



2026年6月17日、Amazon Bedrock AgentCore に Web Search 機能が追加され、米国東部(バージニア北部)リージョンで一般提供が始まりました。AIエージェントを「いま現在の正確なウェブ知識」でグラウンディングするためのフルマネージドツールです。本稿では、RAG や AIエージェント開発に取り組む開発者の視点から、Web Search が何を解決するのか、RAG との使い分け、ユースケース、AgentCore Gateway を使った実装の進め方、そして Ragate としての活用可能性までを公式情報に沿って整理します。
Amazon Bedrock AgentCore の Web Search とは
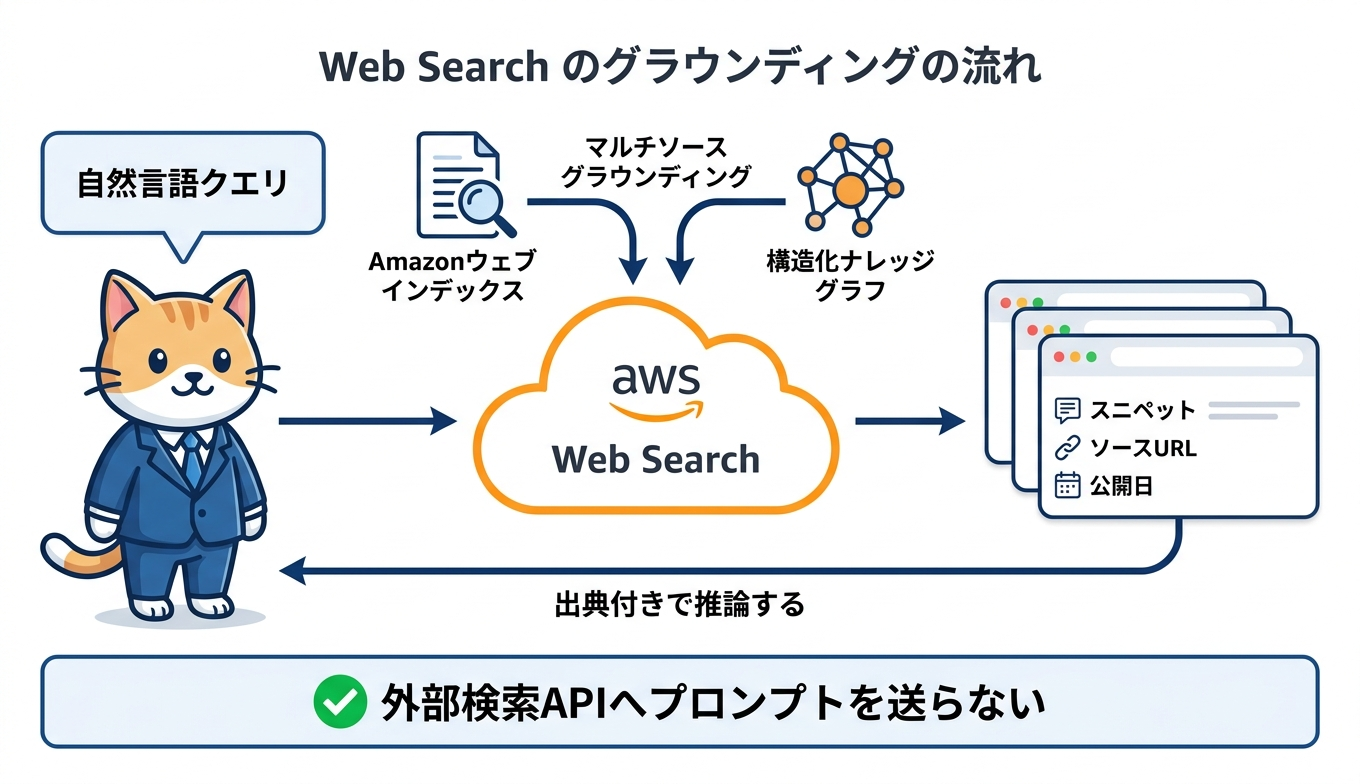
Web Search は、エージェントがユーザーの質問を分析し、モデルの学習データだけでなく最新のウェブ動向に基づいて応答やアクションを生成できるようにするツールです。AWS の発表によれば、Amazon の検索インフラストラクチャを基盤として構築されており、エージェントから自然言語クエリを受け取ると、最も関連性の高いスニペット、ソース URL、タイトル、公開日を返します。モデルはこれらの情報に基づいて推論し、出典が明示された応答を組み立てます。
特徴的なのは「マルチソースグラウンディングアプローチ」です。Amazon のウェブインデックスと構造化されたナレッジグラフデータを組み合わせることで、従来のウェブ検索のみに頼る場合より関連性が高く正確な応答を狙う設計になっています。さらに、AWS 以外の外部検索 API プロバイダーにユーザープロンプトや検索クエリを送信せずに済む点も強調されています。プロンプトを外部へ出さずに最新情報を取り込めるため、企業のガバナンス要件を満たしやすいという狙いです。
RAG との違いと使い分け
最新情報の取り込みという文脈で必ず比較対象になるのが RAG(Retrieval-Augmented Generation)です。なお、今回の AWS の発表記事自体は RAG との明示的な比較を述べているわけではなく、あくまでグラウンディング手法として Web Search を紹介している点は押さえておきたいところです。そのうえで開発者として整理すると、両者は競合ではなく補完関係にあると考えると分かりやすくなります。
RAG は、自社のドキュメントやナレッジベースといった非公開・組織固有のデータをベクトル検索などで取り込み、モデルの応答に反映させる手法です。社内規程、製品仕様、過去の問い合わせ履歴のように、外部には存在しない知識を扱うのに向いています。一方の Web Search は、公開ウェブ上のいま現在の情報をリアルタイムにグラウンディングします。最新ニュース、価格、規制動向のように、鮮度が価値を持つ公開情報を扱うのに向いています。
