



Alibaba傘下のQwenチームが2026年4月に立て続けてリリースした「Qwen3.6シリーズ」が、ローカルLLMの世界を大きく揺さぶっています。わずか27Bのパラメータを持つ密モデルが旧世代の397B大型モデルのコーディング性能を超え、Claude Opus 4.6に数ポイント以内まで迫るSWE-benchスコアを記録しました。さらにMoEモデルは20GB程度のVRAMで動作し、MacBook Pro M5やRTX 3090といったコンシューマーグレードのハードウェアでも実用的な速度が確認されています。本記事では、Qwen3で導入されたハイブリッド思考モードの仕組みからQwen3.6の各モデルの特性、実践的なローカル展開のポイントまでを解説します。
Qwen3.6とは 2026年4月に出揃ったラインナップ
Qwen3.6シリーズは2026年4月に段階的にリリースされました。まず4月2日にクローズドAPI提供の「Qwen3.6-Plus」が登場し、続いて4月16日にMoEアーキテクチャの「Qwen3.6-35B-A3B」がApache 2.0ライセンスでオープンリリースされました。4月20日にはフラッグシップとなる「Qwen3.6-Max-Preview」がAPIのみで公開され、4月22日に密モデルの「Qwen3.6-27B」が同じくApache 2.0でオープンウェイトとして配布されています。
オープンモデルの2種はHugging FaceおよびModelScopeで即座にダウンロード可能となっており、コマーシャル利用も含めて自由に活用できます。一方でQwen3.6-Max-Previewは、Qwen史上初となるクローズドウェイトのフラッグシップモデルです。これまでQwenシリーズはオープン化を積極的に進めてきただけに、この戦略転換は業界で注目を集めました。
各モデルのコンテキスト長はいずれも262,144トークンをネイティブサポートし、拡張設定では最大1,010,000トークンまで対応しています。長大なコードベース全体を一度に読み込んで分析するユースケースでも十分な余裕があります。
ハイブリッド思考モードの仕組みとQwen3からの進化
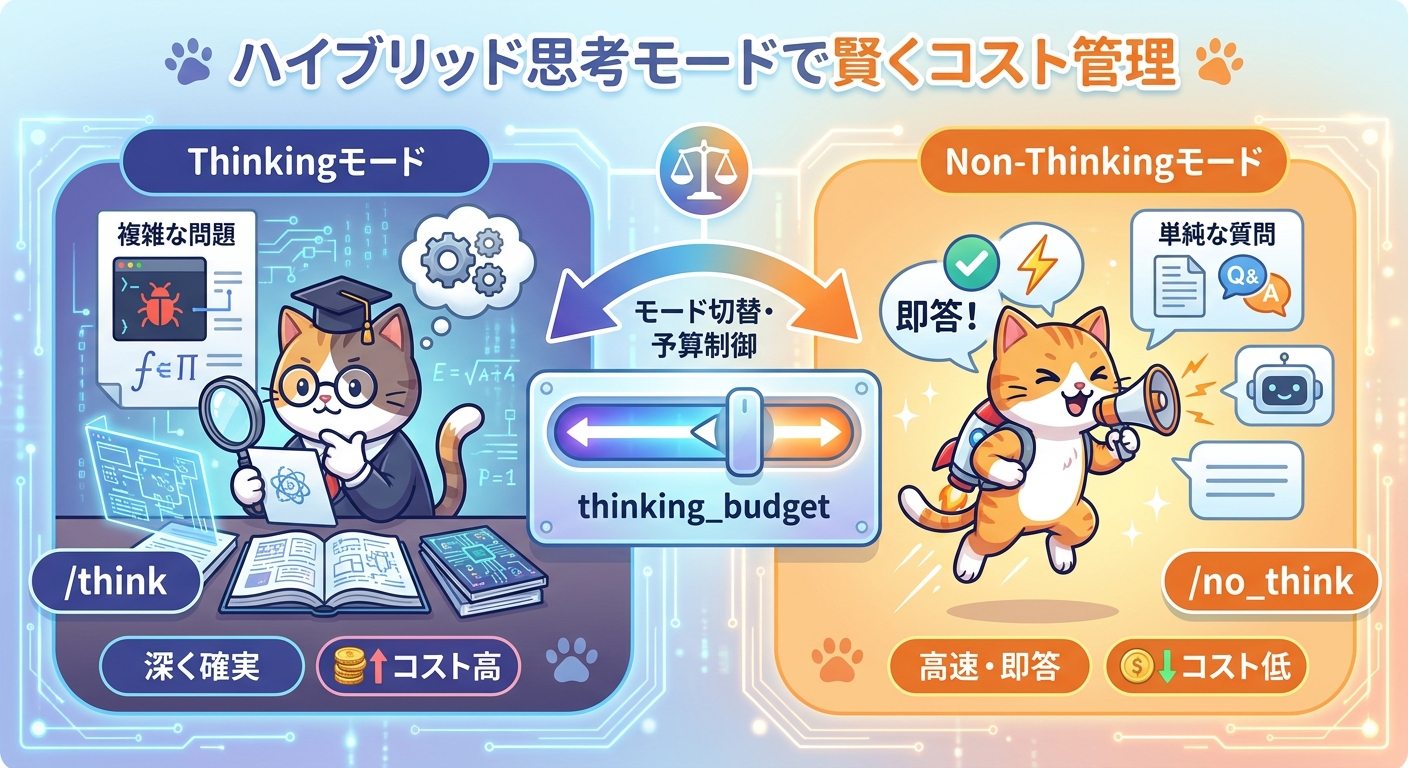
Qwen3.6の重要な機能軸のひとつが「ハイブリッド思考モード」です。これはQwen3(2025年4月リリース)で初めて導入されたアーキテクチャ上の工夫で、モデルが「深く考えるモード(Thinkingモード)」と「即座に返すモード(Non-Thinkingモード)」を1つのモデルで切り替えられる仕組みです。
従来の推論特化モデルはどんな質問にも長いチェーンオブソート(CoT)を走らせるため、単純な質問に対しても無駄な計算コストが発生しました。ハイブリッドモードではタスクの複雑さに応じて動的に切り替えることができ、コストとレイテンシのバランスを柔軟にコントロールできます。
