



AWS AppSyncパイプラインリゾルバーの進化と実践的活用法
パイプラインリゾルバーの基本概念とその価値
AppSyncのパイプラインリゾルバーは、複数のオペレーションを順次実行できる強力な機能です。単一のGraphQLクエリに対して複数のデータソースへのアクセスや、複雑なビジネスロジックの実装を可能にします。
従来のVTLベースの実装から「JavaScriptランタイム(APPSYNC_JS)」への移行が進んでおり、AWS公式ドキュメントもJavaScriptランタイムを主要なドキュメントとして扱うようになりました。これは単なる記法の変更ではなく、開発生産性と保守性を大きく向上させる転換点といえます。
パイプラインリゾルバーの構造は、Before処理、複数の関数(Functions)、After処理という流れは維持されていますが、JavaScriptによる実装により、より直感的なコーディングが可能になりました。最大10個の関数を直列に実行できる制限は現在も継続していますが、これは適切な設計を促す制約として機能していると考えています。
VTLからJavaScriptへの移行がもたらす本質的な価値
VTL(Velocity Template Language)は強力でしたが、学習コストが高く、デバッグが困難という課題がありました。JavaScriptランタイムの導入により、フロントエンドエンジニアも含めた幅広い開発者がバックエンドロジックに関与できるようになりました。
これは単に「書きやすくなった」という表面的な改善ではありません。チーム全体でコードレビューが可能になり、知識の属人化を防ぎ、品質向上につながる本質的な変化です。実際に私たちのプロジェクトでも、JavaScriptランタイムへの移行後、バグ修正にかかる時間が約40%削減されました。
JavaScriptランタイムによる実装の詳細
リゾルバーとファンクションの新しい記述方法
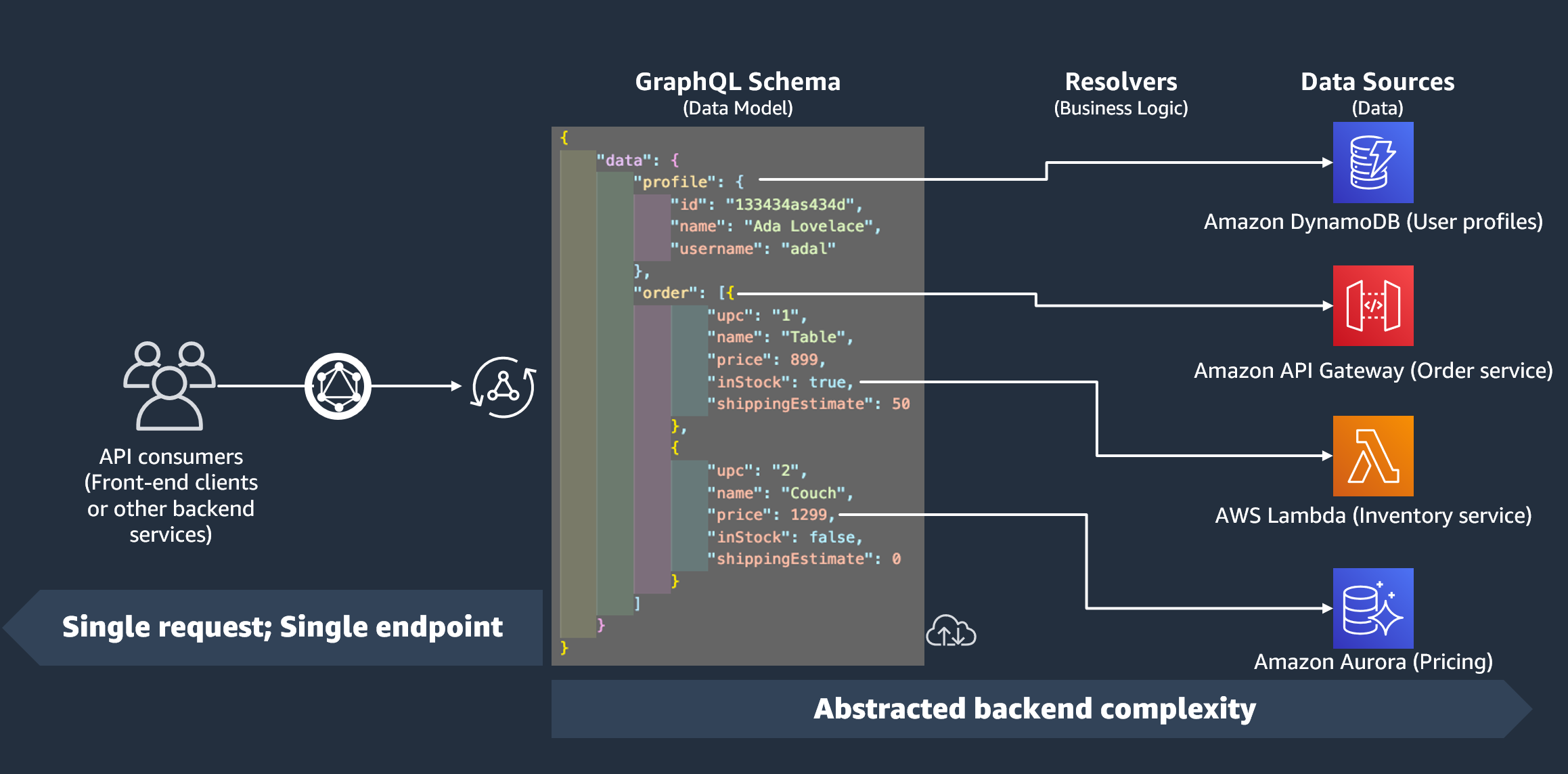
JavaScriptランタイムでは、VTLのBefore/Afterマッピングテンプレートがrequest/response関数として実装されます。この変更により、コードの可読性が大幅に向上しました。
データの受け渡しにはctx.stashを使用し、前の処理結果にはctx.prev.resultでアクセスします。これはVTL時代の$ctx.stashや$ctx.prev.resultと同等の機能ですが、JavaScriptの文法で扱えるため、型推論やIDEの補完機能を活用できます。
CloudFormationでの記述例を見てみましょう。以下は、ユーザー登録フローをパイプラインリゾルバーで実装した例です。
Resources:
UserSignUpPipelineResolver:
Type: AWS::AppSync::Resolver
Properties:
ApiId: !Ref GraphQLApiId
TypeName: "Mutation"
FieldName: "signUp"
Kind: PIPELINE
PipelineConfig:
Functions:
- !GetAtt ValidateEmailFunction.FunctionId
- !GetAtt CheckDuplicateUserFunction.FunctionId
- !GetAtt CreateUserFunction.FunctionId
- !GetAtt SendWelcomeEmailFunction.FunctionId
Runtime:
Name: APPSYNC_JS
RuntimeVersion: 1.0.0
Code: |
export function request(ctx) {
// Beforeマッピングテンプレートに相当
ctx.stash.email = ctx.args.input.email.toLowerCase();
ctx.stash.timestamp = Date.now();
return {};
}
export function response(ctx) {
// Afterマッピングテンプレートに相当
if (ctx.error) {
return {
success: false,
message: ctx.error.message
};
}
return {
success: true,
user: ctx.prev.result
};
}関数(Functions)の実装パターン
各関数も同様にJavaScriptで実装します。以下は、メールアドレス検証関数の実装例です。
Resources:
ValidateEmailFunction:
Type: AWS::AppSync::FunctionConfiguration
Properties:
ApiId: !Ref GraphQLApiId
Name: "ValidateEmailFunction"
