



「自分のPCでChatGPTのような大規模言語モデルを動かしたい」「データをクラウドに送らずに生成AIを活用したい」——そんな要望に応えるのが、ローカルLLMです。2025年に入り、モデルの性能向上や実行ツールの成熟により、エンジニアだけでなく一般ユーザーでもローカルLLMを手軽に活用できる環境が整ってきました。
本記事では、Ollama・LM Studio・Jan・GPT4Allといった主要な実行ツールを比較するとともに、2025年に注目すべきLlama3・Mistral・Gemma・Phiなどのモデルを解説します。ハードウェア要件からユースケース別のおすすめ構成まで網羅的にまとめましたので、ローカルLLM選びの参考にしてください。
ローカルLLMとは?クラウドLLMとの違い
ローカルLLMとは、ChatGPT(OpenAI)やClaude(Anthropic)のようなクラウドサービスとして提供されるLLMとは異なり、自分のコンピュータ上で直接動作させる大規模言語モデルのことです。モデルのウェイト(パラメータファイル)をダウンロードし、手元のCPUやGPUで推論処理を行います。
クラウドLLMとローカルLLMの特徴を比較すると、以下のようになります。
比較項目 | クラウドLLM | ローカルLLM |
|---|---|---|
プライバシー | データがサーバーに送信される | データが外部に出ない |
コスト | 従量課金(使うほど費用がかかる) | 初期投資のみ(継続費用なし) |
オフライン利用 | インターネット接続が必須 | オフラインで動作する |
性能 | 最高水準のモデルを利用可能 | ハードウェアに依存する |
カスタマイズ | 制限あり | ファインチューニング・プロンプト設計が自由 |
セットアップ | アカウント登録のみ | ハードウェアとソフトウェアの準備が必要 |
ローカルLLMが特に有効なシナリオは、個人情報や機密情報を含むデータを扱う業務、医療・法務・金融など情報管理が厳しい業種、またAPI費用を抑えたい開発者向けのプロトタイピングです。一方で、GPT-4oやClaude 3.7 Sonnetのような最先端モデルと同等の性能を求める場合は、現状ではクラウドLLMに分があります。
ただし、2025年はこの状況が大きく変化した年です。Llama 3.3 70BやGemma 3などのオープンソースモデルが商用クラウドLLMに迫る品質を実現し、小型モデルでも実用的なタスクをこなせるようになりました。
主要ローカルLLM実行ツール比較(Ollama vs LM Studio vs Jan vs GPT4All)
ローカルLLMを動かすには、モデルをダウンロードして実行するための「実行ツール」が必要です。2025年時点での主要なツールを比較します。
ツール名 | インターフェース | 対応OS | 対象ユーザー | API提供 | RAG機能 |
|---|---|---|---|---|---|
Ollama | CLI(コマンドライン) | macOS / Linux / Windows | 開発者・上級者 | あり(REST API) | なし(外部連携) |
LM Studio | GUI(デスクトップアプリ) | macOS / Windows / Linux | 初心者〜中級者 | あり(OpenAI互換) | なし |
Jan | GUI(デスクトップアプリ) | macOS / Windows / Linux | 初心者〜中級者 | あり | 実験的対応 |
GPT4All | GUI(デスクトップアプリ) | macOS / Windows / Linux | 初心者〜中級者 | あり | あり(充実) |
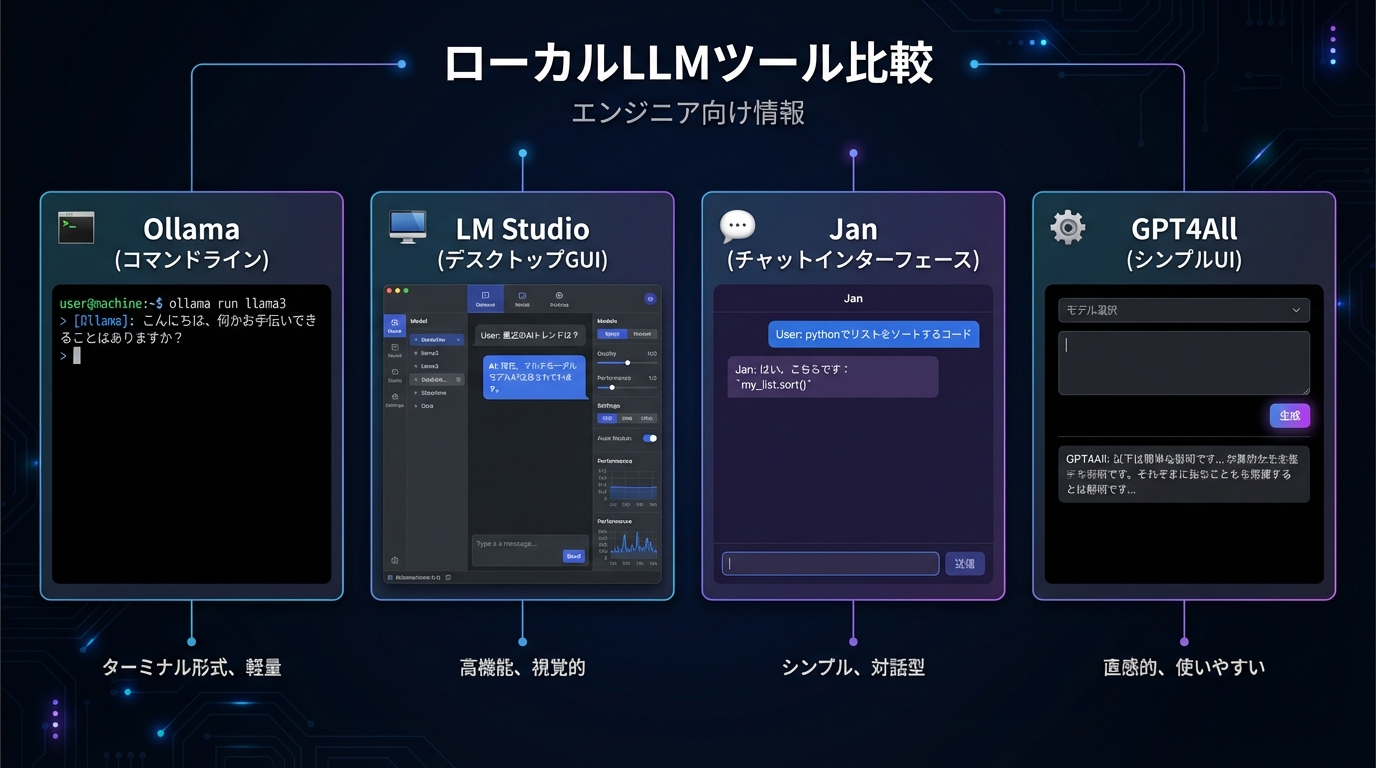
Ollama
Ollamaは、llama.cppをバックエンドに採用したCLI(コマンドライン)ベースの実行環境です。シンプルなコマンド一つでモデルのダウンロードから起動まで完結します。
