


Physical AIとVLAモデルが変えるロボット開発
近年、ロボット工学の世界に大きな変化が訪れています。従来のロボットは「座標Aにアームを移動して、グリッパーを閉じる」というように、細かい動作をすべてルールベースでプログラムする必要がありました。しかし、物体の位置が1cmずれただけで動作が失敗してしまうような脆弱さが課題でした。
この問題を解決しつつあるのが、Physical AIという概念です。Physical AIとは、AIがカメラやセンサーで現実世界を観測し、状況を判断して、ロボットアームや産業アクチュエータを通じて物理的なアクションを実行するシステムです。単なるIoTが「観測」に留まっていたのに対し、Physical AIは「判断」から「行動」までAIが一貫して担います。
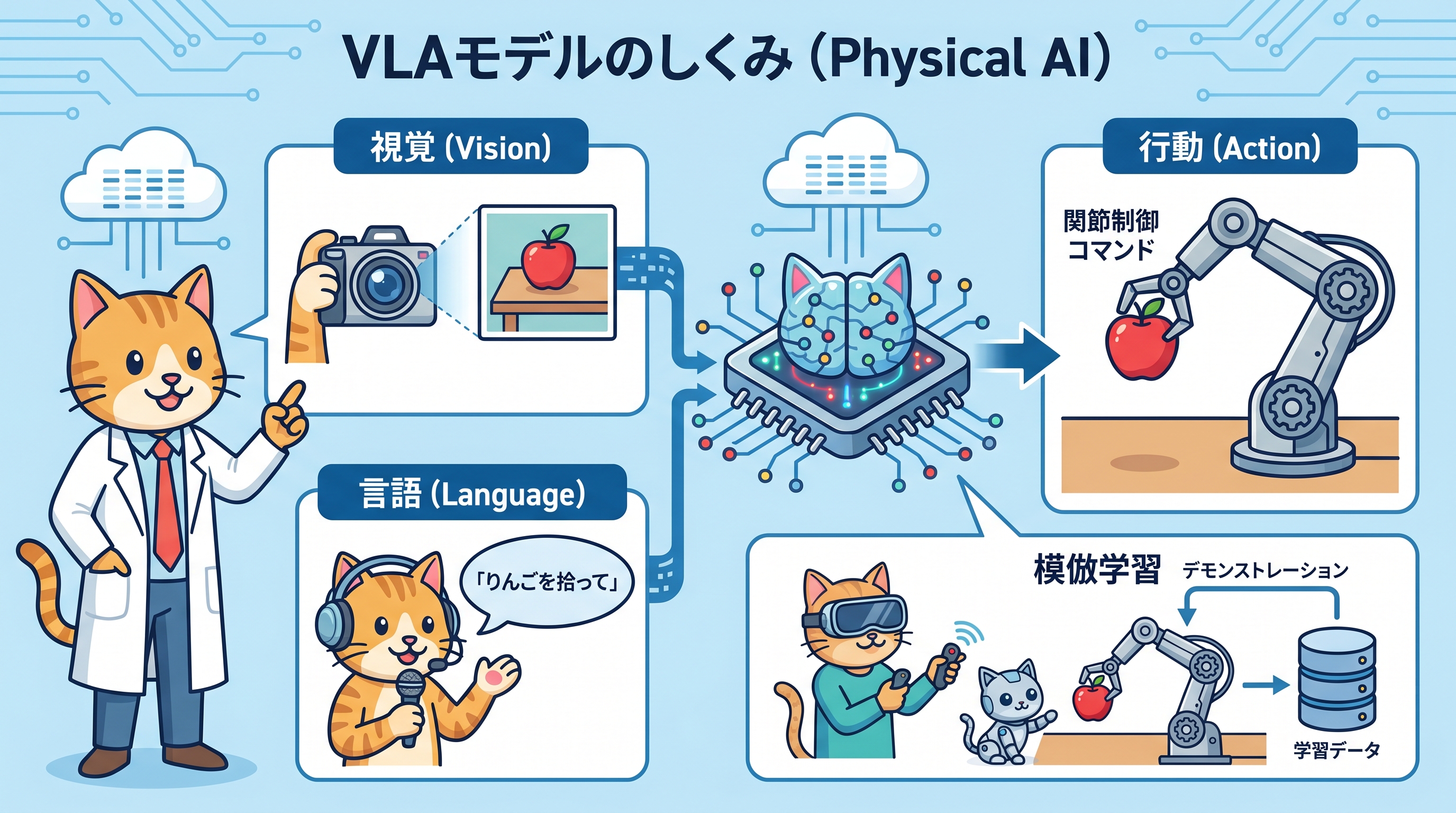
その中心的な技術がVLA(Vision-Language-Action)モデルです。VLAは視覚情報(カメラ映像)・言語情報(自然言語の指示)・行動情報(ロボット制御信号)を統合したモデルで、「赤いりんごを拾ってかごに入れて」という自然言語の指示と、カメラ映像から直接ロボットの関節制御コマンドを生成します。NVIDIA Isaac GR00Tやπ0(Pi Zero)などのVLAモデルが実用段階に入りつつあり、物流倉庫や製造現場での活用が始まっています。
VLAモデルの学習で重要な役割を果たすのが模倣学習(Imitation Learning)です。人間がロボットを遠隔操作してタスクを実演し、その軌跡データをロボットが学習することで、複雑な操作技能を習得させます。GR00T N1.5では、大量の実世界デモンストレーションデータで事前学習されており、少数のファインチューニングデータでも高い性能を発揮します。この模倣学習の品質を左右するのが、収集するデモンストレーションデータの完全性と品質です。
ロボットデータ収集が抱える3つの本質的な課題
模倣学習データの収集は、一見シンプルに思えますが、実際の運用では深刻な課題が3つあります。
課題1 ─ 収集現場の不安定性
ロボットデータの収集は工場・倉庫・病院などのエッジ環境で行われます。これらの現場では、ネットワーク接続が不安定なことが多く、センサーデータの途中断絶が発生しやすい状況です。また、停電や機器の突然のシャットダウンによるデータ損失、書き込み途中でのプロセス終了によるファイル破損など、データの完全性を脅かすリスクが常に存在します。訓練に不完全なデータが混入すると、モデルの精度低下や、最悪の場合は予期しない動作を引き起こす危険性があります。
課題2 ─ クラウド品質判定のコスト
