


LiteLLMが解決するマルチプロバイダ時代の課題
企業が直面するLLM活用の現実
2024年から2025年にかけて、企業のAI活用は新たなフェーズに入りました。単一のLLMプロバイダに依存するリスクが認識され、複数サービスを戦略的に使い分ける「マルチLLM戦略」が主流になりつつあります。
しかし、現場のエンジニアは深刻な課題に直面しています。OpenAIのGPT-5を使っていたプロジェクトでAnthropicのClaudeも試したい、コスト削減のためにAzure OpenAIに切り替えたい、といった要望に対応するたびに、各プロバイダ固有のAPI仕様を学習し、個別の実装を行う必要があります。これは単なる工数の問題だけでなく、コードの保守性やテストの複雑化にもつながっています。
Netflix社の事例では、新しいモデルが発表されてから社内ユーザへ提供するまでの期間を「Day 0」で実現することを目標としていましたが、従来の方法では各モデルごとに何時間もの実装作業が必要でした。同社はLiteLLMの導入により、累計で数ヶ月分の開発期間を削減できたと報告しています。
LiteLLMが提供する統合アプローチ
「LiteLLM」は、この複雑な状況を根本的に解決するオープンソースのゲートウェイ/SDKです。その核心的な価値は、100以上のLLMプロバイダへのアクセスを「OpenAI互換フォーマット」で統一することにあります。
開発者は、プロバイダごとのAPI差異を意識することなく、以下のような統一的なコードでモデルを呼び出せます。
from litellm import completion
# OpenAIでもAnthropicでも同じインターフェース
response = completion(
model="gpt-4", # または "claude-3" など
messages=[{"role": "user", "content": "Hello!"}]
)この抽象化レイヤにより、アプリケーションコードを変更することなく、バックエンドのLLMサービスを自由に切り替えることが可能になります。
実装から本番運用までの具体的なステップ
Python SDKを使った基本実装
環境構築と初期設定
