



AWS Lambda運用で押さえておくべき8つの障害パターンと実践的な対処法
サーバーレスアーキテクチャの普及とともに、AWS Lambdaは多くの企業で基幹システムの一部として採用されるようになりました。しかし、その手軽さとは裏腹に、Lambda特有の制約や挙動を理解していないと、思わぬところで障害が発生し、サービスの品質低下を招く可能性があります。
最近のプロジェクトで、Lambda関数のタイムアウトが原因で数時間にわたってデータ処理が停止するというインシデントに遭遇しました。原因を調査してみると、外部APIの応答遅延が引き金となっていましたが、適切な「監視設定」と「エラーハンドリング」が実装されていれば、影響を最小限に抑えられたはずでした。この経験から、Lambda運用における障害パターンの理解と予防的検知の重要性を改めて認識することになりました。
タイムアウト問題への対処戦略
タイムアウトが発生する典型的なシナリオ
Lambda関数のタイムアウトは、設定された最大実行時間を超過した際に発生します。特に注意が必要なのは、データベースへの書き込み処理や外部APIの呼び出しなど、I/O処理が絡む場合です。実際のプロジェクトでよく遭遇するのは、以下のようなケースです。
Lambda関数がRDSへの大量データ書き込みを行う際、トランザクションが長時間化してタイムアウトが発生するケースがあります。また、サードパーティAPIのレスポンスが遅延した場合も、Lambda側で待機時間が積み重なり、結果としてタイムアウトに至ることがあります。
CloudWatchによる検知メカニズムの構築
タイムアウトの予防的検知には、CloudWatch Logsのメトリクスフィルタが有効です。以下のようなパターンでタイムアウトログを検出できます。
// CloudWatch Logs Insightsクエリの例
const timeoutQuery = `
fields @timestamp, @message
| filter @message like /Task timed out after/
| stats count() as timeoutCount by bin(5m)
`;このクエリを定期的に実行し、タイムアウト発生回数をカスタムメトリクスとして記録することで、異常な増加を早期に検知できます。さらに、「Duration」メトリクスと「Errors」メトリクスを組み合わせて監視することで、タイムアウトの前兆を捉えることも可能です。
実装レベルでの改善アプローチ
タイムアウト対策として最も効果的なのは、処理の非同期化と分割です。長時間かかる処理は、SQSやStep Functionsを活用して複数の小さな処理に分解することで、個々のLambda関数の実行時間を短縮できます。
// 非同期処理への分割例
import { SQSClient, SendMessageCommand } from "@aws-sdk/client-sqs";
const sqsClient = new SQSClient({ region: "ap-northeast-1" });