収集したすべてのデータをクラウドに送信して品質を判定する方式では、コストとレイテンシの問題が生じます。ロボット1台が1日に収集するデータ量は数十GBに上ることがあり、複数台のロボットが同時に稼働する環境では、クラウドへの転送コストだけでも膨大になります。さらに、品質が低いデータをクラウドまで送ってから「不要」と判断するのは、完全な無駄です。
課題3 ─ 手動キュレーションの限界
データ量が増えるにつれ、人手による品質確認はスケールしなくなります。「どのエピソードが完全に収集されたか」「どのファイルが壊れているか」を人間が一つひとつ確認することは、大規模なデータ収集では現実的ではありません。自動化されたデータ完全性確認の仕組みが必要です。
データ基盤を支える3つの設計原則
AWSが提案するエッジシステムのアーキテクチャは、上記の課題を解決するために3つの設計原則を採用しています。
原則1 ─ Immutability(不変性)
一度書き込んだデータは変更しないという原則です。エピソードのデータファイルが完全に収集された後は、そのファイルを上書きや削除をしません。品質に問題があった場合は、既存のエピソードを修正するのではなく、新しいエピソードを作成します。この原則により、データの破損・改ざんを防ぎ、任意の時点でのデータセット状態を再現できる信頼性が生まれます。
原則2 ─ Content-Addressed Storage(コンテンツアドレスストレージ)
ファイルをファイル名ではなく、コンテンツのハッシュ値(SHA-256など)でアドレッシングする原則です。同じ内容のデータは同じアドレスを持つため、重複ストレージを防ぎ、かつデータの整合性を自動的に検証できます。ファイルが1ビットでも変化すれば異なるハッシュ値になるため、転送中のデータ破損も検知できます。
原則3 ─ Event-Driven(イベント駆動)
データの書き込みや状態変化をイベントとして扱い、下流の処理をそのイベントに反応させる原則です。ポーリング(定期的な状態確認)に比べて、リソース効率が高く、処理のレイテンシも低く抑えられます。S3へのファイルアップロードをトリガーに、Lambda関数を起動してクラウド側の処理を開始するパターンがその典型例です。
エッジでデータ完全性を担保する実装パターン
これらの設計原則を具体的に実装するため、システムは3つのプロセスで構成されます。
Collector(収集プロセス)は、ロボットのセンサー(カメラ・関節センサー・グリッパー等)からリアルタイムにデータを収集し、エッジのローカルストレージに書き込みます。rawフォーマット(apto-raw-v5)は、1エピソードを1ディレクトリとして管理し、カメラ画像・関節状態・タイムスタンプなどを構造化して保存します。
