



Amazon ECS に20秒解像度の高解像度メトリクスが追加されました。従来の60秒解像度よりも素早くリソース使用率の変化を検知できるため、ターゲット追跡スケーリングの反応を速め、トラフィックスパイクへの追従性を高められます。この機能は AWS Fargate、Amazon ECS Managed Instances、Amazon EC2 のすべての ECS コンピュートオプションで利用でき、すべての AWS 商用リージョンと AWS GovCloud (US) リージョンで提供されています。
本記事では、60秒解像度のスケーリングが抱えていた課題から、20秒解像度の仕組みと新しい事前定義メトリクスタイプ、コンソールと AWS CLI での設定、既存サービスの2ステップ移行、導入効果と注意点までを順に整理します。
60秒解像度のスケーリングが抱えていた課題
デフォルトでは、Amazon ECS は CPUUtilization と MemoryUtilization のサービスメトリクスを60秒解像度で CloudWatch に発行します。ECS はもともとリソース使用率を20秒ごとに収集していますが、標準解像度では収集した複数のデータポイントを1分ごとに1点へ集約してから送信します。このとき最小値・最大値・平均値が算出され、平均値は20秒ごとの3つの値をまとめた集約値になります。
ターゲット追跡スケーリングは、CloudWatch アラームのデータポイントを評価して反応します。そのため、評価できるデータポイントの間隔が60秒であると、使用率が急上昇してからスケールアウトの判断が下されるまでに構造的な遅れが生じます。トラフィックがスパイクするワークロードでは、この遅れがレイテンシーやエラーの増加につながりやすい点が課題でした。
こうした遅延を補うために、あらかじめ余剰のタスクを抱えておくキャパシティパディングという運用がよく取られてきました。しかしこれは常時余分なコンピュートコストを支払うことを意味します。高解像度メトリクスは、データポイントの間隔そのものを短縮することで、この遅延と余剰容量の課題に応えます。
20秒解像度の高解像度メトリクスと新しい事前定義メトリクスタイプ
サービスにモニタリング構成を設定し resolutionSeconds を 20 にすると、20秒間隔のデータポイントをそのまま CloudWatch へ発行できます。設定はメトリクスごとに行え、CPUUtilization と MemoryUtilization を個別にも両方にも指定できます。データポイント間隔が60秒から20秒へ短縮されることで、使用率変化の検知が速くなり、より高速なサービスオートスケーリングを駆動できる仕組みです。
ターゲット追跡スケーリングポリシーでは、高解像度に対応した新しい事前定義メトリクスタイプを指定します。CPU 向けが ECSServiceAverageCPUUtilizationHighResolution、メモリ向けが ECSServiceAverageMemoryUtilizationHighResolution です。それぞれ20秒解像度での平均 CPU 使用率、平均メモリ使用率を表します。従来型との対応関係は次のとおりです。
従来型(標準60秒解像度) | 高解像度(20秒解像度) |
|---|---|
ECSServiceAverageCPUUtilization | ECSServiceAverageCPUUtilizationHighResolution |
ECSServiceAverageMemoryUtilization | ECSServiceAverageMemoryUtilizationHighResolution |
利用にあたっては前提条件があります。ロードバランサーは Application Load Balancer と Network Load Balancer を使用するサービスでサポートされ、ターゲットグループを持たない Classic Load Balancer は対応しません。デプロイコントローラーについては、CODE_DEPLOY および EXTERNAL を使用するサービスでは高解像度メトリクスを利用できません。コンピュートは前述のとおり Fargate、ECS Managed Instances、EC2 のすべてに対応します。
