



米デルは現地時間2026年5月18日、ラスベガスで開催中のDell Technologies World 2026にて、ローカルでAIエージェントを稼働させる新ソリューション「Dell Deskside Agentic AI」を発表しました。NVIDIA Grace Blackwell系チップを搭載するワークステーション群と、NVIDIAのオープンソース・エージェントスタック(NemoClaw/OpenShell/OpenClaw/Nemotron)を組み合わせ、トークン課金や通信レイテンシに縛られないオンプレミス型のエージェント開発・運用環境を提供するという内容です。
Dell Deskside Agentic AIとは何か
Dell Deskside Agentic AIは、既存のDell AI Factory with NVIDIAの延長に位置付けられる新ソリューションで、ワークステーションを核とした「ローカル実行型のエージェント基盤」をパッケージとして提供します。クラウドAPIに頼らずに、データを手元のデバイスから外に出さずにエージェントを構築・テスト・運用できる点が主要な訴求です。
デルはこのソリューションを「データがデバイスを離れないセキュアなサンドボックスで、AIエージェントを構築・テスト・実行・ファインチューニングするためのもの」と位置付けています。想定ターゲットは、ソフトウェアエンジニアリング、学術研究、規制業界の特定チームで、変動するクラウドのトークンコストを「制御可能なインフラ投資」に置き換えたい組織を念頭に置いています。Dell Technologies Worldの会場における基調メッセージでは「Production-Ready Agentic AI from Deskside to Data Center」として、デスクサイドからデータセンターまでを同一スタックで貫く戦略が打ち出されました。
GB10からGB300まで広がるハードウェアラインナップ
ハードウェアは用途規模に応じた3段構成です。下位の試作機から、最上位のデスクサイド・スーパーコンピューターまで、対応するモデルパラメータ数の幅で棲み分けが整理されています。
製品名 | 主要構成 | 対応モデル規模 |
|---|---|---|
Dell Pro Max with GB10 | NVIDIA GB10 Superchip、128GB統合メモリ | 30B〜200B |
Dell Pro Precision 9 Towers | Intel Xeon 600プロセッサ、NVIDIA RTX PRO Blackwell GPUを最大5基 | 30B〜500B |
Dell Pro Max with GB300 | NVIDIA GB300 Grace Blackwell Ultra Desktop Superchip搭載、独自Maxcool冷却 | 120B〜1T |