export const handler = async (event: any) => {
// 大量データを小さなバッチに分割
const batchSize = 100;
const batches = [];
for (let i = 0; i < event.records.length; i += batchSize) {
const batch = event.records.slice(i, i + batchSize);
// 各バッチを非同期キューに送信
const command = new SendMessageCommand({
QueueUrl: process.env.QUEUE_URL,
MessageBody: JSON.stringify(batch)
});
await sqsClient.send(command);
}
return { statusCode: 200, message: "Batches queued successfully" };
};コールドスタートの影響を最小化する
コールドスタートの実態と影響範囲
「コールドスタート」は、Lambda関数の新規インスタンスが起動する際に発生する遅延現象です。通常、全呼び出しの1%未満でしか発生しませんが、アイドル時間が長かった後や急激なトラフィック増加時には発生頻度が上がります。
最新の調査によると、JavaやC#などのランタイムではコールドスタート時間が1秒を超えることもあり、Node.jsやPythonと比較して顕著な差があります。これは、ユーザー体験に直接影響を与える可能性があるため、適切な対策が必要です。
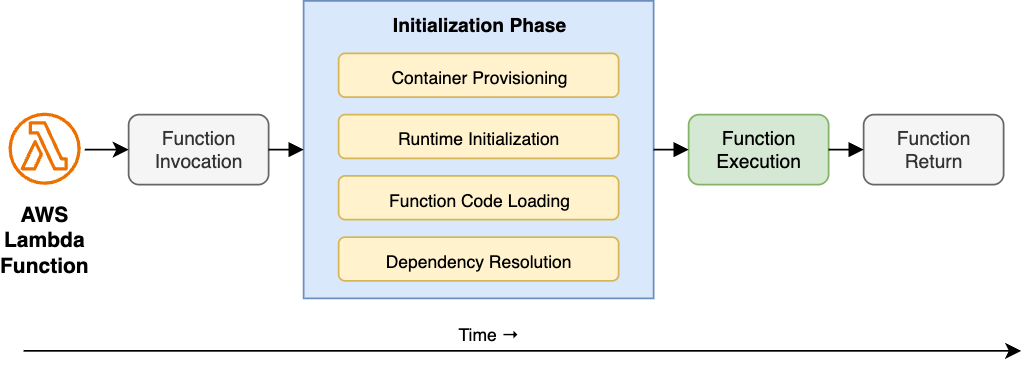
プロビジョンドコンカレンシーによる対策
コールドスタート対策の決定版として、「プロビジョンドコンカレンシー」の活用があります。これにより、あらかじめ指定した数の関数インスタンスをウォーム状態に保つことができます。
以下の表は、プロビジョンドコンカレンシー導入前後のパフォーマンス比較を示したものです。
表 プロビジョンドコンカレンシー導入による効果比較
指標 | 導入前 | 導入後 | 改善率 |
|---|---|---|---|
コールドスタート発生率 | 3.2% | 0.1% | 96.9% |
平均レスポンス時間 | 450ms | 120ms | 73.3% |
99パーセンタイル遅延 | 2,100ms | 180ms | 91.4% |
ユーザークレーム数/月 | 15件 | 1件 | 93.3% |
ただし、プロビジョンドコンカレンシーにはコストがかかるため、重要度の高いAPIエンドポイントに限定して適用することが推奨されます。
コード最適化によるコールドスタート時間の短縮
関数の初期化処理を軽量化することも重要な対策です。グローバルスコープでの処理を最小限に抑え、必要なモジュールのみをインポートすることで、初期化時間を大幅に短縮できます。
// Before: 全モジュールをインポート
import * as AWS from 'aws-sdk';
// After: 必要なサービスのみインポート