LiteLLMの導入は驚くほどシンプルです。Python 3.8以上の環境があれば、以下のコマンドで即座に開始できます。
pip install litellm環境変数にAPIキーを設定することで、各プロバイダへの接続が確立されます。
import os
from litellm import completion
# 各プロバイダのAPIキーを環境変数に設定
os.environ["OPENAI_API_KEY"] = "your-openai-key"
os.environ["ANTHROPIC_API_KEY"] = "your-anthropic-key"
os.environ["AZURE_API_KEY"] = "your-azure-key"
os.environ["AZURE_API_BASE"] = "<https://your-endpoint.openai.azure.com>"プロバイダ間の切り替え実装
実際のコードでプロバイダを切り替える際の実装パターンを見てみましょう。
def get_ai_response(prompt, model_choice="openai"):
"""モデル選択に応じて適切なLLMを呼び出す"""
model_mapping = {
"openai": "gpt-4",
"anthropic": "claude-3-opus-20240229",
"azure": "azure/gpt-4",
"google": "gemini/gemini-pro"
}
messages = [{"role": "user", "content": prompt}]
try:
response = completion(
model=model_mapping[model_choice],
messages=messages,
temperature=0.7
)
return response.choices[0].message.content
except Exception as e:
# フォールバック処理
print(f"Error with {model_choice}: {e}")
# 別のモデルで再試行
return completion(
model="gpt-3.5-turbo", # フォールバック用モデル