技術的には「Long CoT cold start」「Reasoning-based RL」「Thinking mode fusion」「General RL」の4段階学習パイプラインを経ることで、ひとつのモデルに両モードを安定して共存させています。利用側からは以下のように制御します。
- enable_thinking パラメータ — API呼び出し時に True/False で切替
- /think・/no_think コマンド — マルチターン会話の中で動的に切替
- thinking_budget — 推論に使うトークン上限を数値で指定し、超過したら即出力
この仕組みにより、たとえばコードレビューのような複雑なタスクでは深い推論を走らせ、ドキュメント要約のような定型タスクでは素早く返答するという使い分けが実現します。企業内ユースケースでは推論トークンのコスト管理が重要なため、thinking_budget による予算制御は特に実用的な機能です。
Qwen3.6-27Bの実力 30Bクラスを塗り替えるベンチマーク
Qwen3.6-27Bが最も注目されるのは、そのコーディング性能の高さです。自律型のソフトウェアエンジニアリングタスクを測定するSWE-bench Verifiedで77.2%を記録しました。これはClaude Opus 4.6の80.8%に3.6ポイント差まで迫るスコアであり、30B規模のオープンモデルとしては前例のない水準です。
ターミナルでの自律的なコーディング能力を評価するTerminal-Bench 2.0では59.3%となり、Claude 4.5 Opusと全く同じスコアを記録しています。また、タスク遂行スキルを評価するSkillsBenchでは48.2%を達成し、旧世代のQwen2.5-72B-Instruct(397B相当)の30.0%を77%の相対的改善幅で超えました。さらにGoogleのGemma4-31Bとの比較では、12項目のベンチマーク全てでQwen3.6-27Bが上回る結果が報告されています。
ただし注意点があります。これらのベンチマークはQwenチームが独自に構築したエージェントスキャフォールド(bash + ファイル編集ツール)上で実施されており、2026年4月時点で第三者による独立した再現検証は限定的です。数値を参照する際はこの点を踏まえた上で評価することが重要です。
一方でSimon Willisonをはじめとした実務家によるハンズオンレビューでは、ローカル動作での実用性は高く評価されています。Claude Opus 4.7相当の出力をノートPCで得られるという実感的なレポートが多数あり、日常的なコーディング補助用途では十分に機能することが確認されています。
MoEアーキテクチャが広げるローカル展開の選択肢
Qwen3.6-35B-A3Bは「MoE(Mixture of Experts)」アーキテクチャを採用したモデルです。総パラメータ数は35Bですが、1回の推論時にアクティブになるパラメータはわずか3Bです。大型モデルの表現力を保ちつつ、推論時の計算量は小型モデルと同程度に抑えられるため、ローカル展開の現実解として注目されています。
