



AIエージェントの話題が尽きません。PoC(概念検証)は無数に生まれ、デモは華々しく、LLMのベンチマークスコアは月を追うごとに更新されています。しかし、本番環境でAIエージェントを安定的に運用しているエンジニアリングチームに話を聞くと、判で押したような言葉が返ってきます。「思っていたより難しかった」と。
AWSはこの現象を「コパイロットからコワーカーへ」という言葉で整理しています。コパイロット(副操縦士)は人間の操作を補助するものです。一方、コワーカー(同僚)は独立した判断を持ち、自律的にタスクを遂行し、結果に責任を持ちます。この移行は技術的な進化だけでなく、アーキテクチャ・評価・組織設計すべてを問い直すことを意味します。
本記事では、AIエージェントを本番環境で動かすために必要な実践的知見を、アーキテクチャ設計から信頼構築の仕組み、エンジニアの役割変化まで解説します。
ベンチマークの罠 ― スコアが本番を保証しない理由
AIエージェントの能力評価でよく参照されるのが、ソフトウェアエンジニアリングタスクを自動解決する能力を測るSWE-benchです。2025年末時点での最高スコアは74.4%に達しました。これは確かに目覚ましい進歩です。しかし、このスコアが本番運用での信頼性を保証するかというと、話は別です。
SWE-benchを含む多くのベンチマークには、根本的な設計上の問題があります。それは「タスクを完了できたかどうか」という一次元の評価軸に最適化されている点です。本番環境が要求するのはそれだけではありません。arxivに掲載された研究論文「Beyond Accuracy」(2511.14136)はこの問題を鋭く指摘しており、企業が実際に必要とするのはコスト・信頼性・セキュリティ・レイテンシー・運用制約を同時に充足することだと述べています。
SWE-bench自体も品質問題を認識しており、元のデータセットには検証不可能なタスクが多数含まれていたとして、人間によるバリデーションを経た「SWE-bench Verified」が後に公開されました。研究コミュニティ自身が、ベンチマークと現実の乖離を補正しようとしているわけです。
もう一つ厳しい現実があります。Reliability Gapの研究によれば、AIエージェントを実験している企業の割合は85%に上る一方で、本番デプロイまで到達する割合は僅少です。2025年に306名のAIエージェント実践者を対象に行われた調査では、本番導入の最大障壁として「信頼性の不足」が挙げられています。スコアが高いモデルほど、プロダクションへの期待値も高くなります。しかしその期待値は、能力の最適化だけでは満たせないのです。

アーキテクチャ設計の実践 ― モノリスとマルチエージェントの選択基準
「マルチエージェントにすれば解決する」というのは、現場でよく聞く誤解です。確かにマルチエージェントシステムは、複雑なタスクを専門エージェントに分割して並列処理できる利点があります。しかし、導入ハードルは見た目より高いです。
MAST(Multi-Agent Systems Failure Taxonomy)研究では、7つのオープンソースフレームワークにわたる1,642の実行トレースを分析した結果、失敗率が41%から最大86.7%に達することを報告しています。特に注目すべきは、失敗の最大カテゴリが「調整の崩壊(Coordination Breakdown)」であり、全失敗の36.9%を占めることです。エージェント間のコミュニケーション設計が甘いと、システム全体が脆くなります。
また「モノリス回帰の罠」と呼ばれる問題があります。マルチエージェントに移行したにもかかわらず、すべての意思決定が1つのスーパーバイザーエージェントに集中してしまうケースです。これでは避けようとしていたモノリスアーキテクチャを、エージェントの衣をまとって再現しているに過ぎません。
AWSのアーキテクチャガイドが推奨するのは、以下のような判断基準です。
