


オープンウェイトモデルがもたらす構造変化
エンタープライズAIの新たな選択肢
OpenAIが公開した「gpt-oss-120b」と「gpt-oss-20b」は、単なる新しいモデルのリリースという枠を超えて、エンタープライズAI戦略に根本的な変化をもたらす可能性を秘めています。これまでOpenAIは、GPT-2以降、大規模言語モデルの学習済みウェイトを非公開とする戦略を取ってきました。しかし今回、Apache 2.0ライセンスでの公開に踏み切ったことは、オープンソースコミュニティと企業ユーザーの両方に対する明確なメッセージとなっています。
私がこの動きを注目している理由は、企業のAI導入における「コントロール」と「柔軟性」のバランスが大きく変わる可能性があるからです。従来のAPIベースのサービスでは、モデルの内部動作はブラックボックスであり、企業は提供されるインターフェースを通じてのみアクセスできました。しかしオープンウェイトモデルでは、企業が自社のインフラ上でモデルを完全に管理し、必要に応じてカスタマイズすることが可能になります。
Amazon Bedrockとの統合がもたらす実践的価値
Amazon BedrockでのOpenAIモデルの利用が可能になったことで、企業は既存のAWSインフラストラクチャとシームレスに統合できる環境を手に入れました。特に注目すべきは、OpenAI SDKとの互換性を維持しながら、Bedrockのマネージドサービスとしてのメリットを享受できる点です。これにより、企業は以下のような実装パターンを選択できるようになります。
エンタープライズ環境での実装において考慮すべき主なパターンは以下の通りです。
- Bedrockを通じた完全マネージドサービスとしての利用
- SageMaker JumpStartを活用したカスタムデプロイメント
- オンプレミスやエッジ環境での独自運用
- ハイブリッドクラウド環境での分散配置
技術アーキテクチャの深掘り
Mixture-of-Expertsアーキテクチャの革新性
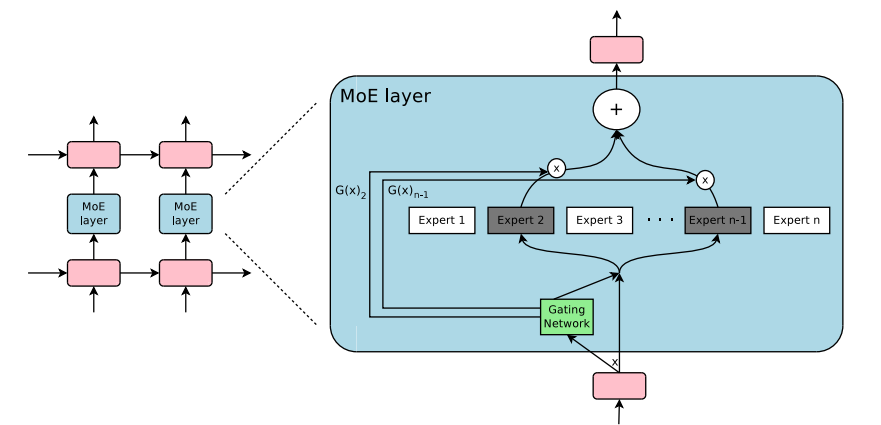
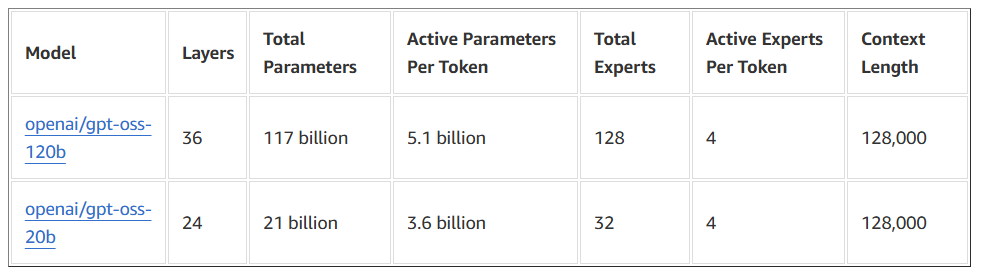
gpt-ossシリーズの最大の特徴は「Mixture-of-Experts (MoE)」構造を採用している点にあります。この設計は、モデルの総パラメータ数と実際の推論時に使用されるアクティブパラメータ数の間に大きなギャップを生み出しています。gpt-oss-120bの場合、全体で約1170億のパラメータを持ちながら、各トークンの推論で実際に使用されるのは約51億パラメータに過ぎません。
MoEアーキテクチャの具体的な構成を見てみると、120bモデルでは36層のTransformerブロックがあり、各層に128個のエキスパートが配置されています。推論時には、これらのエキスパートから上位4つ(Top-4)だけが動的に選択され、計算に参加します。この「スパース活性化」のアプローチにより、大規模なモデル容量を持ちながら、計算コストとメモリ使用量を劇的に削減することが可能になっています。
実務的な観点から見ると、このアーキテクチャは特にリソース制約のある環境での運用において大きな優位性を発揮します。例えば、120bモデルが単一の80GB GPUで動作可能であることや、20bモデルが16GBメモリクラスでも稼働できることは、多くの企業にとって現実的な選択肢となるでしょう。
128kコンテキスト対応と注意機構の工夫