観点ごとに並べると、対象データは RAG が「自社固有・非公開」、Web Search が「公開ウェブ」、鮮度は RAG が「取り込み時点に依存」、Web Search が「リアルタイム」、運用は RAG が「インデックス構築と更新が必要」、Web Search が「フルマネージドでインデックス運用不要」と整理できます。実務では、自社ナレッジは RAG、世の中の最新動向は Web Search という形で両方をエージェントのツールとして持たせる構成が現実的な落としどころになります。
主なユースケース
Web Search が効くのは、回答の鮮度が品質を左右する場面です。たとえばカスタマーサポートでは、製品の最新仕様や公開済みの障害情報を踏まえた回答が求められます。市場調査やリサーチの領域では、競合の動きや規制の変更といった移り変わる情報を、出典付きでエージェントに集めさせる用途が考えられます。
AWS の発表では、実際の顧客事例も紹介されています。科学データプラットフォームの Benchling では、科学者が現在取り組んでいる研究対象について質問すると、Benchling 内に存在する自組織のデータと公開文献の両方に基づいた回答を得られるとされています。これはまさに RAG 的な社内データと Web Search による公開知識を組み合わせた好例です。また、Norton を提供する Gen Digital では、Norton Revamp が世の中の最新の動きに基づいた的確なコンテンツアイデアを提示し、プロフェッショナルがオンラインでの評判を築くことを支援するとされています。
このように、サポート自動化、ハイブリッドなナレッジ回答、コンテンツ生成、継続的なモニタリングといった幅広い場面で、最新ウェブ知識を安全に取り込む基盤として活用できます。
実装方法と導入のポイント
導入の起点は Bedrock AgentCore Gateway です。Web Search は Gateway の組み込みコネクタターゲットとして提供され、プロトコルにはモデルコンテキストプロトコル(MCP)が使われます。具体的な流れとしては、Bedrock AgentCore コンソールで Web Search ツールターゲットを含む Gateway を作成し、ターゲットタイプとして「コネクタ」を選び、事前設定済みの Web Search ツールを選択します。エージェント側はこの Gateway を MCP 経由のツールとして呼び出すだけで、ウェブ検索の能力を獲得できます。
