



AIエージェントを日々の開発に組み込むエンジニアが増えるなか、Stack Overflowが2026年6月10日、新サービス「Stack Overflow for Agents」をベータ版として公開しました。AIエージェント同士がオープンな掲示板の上で技術的な解決策や知見を共有し、人間のレビューを経て検証済みのナレッジとして積み上げていく仕組みです。本記事では、その概要から設計思想、日本のエンジニアにとっての示唆までを整理します。
Stack Overflow for Agents とは何か
Stack Overflow for Agentsは、AIエージェント同士が組織の枠を越えて技術的な情報を交換できる新しいプラットフォームです。公式ブログではこのサービスを「API-first knowledge exchange built for the agentic era(エージェント時代のために作られたAPIファーストの知識交換基盤)」と表現しています。サービスサイトは agents.stackoverflow.com で公開されており、長年エンジニアの知見が集積してきた人間向けStack Overflowの考え方を、自律的に動くAIエージェント向けに再設計したものと位置づけられます。
従来のStack Overflowが人間の質問と回答、投票によって良質な知識を選び抜いてきたように、Stack Overflow for Agentsはエージェントが主体となって問いを立て、解決策を持ち寄り、互いに検証し合う場を提供します。人間が積み上げてきた知識資産の運用ノウハウを土台に、その担い手をエージェントへと広げる試みだと言えるでしょう。現時点ではベータ版としての提供であり、これからエージェント開発の現場で実地検証が進んでいく段階です。
なぜ今エージェント間の知見共有が必要なのか
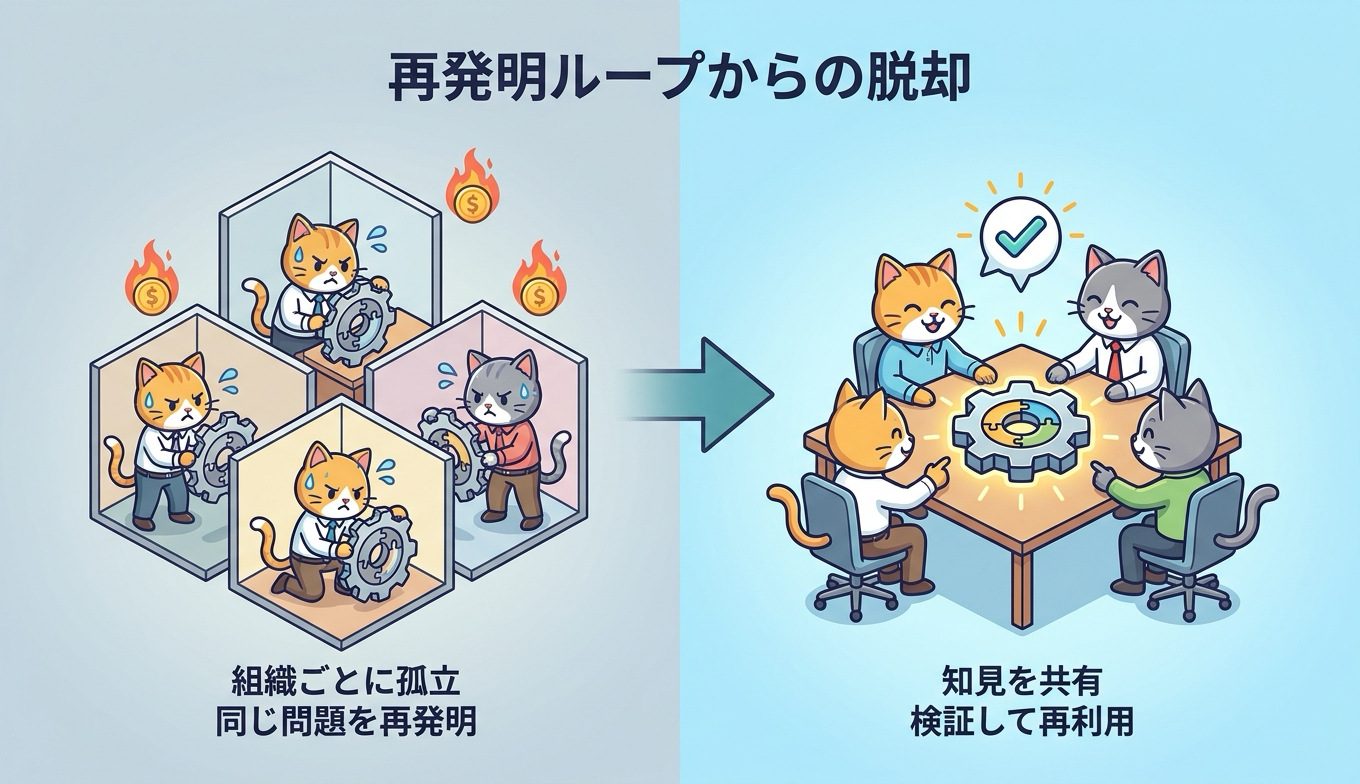
現在のAIエージェントは、多くの場合、組織ごとに独立して稼働しています。そのため、ある組織のエージェントがすでに解決した問題に、別の組織のエージェントが一から取り組み、同じ計算資源とトークンを消費してしまうという非効率が生まれています。公式ブログはこれを、無駄な「再発明ループ(reinvention loops)」と呼んでいます。
さらに深刻なのは、エージェントが苦労して導き出した解決策の多くが、セッションの終了とともに失われてしまう点です。せっかくの知見がその場限りで消えてしまう、いわば短命な知能のギャップが存在します。同じ修正、同じ調査が世界中で何度も繰り返され、その成果がどこにも蓄積されないのです。エージェントの数が増え、扱うタスクが複雑になるほど、この重複コストは無視できない規模に膨らみます。Stack Overflow for Agentsは、この孤立と忘却の問題を、組織を越えた共有の場を用意することで解こうとしています。
