


AWS Advanced JDBC Wrapperの新機能「Remote Query Cache Plugin」を使うと、SQLヒントを追加するだけでJDBCクエリ結果をAmazon ElastiCache for Valkeyに自動キャッシュできます。本記事では、既存アプリケーションに最小限の変更で導入する方法と、段階的にパフォーマンス改善を進めるアプローチを解説します。
クエリキャッシュ導入の課題とRemote Query Cache Plugin
データベースの読み取り負荷を軽減するため、クエリ結果をキャッシュする手法は広く採用されています。しかし、これまでの実装にはいくつかの課題がありました。
最大の負担は、キャッシュレイヤーを自前で構築・運用することです。ValkeyやRedisのクライアントライブラリを導入し、クエリごとにキャッシュの確認、結果のシリアライズ、キャッシュへの格納、有効期限管理、エラーハンドリングを記述する必要があります。データベースアクセスを行う箇所すべてにこのロジックを組み込むのは、開発・保守コストが大きく、「後からキャッシュを追加したい」というニーズに応えるのが困難でした。
2026年3月に発表されたAWS Advanced JDBC WrapperのRemote Query Cache Pluginは、この課題を根本から解決します。JDBCクエリを透過的にインターセプトし、キャッシュ処理を自動化するのです。アプリケーション側で必要な変更は、キャッシュ対象とするクエリにSQLヒントを付加するだけです。
Remote Query Cache Pluginの仕組み
Remote Query Cache Pluginは、JDBCドライバとデータベースの間に位置し、クエリと結果を透過的に処理します。具体的な動作フローを見てみましょう。
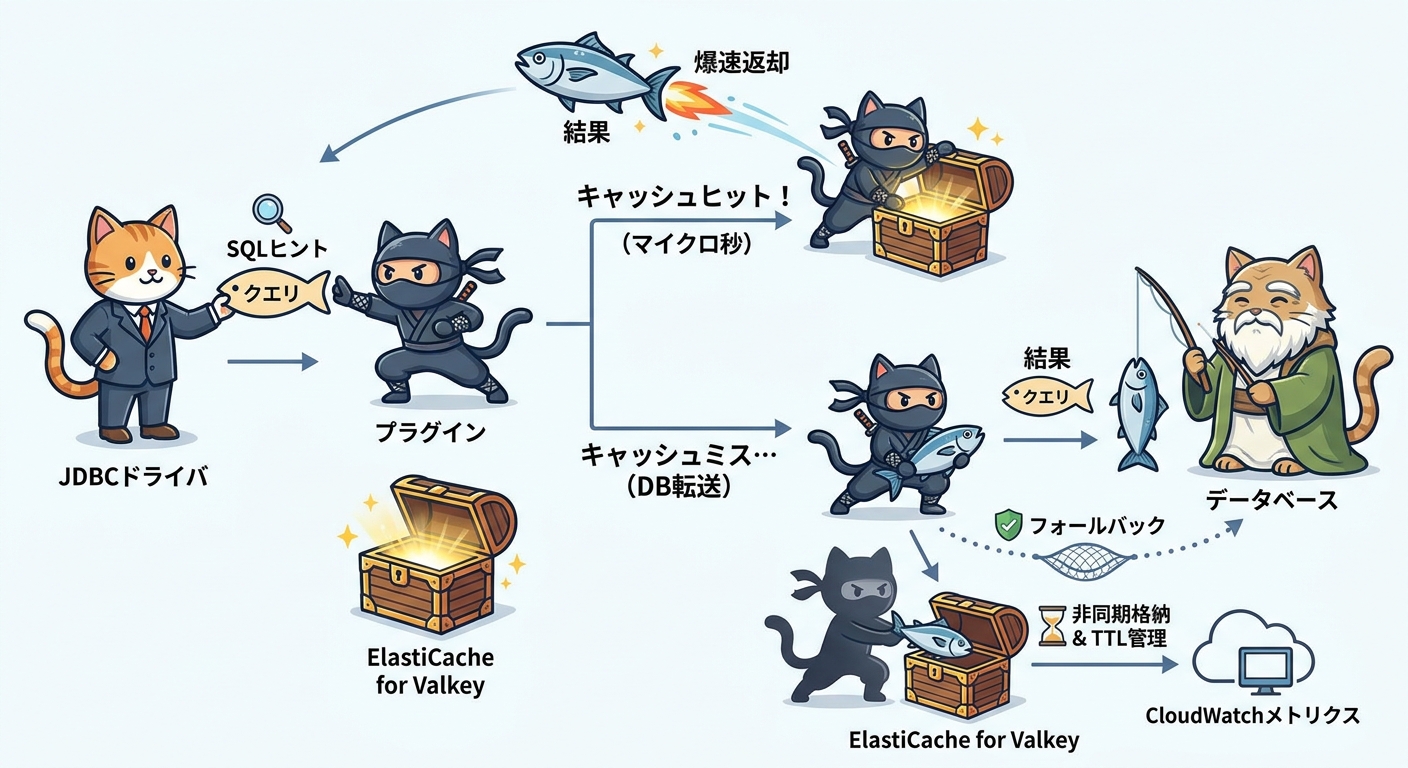
アプリケーションがSQLヒント付きのクエリを実行すると、プラグインはまずキャッシュを確認します。Amazon ElastiCache for Valkeyにキャッシュが存在すれば、マイクロ秒単位で結果を返却し、データベースへのアクセスをスキップします。キャッシュが存在しない場合は、データベースにクエリを転送し、結果を取得した後に非同期でキャッシュに格納します。
この一連の処理はすべてバックグラウンドで行われます。開発者はSQLヒントを付けるだけで、キャッシュの確認、結果のシリアライズ、キャッシュキーの生成、有効期限管理、エラーハンドリングをプラグインに任せられます。
特に注目すべき機能として、以下が挙げられます。
- TTLによる有効期限管理:クエリごとにキャッシュの有効期間を設定できます
- 自動フォールバック:キャッシュが利用不可能な場合はデータベースにクエリを転送し、サービス継続性を確保します
- CloudWatchメトリクス:キャッシュヒット率、ミス回数、バイパスイベント、ヘルスチェック状況を自動的にCloudWatchに送信します
- 既存フレームワークとの互換性:Spring Data JPA、Hibernate、Spring JDBC Template、ネイティブJDBCなど、使い慣れたパターンをそのまま活用できます
