



2025年に NVD(National Vulnerability Database)へ公開された CVE は48,000件を超えました。膨大な脆弱性情報に対し、人手で検出ルールを書き起こす運用は限界に近づいています。AWS は2026年6月、Amazon CISO の C. J. Moses 氏による寄稿記事「How Amazon uses agentic AI for vulnerability detection at global scale」を日本語ブログでも公開し、Amazon 社内で運用しているエージェンティック AI システム「RuleForge」の中身を明らかにしました。本記事では、RuleForge の仕組みと、誤検知67%削減・ルール生成336%高速化といった成果がどのように生まれているかを、エンジニア視点で整理してお伝えします。
RuleForge が解決する脆弱性検出のスケール問題
RuleForge は、AWS が「脆弱性を悪用するコードのサンプルから直接検出ルールを生成するエージェンティック AI システム」と説明する自社運用システムです。新たに公開された CVE(Common Vulnerabilities and Exposures)や PoC(Proof of Concept)コードを取り込み、Amazon の内部検出システムが利用する本番品質の検出ルールを自動生成します。
従来、セキュリティアナリストは PoC を解析し、誤検知を抑えながら脅威を捉えるルールを手作業で書き上げてきました。一件あたりの作業量が大きく、CVE 公開から実環境への適用までに数日〜数週間を要する場合もありました。Amazon は、この「公開から防御開始までの空白期間」を埋めるために、単一の大規模モデルにすべてを任せるのではなく、複数の特化エージェントが取り込み・生成・評価・検証を分担し、最終ゲートを人間が担うエージェンティック型のアプローチを採用しました。AWS の発表によると、このパイプラインで RuleForge は手動プロセスと比較して336%速く本番環境向けの検出ルールを生成しているとのことです。
注目すべきは、336%という数値が単なるベンチマーク値ではなく、Amazon の本番セキュリティ運用で達成された実測値である点です。新規 CVE が日々増え続ける状況で、防御側が攻撃者と同じ速度感で対応するための土台として機能しています。
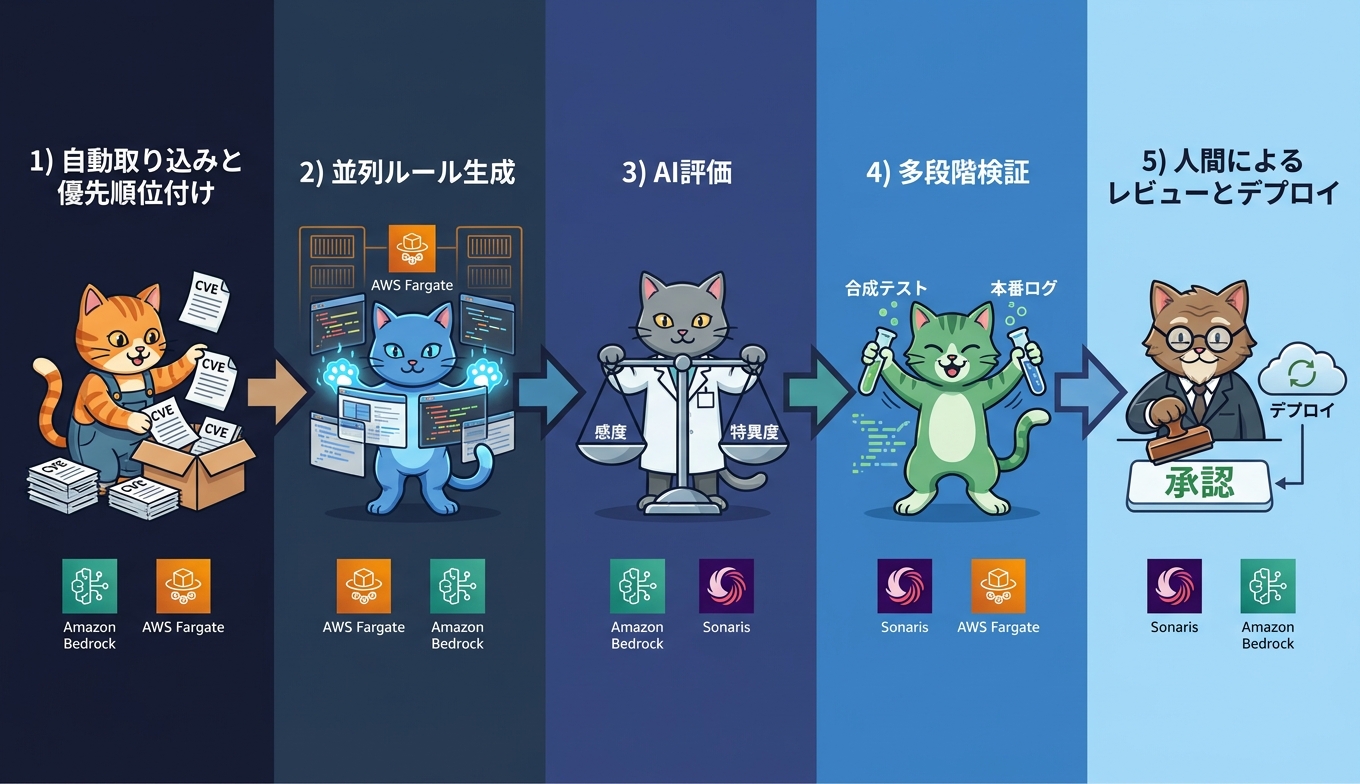
5段階パイプラインの全体像