もう一つの重要な技術的特徴は、128kトークンという極めて長いコンテキスト長のネイティブサポートです。これは「Rotary Position Embeddings (RoPE)」と呼ばれる位置エンコーディング手法の採用により実現されています。さらに、層ごとに全結合型の注意機構と局所バンド型のスパース注意を交互に配置することで、効率的な情報処理を実現しています。
長大なコンテキストを扱える能力は、エンタープライズアプリケーションにおいて以下のような具体的な価値を生み出します。
- 複数の関連文書を一度に参照しながらの包括的な分析
- 長期的な会話履歴を保持した対話型AIの実装
- 大規模なコードベースの解析と最適化提案
- 複雑な業務プロセスの文書化と改善提案
MXFP4量子化による実用性の向上
モデルの実用性を高める重要な要素として、「MXFP4形式」と呼ばれる独自の4ビット量子化技術が採用されています。この量子化により、117Bパラメータの120bモデルでも80GBのGPUメモリに収まるサイズとなり、単一のNVIDIA H100カード上での動作が可能になっています。
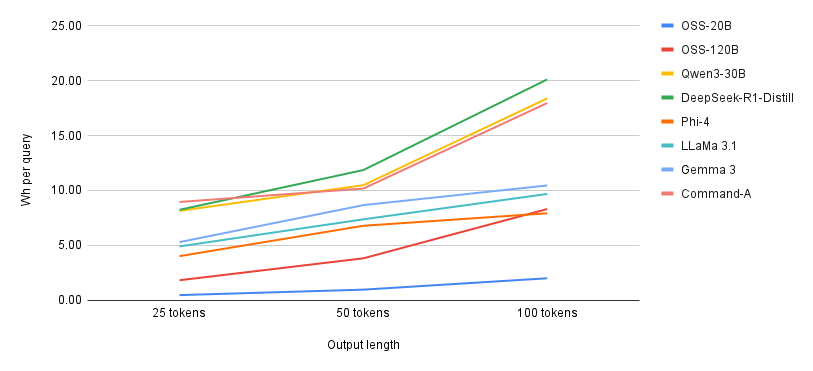
量子化技術の採用は、単にメモリ使用量を削減するだけでなく、推論速度の向上にも寄与しています。Hugging Faceの測定によると、gpt-oss-20bは100トークンの生成で平均2.02Whという驚異的な省エネ性能を示しており、これはLlama-3.1 70B(9.68Wh)と比較して著しく効率的です。
Amazon Bedrockでの実装における戦略的考察
コスト最適化の新たなアプローチ
.webp)
Amazon Bedrockでgpt-ossモデルを利用する際の最大のメリットの一つは、コスト最適化の柔軟性が大幅に向上することです。About Amazonの報告によると、Bedrock上のgpt-ossは他のモデルと比較して、Gemini比で10倍、DeepSeek-R1比で18倍、OpenAI o4比で7倍のコストパフォーマンスを実現しているとされています。
しかし、これらの数値を鵜呑みにするのではなく、実際の業務に即した評価が重要です。
私が推奨するコスト最適化のアプローチは以下の2通りです。
【1】推論レベルの動的調整機能を活用
まず、推論レベルの動的調整機能を活用することです。gpt-ossモデルは「低」「中」「高」の3段階の推論努力度を設定でき、タスクの重要度やSLAに応じて最適なレベルを選択できます。例えば、定型的な問い合わせ対応には低推論モードを使用し、複雑な分析や意思決定支援には高推論モードを適用するといった使い分けが可能です。
【2】ハイブリッドデプロイメント戦略の採用
ピーク時にはBedrockのサーバーレス環境を活用し、通常時はSageMaker上の専用インスタンスで処理するといった、負荷に応じた柔軟な配置が考えられます。
Chain-of-Thoughtの活用と管理
gpt-ossモデルの特徴的な機能として、「Chain-of-Thought (CoT)」の完全な出力が可能である点が挙げられます。これは、モデルが最終的な回答に至るまでの思考プロセスを可視化できることを意味します。
エンタープライズ環境でのCoT活用における重要な観点は以下の通りです。
- 監査とコンプライアンスへの対応
- デバッグとモデル挙動の理解
- 品質保証とリスク管理
- 知識の蓄積と組織学習
ただし、CoTの出力には注意が必要です。OpenAIの推奨では、エンドユーザーにはCoTを直接見せず、最終回答のみを提示することが推奨されています。これは、思考過程に事実誤認や不適切な内容が含まれる可能性があるためです。