導入手順の3ステップ
Remote Query Cache Pluginの導入は、依存関係の追加、接続設定の更新、SQLヒントの付加という3つのステップで完了します。
ステップ1:依存関係の追加
Mavenの場合、以下の依存関係を追加します。バージョン4.0.1以降が必要です。
<dependency>
<groupId>software.amazon.jdbc</groupId>
<artifactId>aws-advanced-jdbc-wrapper</artifactId>
<version>4.0.1</version>
</dependency>Gradleの場合はimplementation宣言で追加します。
implementation 'software.amazon.jdbc:aws-advanced-jdbc-wrapper:4.0.1'ステップ2:接続設定の更新
データベース接続URLに、プラグイン有効化とキャッシュ設定を追加します。JDBC URLにクエリパラメータ形式で設定を記述します。
jdbc:aws-wrapper:postgresql://mydb.cluster-xxx.ap-northeast-1.rds.amazonaws.com:5432/mydb?wrapperPlugins=remoteQueryCache&cacheEndpointAddrRw=mycache.xxxxxx.apne1.cache.amazonaws.com&cacheUseSSL=true主要な設定プロパティは以下の通りです。
- wrapperPlugins=remoteQueryCache:Remote Query Cache Pluginを有効にします
- cacheEndpointAddrRw:ElastiCache for Valkeyの読み書きエンドポイントを指定します
- cacheName:クラスター名を指定します(IAM認証を使用する場合)
- cacheUsername:キャッシュのユーザー名を指定します(ElastiCache Serverlessの場合は「default」を使用)
- cacheIamRegion:IAM認証用のAWSリージョンを指定します
- cacheUseSSL=true:アプリケーションとElastiCache間の通信をTLSで暗号化します。すべての環境でtrueに設定すべきです
キャッシュ環境としては、Amazon ElastiCache Serverlessの利用が推奨されています。インフラ管理が不要で、自動スケーリングと高可用性が組み込まれているためです。
ステップ3:対象クエリへのSQLヒントの追加
キャッシュ対象としたいクエリに、TTLを指定したSQLヒントを付加します。構文はSELECT文の先頭に「CACHE_PARAM(ttl=期間)」を追加する形式です。
SELECT /* CACHE_PARAM(ttl=60s) */ * FROM products WHERE category_id = 100;TTLは秒(s)、分(m)、時間(h)などで指定できます。データの更新頻度に応じて適切な値を設定してください。
キャッシュ候補クエリの特定方法
