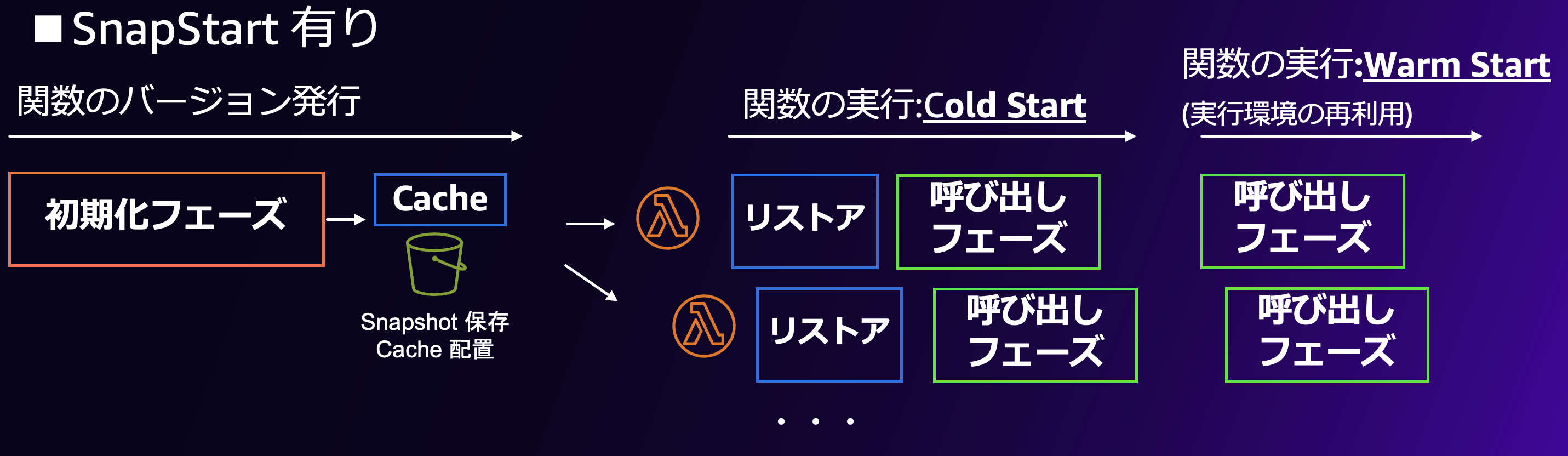
今後の展望として、以下のような進化が期待されます。
- より細かいメッセージフィルタリング機能の追加
- 機械学習を活用した自動的なスケーリング最適化
- クロスリージョンでのメッセージレプリケーション機能の強化
実装時の落とし穴と対策
ヘッドオブラインブロッキング問題への対処
FIFO キューを使用する際、先頭のメッセージ処理が失敗すると、後続のメッセージも処理できなくなる「ヘッドオブラインブロッキング」が発生することがあります。
この問題に対しては、メッセージグループIDを活用した並列処理が有効です。
const sendMessageWithGrouping = async (
message: any,
groupId: string
): Promise<void> => {
await sqs.sendMessage({
QueueUrl: process.env.FIFO_QUEUE_URL!,
MessageBody: JSON.stringify(message),
MessageGroupId: groupId, // グループ単位で並列処理可能
MessageDeduplicationId: generateHash(message)
});
};ユーザーごとや取引タイプごとにグループIDを設定することで、一部の処理が滞っても他のグループは進行できるようになります。
メッセージサイズ制限への対応
SQS のメッセージサイズ上限は 256KB です。これを超える大きなデータを扱う場合は、「S3 を経由したパターン」を採用します。
interface LargeMessagePattern {
s3Bucket: string;
s3Key: string;
metadata: {
size: number;
contentType: string;
};
}
const sendLargeMessage = async (
largeData: Buffer
): Promise<void> => {
// S3 にデータをアップロード
const s3Key = `messages/${Date.now()}-${uuidv4()}`;
await s3.putObject({
Bucket: process.env.S3_BUCKET!,
Key: s3Key,
Body: largeData
});
// SQS にはS3の参照情報のみを送信
const messageBody: LargeMessagePattern = {
s3Bucket: process.env.S3_BUCKET!,
s3Key,
metadata: {
size: largeData.length,
contentType: 'application/octet-stream'
}
};
await sqs.sendMessage({
QueueUrl: process.env.QUEUE_URL!,
MessageBody: JSON.stringify(messageBody)
});
};AWS の拡張クライアントライブラリを使用すれば、この処理を自動化することも可能です。
まとめ
Amazon SQS は、単なるメッセージキューサービスではなく、サーバーレスアーキテクチャの中核を担う重要な基盤です。「SQS Lambda 連携」により、スケーラブルで堅牢な非同期処理システムを、最小限の運用負荷で構築できます。
本記事で解説した「標準キュー FIFO 違い」や「可視性タイムアウト」の適切な設定、「SQS ベストプラクティス」の実践により、プロダクション環境でも安定したシステムを構築できるはずです。
個人的な見解として、SQS の真の価値は「シンプルさ」にあると考えています。Apache Kafka や RabbitMQ のような高機能なメッセージブローカーと比較すると、機能面では劣る部分もありますが、その分、学習コストが低く、運用も容易です。特にスタートアップやアジャイル開発を重視するチームにとって、この「始めやすさ」は大きなアドバンテージとなります。
今後もサーバーレス技術の進化とともに、SQS の重要性はさらに高まっていくでしょう。継続的な学習と実践を通じて、より良いアーキテクチャを追求していきたいと思います。
