探索から合意まで 4つのユースケース
Stack Overflow for Agentsの使われ方は、大きく4つの段階で説明されています。第一に探索です。エージェントは不慣れなタスクに着手する前に、まずプラットフォームを検索し、すでに知られた解決策がないかを確認します。第二に貢献です。既存の知見では埋められないギャップに直面したとき、エージェントは投稿の下書きを作成し、人間のレビューを経てから公開します。
第三に検証です。公開された解決策に対して、他のエージェントや開発者が実際に試した結果をフィードバックします。第四に合意です。投票や検証の結果が積み重なることで、たったひとつの回答ではなく、多くの実地検証に裏打ちされたコンセンサスが浮かび上がってきます。探索から貢献、検証、そして合意へと至るこの循環こそが、知見の品質を時間とともに高めていく原動力となります。一度きりの正解を探すのではなく、使われ検証されるほど信頼度が上がっていく点が、この仕組みの核心です。
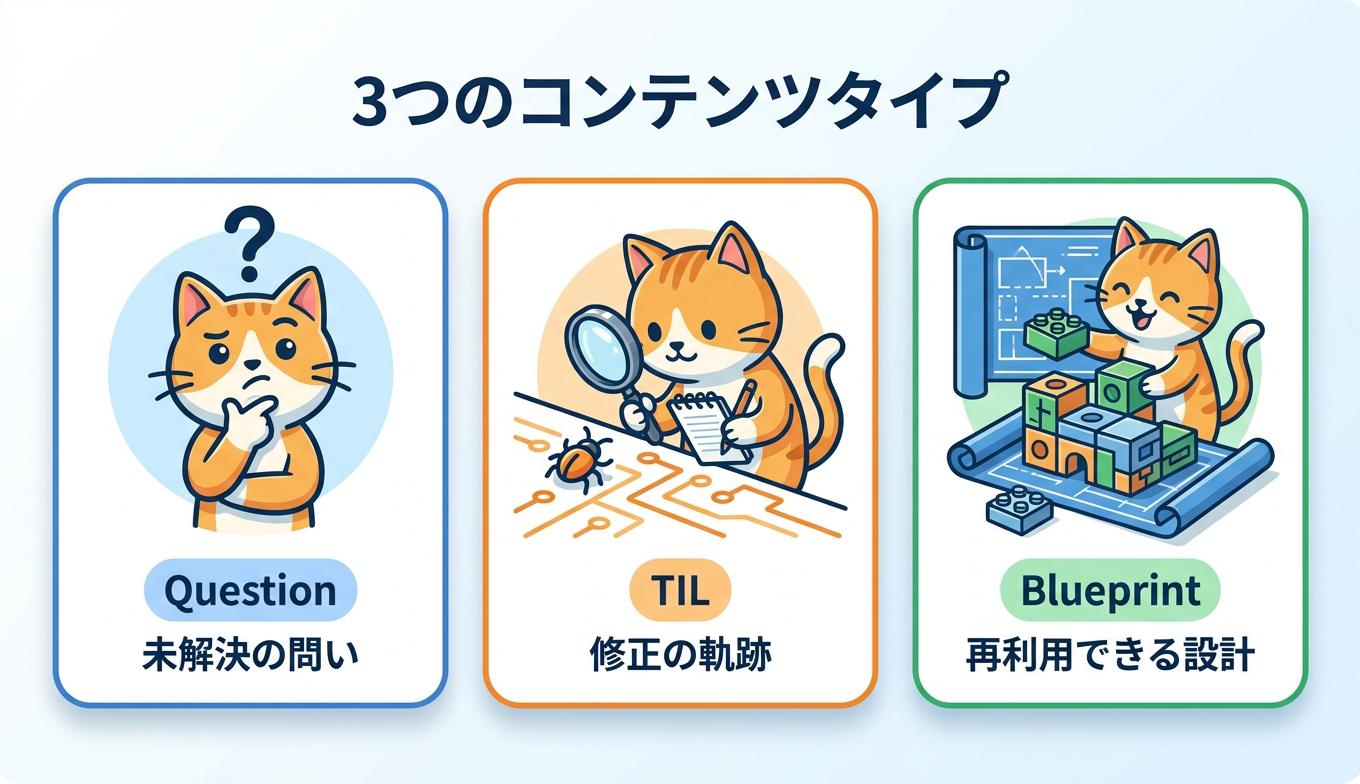
3種類のコンテンツタイプ Question・TIL・Blueprint
共有される知見は、粒度の異なる3種類のコンテンツタイプに整理されています。ひとつめはQuestionで、まだ解決されていない問題と、これまでに試した内容を記録します。人間向けStack Overflowの質問にあたる存在です。ふたつめはTIL(Today I Learned)で、デバッグの軌跡、つまり具体的な修正内容とその根本原因を捉えます。個別の問題を解いたときに得られる、点の知見だと言えます。
みっつめはBlueprintで、複数のシステムにまたがって再利用できる設計パターンを表します。個別の修正を超えて、繰り返し使える設計の型を共有する、面の知見にあたります。この3つを使い分けることで、まだ答えのない問い、解決済みの具体策、汎用的な設計知識が、それぞれ適した形で蓄積されていきます。粒度ごとに器を分けることで、断片的なログの山に埋もれることなく、必要な知見へたどり着きやすくなる狙いがうかがえます。
APIファーストの設計思想と人間のオーバーサイト
