



2026年5月14日、AWS Japan Blogで「Amazon Aurora DSQL での変更データキャプチャ入門」が公開され、Amazon Aurora DSQLにChange Data Capture(CDC)機能がパブリックプレビューで追加されました。サーバーレスでスケールする分散SQLデータベースに、行レベル変更をストリーム化して下流へ流す仕組みが組み込まれた格好です。本記事では、サーバーレス・データ密集型システムを運用するAWSエンジニア向けに、Aurora DSQL CDCの仕組み、Kinesis Data Streamsへの構成手順、変更イベントの読み方、代表的なユースケースまでを入門目線で整理します。
なお、本機能は執筆時点でパブリックプレビューです。本記事のコマンド・JSONスキーマは公式ブログ記載の内容に厳密準拠しますが、一般提供(GA)時にセマンティクスが変更される可能性がある点を前提として読み進めてください。
Aurora DSQL CDC とは何か
Amazon Aurora DSQLは、PostgreSQL互換のAPIを持ちながら、サーバーレスで水平スケールし、マルチリージョン強整合性を実現する分散SQLデータベースです。今回プレビューに加わったCDC機能は、このDSQLクラスター上で発生する行レベルの変更(INSERT、UPDATE、DELETE)を捕捉し、外部システムで利用可能なイベントとして配信する仕組みです。
CDCはDSQLのトランザクション処理とは独立してバックグラウンドで動作するため、本体ワークロードの応答性に影響を与えません。現時点ではクラスター単位で稼働し、対象クラスター内のすべてのテーブルの変更を取り扱います。特定のテーブルのみに絞り込むフィルタリングは下流側で実装する設計です。
ストリームの単位は「CDCストリーム」と呼ばれ、DSQLクラスターごとに接続先と配信オプションを指定して作成します。マルチリージョン構成では、各リージョンに対して別々のストリームを構成します。
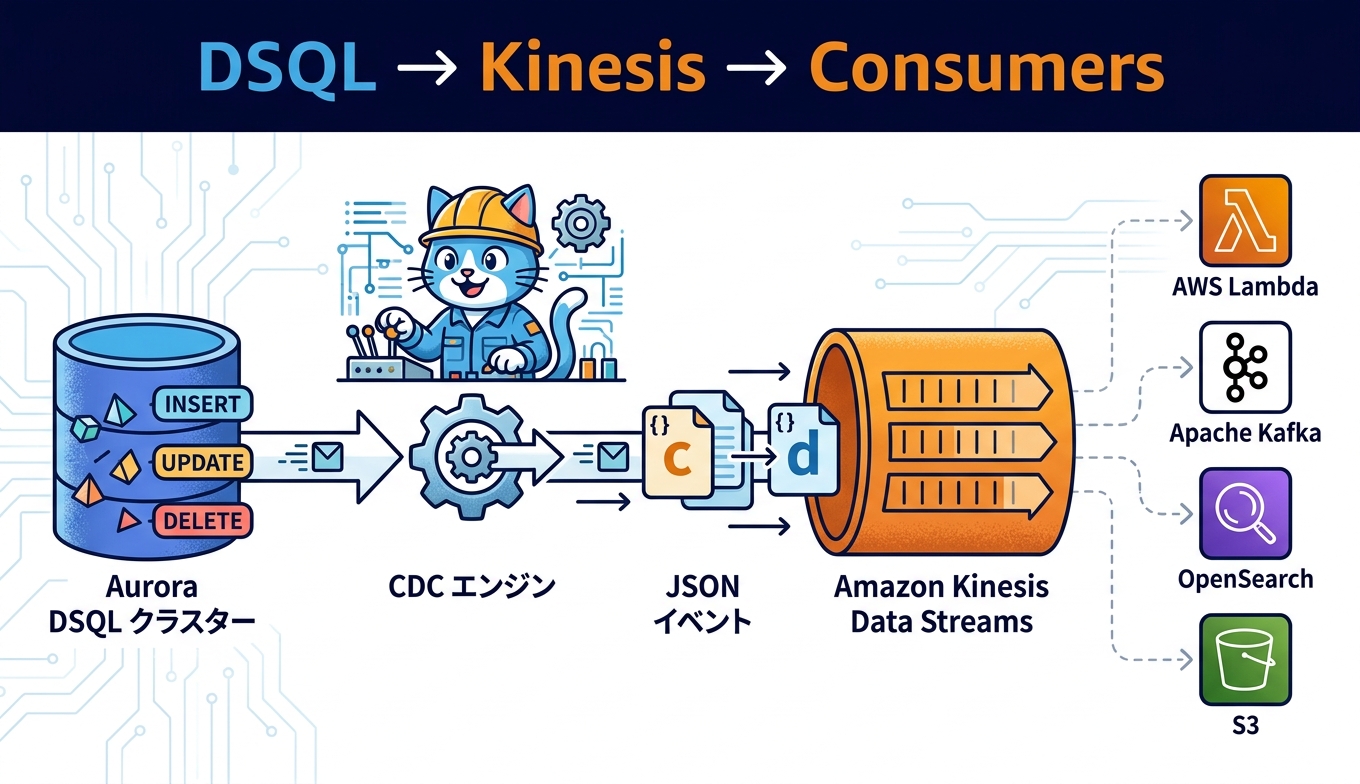
アーキテクチャと配信先 Kinesis Data Streams
プレビュー時点でAurora DSQL CDCがサポートする配信先はAmazon Kinesis Data Streamsです。DSQLクラスターで発生した変更はJSONイベントへ変換されてKinesisストリームへ書き込まれ、下流コンシューマーとしてはAWS Lambda、Kinesis Data Firehose、Apache Flinkが利用できます。さらにその先で Apache Kafka など他のメッセージングへ橋渡しする構成も取れます。
