



MiniMaxとは 上海発の次世代AIスタートアップ
2021年12月、中国・上海でひとつのAIスタートアップが誕生しました。コンピュータビジョンの世界的企業SenseTimeの研究者たちが独立して立ち上げた「MiniMax Group」です。共同創業者のYan Junjie(顔駿傑)はSenseTimeの元副社長であり、ビジョンAIで培った技術基盤を持ち寄って、マルチモーダルAIの新たな地平を切り拓こうとしました。
その後の成長は目覚ましいものでした。2024年3月にはアリババグループが主導する$600M(約900億円)の大型調達ラウンドを成功させ、評価額は$2.5Bに到達します。さらに2025年時点では$4B(約6,000億円)まで評価額が上昇し、2026年1月9日には香港証券取引所(HKEx)への上場を果たしました。主要な投資家にはHillhouse Investment、HongShan(旧Sequoia China)、IDG Capital、Tencentといった名だたるファンドが名を連ねており、MiniMaxに対する業界の期待の高さが伺えます。
同社はAPIプラットフォームだけでなく、コンシューマ向けプロダクトにも力を入れています。AIキャラクターアプリ「Talkie」はグローバルで展開され、中国向けには「星野(Xingye)」を提供。動画生成サービス「Hailuo AI」も注目を集めており、基盤モデルの技術力を実サービスで証明し続けています。テクノロジーと商品化の両輪で成長するスタートアップとして、世界のAI業界から強い注目を集めています。
MiniMaxのモデルラインナップと進化の軌跡
MiniMaxが提供するモデルラインナップは、数年で急速に充実してきました。その進化を俯瞰することで、同社の技術的な方向性がよく理解できます。
まず2025年1月に公開された「MiniMax-Text-01」と「MiniMax-VL-01」が転換点となりました。MiniMax-Text-01は総パラメータ数456B(兆)という巨大なモデルでありながら、トークン生成ごとにアクティベートされるのは45.9Bだけというスパース構造を採用しています。そして最大の特徴が、学習時1Mトークン・推論時最大4Mトークンというかつてない超長文コンテキストウィンドウです。MiniMax-VL-01はそのText-01をベースに303MパラメータのVision Transformer(ViT)を組み合わせたマルチモーダルモデルで、336×336から2016×2016の解像度まで動的に対応する画像理解能力を備えています。
2025年後半から2026年にかけては「MiniMax-M2」シリーズが登場します。M2は最大204,800トークンのコンテキストを持つエージェント特化モデルで、ツール使用やWeb検索など実用的なエージェント機能を備えています。その発展形である「MiniMax-M2.5」は総パラメータ230B・アクティブパラメータ10Bというバランスを実現し、コーディングと推論において特に顕著な性能向上を達成しました。さらに推論速度を最大化した「M2.5-Lightning」は100 tokens/秒という高スループットを誇り、リアルタイムアプリケーションに最適です。2026年時点では「MiniMax-M2.7」も登場し、継続的なアップデートが続いています。
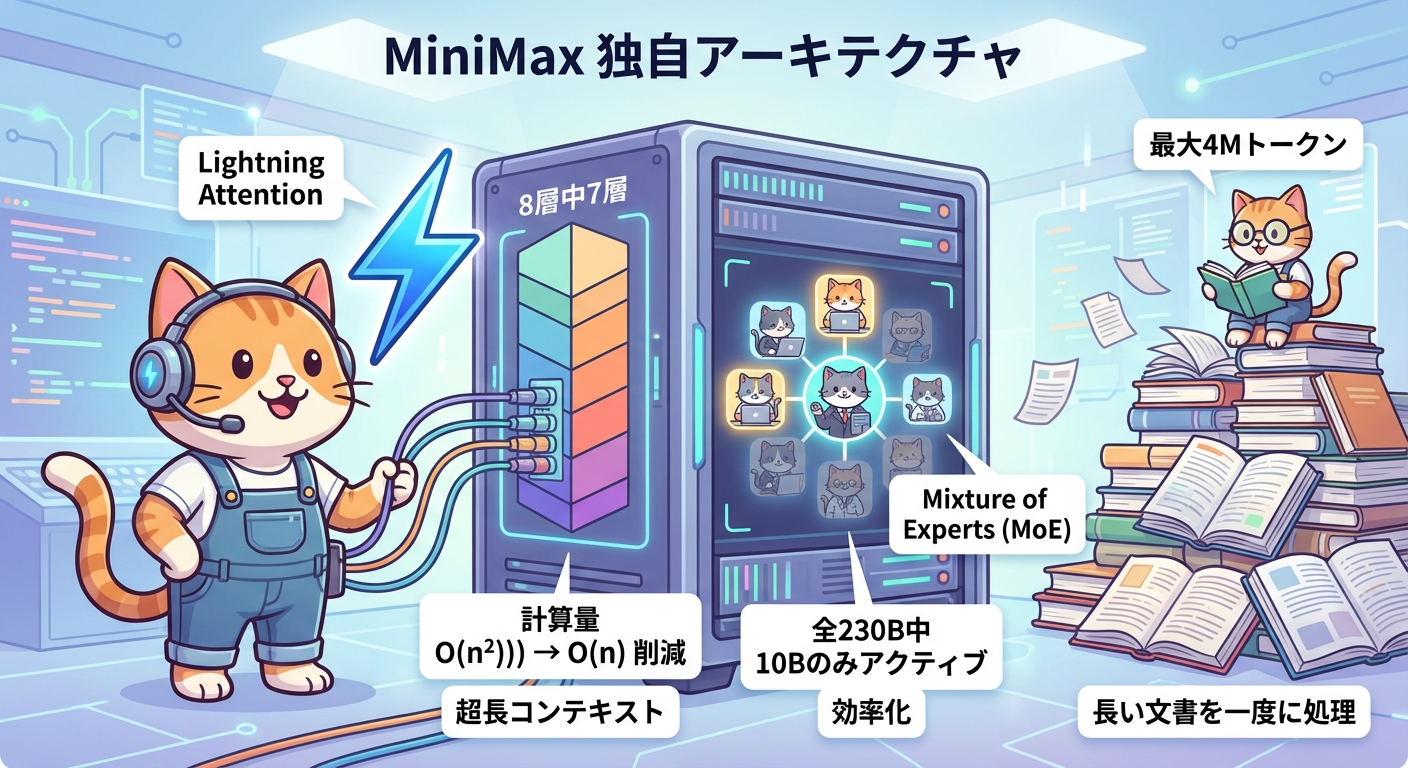
Lightning AttentionとMoEが生み出す技術的優位性
MiniMaxの性能を支える核心的な技術は、「Lightning Attention」と「Mixture-of-Experts(MoE)」の組み合わせです。この二つの革新が、超長コンテキストと高いコスト効率という一見相反する目標の同時達成を可能にしています。