- 初期段階はモノリス優先:小規模・単一ドメインのタスクはシンプルなモノリスエージェントから始め、デバッグしやすい状態を保つ
- デコンポーズの基準を持つ:ユーザー数増加・タスクの複雑化・専門知識の必要性が明確になった段階でマルチエージェントへ移行する
- 失敗境界の明示的設計:各エージェントが担当するドメイン内の決定に限って自律性を与え、エッジケースは必ず上位エージェントまたは人間にエスカレーションする
- スコープのアーキテクチャ的制約:エージェントが実行可能なアクションの範囲をシステムプロンプトではなくインフラレベルで制限する
失敗境界とスコープの設計は、エラーが発生したときにどこまで波及するかを制御します。これはエージェントシステム特有の課題ではなく、マイクロサービスアーキテクチャで長年議論されてきたサーキットブレーカーパターンと本質的に同じ問いです。
AWS上での実装パターン ― Step FunctionsとBedrock AgentCore
設計思想を実装に落とし込む際、AWSは本番グレードのエージェント運用に必要なコンポーネントをほぼフルスタックで揃えています。
AWS Step Functionsによるオーケストレーション
マルチエージェントシステムの調整層として、Step Functionsは強力な選択肢です。ステートマシンとして定義されたワークフローは、各ステップの成功・失敗・タイムアウトを明示的に扱えます。エラーパスが仕様として可視化されるため、「エージェントが失敗したらどうなるか」をコードとして記述・レビューできます。
たとえば「コードレビューエージェント → セキュリティチェックエージェント → デプロイ判定エージェント」という3ステージのパイプラインをStep Functionsで定義すると、各エージェントの入力・出力・エラー処理が状態遷移図として確認できます。監査証跡も自動生成されます。
Amazon Bedrock AgentCore
2025年7月にGA(一般提供開始)となったBedrock AgentCoreは、エージェントの本番デプロイを支援するマネージドサービスです。主な機能は以下の通りです。
- AgentCore Evaluations:正確性・有用性・安全性など13種類の事前定義評価指標で、本番トラフィックに対してリアルタイムに品質評価を継続実行できます。評価結果の退行を検知してアラートを発火する仕組みも備えています
- AgentCore Identity:IAMと連携した細粒度のアクセス制御。エージェントがどのツール・API・Lambda関数を呼び出せるかをCedar言語で定義します。システムプロンプトへの「〇〇はしないでください」という記述ではなく、インフラレベルのハードコンストレイントとして適用されます
- AgentCore Observability:セッション数・レイテンシー・トークン使用量・エラー率をリアルタイムで追跡するダッシュボード。コンポーネント単位のブレークダウンにより、どのエージェントのどのツール呼び出しでコストが発生しているかを把握できます
AWS Lambdaとのツール統合
エージェントがツールとして呼び出すアクションをLambda関数として実装する設計パターンは、スコープ管理の観点で優れています。Lambda関数単位でIAMロールを割り当てることで、エージェントが持つ権限を最小権限原則に従って制御できます。関数単体でのテスト・監視・デプロイも独立して行えます。
信頼を構築する ― 監査可能性・説明可能性・段階的委任
技術的な信頼性(エラー率・レイテンシー)と、組織的な信頼性(「このエージェントに任せて大丈夫か」という判断)は別の問題です。後者は、ステークホルダーとの関係性・コンプライアンス要件・過去のインシデント対応実績など、定量化しにくい要素で構成されています。
監査可能性の確保