Sync(同期プロセス)は、エッジのローカルストレージからS3へのデータ転送を担当します。完全に収集が完了したエピソードのみを転送することが重要で、転送中断が起きても再開できる耐障害性が求められます。
Storage(ストレージプロセス)は、S3上でのデータ整理やインデックス管理を行います。どのエピソードがどのロボット・どのタスク・どの日時に収集されたかを管理し、訓練パイプラインが必要なデータを効率的に取得できるようにします。
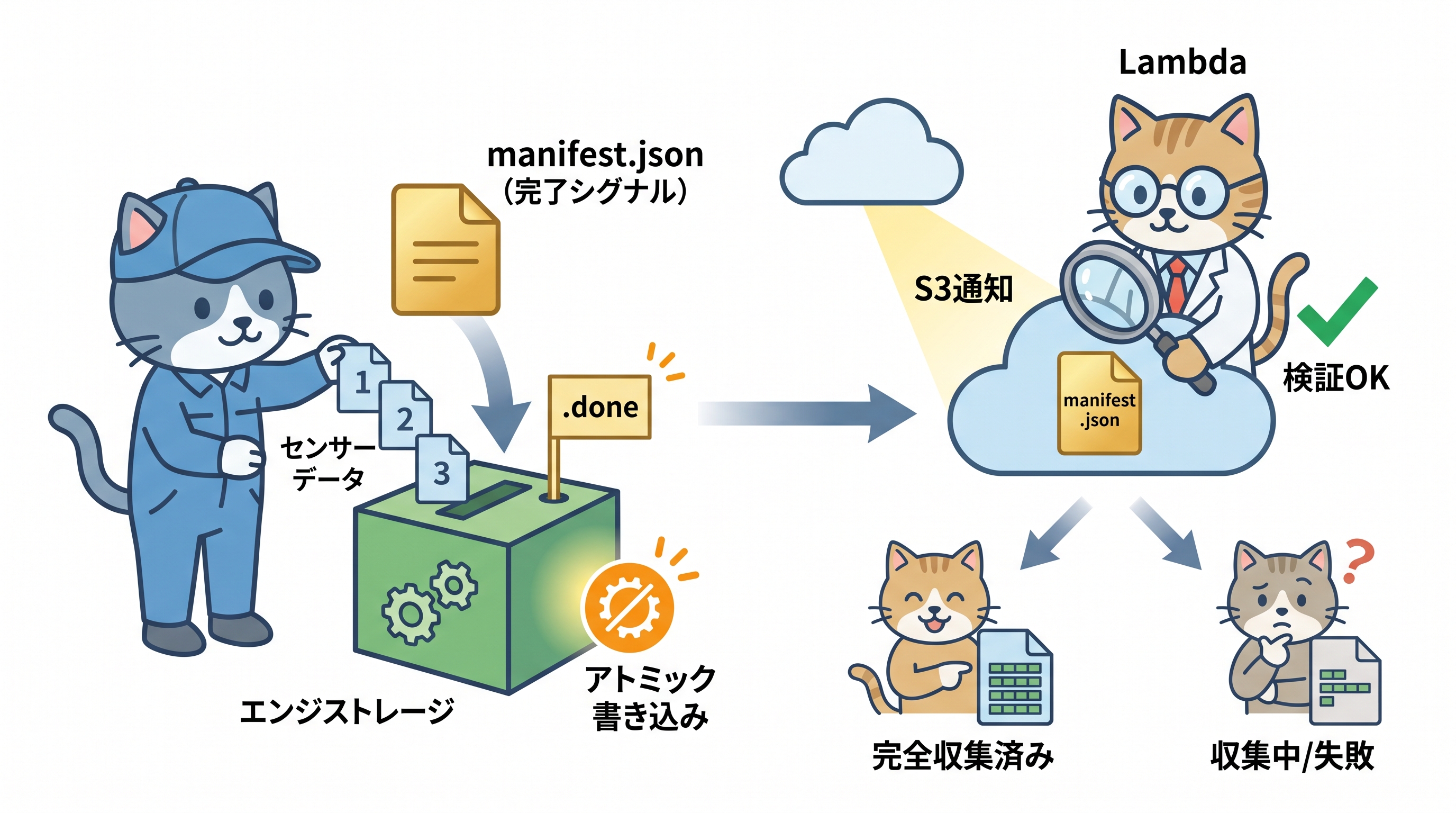
ここで最も重要な設計パターンが「manifest.jsonを最後にPUTする」というアトミック書き込みです。1エピソードのデータ(カメラ映像・センサーデータ等)を書き込んだ後、最後に必ずmanifest.jsonを書き込みます。
manifest.jsonには、エピソードに含まれるすべてのファイルの一覧・ハッシュ値・タイムスタンプが記録されています。下流システムはmanifest.jsonの存在を確認するだけで、「このエピソードは完全に収集が完了した」と判断できます。manifest.jsonが存在しない場合は「収集中」または「収集失敗」とみなして処理を保留します。
S3 Event Notificationsで実現するイベント駆動パイプライン
エッジでの完全性担保と合わせて、クラウド側との連携にはS3 Event Notificationsが活用されます。
.done/.failedセンチネルファイルによる完了判定も重要なパターンです。エピソード収集が正常完了した場合は`.done`ファイルを、何らかのエラーで失敗した場合は`.failed`ファイルをディレクトリ内に配置します。センチネルファイルは中身ではなく「存在する/しない」だけで状態を表現するため、軽量で確実な状態管理が実現できます。
S3にmanifest.jsonや.doneファイルがアップロードされると、S3 Event NotificationsがLambda関数をトリガーします。Lambda関数はmanifest.jsonを読み込んでエピソードの整合性チェック(ファイル数・ハッシュ値の検証)を行い、問題がなければ訓練キューに追加します。この一連の流れがすべてイベント駆動で自動化されることで、人手によるキュレーションを最小化できます。
このアーキテクチャの利点は、エッジとクラウドの責任を明確に分離できることです。エッジは「完全性の確定」に責任を持ち、クラウドは「品質の判定と管理」に責任を持ちます。エッジ側が「これは完全なエピソードである」と保証してからS3に送ることで、クラウド側での無駄な処理や誤判定が減ります。