動作確認やデバッグには、API コールや CLI に加えて MCP Inspector が利用できます。MCP Inspector は MCP サーバーをテスト・デバッグするためのインタラクティブな開発者向けツールで、ツールが期待どおりに応答するかを対話的に確認できます。エージェントの実装側では、MCP Python SDK や Strands MCP Client を使って Gateway に接続する構成が案内されています。MCP に準拠しているため、既存の MCP 対応エージェントへ後付けでツールとして組み込みやすいのも実装上の利点です。
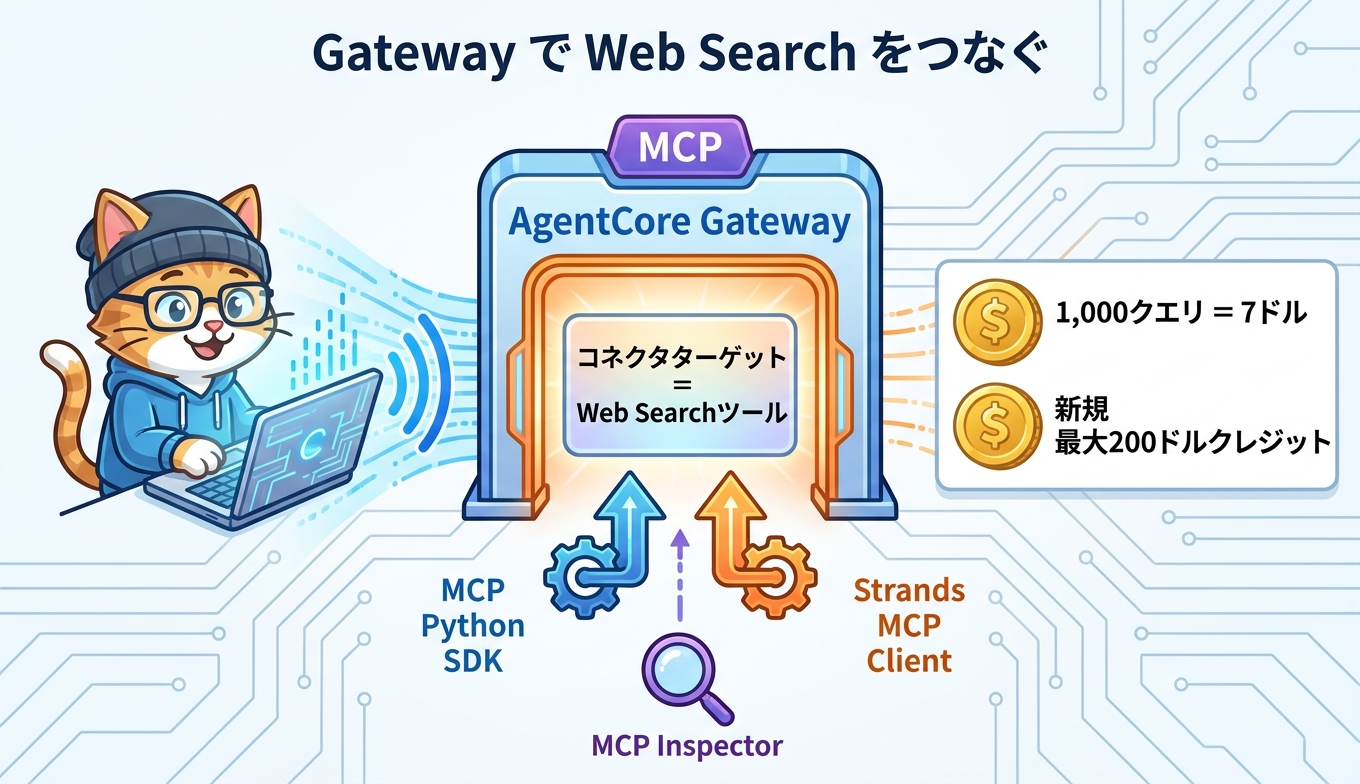
料金面も設計の段階で意識しておきたいポイントです。初期費用はなく、エージェントが Web 検索に送信した検索クエリの数に応じて課金されます。単価は 1,000 クエリあたり 7 ドルで、AWS の新規のお客様には最大 200 ドルの無料利用枠クレジットが用意されています。クエリ課金であるため、エージェントが不要に検索を連発しない設計、たとえば検索が本当に必要かをモデルに判断させるプロンプト設計や、社内ナレッジで答えられる質問は RAG 側に寄せる切り分けが、そのままコスト最適化につながります。
Ragate としての活用可能性と見解
Ragate は AWS を中心としたクラウド支援と AX(AI Transformation)の伴走を強みとし、AWS パートナーとして新機能をいち早く実プロジェクトへ取り込んできました。AgentCore は MVP 開発やテクノロジーアドバイザリーの現場で活用領域となっており、今回の Web Search はその選択肢をさらに広げる追加機能だと捉えています。
とりわけ価値が大きいと考えるのは、社内 RAG と Web Search を組み合わせたハイブリッドなエージェント構築です。社内の閉域ナレッジは RAG で安全に押さえつつ、世の中の最新動向は Web Search で出典付きに補う構成は、回答の信頼性と鮮度を両立させやすく、企業の実運用に乗せやすい形です。Web Search が外部検索 API へプロンプトを送らない設計である点も、ガバナンスを重視する企業にとって採用判断を後押しします。
導入にあたっては、Ragate が掲げる「小さく確実な」4フェーズ、すなわち基盤整備、パイロット展開、全社展開、高度化のロードマップに沿って進めるのが現実的です。まずは限定したユースケースで Gateway と Web Search を試し、クエリ課金の実コストと回答品質を自社データで確かめたうえで段階的に広げていく進め方を推奨します。最新ウェブ知識を安全に扱えるエージェント基盤づくりを、設計から運用まで一気通貫で支援できる領域だと考えています。
