messages=messages
)プロキシサーバとしての展開
LLM Gatewayの構築
エンタープライズ環境では、プロキシサーバとしてLiteLLMを展開することが一般的です。これにより、組織全体でLLMアクセスを一元管理できます。
# プロキシサーバ機能を含めてインストール
pip install 'litellm[proxy]'
# プロキシサーバの起動
litellm --model gpt-3.5-turbo --port 4000設定ファイルによる高度な管理
本番環境では、config.yamlを使用して詳細な設定を行います。
model_list:
- model_name: gpt-4-primary
litellm_params:
model: azure/gpt-4
api_base: <https://primary.openai.azure.com>
api_key: "os.environ/AZURE_API_KEY_PRIMARY"
rpm: 60 # レート制限
- model_name: gpt-4-backup
litellm_params:
model: openai/gpt-4
api_key: "os.environ/OPENAI_API_KEY"
rpm: 30
router_settings:
routing_strategy: "usage-based" # 利用状況に基づくルーティング
fallback: true # 障害時の自動フォールバックこの設定により、プライマリのAzure OpenAIが利用できない場合、自動的にOpenAIの標準APIにフォールバックする仕組みが実現できます。
実践的な活用シナリオと運用戦略
コスト最適化とパフォーマンスのバランス
動的なモデル選択戦略
LiteLLMを活用した「コスト意識型のアーキテクチャ」を構築することで、品質とコストの最適なバランスを実現できます。
以下の表は、実際の運用で考慮すべきモデル選択の基準を示しています。
表 用途別のLLMモデル選択ガイド
用途 | 推奨モデル | コスト目安 | レスポンス速度 | 選択理由 |
|---|---|---|---|---|