通常のTransformerが採用するSoftmax Attentionは、入力トークン数Nに対してO(N²)の計算量を必要とします。これが「コンテキスト長に限界がある」問題の根本原因です。MiniMaxが開発したLightning Attentionは線形アテンションの一種で、計算量をO(N)まで削減することに成功しました。ただし線形アテンションには精度が落ちやすい弱点があるため、MiniMaxは8層に1層の割合でSoftmax Attentionを挟む「7:1ハイブリッドアテンション」を採用しています。この比率こそが、1Mトークンから最大4Mトークンという前例のないコンテキスト長を実用的な精度で実現する秘訣です。
一方MoEは、モデル全体のパラメータ数と実際の計算量を切り離す技術です。MiniMax-M2.5は総パラメータ数こそ230Bに及びますが、1つのトークンを処理する際にアクティベートされるのはわずか10B分のエキスパートのみです。つまり大きなモデルの「知識の幅」と小さなモデルの「動作の軽さ」を同時に享受できます。大規模MoEモデルの学習では勾配爆発や不安定性が課題となりますが、MiniMaxはCISPO(Constraint-Iterative Scaled Policy Optimization)アルゴリズムを導入してこれを克服しています。さらに長文コンテキストにおけるエージェントロールアウトの信頼性向上には、プロセスリワードメカニズムを採用しています。
位置エンコーディングにはRoPE(Rotary Position Embedding)を採用し、アテンションヘッド次元の半分に適用しています。ベース周波数は10,000,000と非常に高く設定することで、超長距離の位置関係を正確に把握できるようになっています。Vocabulary Sizeは200,064と広く、多言語や専門ドメインの語彙に幅広く対応しています。
ベンチマーク比較 MiniMax M2.5 vs Claude Opus 4.6
2026年時点でのMiniMaxの主力モデルは「MiniMax-M2.5」です。このモデルが各種ベンチマークでどのような数値を示し、Anthropicの「Claude Opus 4.6」と比較してどこが優れ、どこが課題かを見ていきましょう。
まず注意すべき点として、MMLU・HumanEval・GSM8Kといった従来型ベンチマークは、現代のフロンティアモデルではほぼ飽和状態にあります。どのモデルも90%以上のスコアを記録しており、差別化の指標として機能しなくなっています。より実用的な評価指標として注目されているのが「SWE-bench Verified」です。実際のソフトウェアエンジニアリングタスクをどれだけ解決できるかを測るこのベンチマークで、MiniMax-M2.5は80.2%を記録しました。Claude Opus 4.6の80.8%、Gemini 3.1 Proの80.6%と同等のスコアであり、完全に「フロンティアクラス」の性能を持つことが確認されています。
コーディング能力を示すHumanEvalでは89.6%、数学的推論のAIME 2025では86.3%、科学的QAであるGPQA Diamondでは85.2%を達成。特にBrowseComp(Webブラウジング能力)では76.3%と高く、エージェントとしての実用性が際立っています。
最も大きな差が出るのはコスト面です。MiniMax-M2.5の料金は入力$0.118/1Mトークン・出力$0.99/1Mトークンです。Claude Opus 4.6の入力約$15/1Mトークン・出力約$75/1Mトークンと比較すると、入力で約127倍、出力で約75倍もの差があります。M2.5-Lightningは入力$0.30・出力$2.40と若干高めですが、それでも100 tokens/秒という高速処理が可能です。大量のトークンを処理するバッチ処理やRAGパイプラインでは、このコスト差が導入可否を左右する決定的な要因になります。