セキュリティとガバナンスの実装
オープンウェイトモデルをエンタープライズ環境で運用する際、セキュリティとガバナンスの観点から考慮すべき要素があります。Apache 2.0ライセンスにより商用利用の制約は最小限ですが、運用面での責任は利用者側にあります。
実装時に検討すべきセキュリティ対策の主要な要素は以下の通りです。
- データプライバシーの保護とPII(個人識別情報)の管理
- モデル出力の監視とフィルタリング機構の実装
- アクセス制御と利用ログの管理
- インシデント対応プロセスの確立
BedrockのGuardrails機能を活用することで、これらの要件の多くを効率的に実装できます。特に、有害なコンテンツのフィルタリングやPIIの自動検出・マスキングなど、エンタープライズグレードのセキュリティ機能を簡単に適用できる点は大きなメリットです。
エンタープライズでの活用シナリオ
業務自動化エージェントへの適用
gpt-ossモデルの高度な推論能力とツール使用機能を活かした業務自動化エージェントの構築は、特に有望な活用シナリオです。BedrockのAgent Core機能と組み合わせることで、複雑な業務プロセスを自動化できます。
具体的な実装例として、以下のようなシナリオが考えられます。
カスタマーサポート業務
カスタマーサポート業務における一次対応の自動化では、顧客からの問い合わせを受け付け、社内のCRMシステムやナレッジベースを参照しながら、適切な回答を生成します。必要に応じて、チケットの作成やエスカレーション、フォローアップタスクの設定まで自動で実行できます。
財務分析と報告書作成の自動化
財務分析と報告書作成の自動化では、複数のデータソースから情報を収集し、トレンド分析や異常検知を行いながら、経営層向けのレポートを自動生成します。CoT機能により、分析の根拠や推論過程を明確に示すことで、意思決定の透明性を確保できます。
オンプレミスとクラウドのハイブリッド運用
20bモデルの軽量性を活かしたハイブリッド運用は、データ主権やコンプライアンス要件の厳しい業界において特に価値があります。機密性の高いデータを扱う処理はオンプレミス環境で実行し、一般的なタスクはBedrockを活用するという使い分けが可能です。
金融業界での実装例を考えてみましょう。顧客の個人情報や取引データを扱う分析はオンプレミスの20bモデルで処理し、市場分析や一般的な情報収集はBedrockの120bモデルを活用するといった運用が考えられます。この場合、以下のような実装アーキテクチャが有効です。
オンプレミス環境では、Kubernetesクラスタ上にgpt-oss-20bをデプロイし、プライベートエンドポイント経由でのみアクセスを許可します。データはすべて暗号化され、処理ログは監査要件に準拠した形で保存されます。
クラウド環境では、Bedrock APIを通じてgpt-oss-120bにアクセスし、公開情報の分析や一般的なタスク処理を実行します。両環境間の連携は、セキュアなAPI Gatewayを介して行い、必要最小限の情報のみを交換します。
開発生産性向上への活用
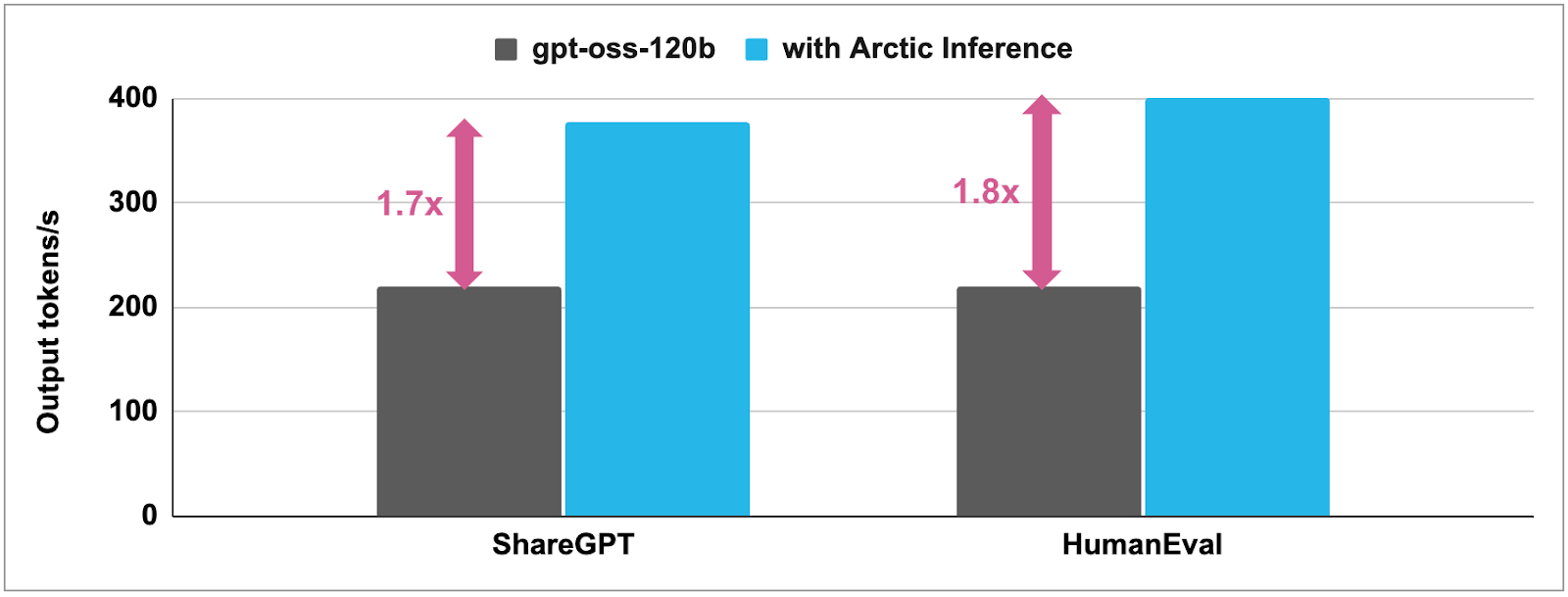
ソフトウェア開発チームにおける生産性向上は、gpt-ossモデルの最も直接的な活用領域の一つです。Snowflakeの事例では、Arctic Speculatorを使用してgpt-ossの推論を1.6〜1.8倍高速化することに成功しています。