簡易な質問応答 | GPT 5 | 低 | 高速 | コスト効率が高い |
高度な推論・分析 | GPT-5 / Claude | 高 | 中速 | 精度と信頼性を重視 |
リアルタイム処理 | Gemini Pro | 中 | 高速 | 低レイテンシが必要 |
専門知識が必要な回答 | Claude Opus | 高 | 低速 | 深い文脈理解が必要 |
大量バッチ処理 | Mixtral-8x7B (OSS) | 極低 | 可変 | 自社インフラで実行可能 |
この表に基づいて、リクエストの性質に応じて自動的にモデルを選択する仕組みを実装することで、コストを大幅に削減しながら品質を維持できます。
実装例:コンテキストベースのルーティング
def smart_model_selection(request_type, content_length, urgency):
"""リクエストの特性に基づいて最適なモデルを選択"""
if request_type == "simple_qa" and content_length < 500:
return "gpt-3.5-turbo"
elif urgency == "high" and content_length < 1000:
return "gemini/gemini-pro"
elif request_type == "analysis" or content_length > 2000:
return "claude-3-opus-20240229"
else:
return "gpt-4"エンタープライズグレードのセキュリティと管理
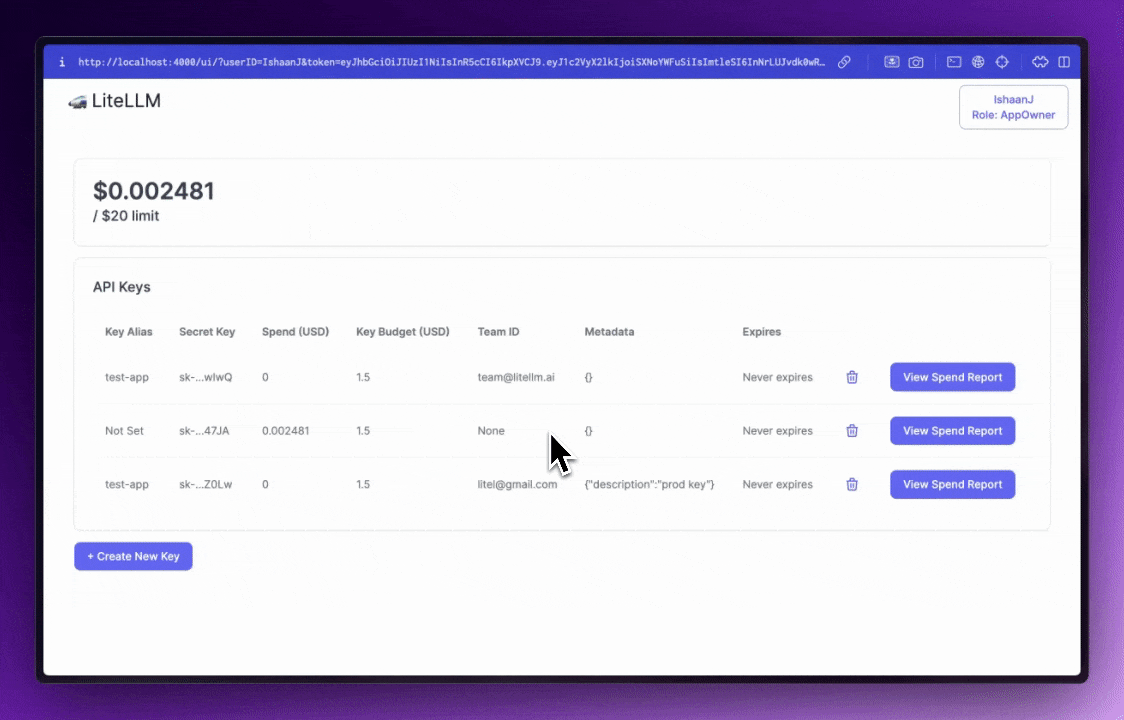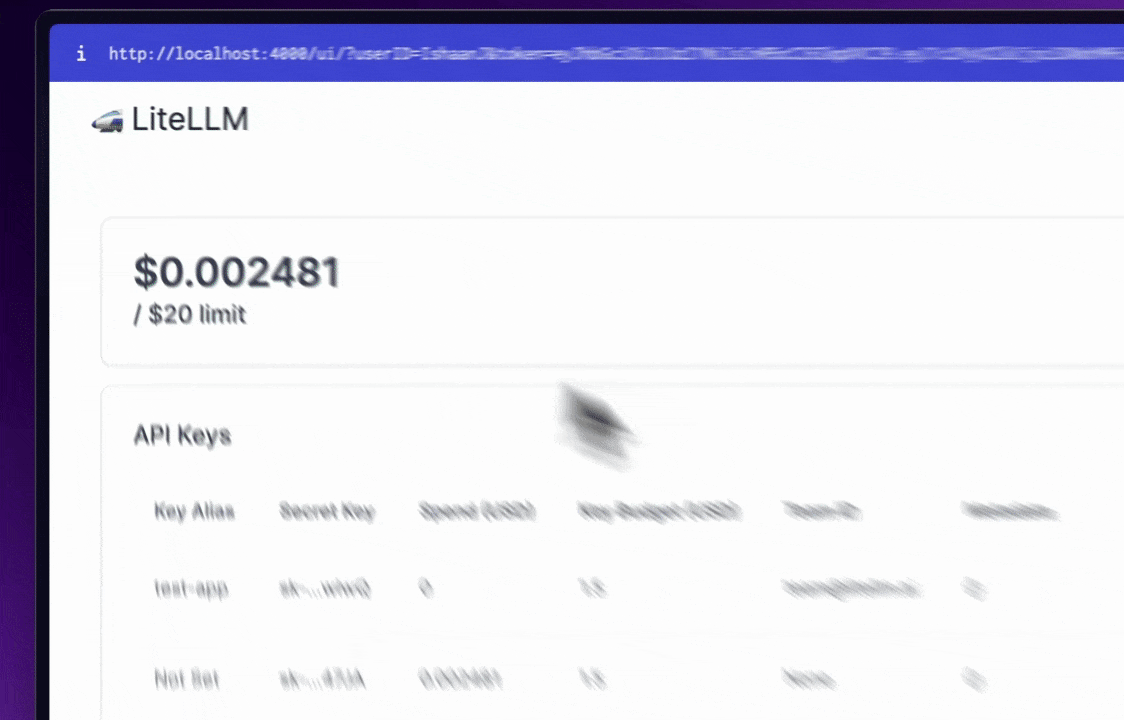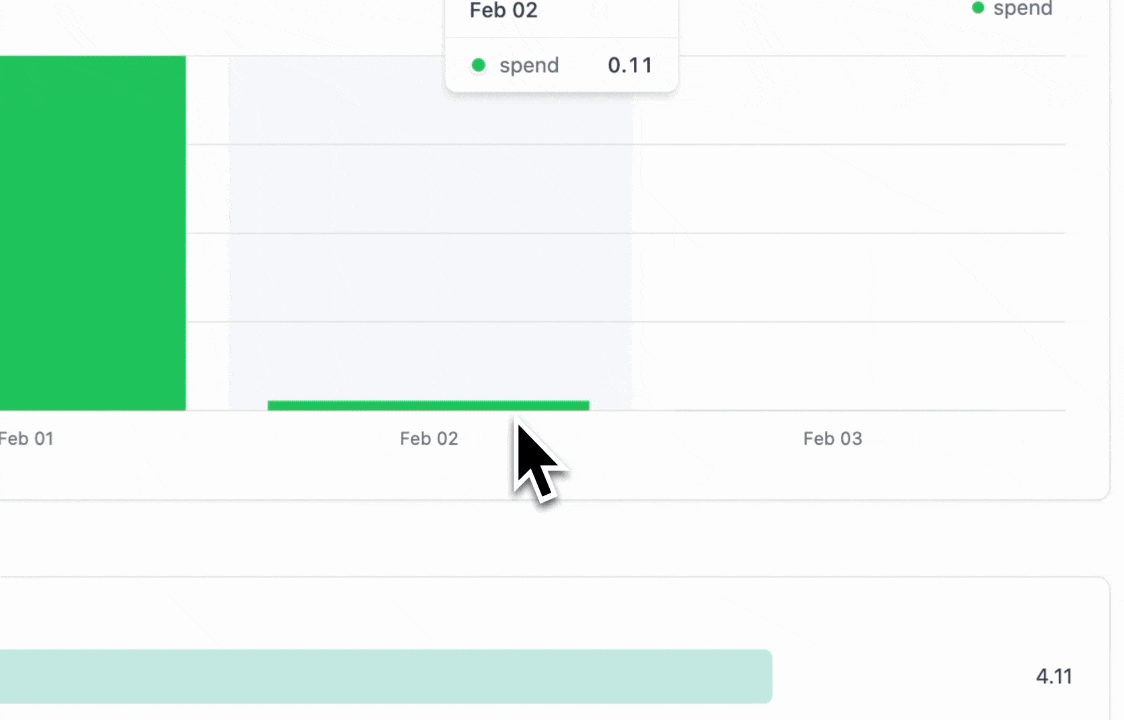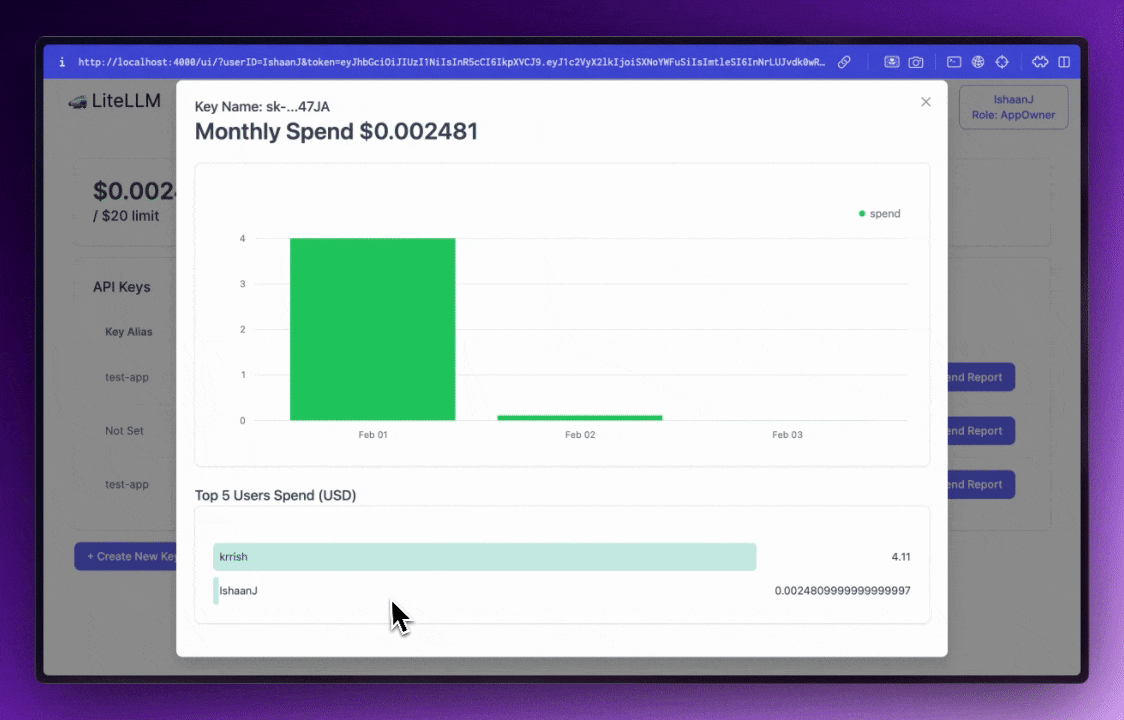
Virtual Keysによる権限管理
「Virtual Keys」機能を使用することで、チームや部門ごとに細かなアクセス制御を実装できます。
# Virtual Key作成の例
import requests