エージェントが何を判断し、何を実行し、何を変更したかを事後的に再現できることは、本番運用の前提条件です。Bedrock AgentCore Observabilityは全インタラクションのトレースを記録し、意思決定の文脈を後から参照できます。これはバグ修正にとどまらず、「このエージェントがなぜこの判断をしたか」をビジネスサイドやコンプライアンス担当者に説明するためにも使われます。
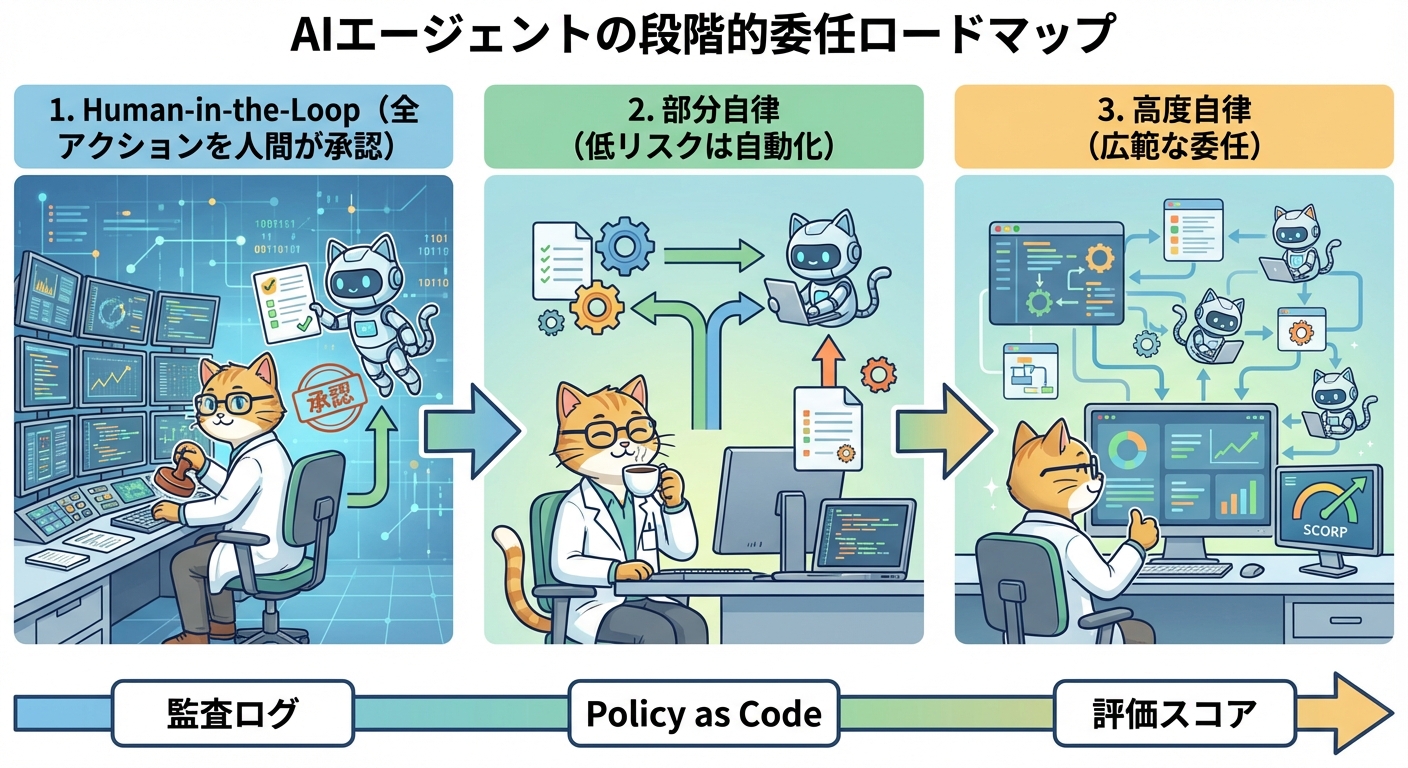
段階的委任のロードマップ
組織がAIエージェントを信頼するプロセスは段階的である必要があります。初期フェーズでは、エージェントはすべてのアクションを実行前に人間が承認するHuman-in-the-Loopモードで動かします。評価メトリクスが一定のしきい値を超えたら、特定カテゴリのアクションを自律化します。さらにデータが蓄積されたら、より高リスクなアクションへと委任範囲を拡大します。
この進め方は、新しいチームメンバーに仕事を任せるプロセスとよく似ています。最初は小さなタスクを任せ、実績が積み重なるにつれて権限を拡大します。エージェントに対しても同じアプローチが機能します。
Policy as Code
Bedrock AgentCore IdentityはCedar言語によるポリシー定義をサポートします。「このエージェントは本番DBに対してREADは許可するがWRITEは禁止」「このエージェントは営業時間内のみSlackに投稿できる」といった条件を、自然言語またはCedarコードで記述し、インフラレベルで強制できます。これにより、セキュリティ・コンプライアンスチームがLLMのプロンプト実装に依存せず、ポリシーを独立して管理・監査できます。
人間の役割の変化 ― コードを書く人からシステムを委任する人へ
AIエージェントの普及が進むにつれ、エンジニアリーダーやテックリードに求められるスキルセットが変化しています。「コードを正しく書く能力」に加えて、「どのタスクをエージェントに委任し、どのタスクを人間が判断するかを設計する能力」が重要になります。
委任の設計:何をエージェントに任せられるかを判断するには、タスクの構造化可能性・失敗コスト・可逆性・監査要件を分析する必要があります。たとえばコードレビューのコメント生成は委任しやすく、本番デプロイのトリガーは高い監視下に置くべきです。
曖昧さの解消:エージェントは曖昧な仕様に対して想定外の動作をすることがあります。エンジニアリーダーの役割として、エージェントへの指示(プロンプト・ポリシー・スコープ定義)を継続的に精緻化し、曖昧さを減らすことが重要です。これは従来の「要件定義」と「テスト設計」の融合した新しいスキルです。
評価フレームワークの設計:エージェントの品質をどう測るかは、プロダクトオーナーとエンジニアリングチームが協働して決めるべき問いです。SWE-benchのような汎用指標ではなく、自社のユースケースに合わせたカスタム評価軸を定義し、継続的に計測する体制が求められます。AgentCore Evaluationsのカスタム評価指標機能はこの用途に使えます。
AIエージェントは、エンジニアを不要にするのではなく、エンジニアの仕事の重心を変えます。実装から判断へ、手作業から設計へ、単発タスクから継続的なシステム改善へ。「コパイロットからコワーカーへ」という移行は、エージェント側の進化だけでなく、それを運用する人間側の進化でもあります。
AIエージェントの本番運用は、まだ多くの組織にとって未踏領域です。しかし、本記事で紹介したような設計原則と評価フレームワークを積み重ねることで、信頼できるエージェントシステムを段階的に構築していくことは十分に可能です。PoC止まりを超えて、本番での価値提供に踏み出すための第一歩として、アーキテクチャの見直しと評価指標の設計から始めてみてください。
