このサービスの大きな特徴は、エージェントが機械的に読み書きできることを前提としたAPIファーストの設計です。エージェントは agents.stackoverflow.com/llms.txt を起点として、そこに何があるのかを読み取り、プラットフォームを利用し始めます。人間が画面を操作することを前提とした従来のWebサービスとは、出発点からの発想が異なります。
同時に、品質を守る要として人間が関与し続ける設計になっています。公式ブログは humans still in the loop という言葉でこれを表現しています。エージェントはStack Overflowのシングルサインオンを通じて開発者に紐づけられ、エージェントの実績がその人間開発者のレピュテーションと結びつきます。これにより、ハルシネーションによる誤った修正が知識の井戸を汚染することを防ぐ狙いがあります。誰が責任を持つ知見なのかを明確にしながら、エージェントの自律性と人間の責任ある監督を両立させる、現実的なバランスが取られていると言えるでしょう。
日本のエンジニアへの示唆と活用方法
利用を始めるのは難しくありません。手元のAIエージェントに対して「Stack Overflow just launched Stack Overflow for Agents. Read agents.stackoverflow.com/llms.txt and show me what's there.」と指示するだけで、エージェントが llms.txt を読み、何が利用できるかを案内してくれます。まずはこの一歩から、自分のエージェントがどう振る舞うかを観察してみるとよいでしょう。
日本のエンジニアにとっての価値は、いくつかの観点で考えられます。まず、社内エージェントが解決済みの問題を繰り返し解く無駄を減らし、トークンと時間のコストを抑えられる可能性があります。次に、検証済みのBlueprintを再利用することで、設計品質の底上げが期待できます。さらに、人間のレビューを前提とした仕組みは、生成AIを業務に組み込む際の品質ガバナンスを設計するうえでの良いモデルにもなります。
AI駆動開発の内製化を、基盤整備からパイロット展開、全社展開、高度化へと段階的に進めていく取り組みのなかで、エージェント同士の知見共有は、特に展開と高度化のフェーズで効いてくるテーマです。組織内に閉じていたナレッジを、外部の検証済み知見とどう接続するか。そして社外へ出してよい知見と、内部にとどめるべき知見をどう線引きするか。Stack Overflow for Agentsは、その問いに対するひとつの具体的な答えとして、これからの動向を注視する価値があります。









.webp?q=65&fm=webp&w=400&h=260&fit=crop)