def create_team_key(team_name, budget, allowed_models):
"""チーム用の制限付きAPIキーを発行"""
response = requests.post(
"<http://litellm-proxy:4000/key/generate>",
headers={"Authorization": f"Bearer {MASTER_KEY}"},
json={
"team": team_name,
"max_budget": budget, # 月間予算上限
"models": allowed_models,
"duration": "30d", # 有効期限
"metadata": {
"department": "engineering",
"project": "ai-assistant"
}
}
)
return response.json()監査ログとコンプライアンス
エンタープライズ環境では、すべてのLLM利用を追跡し、監査可能にすることが重要です。LiteLLMは包括的なログ機能を提供しています。
引用:LiteLLM公式ドキュメント Enterprise版では、GDPR対応のためのログ無効化機能やチームごとのログ分離、JWT認証、IPアドレス制限などの高度なセキュリティ機能が利用可能です。
高可用性とスケーラビリティの確保
水平スケーリングによる負荷分散
公式ベンチマークによると、LiteLLMは単一インスタンスで毎秒約475リクエストを処理可能で、水平スケーリングにより線形にスループットが向上します。
# Docker Composeによる冗長構成の例
version: '3.8'
services:
litellm-1:
image: ghcr.io/berriai/litellm:stable
environment:
- DATABASE_URL=postgresql://...
- MASTER_KEY=${MASTER_KEY}
ports:
- "4001:4000"
litellm-2:
image: ghcr.io/berriai/litellm:stable
environment:
- DATABASE_URL=postgresql://...