RuleForge は5段階のパイプラインで動作します。各段階で異なる役割のエージェントやモデル、検証基盤が組み合わされる点が特徴です。
- 自動取り込みと優先順位付け - 公開された CVE や PoC コードを継続的に取得し、悪用可能性や影響範囲をもとにスコア化します
- 並列ルール生成 - AWS Fargate 上で複数の候補ルールを同時に生成し、Amazon Bedrock のモデルを活用して文法面と検知ロジックの多様性を確保します
- AI を活用した評価 - 別系統で動作する「ジャッジモデル」が、感度(検知漏れの少なさ)と特異度(誤検知の少なさ)の2軸で候補ルールをスコアリングします
- 多段階検証 - 合成テストデータでの動作確認、続いて本物のトラフィックログを用いた検証へ段階的に進みます
- 人間によるレビューとデプロイ - セキュリティエンジニアが最終承認したルールのみが本番投入されます
Amazon Bedrock がルール生成の知能面を、AWS Fargate が並列実行のスケールアウト面を担う構成は、エージェンティックワークフローを本番運用へ落とし込む際の参考になります。
ジャッジモデルが誤検知を67%削減
記事の中で特に示唆に富むのが、ジャッジモデルの設計に関する考察です。Amazon は当初、ルールを生成したモデル自身に品質を自己評価させていましたが、生成元モデルは自分の出力を過大評価する傾向があり、品質ゲートとしては機能しませんでした。そこで、独立した別のモデルを「ジャッジ」として配置し、感度と特異度を分離して採点する設計に切り替えています。
さらに、プロンプト設計では「このルールはどの程度の確率で攻撃を検知できるか」という肯定的な問い方よりも、「このルールはどの程度の確率で攻撃を検知できないか」と否定的な表現で問う方が、見落としの抽出に有効であることが判明したと述べられています。ドメイン固有の専門用語を詰め込んだ長文プロンプトよりも、否定形の単純な問いの方が精度が高かったという経験則は、社内 LLM 活用にも転用しやすいヒントです。
こうしたジャッジモデルの導入により、RuleForge は誤検知を67%削減しました。さらに、AI ジャッジの推論チェーンを人間の専門家の推論と突き合わせた評価では、9つのルールのうち6つで両者の論理が一致したと報告されています。エージェントの判断根拠を可視化し、人間の判断軸とすり合わせるプロセスが、信頼度の積み上げに直結しています。
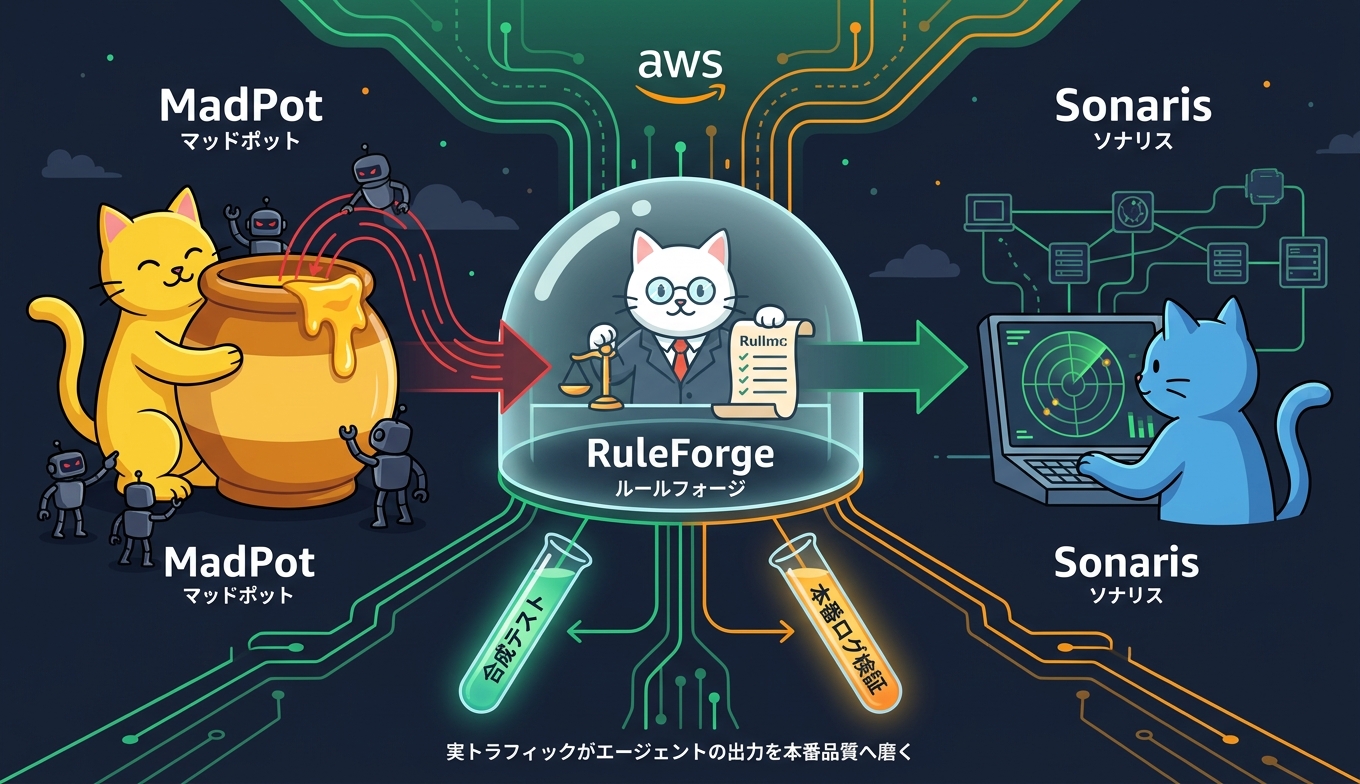