コンソールとAWS CLIで新規サービスに設定する
コンソールから設定する場合は、サービス作成時にモニタリングの解像度を20秒へ構成し、その後スケーリングポリシーで対応する高解像度のメトリクスタイプを選ぶという流れになります。AWS CLI では次の3つのコマンドで設定が完了します。
モニタリング構成付きでサービスを作成する
aws ecs create-service --region us-east-1 \
--cluster my-cluster \
--service-name my-service \
--task-definition my-app:1 \
--desired-count 2 \
--monitoring "metricConfigurations=[{metricNames=[CPUUtilization,MemoryUtilization],resolutionSeconds=20}]"スケーラブルターゲットを登録する
aws application-autoscaling register-scalable-target \
--service-namespace ecs \
--resource-id service/my-cluster/my-service \
--scalable-dimension ecs:service:DesiredCount \
--min-capacity 1 \
--max-capacity 10 \
--region us-east-1高解像度メトリクスでターゲット追跡ポリシーを作成する
ポリシータイプには TargetTrackingScaling を指定し、PredefinedMetricType に高解像度のメトリクスタイプを設定します。
aws application-autoscaling put-scaling-policy \
--service-namespace ecs \
--resource-id service/my-cluster/my-service \
--scalable-dimension ecs:service:DesiredCount \
--policy-name my-highres-cpu-policy \
--policy-type TargetTrackingScaling \
--target-tracking-scaling-policy-configuration '{
"TargetValue": 50.0,
"PredefinedMetricSpecification": {
"PredefinedMetricType": "ECSServiceAverageCPUUtilizationHighResolution"
}
}' \
--region us-east-1既存サービスを2ステップで移行する
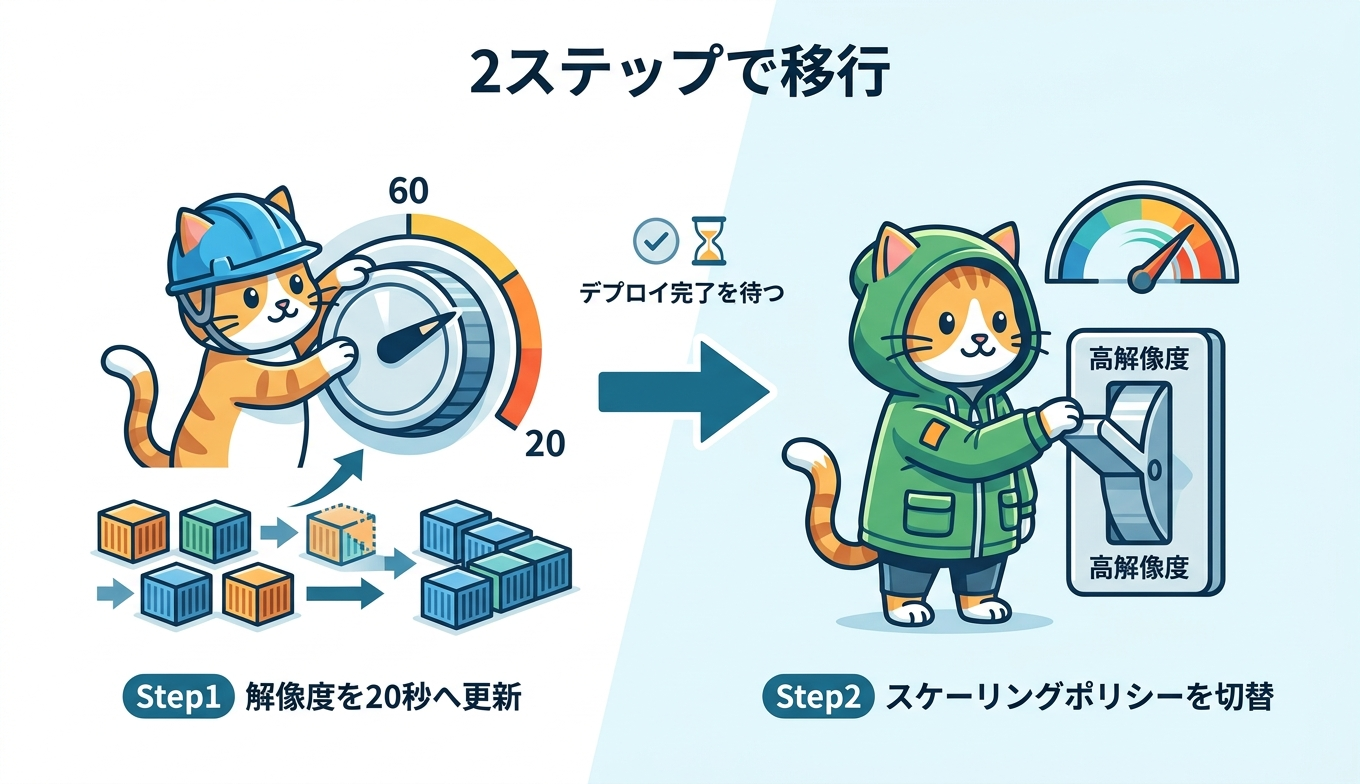
すでに稼働しているサービスは2つのステップで移行できます。ここで重要なのは順序です。先にモニタリング解像度を20秒へ更新してデプロイの完了を待ち、そのあとでスケーリングポリシーを高解像度メトリクスタイプへ更新します。順序を逆にすると、高解像度のメトリクスタイプが選択できず、コンソールではグレーアウトします。
ステップ1 モニタリング解像度を20秒へ更新する
モニタリング構成の変更は新しいサービスリビジョンを作成し、サービスデプロイをトリガーします。すべてのタスクが20秒解像度での発行を開始しデプロイが完了するまで、高解像度のスケーリングメトリクスは利用できません。
aws ecs update-service --region us-east-1 \
--cluster my-cluster \
--service my-service \