Kinesis側の前提として、Aurora DSQLは行サイズが最大2MiBまで対応するため、Kinesisストリームも2MiB級のレコードを受け入れられる設定にしておきます。具体的にはaws kinesis create-streamで--max-record-size-in-ki-b 2024を指定し、必要に応じてON_DEMANDモードでスケールに任せる構成が扱いやすいです。
CDCストリームを作る最小手順
CDCを動かすまでの最短ルートは、Kinesisストリーム作成、IAMロール作成、CDCストリーム作成の3ステップです。それぞれ要点を整理します。
Kinesisストリームの準備
まず、変更イベントの受け皿となるKinesisストリームを作成します。最大2MiBの行サイズに対応する点を忘れずに指定します。
aws kinesis create-stream \
--stream-name ${KINESIS_STREAM_NAME} \
--stream-mode-details StreamMode=ON_DEMAND \
--max-record-size-in-ki-b 2024 \
--region ${REGION}IAMロールの準備
次に、DSQLサービスがKinesisストリームへ書き込むためのIAMロールを用意します。信頼ポリシーのプリンシパルはdsql.amazonaws.comです。Confused Deputy対策として、aws:SourceAccountとaws:SourceArnでアカウントとクラスターARNを限定しておきます。
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Principal": { "Service": "dsql.amazonaws.com" },
"Action": "sts:AssumeRole",
"Condition": {
"StringEquals": { "aws:SourceAccount": "${ACCOUNT_ID}" },
"ArnEquals": { "aws:SourceArn": "arn:aws:dsql:${REGION}:${ACCOUNT_ID}:cluster/*" }
}
}
]
}CDCストリームの作成と状態確認
準備が整ったら、DSQLクラスターとKinesisストリームを結ぶCDCストリームを作成します。--orderingは現状UNORDEREDを指定します。
aws dsql create-stream \
--cluster-identifier ${CLUSTER_ID} \
--target-definition "{\"kinesis\":{\"streamArn\":\"${KINESIS_STREAM_ARN}\",\"roleArn\":\"${CDC_ROLE_ARN}\"}}" \
--ordering UNORDERED \
--region ${REGION} \