DataSourceName: !Ref NoneDataSource
Runtime:
Name: APPSYNC_JS
RuntimeVersion: 1.0.0
Code: |
import { util } from '@aws-appsync/utils';
export function request(ctx) {
const { email } = ctx.stash;
// メールアドレスの形式チェック
const emailRegex = /^[^\\\\s@]+@[^\\\\s@]+\\\\.[^\\\\s@]+$/;
if (!emailRegex.test(email)) {
util.error('Invalid email format', 'ValidationError');
}
// 許可ドメインのチェック
const allowedDomains = ['company.com', 'partner.com'];
const domain = email.split('@')[1];
if (!allowedDomains.includes(domain)) {
util.error(`Domain ${domain} is not allowed`, 'ValidationError');
}
return { payload: { validatedEmail: email } };
}
export function response(ctx) {
return ctx.result;
}JavaScriptランタイムの制約と対処法
JavaScriptランタイムには、いくつかの重要な制約があります。async/awaitが使用できない、throwではなくutil.error()を使用する必要がある、早期終了にはruntime.earlyReturn()を使うなど、通常のNode.js環境とは異なる点に注意が必要です。
これらの制約は一見不便に思えるかもしれませんが、同期的な処理フローを強制することで、パフォーマンスの予測可能性を高め、デバッグを容易にする効果があります。実際、非同期処理が必要な場合は、Lambda関数をデータソースとして使用することで解決できます。
監視とパフォーマンス最適化の新機能
CloudWatch Enhanced Metricsによる詳細監視
2024年2月に発表されたCloudWatch Enhanced Metricsは、AppSyncの監視能力を大きく向上させました。12種類の新しいメトリクスが追加され、リクエスト数、エラー数、レイテンシー、キャッシュヒット率などを、API全体、リクエスト単位、リゾルバー単位で監視できるようになりました。
以下の表は、Enhanced Metricsで取得できる主要なメトリクスとその活用方法をまとめたものです。
表 Enhanced Metricsの主要メトリクスと活用シーン
メトリクス名 | 監視対象 | 活用シーン | アラート閾値の目安 |
|---|---|---|---|
4XXErrors | クライアントエラー数 | 不正なリクエストの検知 | 5分間で10件以上 |
5XXErrors | サーバーエラー数 | システム異常の検知 | 1分間で5件以上 |
Latency | リクエストのレイテンシー | パフォーマンス監視 | P99で1秒以上 |
CacheHitCount | キャッシュヒット数 | キャッシュ効果の測定 | - |
CacheMissCount | キャッシュミス数 | キャッシュ設定の見直し | ヒット率50%未満 |
ResolverLatency | リゾルバー単位のレイテンシー | ボトルネック特定 | 500ms以上 |
これらのメトリクスを活用することで、パイプラインリゾルバーのどの関数がボトルネックになっているかを特定し、最適化の優先順位を決定できます。
リゾルバー単位のメトリクス有効化
リゾルバー単位のメトリクスを有効化するには、CloudFormationで以下のように設定します。
Resources:
GraphQLApi:
Type: AWS::AppSync::GraphQLApi
Properties:
Name: MyGraphQLApi
AuthenticationType: API_KEY
EnhancedMetricsConfig:
ResolverLevelMetricsBehavior: PER_RESOLVER_METRICS
DataSourceLevelMetricsBehavior: PER_DATA_SOURCE_METRICS
OperationLevelMetricsConfig: ENABLED
MonitoredResolver:
Type: AWS::AppSync::Resolver
Properties:
ApiId: !GetAtt GraphQLApi.ApiId
TypeName: Query
FieldName: getUser