開発チームでの具体的な活用方法として、以下のような実装が考えられます。
コードレビューの自動化では、プルリクエストに対して自動的にコードレビューを実行し、潜在的な問題やベストプラクティスからの逸脱を指摘します。CoT出力により、指摘の理由や改善提案の根拠を明確に示すことができます。
ドキュメント生成の効率化では、コードベースから自動的にAPIドキュメントや技術仕様書を生成し、変更があった場合は差分を明確に示しながら更新します。128kコンテキストを活かして、大規模なコードベース全体を考慮した包括的なドキュメントを作成できます。
実装における具体的な考慮事項
パフォーマンスチューニングの戦略
Bedrockでgpt-ossモデルを効果的に運用するためには、適切なパフォーマンスチューニングが不可欠です。私の経験から、以下のアプローチが特に有効であることがわかっています。
まず、推論バッチサイズの最適化です。MoEアーキテクチャの特性上、バッチサイズを適切に設定することで、スループットを大幅に向上させることができます。一般的に、バッチサイズ8〜16程度が最も効率的ですが、具体的な値はワークロードの特性によって調整が必要です。
次に、キャッシング戦略の実装です。頻繁に使用されるプロンプトや共通的な前処理結果をキャッシュすることで、レスポンスタイムを短縮できます。BedrockのAPIレベルでのキャッシングに加えて、アプリケーション層でのインテリジェントなキャッシング機構を実装することが推奨されます。
ファインチューニングとカスタマイゼーション
SageMaker JumpStartを使用したファインチューニングは、ドメイン固有の要件に対応するための強力な手段です。特に、LoRA(Low-Rank Adaptation)やQLoRA(Quantized LoRA)といった効率的な手法を活用することで、限られたリソースでも効果的なカスタマイゼーションが可能です。
ファインチューニングを実施する際の重要な考慮事項は以下の通りです。
- データ品質の確保とバイアスの管理
- 過学習を防ぐための適切な正則化とバリデーション
- ベースモデルの能力を保持しながら特定タスクを強化するバランス
- 継続的な評価とモデルの更新プロセス
監視とオブザーバビリティ
プロダクション環境でのモデル運用において、包括的な監視体制の構築は必須です。BedrockとCloudWatchの統合により、基本的なメトリクスは自動的に収集されますが、ビジネス固有のKPIについては追加の実装が必要です。
監視すべき主要なメトリクスには以下のようなものがあります。
レスポンスタイムの分布 | SLA違反のリスクを早期に検出します。特に、推論レベルごとのレスポンスタイムを分離して監視することで、適切な推論レベルの選択を最適化できます。 |
|---|---|
トークン使用量とコストの追跡 | 日次・週次・月次のトレンドを分析し、予算超過のリスクを管理します。また、プロンプトの効率性を評価し、不必要に長いプロンプトや非効率な使用パターンを特定します。 |
エラー率と品質メトリクスの監視 | モデルの出力品質を定量的に評価するためのカスタムメトリクスを定義し、継続的に測定します。特に、CoT出力の一貫性や論理的な妥当性を評価することが重要です。 |
今後の展望と戦略的示唆
オープンウェイトモデルエコシステムの発展
OpenAIがオープンウェイト戦略に転換したことは、AI業界全体に大きな影響を与える可能性があります。これは単なる一時的なトレンドではなく、エンタープライズAIの民主化という大きな流れの一部として捉えるべきです。