また、S3の強整合性(Strong Consistency)も重要な前提です。S3はPUTオペレーション後の読み取りで、常に最新の状態を返します。manifest.jsonをPUTした後、すぐにそのファイルをGETしても古い状態が返ることはありません。この保証があるからこそ、「manifest.jsonが存在する = エピソード完全収集済み」という判定ロジックが信頼できます。
Physical AIデータ基盤設計から得られるエンジニアリングの知見
今回解説したPhysical AIデータ収集基盤の設計思想は、ロボット開発に限らず、幅広いエンジニアリングに応用できる普遍的な知見を含んでいます。
エッジでの完全性確定という考え方は、特に重要です。「とりあえず送ってクラウドで判断する」というアプローチは、コストが高く、品質の低いデータが混入するリスクがあります。エッジで完全性を確定してから送ることで、クラウドのリソースを高付加価値な処理(品質評価・特徴抽出・モデル訓練)に集中させることができます。
アトミックな状態遷移のシグナリングも汎用性の高いパターンです。「ファイルの存在/非存在でステートを表現する」「最後に書き込まれるファイルが完了のシグナルになる」というパターンは、分散システムの状態管理において広く使われています。データベースのトランザクションが難しいファイルシステムやオブジェクトストレージ上での操作に特に有効です。
Content-Addressed StorageとImmutabilityの組み合わせは、データの信頼性と再現性を担保するための黄金律です。どのモデルがどのデータで訓練されたかを追跡できるLineage(系譜)管理はMLOpsの基本であり、その基盤となるのがデータの不変性とコンテンツベースのアドレッシングです。
Physical AIはまだ発展途上の分野ですが、AWSのブログで紹介されているこのようなデータ基盤の設計思想は、VLAモデルの訓練品質を大きく左右します。ロボットの「脳」となるAIモデルの学習データが不完全であれば、どれほど優れたモデルアーキテクチャを使っても、現実世界での信頼性は保証できません。エッジシステムでのデータ完全性の担保は、Physical AIの信頼性の礎となる重要な技術課題です。
Ragateでは、AWSを活用したエッジ・クラウド連携アーキテクチャの設計・実装を支援しています。Physical AI関連の基盤構築や、エッジデバイスとクラウドのデータパイプライン構築についてご相談がございましたら、ぜひお気軽にお問い合わせください。
