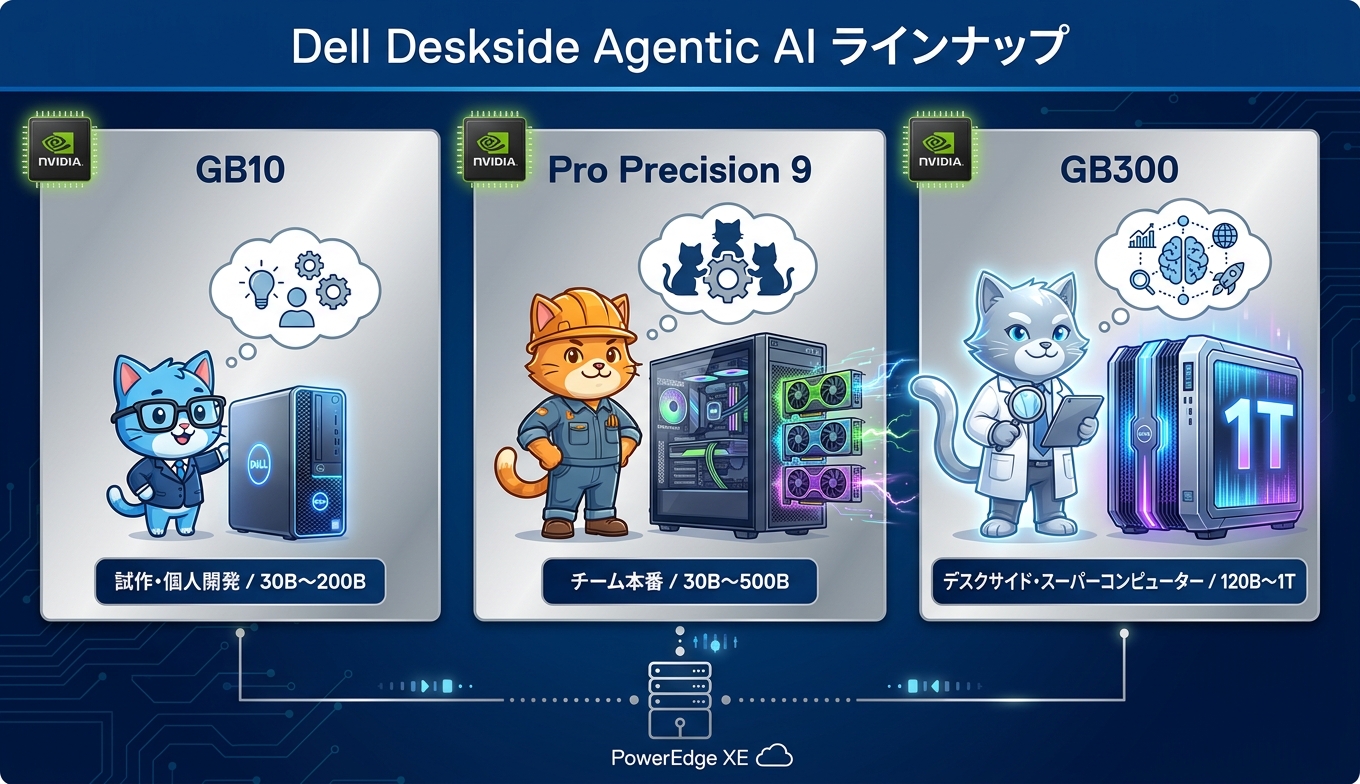
下位機のDell Pro Max with GB10は、コンパクト筐体に統合メモリ128GBを備えた個人向けのエージェント試作機です。中位のPro Precision 9 Towersはチームでの本番ワークロード向けで、RTX PRO Blackwell系GPUを複数基搭載できます。最上位のPro Max with GB300は、いわばデスクサイドに置けるスーパーコンピューターで、最大1兆パラメータ級のモデル推論まで視野に入れた構成です。さらに、データセンター側にはDell PowerEdge XEサーバが連携し、デスクサイドの開発機から本番投入まで同じNVIDIAスタックで滑らかにつなぐ思想になっています。
NemoClawとOpenShellが構成するエージェント実行基盤
ローカルでエージェントを安全に動かすために、Dell Deskside Agentic AIは複数のNVIDIA系オープンソースコンポーネントを束ねています。役割を整理すると次の通りです。
コンポーネント | 役割 |
|---|---|
NVIDIA NemoClaw | OpenClawをNVIDIAデバイス上で最適化展開するためのオープンソース参照スタック |
NVIDIA OpenShell | 常時稼働エージェントのサンドボックス兼ゲートウェイ。資格情報や外部APIアクセスを集中制御 |
OpenClaw | サンドボックス内で動くマルチチャネル・エージェントフレームワーク |
NVIDIA Nemotron 3 | 推論・コーディング用のオープン基盤モデル群(Super 120B、Nano 4Bなど) |
NVIDIA Agent Toolkit | エージェント開発を加速する補助ツール群 |
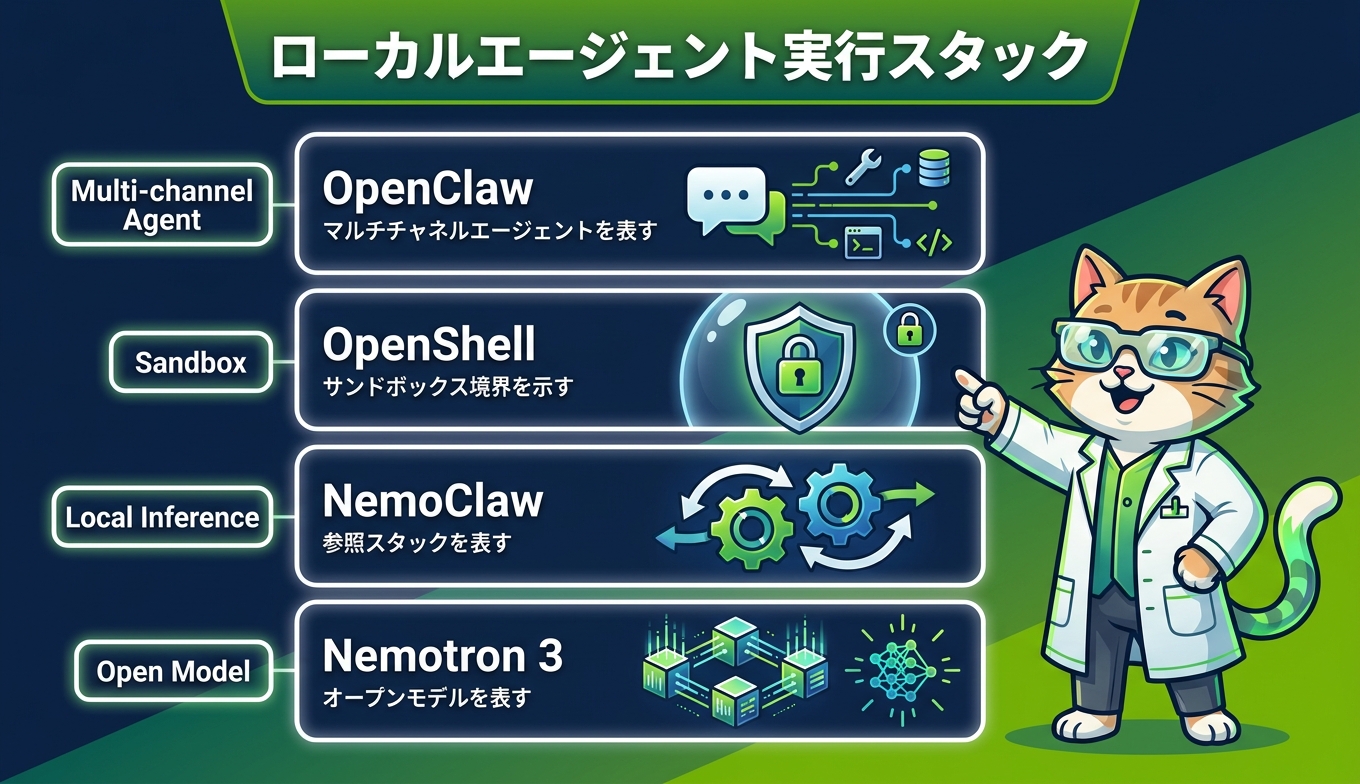
このスタックの肝になるのが、エージェントの行動制約をプロンプトではなく実行環境側で強制するOpenShellです。各エージェントはOpenShellのサンドボックスに閉じ込められ、ネットワーク・ファイルシステム・資格情報といったインフラ層のポリシーが、エージェント本体から触れない場所で適用されます。プロンプト経由でエージェントが乗っ取られても、境界を踏み越えにくい構造です。
デルはここに自社のリファレンスアーキテクチャ「AI-Q 2.0」を組み合わせ、規制業界向けの多段エージェント研究ワークフローを構築する手順を提示しています。Nemotron 3 Super 120Bなどの大型推論モデルだけでなく、Nano系の軽量モデルを補助エージェントに割り当てるマルチエージェント構成も視野に入っています。
トークン課金から固定投資への切り替えを狙う採算モデル