--monitoring "metricConfigurations=[{metricNames=[CPUUtilization,MemoryUtilization],resolutionSeconds=20}]"モニタリング構成は CreateService や UpdateService のレスポンスには返らないため、DescribeServiceRevisions で確認します。サービスリビジョンの ARN は describe-services の出力から取得できます。
aws ecs describe-service-revisions --region us-east-1 \
--service-revision-arns arn:aws:ecs:us-east-1:012345678910:service-revision/my-cluster/my-service/1234567890123456789レスポンスに次のように resolutionSeconds が20で含まれていれば、構成が有効になっています。
{
"serviceRevisions": [
{
"monitoring": {
"metricConfigurations": [
{
"metricNames": ["CPUUtilization", "MemoryUtilization"],
"resolutionSeconds": 20
}
]
}
}
]
}ステップ2 スケーリングポリシーを高解像度メトリクスタイプへ更新する
デプロイ完了を確認したら、スケーリングポリシーを高解像度メトリクスタイプへ更新します。スケーラブルターゲットが未登録であれば先に register-scalable-target で登録し、put-scaling-policy の PredefinedMetricType に CPU なら ECSServiceAverageCPUUtilizationHighResolution、メモリなら ECSServiceAverageMemoryUtilizationHighResolution を指定します。コマンドの構造は前章と同じです。
ユースケースと導入効果、運用上の注意事項
高解像度メトリクスは、トラフィックがスパイクするワークロードで特に効果を発揮します。使用率変化の検知が速くなることで、スパイクへの応答が改善し、レイテンシーやエラーの低減につながります。スケールアウトが十分に速くなるため、あらかじめ余剰容量を抱えるキャパシティパディングに頼る必要が薄れ、ワークロードによってはベースラインのタスク数を削減できます。これにより、パフォーマンスと可用性を維持しながらコンピュートコストを直接削減できる可能性があります。ターゲット追跡を使えば、カスタムのステップスケーリングポリシーを組まずにスケーリング構成を簡素にまとめられる点も利点です。
改善幅の目安として、AWSのベンチマークテストにおいて、スケールアウトのトリガー時間が363秒から86秒へ、新規タスクのスケールとプロビジョニングの総時間が386秒から109秒へ短縮されたと報告されています。これらはAWSのベンチマーク条件下での値であり、ワークロードに依存しない保証値ではない点に留意してください。
運用上の注意点もあります。機能自体に追加料金はありませんが、CloudWatch の高解像度メトリクスには追加の CloudWatch 料金が発生します。標準の60秒解像度は無料です。また前述のとおり、モニタリング構成の変更はデプロイを伴うため、完了まで高解像度スケーリングメトリクスは選択できません。スケールアウトとスケールインのクールダウン期間は秒単位で設定でき、コンソールの Additional Settings から構成します。ALB と NLB のみ対応し Classic Load Balancer は非対応、CODE_DEPLOY と EXTERNAL のデプロイコントローラーは非対応という制約も確認しておきましょう。順序を守った移行手順と料金・非対応構成の確認を押さえれば、既存サービスにも段階的に取り入れられます。
