- MASTER_KEY=${MASTER_KEY}
ports:
- "4002:4000"
nginx:
image: nginx
volumes:
- ./nginx.conf:/etc/nginx/nginx.conf
ports:
- "4000:80"
depends_on:
- litellm-1
- litellm-2導入における技術的考察と戦略的判断
アーキテクチャパターンの選択
集中型vs分散型の判断基準
LiteLLMの導入にあたっては、組織の規模と要件に応じて適切なアーキテクチャパターンを選択する必要があります。
集中型アーキテクチャ(単一のLiteLLMプロキシ)を選択すべきケースとしては、中小規模の組織で統一的な管理が重要な場合が挙げられます。一方、大規模組織では、部門ごとに独立したLiteLLMインスタンスを配置する分散型アーキテクチャが適している場合があります。
マイクロサービスとの統合パターン
既存のマイクロサービスアーキテクチャにLiteLLMを統合する際は、「サイドカーパターン」の採用を検討する価値があります。各マイクロサービスに小規模なLiteLLMインスタンスを併設することで、ネットワークレイテンシを最小化しながら、サービスごとのカスタマイズも可能になります。
パフォーマンスチューニングとモニタリング
メトリクス収集と分析
LiteLLMは「Prometheus」対応のメトリクスを提供しており、以下のような重要指標を監視できます。
運用上重要なメトリクスとして監視すべき項目は以下の通りです。
- リクエスト処理時間(P50、P95、P99)
- プロバイダ別のエラー率
- トークン消費量と推定コスト
- キャッシュヒット率
- フォールバック発生頻度
キャッシュ戦略の実装
同一または類似のリクエストに対してキャッシュを活用することで、コストとレイテンシを大幅に削減できます。
from litellm import completion
from litellm.caching import Cache
# Redisベースのキャッシュ設定
litellm.cache = Cache(
type="redis",
host="localhost",
port=6379,
ttl=3600 # 1時間のTTL
)
# セマンティック類似度ベースのキャッシュ
litellm.cache.similarity_threshold = 0.95リスク管理とフォールバック戦略
プロバイダ障害への対応
複数のLLMプロバイダを利用する環境では、障害時の対応戦略が重要になります。LiteLLMの「Router」機能を活用することで、高度なフォールバック戦略を実装できます。
from litellm import Router
router = Router(
model_list=[
{
"model_name": "primary",
"litellm_params": {
"model": "gpt-4",
"api_key": os.getenv("OPENAI_API_KEY")
}
},
{
"model_name": "secondary",
"litellm_params": {
"model": "claude-3-sonnet-20240229",
"api_key": os.getenv("ANTHROPIC_API_KEY")
}
}
],
fallbacks=[
{"primary": ["secondary"]}, # primaryが失敗したらsecondaryへ
],
allowed_fails=2, # 2回失敗したらフォールバック
timeout=30
)データプライバシーとコンプライアンス
機密データを扱う場合、「Guardrails」機能を使用してPII(個人識別情報)の自動マスキングを実装することが推奨されます。
from litellm import completion
# PIIマスキング設定
response = completion(
model="gpt-4",
messages=messages,
guardrails={
"pii_masking": True,
"prompt_injection_check": True,
"output_validation": {
"no_email": True,
"no_phone": True,
"no_ssn": True
}
}
)実装を成功に導くベストプラクティス
段階的な導入アプローチ
Phase 1: パイロットプロジェクトでの検証
まず小規模なプロジェクトでLiteLLMの価値を実証することから始めることを推奨します。具体的には、既存のOpenAI APIを使用しているアプリケーションに対して、LiteLLMプロキシを挟むだけの最小限の変更から着手します。
この段階で検証すべき項目として、以下の点が挙げられます。
- レスポンスタイムへの影響(通常3-5ms程度のオーバーヘッド)
- エラーハンドリングの適切性
- ログとモニタリングの有効性
- コスト削減効果の測定
Phase 2: 本番環境への段階的展開
パイロットプロジェクトで効果を確認した後、本番環境への展開を段階的に進めます。カナリアデプロイメントやブルーグリーンデプロイメントの手法を活用し、リスクを最小化しながら展開することが重要です。
Phase 3: 全社展開とガバナンス確立
最終的には、組織全体のLLM利用ガバナンスの中核としてLiteLLMを位置づけます。この段階では、以下のような組織的な取り組みが必要になります。