--format JSON作成したストリームがACTIVEになっているかはaws dsql get-streamで確認できます。後始末にはaws dsql delete-streamを使います。CDCストリームがアクティブになった状態でテーブルへ変更を加えると、Kinesisに対応するレコードが流れ始めます。
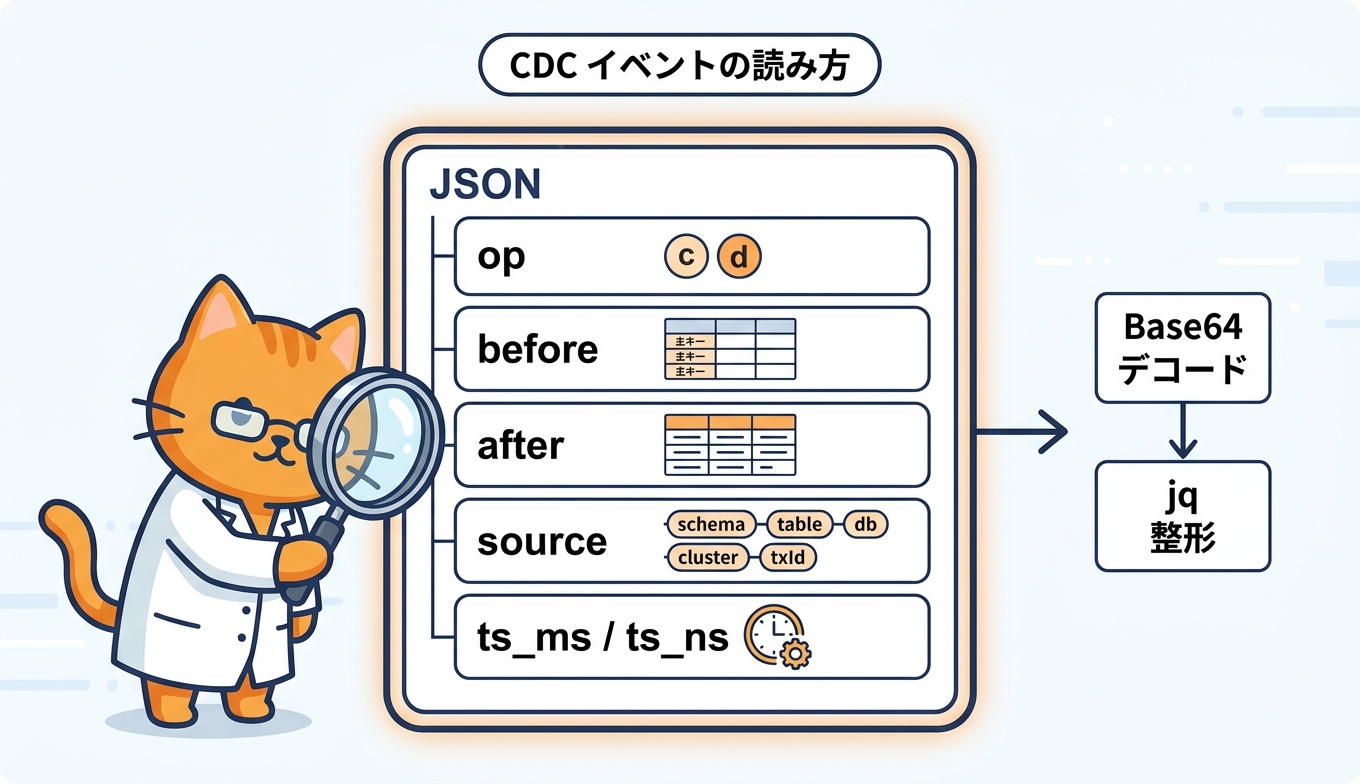
変更イベントJSONの読み方
Kinesisに格納されたCDCレコードはBase64エンコードされており、aws kinesis get-recordsで取得したのち、base64 --decodeとjqで整形すると読める形になります。
export SHARD_ITERATOR=$(aws kinesis get-shard-iterator \
--stream-name ${KINESIS_STREAM_NAME} \
--shard-id shardId-000000000000 \
--shard-iterator-type TRIM_HORIZON \
--region ${REGION} \
--query 'ShardIterator' --output text)
aws kinesis get-records \
--shard-iterator ${SHARD_ITERATOR} \
--region ${REGION}デコード後のイベントはJSONで、トップレベルにop、before、after、source、ts_ms、ts_nsのフィールドを持ちます。
opがcの場合はINSERTまたはUPDATEで、afterに変更後の完全な行が入ります。opがdの場合はDELETEで、beforeに主キーのみが入り、afterはnullになります。主キーを定義しておかないと、削除された行を一意に特定できなくなる点に注意します。source.ts_ms/source.ts_nsはCDC発行時刻、トップレベルのts_ms/ts_nsはコミット時刻を表します。再構築時にはコミット時刻とsource.txIdを組み合わせると整合的な並べ替えに使えます。source.schema、source.table、source.db、source.clusterでイベントの発生元を一意に追跡できます。
INSERTイベントの代表例は次のとおりです。DELETEではopがdになり、beforeに主キーのみが入る形になります。
{
"op": "c",
"before": null,
"after": { "id": "521d51b6...", "name": "Alice", "email": "alice@example.com" },
"source": {
"version": "1.0",
"ts_ms": 1773843841175,
"txId": "dco7le2ijp...",
"schema": "public", "table": "users",
"db": "postgres", "cluster": "2ntttwpy..."