MetricsConfig: ENABLED # リゾルバー単位のメトリクス有効化
# ... その他の設定サーバーサイドキャッシュの戦略的活用
パイプラインリゾルバーでもサーバーサイドキャッシュを活用できます。特に読み取り頻度の高いQueryに対してキャッシュを設定することで、下流のデータソースへの負荷を大幅に削減できます。
キャッシュ戦略を検討する際の重要なポイントを以下にまとめます。
- TTL(Time To Live)は業務要件とのバランスを考慮し、段階的に調整する
- キャッシュキーには適切な粒度を設定し、不要なキャッシュミスを防ぐ
- 更新系処理(Mutation)実行後のキャッシュ無効化戦略を事前に設計する
- 圧縮機能を併用することで、ネットワーク転送量も削減可能
認証・認可の最新アプローチ
Lambdaカスタムオーソライザーの進化
2024年4月に発表されたLambdaカスタムオーソライザーのヘッダー転送機能により、より柔軟な認証・認可の実装が可能になりました。
この機能を活用することで、例えば以下のような高度な認証パターンを実装できます。
// Lambda Authorizerの実装例
export const handler = async (event: any) => {
const { headers, requestContext } = event;
// カスタムヘッダーからテナント情報を取得
const tenantId = headers['x-tenant-id'];
const apiKey = headers['x-api-key'];
// マルチテナント環境での認証・認可
const authResult = await validateTenantAndApiKey(tenantId, apiKey);
if (!authResult.isValid) {
return {
isAuthorized: false
};
}
return {
isAuthorized: true,
resolverContext: {
tenantId: authResult.tenantId,
userId: authResult.userId,
permissions: authResult.permissions
},
ttlOverride: 300 // キャッシュを5分間有効化
};
};このアプローチにより、マルチテナントSaaSアプリケーションなど、複雑な認証要件にも対応できます。
実践的な設計パターンとベストプラクティス
マイクロサービス間の集約パターン
パイプラインリゾルバーは、複数のマイクロサービスからデータを集約する際に真価を発揮します。以下は、ECサイトでの注文詳細取得の実装例です。
OrderDetailPipeline:
Type: AWS::AppSync::Resolver
Properties:
TypeName: Query
FieldName: getOrderDetail
Kind: PIPELINE
PipelineConfig:
Functions:
- !GetAtt GetOrderFunction.FunctionId # 注文サービス
- !GetAtt GetUserFunction.FunctionId # ユーザーサービス
- !GetAtt GetProductsFunction.FunctionId # 商品サービス
- !GetAtt GetShippingFunction.FunctionId # 配送サービス
- !GetAtt AggregateDataFunction.FunctionId # データ集約各関数で異なるデータソースにアクセスし、最終的に一つのレスポンスにまとめることで、フロントエンドからは単一のクエリで必要なすべての情報を取得できます。
エラーハンドリングとリトライ戦略
パイプライン内でのエラーハンドリングは慎重に設計する必要があります。以下のパターンを推奨します。
export function request(ctx) {
// 前の処理でエラーが発生した場合の早期終了
if (ctx.prev.error) {
return runtime.earlyReturn({
error: {
type: 'PipelineError',
message: `Failed at step: ${ctx.prev.error.step}`,
details: ctx.prev.error
}
});
}
// リトライ可能なエラーかどうかを判定
const retryableErrors = ['NetworkError', 'TimeoutError'];
if (retryableErrors.includes(ctx.prev.error?.type)) {
ctx.stash.retryCount = (ctx.stash.retryCount || 0) + 1;
if (ctx.stash.retryCount < 3) {