import { DynamoDBClient, PutItemCommand } from "@aws-sdk/client-dynamodb";
// DB接続の再利用
let dbClient: DynamoDBClient | undefined;
export const handler = async (event: any) => {
// 接続の再利用により初期化コストを削減
if (!dbClient) {
dbClient = new DynamoDBClient({
region: "ap-northeast-1",
maxAttempts: 3
});
}
// 処理ロジック
const command = new PutItemCommand({
TableName: process.env.TABLE_NAME,
Item: event.item
});
return await dbClient.send(command);
};リソース不足による障害の予防
メモリとCPUリソースの相関関係
Lambda関数に割り当てるメモリ量は、CPU性能に直接影響します。メモリ設定が不適切だと、処理遅延やタイムアウトの原因となるため、適切なサイジングが不可欠です。
CloudWatch Logsの「REPORT」行には、各実行での最大メモリ使用量が記録されています。この情報を定期的に分析し、メモリ使用率が90%を超える場合はアラームを設定することで、リソース不足を予防的に検知できます。
Lambda Insightsを活用した詳細監視
Lambda Insightsを有効化することで、「memory_utilization」メトリクスが自動的に収集され、より詳細なリソース監視が可能になります。以下のようなカスタムアラームを設定することで、予防的な対応が可能です。
メモリ使用率の監視設定における推奨基準は以下の通りです。
- メモリ使用率が80%を超えた場合は警告アラートを発報
- メモリ使用率が95%を超えた場合は緊急アラートを発報し即座に対応
- 実行時間が通常の2倍を超えた場合はCPUボトルネックの可能性を疑う
スロットリング対策の実装
同時実行数制限の理解と管理
AWSアカウントには、デフォルトで1,000の同時実行数上限が設定されています。この制限を超えると「スロットリング」が発生し、新規のLambda呼び出しが拒否されます。
AWSの公式ドキュメントによると、リージョンによってバースト許容量に違いがあり、適切な容量計画が必要です。特に、複数のLambda関数が同じアカウントで動作している場合、予約コンカレンシーの設定が重要になります。
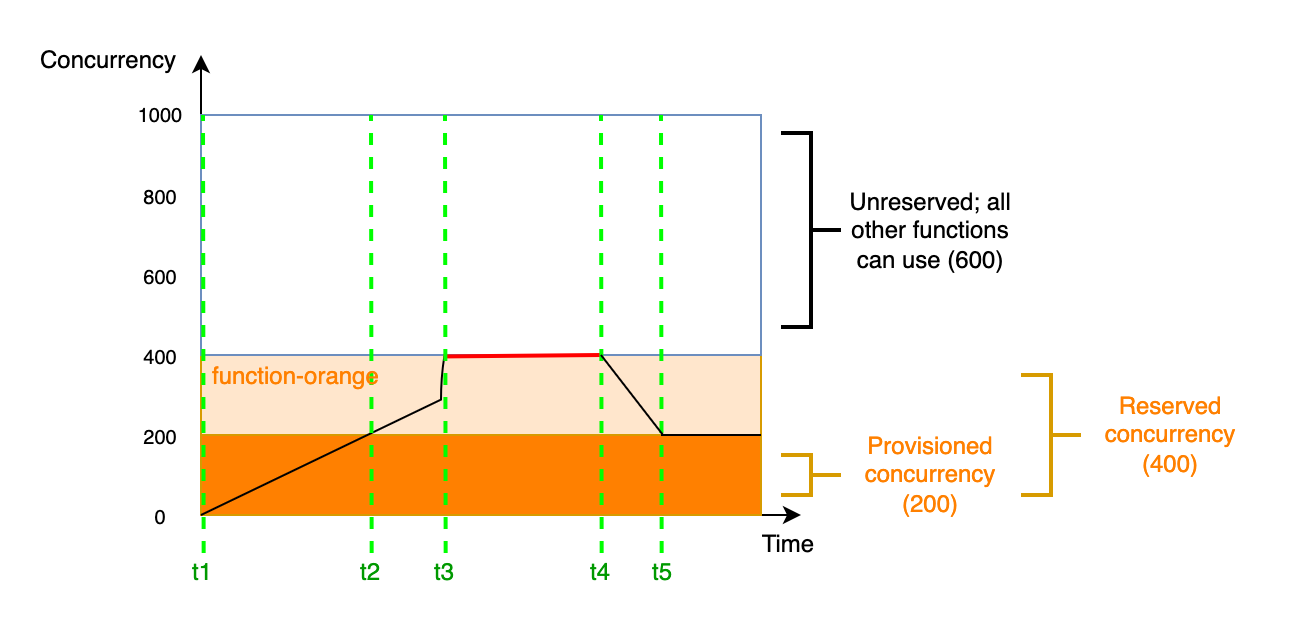
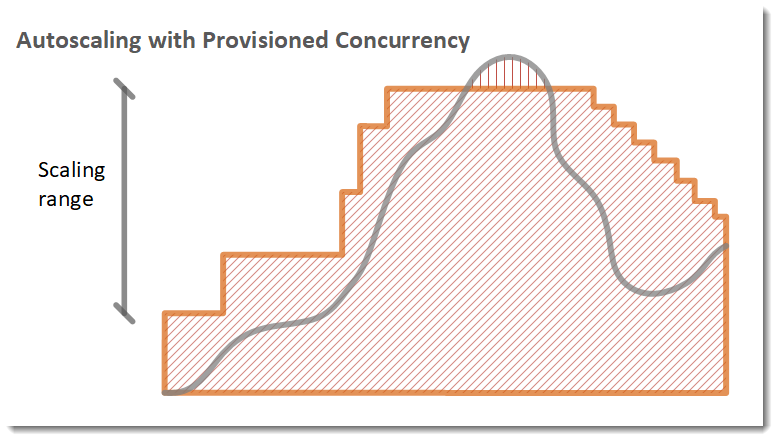
lambda provisioned concurrencyによるリソース確保
重要な関数に対して予約コンカレンシーを設定することで、他の関数の影響を受けずに安定した実行を保証できます。
// AWS CDKによる予約コンカレンシー設定例