特定のドメインや言語に特化したファインチューニング済みモデルのエコシステムが形成されるでしょう。企業は、これらの専門モデルを組み合わせて、自社のニーズに最適化されたAIシステムを構築できるようになります。
ツールとフレームワークの成熟により、オープンウェイトモデルの運用がより簡単になります。特に、モデルの最適化、デプロイメント、監視を統合的に管理するプラットフォームの登場が期待されます。
エンタープライズAI戦略への影響
オープンウェイトモデルの登場により、企業のAI戦略は「ビルド vs バイ」から「ハイブリッド活用」へとシフトしていくと考えられます。
コアコンピテンスに関連する差別化要素についてはオープンウェイトモデルをカスタマイズして内製化し、汎用的なタスクについてはマネージドサービスを活用するという使い分けが一般的になるでしょう。
リスク分散の観点から、複数のモデルプロバイダーを併用し、ベンダーロックインを回避しながら、最適なコストパフォーマンスを追求する戦略が重要になります。
実装ロードマップ
企業がgpt-ossモデルを活用したAI戦略を実行する際の、段階的なアプローチを提案します。
第1フェーズ(評価と検証) | 既存のユースケースに対してgpt-ossモデルの適用可能性を評価します。BedrockのPlaygroundやSageMaker Studioを活用して、小規模なPoCを実施し、性能とコストの基準値を確立します。 |
|---|---|
第2フェーズ(パイロット実装) | 選定されたユースケースに対して、本番環境に近い条件でのパイロット実装を行います。この段階で、セキュリティ、ガバナンス、運用プロセスの詳細を固めます。 |
第3フェーズ(本番展開と最適化) | 段階的に本番環境への展開を進めながら、継続的な最適化を実施します。ファインチューニングやカスタマイゼーションを通じて、ビジネス固有の要件に対応します。 |
第4フェーズ(スケールと拡張) | 成功したユースケースを他の領域に展開し、組織全体でのAI活用を推進します。この段階では、MLOpsの成熟度を高め、継続的な改善サイクルを確立することが重要です。 |
余談:オファリング制作に関する考察
結論:特定モデルのオファリング化は難しい、まずはお客様の足元の課題を解消したい

前提としてAIモデルのアップデートは非常に激しく、多いときは月1回以上の大型のアップデートがされます。
そのため、特定のAIモデルをターゲットに価値を探求→オファリング化した場合、すぐに価値が希薄化してしまう恐れがあると考え、オファリング化は当社としては行わない方針としました。
ただし、逆に考えれば、「ドメイン毎にAIモデルの選定・導入に特化したアドバイザリー支援」については「近い未来」で一定の需要があるのではないかと考察しました。ここで近い将来と表現したのは、AIモデル選定以前に、AI導入に足踏みをしている企業が多いためです。
私の考えでは、直近はAI導入×DX戦略策定という超上流工程の支援を引き続き継続して行い、以下に該当するような企業を創出していく活動を続けたいと考えています。
- ビジネス課題や目標指標(KPI等)と直結するAI利活用戦略策定が済んでいる
- 長期構想に向けたPoC・MVP制作を実行している(Bedrock・GenUIを推奨)
- AIシステムを調達済み、本格的なAI利活用を推進している(Bedrock・Difyを推奨)
上記の企業様へ段階的にアドバイザリー支援を提供していきたい、そんな想いでいます。
