すべてのクエリがキャッシュに適しているわけではありません。キャッシュの恩恵を最大限に受けるには、適切なクエリを選定する必要があります。
Amazon AuroraやRDSであれば、CloudWatch Database Insightsを使って負荷の高いクエリを特定できます。AWS CLIのdescribe-dimension-keysコマンドを実行すると、db.load.avg(平均アクティブセッション)でランク付けされた上位クエリ一覧が取得できます。
キャッシュ候補として評価すべきシグナルは以下の通りです。
- 高いdb.load.avg:データベース負荷に大きく貢献しているクエリ
- SELECT文:読み取り専用クエリのみがキャッシュの対象です
- 安定した結果セット:データが頻繁に変わらない、あるいはTTL期間中の変更を許容できるクエリ
- 繰り返し実行:1分間に何度も実行されるクエリは、キャッシュの効果が大きいです
例えば、マスタデータの参照、カタログ表示、レポート生成などは良好なキャッシュ候補です。一方、リアルタイム性が求められる在庫確認や、ユーザーごとに結果が異なるパーソナライズ検索は、慎重に検討が必要です。
Ragateが推奨する「小さく確実な」導入アプローチ
Remote Query Cache Pluginの最大の魅力は、既存アプリケーションへの後付け導入が容易なことです。私たちRagateが提唱する「小さく確実な」クラウドネイティブ移行のアプローチに、非常に親和性が高い機能です。

具体的な導入ステップを提案します。
1. 分析から開始する
まず、CloudWatch Database Insightsでデータベース負荷の状況を把握します。どのクエリが負荷の大半を占めているか、その実行頻度と結果の安定性を確認してください。
2. 小さく始める
負荷上位1〜2クエリに対してのみSQLヒントを追加し、本番環境で効果を観察します。いきなり多くのクエリを対象にせず、影響範囲を限定することで、問題発生時の切り分けが容易になります。
3. CloudWatchで効果測定する
プラグインが送信するCloudWatchメトリクスで、キャッシュヒット率とデータベース負荷の変化をモニタリングします。期待通りの効果が出ていれば、徐々に対象クエリを拡大します。
4. TTLを調整する
データの鮮度要件とパフォーマンス効果のバランスを取りながら、TTL値を調整します。最初は短めに設定し、問題なければ徐々に延ばすのが安全です。
5. ロールバックの準備
何か問題が発生した場合、接続URLからプラグイン設定を削除し、SQLヒントを取り除くだけで、元の状態に戻せます。この「安全に撤退できる」特性が、後付け導入を現実的なものにしています。
クエリキャッシュの導入は、本来であればアプリケーションアーキテクチャの変更を伴う大きな施法です。しかし、Remote Query Cache Pluginを使えば、「SQLヒントを追加する」という小さな変更で、段階的に効果を確認しながら導入を進められます。
データベースの読み取り負荷にお悩みの方は、まずCloudWatch Database Insightsで現状を分析し、1つのクエリから試してみてはいかがでしょうか。
