デルが特に強調するのが、エージェント運用コストの構造変化です。変動が読みにくいクラウドAPIのトークン課金から、減価償却で見通しを立てやすいインフラ投資へ置き換えられる点を、次のような数値で訴求しています。
指標 | 公称値 |
|---|---|
クラウドAPI比の損益分岐点 | 最短3か月で到達 |
2年間の累積コスト削減 | 最大87% |
背景にあるのは、常時稼働の自律エージェントがトークンを大量に消費しやすいという最近の利用実態です。デル社内の事例として「24時間で10億トークンを消費し、3,400ドルの請求が発生した開発者」のエピソードが紹介されており、長時間ジョブを走らせるタイプのエージェント運用がクラウドAPIのトークン課金には馴染みづらいことを示唆しています。GB300機のように初期投資が大きい構成でも、エージェントを高稼働で回し続けるユースケースなら、想定的に短期間で元が取れる、というのが今回の数値の趣旨です。
エンジニアが押さえておきたい実装インパクトと論点
エンジニアにとっての要点は、概ね次の三点に整理できます。
第一にモデル選定の自由度です。Nemotron 3系の他、Qwen 3.5やMistral Small 4などのOSSモデルがローカル実行を前提に並ぶため、用途に応じてサイズと精度をすり替えやすくなります。GB10機の128GB統合メモリは30B〜200B規模を、GB300機は1兆パラメータ級までを引き受けるため、プロトタイプから本番までを「同じインタフェース/別容量」で吸収できる構図です。手元のワークステーションで実機検証してから本番のデータセンター側に同じスタックを持ち込めるため、開発と運用の継ぎ目が浅く済みます。
第二にセキュリティ境界の取り扱いです。OpenShellによるサンドボックス+ポリシー強制は、エージェントが暴走または悪用された場合の被害局所化に大きく寄与します。逆に言えば、ポリシー定義そのものを誰がどう管理するのかが新たな運用課題になります。AI-Q 2.0のリファレンスがどこまで実務に耐えるかは、現場での評価が必要で、特に複数エージェントが相互に呼び出すケースのアクセス制御は要注意です。
第三に経済モデルの再設計です。クラウドAPIの「使った分だけ」モデルとローカル機材の減価償却を比較する場合、稼働率、電力、保守費を加味したTCO試算が欠かせません。デルが提示する「3か月で損益分岐」「2年間で最大87%削減」という数値はフルロード前提の試算であり、自社のエージェントが本当にそこまでのトークンを継続的に消費するか、別途の検証が要ります。
生成AIワークロードを再びオンプレに引き戻す動きが本格化する中で、Dell Deskside Agentic AIはローカル実行型エージェントの代表例になりそうです。GB300を搭載したデスクサイド機が手元で回せる時代に備え、エンジニアは「クラウド前提だった設計」を見直す準備を始めても損はないでしょう。
