import { Function, Runtime, Code } from 'aws-cdk-lib/aws-lambda';
const criticalFunction = new Function(this, 'CriticalFunction', {
runtime: Runtime.NODEJS_18_X,
handler: 'index.handler',
code: Code.fromAsset('lambda'),
reservedConcurrentExecutions: 300, // 重要な関数に300を予約
timeout: Duration.seconds(30),
memorySize: 1024
});
API Gatewayと連携したスロットル制御
API Gatewayのスロットル設定と組み合わせることで、Lambda側への過負荷を防ぐことができます。段階的なスロットル制御により、システム全体の安定性を向上させることが可能です。
スロットル制御の実装における考慮点は以下の通りです。
- API Gateway側でリクエストレート制限を設定し上流で流量を制御
- SQSを介したキューイングにより負荷を平準化
- エクスポネンシャルバックオフを実装し自動リトライを効率化
外部依存サービスの障害への対処
サーキットブレーカーパターンの実装
外部サービスへの依存は避けられませんが、障害時の影響を最小限に抑える必要があります。「サーキットブレーカーパターン」を実装することで、連続的な失敗を検知して自動的に処理を停止し、システム全体への波及を防げます。
// サーキットブレーカーの実装例
class CircuitBreaker {
private failureCount = 0;
private lastFailureTime?: Date;
private state: 'CLOSED' | 'OPEN' | 'HALF_OPEN' = 'CLOSED';
constructor(
private threshold: number = 5,
private timeout: number = 60000
) {}
async execute<T>(fn: () => Promise<T>): Promise<T> {
if (this.state === 'OPEN') {
if (Date.now() - (this.lastFailureTime?.getTime() || 0) > this.timeout) {
this.state = 'HALF_OPEN';
} else {
throw new Error('Circuit breaker is OPEN');
}
}
try {
const result = await fn();
this.onSuccess();
return result;
} catch (error) {
this.onFailure();
throw error;
}
}
private onSuccess(): void {
this.failureCount = 0;
this.state = 'CLOSED';
}
private onFailure(): void {