組織全体でのLiteLLM活用を成功させるために必要な要素は以下の通りです。
- 利用ポリシーとガイドラインの策定
- チーム横断的な知識共有の仕組み構築
- コスト配賦とチャージバックの仕組み確立
- セキュリティ監査プロセスの整備
トラブルシューティングと運用ノウハウ
よくある課題と解決策
実際の運用で遭遇しやすい課題とその解決策を以下にまとめました。
表 LiteLLM運用における典型的な課題と対処法
課題 | 症状 | 原因 | 解決策 |
|---|---|---|---|
レート制限エラー | 429 Too Many Requests | 単一プロバイダへの集中 | 複数プロバイダへの負荷分散設定 |
レスポンス遅延 | タイムアウト頻発 | ネットワーク経路の問題 | リージョン最適化とCDN活用 |
コスト超過 | 予算オーバー | モデル選択の不適切 | 用途別モデル選択ルールの見直し |
認証エラー | 401 Unauthorized | APIキーの期限切れ | キーローテーション自動化 |
出力品質のばらつき | 回答精度の低下 | プロバイダ間の差異 | プロンプトエンジニアリングの統一 |
これらの課題に対しては、LiteLLMの豊富な機能を活用することで、多くの場合自動的に対処できます。
運用監視のダッシュボード構築
「Grafana」と「Prometheus」を組み合わせることで、包括的な監視ダッシュボードを構築できます。
# Prometheus設定例
scrape_configs:
- job_name: 'litellm'
static_configs:
- targets: ['litellm-proxy:4000']
metrics_path: '/metrics'
scrape_interval: 15s将来を見据えた拡張性の確保
カスタムプロバイダの統合
社内で独自に開発したLLMや、まだLiteLLMが公式サポートしていないプロバイダも、カスタムプロバイダとして統合可能です。
# カスタムプロバイダの実装例
from litellm.llms.custom_llm import CustomLLM
class MyCompanyLLM(CustomLLM):
def completion(self, messages, **kwargs):
# 独自のAPI呼び出しロジック
response = self.call_internal_api(messages)
# OpenAI形式に変換
return self.format_response(response)
# プロバイダの登録
litellm.register_model(
model_name="mycompany/internal-llm",
custom_llm_provider=MyCompanyLLM
)次世代技術への対応準備
生成AI分野は急速に進化しており、新しいモデルやプロバイダが続々と登場しています。LiteLLMのオープンソース性と活発なコミュニティにより、これらの新技術への対応も迅速に行われています。
GitHubのリリース履歴を見ると、月に複数回のアップデートが行われており、最新のモデルへの対応が継続的に追加されていることが分かります。
まとめ
投資対効果の実証
LiteLLMの導入による投資対効果は、複数の観点から評価できます。
まず開発効率の向上という観点では、Netflix社の事例にあるように、新モデル対応にかかる時間を大幅に削減できます。仮に1モデルあたり8時間の実装工数が必要だったものが、LiteLLMによりほぼゼロになるとすれば、10個の新モデルで80時間、つまり2週間分の開発工数が削減できることになります。
次にコスト最適化の観点では、動的なモデル選択により、高価なGPT-4の利用を本当に必要な場面に限定し、その他のケースではより安価なモデルを使用することで、AIコストを30-50%削減することも可能です。
組織のAI活用成熟度を高める基盤として
LiteLLMは単なる技術的なツールではなく、組織のAI活用成熟度を高めるための戦略的な基盤となります。統一的なインターフェースにより、エンジニアはプロバイダの違いを意識せずに最適なモデルを選択でき、イノベーションのスピードが加速します。
また、ガバナンスとコンプライアンスの観点でも、すべてのLLM利用を一元的に管理・監視できることで、組織としての統制を保ちながら、各チームの自由度も確保できます。
今後の展望と推奨アクション
新しいモデル、新しいプロバイダ、新しい利用形態が次々と登場する中で、「変化に強いアーキテクチャ」を構築することが重要です。
LiteLLMはまさにそのような変化に強いアーキテクチャの中核となるツールです。MITライセンスのオープンソースであることから、ベンダーロックインのリスクもなく、必要に応じてカスタマイズも可能です。
私の経験から言えることは、マルチLLM時代において、プロバイダの抽象化レイヤを持つことは必須だということです。その選択肢として、実績があり、活発なコミュニティを持ち、エンタープライズグレードの機能を備えたLiteLLMは、現時点で最も有力な選択肢の一つだと考えています。
まずは小規模なパイロットプロジェクトから始め、段階的に活用範囲を広げていくアプローチを推奨します。その過程で得られる知見は、組織全体のAI活用戦略にとって貴重な資産となるはずです。
