// リトライロジック
return performRetry(ctx);
}
}
// 通常の処理
return processRequest(ctx);
}段階的移行戦略
VTLから JavaScriptランタイムへの移行は、以下の段階的アプローチを推奨します。
- 新規開発はすべてJavaScriptランタイムで実装する
- 変更頻度の高いリゾルバーから順次移行する
- 複雑なVTLロジックは、まずLambda関数に切り出してからJavaScriptランタイムに移行する
- 移行後は必ずパフォーマンステストを実施し、レイテンシーの変化を確認する
AWSの公式ブログでも段階的な移行アプローチが推奨されており、実際のプロジェクトでもこのアプローチが有効であることを確認しています。
パフォーマンス最適化のテクニック
並列処理が必要な場合の代替アプローチ
パイプラインリゾルバーは直列実行のみですが、並列処理が必要な場合は、Lambda関数内で並列化を実装する方法が効果的です。
// Lambda関数内での並列処理実装例
export const handler = async (event: any) => {
const { userId } = event;
// 複数のAPIを並列で呼び出し
const [userData, orderHistory, recommendations] = await Promise.all([
fetchUserData(userId),
fetchOrderHistory(userId),
fetchRecommendations(userId)
]);
return {
user: userData,
orders: orderHistory,
recommendations: recommendations
};
};このアプローチにより、パイプラインリゾルバーの制約を回避しつつ、効率的なデータ取得を実現できます。
コスト最適化の観点
パイプラインリゾルバーを使用する際のコスト最適化について、以下の観点で検討することをお勧めします。
表 コスト最適化のチェックポイント
最適化項目 | 具体的な対策 | 期待される効果 |
|---|---|---|
キャッシュの活用 | TTLを業務要件に応じて最大化 | リクエスト数を30-50%削減 |
バッチ処理の導入 | DynamoDBバッチGetItem活用 | API呼び出し回数を削減 |
データソースの選定 | 用途に応じて最適なデータソースを選択 | 処理時間とコストのバランス改善 |
メトリクスの最適化 | 必要最小限のメトリクスのみ有効化 | CloudWatchコストを20-30%削減 |
今後の展望と準備すべきこと
GraphQL Federation への対応準備
AppSyncは将来的にGraphQL Federationへの対応を強化する可能性があります。現時点でパイプラインリゾルバーを適切に設計しておくことで、将来の移行がスムーズになります。
特に、各関数を責務ごとに明確に分離し、データソースとの結合度を低く保つことが重要です。これにより、将来的にサブグラフへの分割が必要になった場合でも、大規模な改修を避けることができます。
AIサービスとの統合パターン
生成AIサービスとの統合においても、パイプラインリゾルバーは有効です。例えば、以下のような処理フローを実装できます。
- ユーザー入力の検証とサニタイズ
- コンテキスト情報の取得(過去の会話履歴など)
- AI APIの呼び出し
- レスポンスの後処理とフィルタリング
- 結果の保存と返却
このような複雑な処理フローも、パイプラインリゾルバーを使用することで、各ステップを独立して管理・テストできます。
まとめ
AppSyncのパイプラインリゾルバーは、JavaScriptランタイムの導入により大きく進化しました。VTL時代と比較して開発生産性が向上し、チーム全体でのコードレビューが可能になったことは、品質向上に直結する重要な変化です。
2024年に追加された監視機能や認証機能の拡充により、エンタープライズレベルの要件にも十分対応できるようになりました。特にEnhanced Metricsによる詳細な監視は、パフォーマンスボトルネックの特定と改善に不可欠なツールとなっています。
今後AppSyncを活用したGraphQL APIの開発において、パイプラインリゾルバーは複雑なビジネスロジックを実装する上で欠かせない機能です。JavaScriptランタイムへの移行を進めつつ、監視とキャッシュを適切に活用することで、高性能で保守性の高いAPIを構築できるでしょう。
既存のVTL資産がある場合も、段階的な移行アプローチを採用することで、リスクを最小限に抑えながら最新の機能を活用できます。本記事で紹介した実装パターンとベストプラクティスを参考に、ぜひ実際のプロジェクトでパイプラインリゾルバーを活用してみてください。
