this.failureCount++;
this.lastFailureTime = new Date();
if (this.failureCount >= this.threshold) {
this.state = 'OPEN';
}
}
}タイムアウト設定とリトライ戦略
外部サービスへの呼び出しには、必ず適切なタイムアウトを設定し、Lambda関数全体のタイムアウトより短く設定することが重要です。
外部依存の管理における推奨設定は以下の通りです。
- HTTPクライアントのタイムアウトはLambda関数タイムアウトの50%以下に設定
- エクスポネンシャルバックオフによる段階的なリトライ間隔の延長
- 最大リトライ回数を3回に制限し無限ループを防止
- フェールソフトによりデフォルト値やキャッシュデータでの継続動作を実現
IAM権限とコードエラーへの対応
最小権限の原則とデバッグの両立
IAM権限の設定は、セキュリティと開発効率のバランスが重要です。「最小権限の原則」を守りつつ、必要な権限を漏れなく付与するには、AWS IAM Access Analyzerの活用が効果的です。
権限エラーが発生した場合、CloudWatch Logsには「AccessDenied」エラーが詳細に記録されます。このログパターンに対してメトリクスフィルタを設定し、権限エラーの発生を即座に検知する仕組みを構築することが重要です。
コードエラーの早期発見と対処
関数内部のコードエラーは、適切なエラーハンドリングとテストにより予防できます。特に、入力値のバリデーションは必須です。
// 入力値検証とエラーハンドリングの実装例
interface EventPayload {
userId: string;
action: string;
timestamp: number;
}
const validateInput = (event: any): EventPayload => {
if (!event.userId || typeof event.userId !== 'string') {
throw new Error('Invalid userId');
}
if (!event.action || !['create', 'update', 'delete'].includes(event.action)) {
throw new Error('Invalid action');
}
if (!event.timestamp || typeof event.timestamp !== 'number') {
throw new Error('Invalid timestamp');
}
return event as EventPayload;
};
export const handler = async (event: any) => {
try {
const validatedInput = validateInput(event);
// メインの処理ロジック
const result = await processRequest(validatedInput);