量子化すればさらにサイズを削減できます。unslothが提供するUD-Q4_K_XL量子化版は22.4GBとなり、RTX 3090(24GB VRAM)で101トークン/秒という実用的な速度で動作します。MacBook Pro M5ではLM Studio経由での動作が確認されており、GPU非搭載のAppleシリコン環境でもローカルLLMとして機能します。
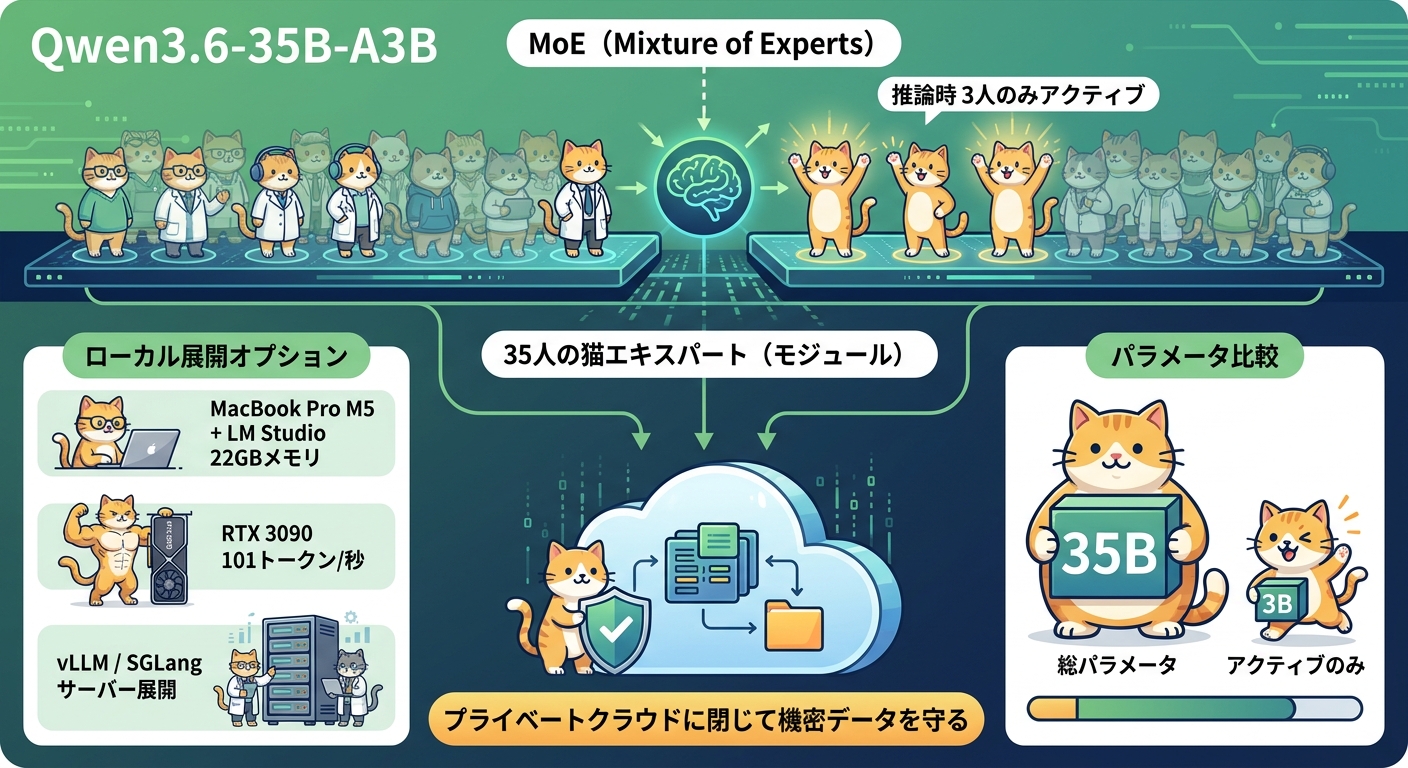
展開ツールとしてはllama.cpp、vLLM、SGLangが対応しています。Ollamaは2026年4月時点でvisionのmmproj対応待ちのため、画像入力が必要なユースケースでは注意が必要です。なお、初期リリース直後のコミュニティ報告(r/LocalLLaMA)では、ツールコールの繰り返し・スキップ不具合やCUDA 13.2での低ビット量子化時の文字化けが確認されています。CUDA 13.1の使用または最新のllama.cppビルドへのアップデートが推奨されています。
セキュリティ要件が厳しいエンタープライズ環境では、外部APIへのデータ送信を禁止している場合があります。MoEモデルをプライベートクラウドやオンプレミスに展開することで、高い推論性能を保ちつつデータを自社環境内に閉じる運用が実現します。コンプライアンス観点からローカルLLMを選定する際の有力候補となるでしょう。
オープン化とクローズド化の狭間で問われるLLM戦略
Qwen3.6シリーズで特筆すべき動向のひとつが、Qwen史上初のクローズドウェイトフラッグシップ「Qwen3.6-Max-Preview」の登場です。Qwenチームはこれまで積極的なオープンウェイト戦略を採用し、コミュニティから高い支持を得てきました。フラッグシップのクローズド化は、その方針の一部転換を示すものであり、MetaのLlamaシリーズを含む「オープンLLM」の定義そのものに問いかけを投げかけています。
一方で27BおよびMoEモデルをApache 2.0でオープンリリースしたことは、エンタープライズ実用層へのしっかりとした提供継続を示しています。最先端フラッグシップはAPIで収益化しつつ、実用層はコミュニティに開放するという二層構造は、今後のLLMビジネスモデルとして定着していく可能性があります。
企業がLLM活用戦略を検討する際には、オープンウェイトモデルのメリット(ローカル展開・カスタムファインチューニング・ベンダーロックイン回避)とクローズドAPIのメリット(最先端性能・管理コストゼロ・継続的アップデート)を目的に応じて使い分けることが重要です。Qwen3.6はその両方の選択肢を1つのファミリーとして提供している点で、現在のハイブリッドLLM時代を象徴するシリーズといえます。
生成AIを業務に取り込む企業にとって、「クラウドAPIで始めてオープンモデルで内製化する」というパスが現実的な選択肢となりつつあります。Qwen3.6-27BやQwen3.6-35B-A3Bの登場は、その移行コストをさらに下げるものであり、エンジニアとして押さえておくべきマイルストーンです。
