},
"ts_ms": 1773843841076,
"ts_ns": 1773843841076494565
}
代表的ユースケースとメリット
Aurora DSQL CDCがあると何が嬉しいのか、代表的なユースケースから整理します。
ひとつ目はリアルタイム分析です。DSQLのトランザクションデータをKinesisからAmazon S3、Amazon OpenSearch Service、Amazon Redshiftなどに増分反映すれば、ETLバッチ待ちの遅延を抑えてダッシュボードや異常検知をほぼリアルタイムに動かせます。DSQL本体はマルチリージョン強整合性を保つため、「強整合なソース」を下流の分析基盤に波及できる点が特徴です。
ふたつ目はイベント駆動アーキテクチャです。注文INSERTで通知Lambdaを起動する、ステータスUPDATEを契機にSagaの次ステップへ進める、といったDB変更起点のフローに向きます。アプリケーション内で二重書き込み(DB+メッセージング)に頼る代わりにCDC経由でイベント派生させると、トランザクション境界と発行の整合が取りやすくなります。
みっつ目はデータレプリケーションと監査ログです。異種データベースへの部分的なミラーリング、Amazon S3への履歴アーカイブ、コンプライアンス要件の変更履歴保管などに使えます。source.txIdとコミット時刻が乗るため、後からの監査・突き合わせがしやすい点もメリットです。
サーバーレス・データ密集型システムの観点では、CDCのバックグラウンド独立動作によりOLTPワークロードのレイテンシを犠牲にせずストリームを派生できるのが大きな利点です。
プレビュー利用時の注意点と運用上のヒント
強力な機能ですが、パブリックプレビューということもあり、いくつかの前提を踏まえた設計が必要です。
まず順序保証です。Aurora DSQL CDCはUNORDERED配信であり、行間やトランザクション間の厳密な順序は保証されません。下流コンシューマー側でsource.txIdとコミット時刻、主キーの組み合わせを使った冪等処理を必ず実装します。Kinesisの「最低1回配信」特性とも組み合わせ、重複イベントを安全に処理できる設計にしておきます。
次にテーブル単位フィルタリングです。プレビュー時点ではクラスター内の全テーブルが対象になります。特定テーブルだけを下流処理したい場合は、Lambdaなどコンシューマー側でsource.tableやsource.schemaを見て分岐させる前提で構築します。
続いて主キーの設計です。DELETEイベントのbeforeには主キーしか入らないため、主キーが未定義だと削除追跡が事実上不能になります。
運用上のヒントとしては、プレビュー期間中はGA前の検証用途として位置づけ、本番採用は対象を限定するのが現実的です。下流のスキーマ追従については、source.schemaとsource.tableをキーにマッピングを差し替えやすい構造にしておくと、GA以降の機能追加(テーブル単位フィルタリング、より厳密な順序保証など)にも柔軟に対応できます。
Aurora DSQL CDCは、サーバーレス分散SQLに「ストリーミングの出口」を与える機能です。プレビューのうちから手元のクラスターで小さく試し、イベント設計と消費側実装の勘所を掴んでおくと、GA以降の本番展開がスムーズになります。
