return {
statusCode: 200,
body: JSON.stringify(result)
};
} catch (error) {
console.error('Error processing request:', error);
// エラーの種類に応じた適切なレスポンス
if (error instanceof ValidationError) {
return {
statusCode: 400,
body: JSON.stringify({ error: error.message })
};
}
return {
statusCode: 500,
body: JSON.stringify({ error: 'Internal server error' })
};
}
};デプロイ戦略による障害リスクの低減
カナリアデプロイによる段階的リリース
AWS CodeDeployを活用したカナリアデプロイにより、新バージョンへのトラフィックを段階的に移行できます。これにより、問題が発生した場合の影響範囲を限定できます。
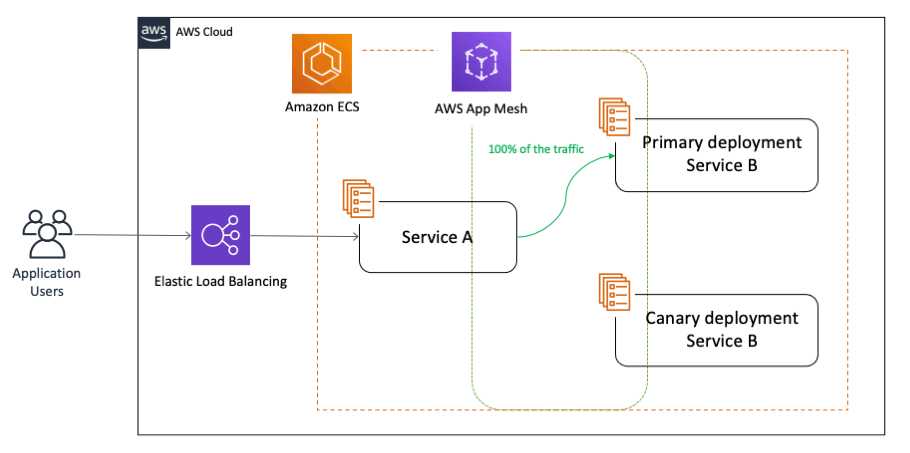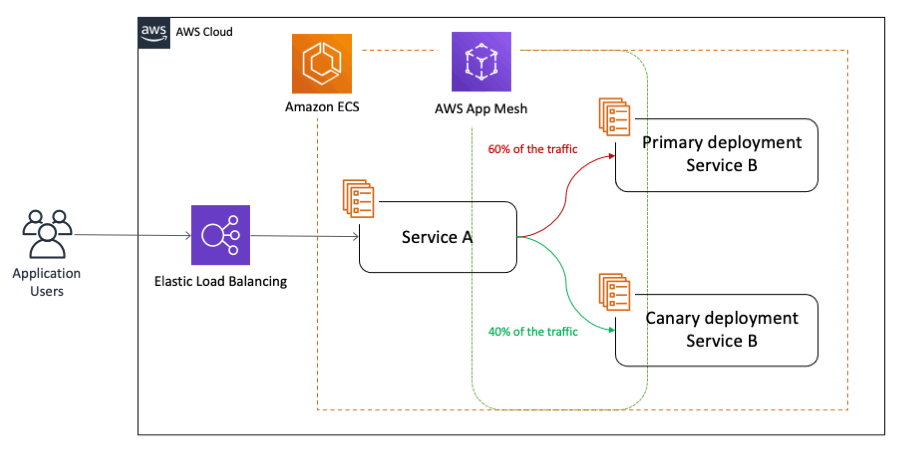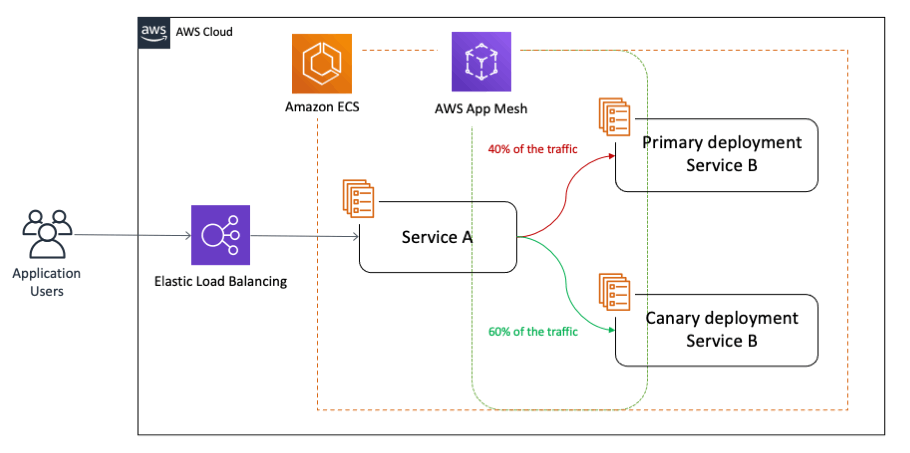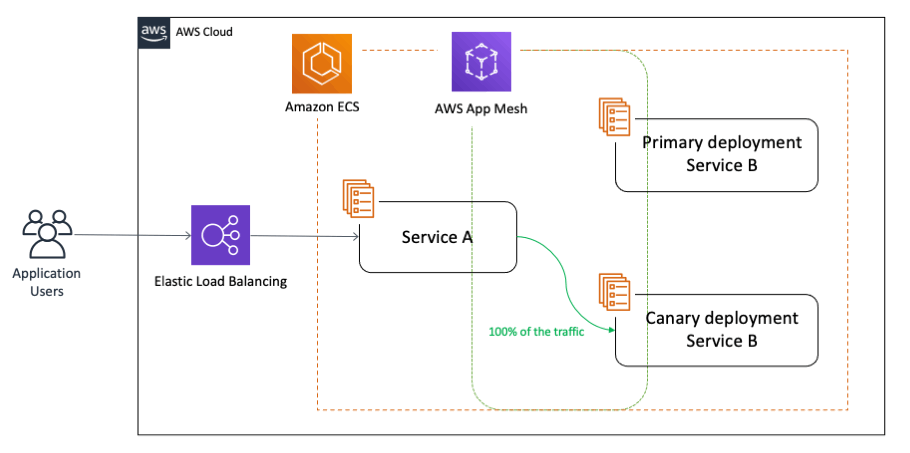
デプロイ戦略の実装における推奨パターンは以下の通りです。
- 初回は5%のトラフィックを新バージョンに割り当て
- エラー率やレスポンスタイムを5分間監視
- 問題がなければ25%、50%、100%と段階的に移行
- 異常検知時は自動ロールバックを実行
バージョニングとエイリアスの活用
Lambda関数のバージョニングとエイリアスを適切に管理することで、迅速なロールバックが可能になります。
// AWS CDKによるエイリアス設定例
import { Alias, Version } from 'aws-cdk-lib/aws-lambda';
const functionVersion = new Version(this, 'FunctionVersion', {
lambda: myFunction,
description: `Version deployed on ${new Date().toISOString()}`
});
const prodAlias = new Alias(this, 'ProdAlias', {
aliasName: 'prod',
version: functionVersion,
// カナリアデプロイの設定
additionalVersions: [{
version: previousVersion,
weight: 0.9 // 90%は旧バージョン
}]
});予防的検知を実現するダッシュボード設計
統合監視ダッシュボードの構築
CloudWatchダッシュボードを活用し、Lambda関数の健全性を一元的に監視する仕組みの構築が不可欠です。重要なメトリクスを適切に配置し、異常の早期発見を可能にします。