MiniMax APIの料金体系と開発者向け活用シーン
MiniMaxのAPIプラットフォームは「platform.minimax.io」から利用でき、APIキーを発行してBearerトークン認証でアクセスします。OpenRouter経由でのアクセスも可能なため、既存のOpenRouterインテグレーションがあれば最小限のコード変更で試せます。主なエンドポイントはテキスト生成・チャット補完・埋め込みなどで、OpenAI互換のAPIフォーマットに近い設計になっています。
モデル別料金体系を整理すると、M2.5が最もコストパフォーマンスに優れており、入力$0.118・出力$0.99(いずれも1Mトークンあたり)です。性能向上版のM2.7は入力$0.30・出力$1.20と若干高めですが、それでもClaudeと比較すれば圧倒的なコスト効率です。高速推論を最優先にする場合はM2.5-Lightning(入力$0.30・出力$2.40)が適しています。
開発者が特にMiniMaxを活用しやすいシーンはいくつかあります。まず「大量ドキュメントのRAGパイプライン」です。Legal、Finance、研究論文など大容量のコーパスを扱う場合、最大4Mトークンのコンテキスト長により複数の長文書を一括で処理できます。コスト面での優位性と合わせて、大規模RAGシステムの運用コストを大幅に削減できます。次に「コーディングエージェント」です。SWE-bench 80.2%という実績は、GitHub IssueをベースにしたPRの自動生成やバグ修正ワークフローに実用的な水準です。さらに「マルチモーダル処理」ではMiniMax-VL-01を使うことで、画像を含むドキュメントの解析や視覚的なUI検証ツールの構築が可能です。
ClaudeとMiniMaxの使い分け戦略
MiniMaxとClaudeは、どちらか一方が「優れている」というよりも、用途に応じて使い分けるべきコンポーネントです。エンジニアが両者の特性を正しく理解することで、パフォーマンスとコストを最適化したシステム設計が可能になります。
MiniMaxを選ぶべき場面は、主にスループットとコスト効率が重要な場合です。バッチ推論・RAGパイプライン・ログ解析・定型文書処理など、大量のリクエストを捌く必要がある場面では、Claudeとの100倍超のコスト差が大きな意味を持ちます。またM2.5-Lightningの100 tokens/秒という処理速度は、リアルタイムチャットやストリーミング応答が求められるプロダクトにも魅力的です。コーディング・エージェントタスクにおいても、SWE-bench水準の性能がClaudeとほぼ同等である点を踏まえると、費用対効果は明確にMiniMaxが優位です。
Claudeを選ぶべき場面は、高度な推論・倫理的判断・繊細なコミュニケーションが求められるときです。コンプライアンス審査・医療アドバイス・法的文書の草案作成など、誤りが許されないドメインでは、Anthropicが積み重ねてきたAI Safety研究と企業向けの信頼性が強みになります。また日本語を含む多言語の微妙なニュアンスや、複雑なインストラクションフォロー能力においても、Claudeのほうが安定した品質を発揮するケースがあります。
現実的なアーキテクチャとして有効なのは、「ハイブリッド構成」です。日常的な大量処理はMiniMaxで担い、ユーザー対面の高品質応答や判断が必要な重要タスクはClaudeに任せる、という役割分担によってコストと品質の両立が図れます。たとえばドキュメント解析の一次処理はMiniMax-M2.5、最終的なユーザーレスポンスの生成はClaude Sonnet 4.6、という組み合わせは多くのエンタープライズ用途で実用的な選択肢となります。オープンソースモデルのため自社インフラへのデプロイも可能で、クラウドAPIへの依存を減らしたい場合にも選択肢のひとつです。
