MadPot と Sonaris が支える検証フロー
RuleForge が生成するルールは、最終的に Amazon の内部検出システムへ供給されますが、その品質を裏付けているのが既存の検証インフラです。Amazon は、デジタルおとりを用いて悪意あるアクターの挙動を捕捉する世界規模のハニーポットシステム「MadPot」と、社内検出システム「Sonaris」を運用しており、RuleForge はこれらが収集する実世界のトラフィックデータを活用してルールを多段階で検証します。
合成テストだけでは検知できない実環境特有の挙動を、MadPot 由来のトラフィックで再現する流れです。生成 AI が量を担い、ハニーポットと社内検出系が現実適合性を担うという役割分担は、AI 主導のセキュリティ自動化が単独で完結しない、現実的な姿を示しています。長期間にわたり蓄積された実トラフィックという資産があってこそ、生成系エージェントの出力を本番品質まで磨き込めるという構図がよく分かります。
AWS は2025年8月に信頼度スコアリングシステムをデプロイし、アナリストが新しい検出ルールをデプロイする速度をさらに加速させたと述べています。生成ルールへの確信度を可視化することで、スコアの高いルールはレビュー負荷を抑え、低いものは人間によるレビューを厚くするといった、運用効率と品質の両立を支える仕組みです。
Human-in-the-loop が残るハイブリッド設計の示唆
RuleForge は高い自動化率を達成していますが、Amazon は本番デプロイ前の最終ゲートを人間に残しています。エージェント主導の高速生成と、人間のレビューによる最終判断を組み合わせるハイブリッド構造です。AI に置き換えるのではなく、AI が大量の選別作業をこなし、人間がよりクリティカルな判断に集中できる体制を作る発想が貫かれています。
システム部門や情報システム部門で同様の取り組みを検討する際にも、ジャッジモデルの分離、否定形プロンプトの活用、ハニーポットや本番ログでの段階検証、最終ゲートに人間を残す設計は、そのまま転用できる原則です。生成 AI を本番ワークフローへ組み込む際は、生成と評価の役割分離、現実データでの多段階検証、Human-in-the-loop の3点を押さえる設計が、Amazon の事例から見えてくる実践的なアプローチと言えます。Ragate でもこうした設計知見を、お客様のクラウドセキュリティ・運用自動化のご相談に活用してまいります。
