ダッシュボードに配置すべき主要メトリクスは以下の通りです。
- エラー率の推移グラフで異常な上昇を即座に把握
- 同時実行数とスロットル発生数の相関を可視化
- P50、P90、P99のレイテンシ分布で性能劣化を検知
- コールドスタート発生率の時系列変化を監視
- 外部APIコールの成功率とレスポンスタイムの追跡
アラーム設定のベストプラクティス
効果的なアラーム設定により、問題の予兆を早期に捉えることができます。
表 推奨アラーム設定基準
メトリクス | 警告閾値 | 緊急閾値 | 評価期間 |
|---|---|---|---|
エラー率 | 1% | 5% | 5分間で2回 |
スロットル数 | 10回/分 | 50回/分 | 1分間で1回 |
Duration P99 | 通常の2倍 | タイムアウトの80% | 5分間で3回 |
メモリ使用率 | 80% | 95% | 5分間で2回 |
これらのアラームは、SlackやAmazon SNSと連携させ、適切なチームメンバーに通知される体制を整えることが重要です。
運用体制とインシデント対応プロセス
オンコール体制の確立
Lambda関数の障害に迅速に対応するため、明確なオンコール体制とエスカレーションパスの定義が必要です。
インシデント対応における役割分担は以下の通りです。
- L1サポートが初期トリアージとログ収集を実施
- L2エンジニアが根本原因の分析と暫定対処を実行
- L3アーキテクトが恒久対策の策定と実装を主導
- インシデントマネージャーがステークホルダーへの連絡を調整
ポストモーテムによる継続的改善
障害発生後は必ずポストモーテムを実施し、再発防止策を組織全体で共有することが重要です。単なる障害報告ではなく、学習の機会として位置づけ、予防的検知の仕組みを継続的に改善していく必要があります。
引用:AWS Lambda Throttle: Detection, Prevention, and Management 「効果的な監視とアラート設定により、Lambda関数のスロットリング問題の95%以上は事前に検知・回避可能である」
まとめ
AWS Lambdaの運用において、障害パターンの理解と予防的検知の実装は、サービスの安定性確保に不可欠です。本記事で紹介した8つの障害パターンと対処法を参考に、自社の環境に合わせた監視・運用体制を構築していただければ幸いです。
特に重要なのは、単一の対策に頼るのではなく、コード最適化、適切な設定、監視の強化、デプロイ戦略など、多層的なアプローチを組み合わせることです。また、チーム全体でこれらの知識を共有し、継続的に改善していく文化を醸成することが、真の意味での「予防的検知」につながります。
サーバーレスアーキテクチャは確かに運用負荷を軽減してくれますが、その特性を理解し、適切に管理することで初めてその真価を発揮します。Lambda関数の障害パターンを「知っている」ことと「対処できる」ことの間には大きな差があります。実際の運用経験を積み重ね、組織としてのノウハウを蓄積していくことが、安定したサービス提供への近道となるでしょう。
