REST APIが標準搭載されており、アプリケーション連携やDockerコンテナへの組み込みが容易です。LM Studioより10〜20%高速な推論速度を持ち、Modelfileでモデルの動作カスタマイズも可能です。API-firstな設計でプロダクション組み込み用途に最適です。
LM Studio
LM Studioは、グラフィカルなUIで直感的にモデルを管理・実行できるデスクトップアプリです。1000以上のモデルをブラウジングしてワンクリックでダウンロードできる機能を持ちます。
2025年にチームコラボレーション機能が追加されました。Apple SiliconではMLX形式モデルで省メモリかつ高速推論が可能です。OpenAI互換APIサーバー機能により、既存アプリをローカルLLMへ切り替えやすい点も強みです。
Jan
Janは完全オープンソース(MIT License)のローカルLLM実行環境です。GUIとAPIの両方に対応しており、プライバシーを重視したユーザーに選ばれています。ただし、2025年時点ではドキュメント解釈機能がExperimental扱いで不安定な部分もあります。
GPT4All
GPT4AllはRAG(Retrieval-Augmented Generation)機能が充実していることが最大の特徴です。ローカルのドキュメントを知識ベースとして取り込み、それを参照しながら回答を生成する機能が標準搭載されています。Mac M-Series・AMD・NVIDIAのGPUに広く対応し、ダウンロード数でもJanやLM Studioを上回る実績を持っています。
2025年注目モデル比較(Llama3・Mistral・Gemma・Phi)
ローカルLLMを動かすには「どのモデルを使うか」の選択も重要です。2025年に注目すべきオープンソースモデルを比較します。
モデル名 | 開発元 | 代表サイズ | ライセンス | 強み | 日本語対応 |
|---|---|---|---|---|---|
Llama 3系列(3.1/3.3) | Meta | 8B(3.1) / 70B(3.3) | Meta Llama License | バランス・汎用性 | 公式サポート |
Mistral Small | Mistral AI | 7B / 22B | Apache 2.0 | 軽量・高速 | 部分対応 |
Gemma 3 | Google DeepMind | 4B / 12B / 27B | Gemma License | 小型高性能・マルチモーダル | 多言語対応 |
Phi-4 mini | Microsoft | 3.8B / 14B | MIT License | 推論・教育 | 部分対応 |
Llama 3.3(Meta)
MetaのLlamaシリーズはローカルLLM界のデファクトスタンダードです。15兆トークンで学習しており汎用性が高く、Llama 3.3 70Bはオープンソース最高水準の性能を誇ります。日本語はMetaが公式サポートしており、初めての方にはLlama 3.1 8B Q4がおすすめです。
Mistral(Mistral AI)
フランスのMistral AIが開発するMistralシリーズは、軽量さと高速処理が特徴です。7Bパラメータながら他社の大型モデルと競合できる性能を持ち、長文の要約や文書分類など実用的なタスクに強みがあります。Apache 2.0ライセンスで商用利用が自由であることも企業導入が進んでいる理由のひとつです。
Gemma 3(Google DeepMind)
2025年にリリースされたGemma 3は、小型モデルの性能限界を塗り替えた注目作です。Gemma 3 4Bが前世代のGemma 2 27Bを上回るベンチマーク結果を出しており、少ないVRAMで高い性能を発揮します。マルチモーダル対応(テキストと画像の両方を扱える)と多言語対応の強化も特筆すべき点です。
Phi-4(Microsoft)
MicrosoftのPhiシリーズは小規模で高い推論能力が特徴です。Phi-4-mini(3.8B)は数学・論理推論で大型モデルに迫る性能を示します。MIT Licenseで商用利用可能であり、教育アプリや推論タスクに最適です。
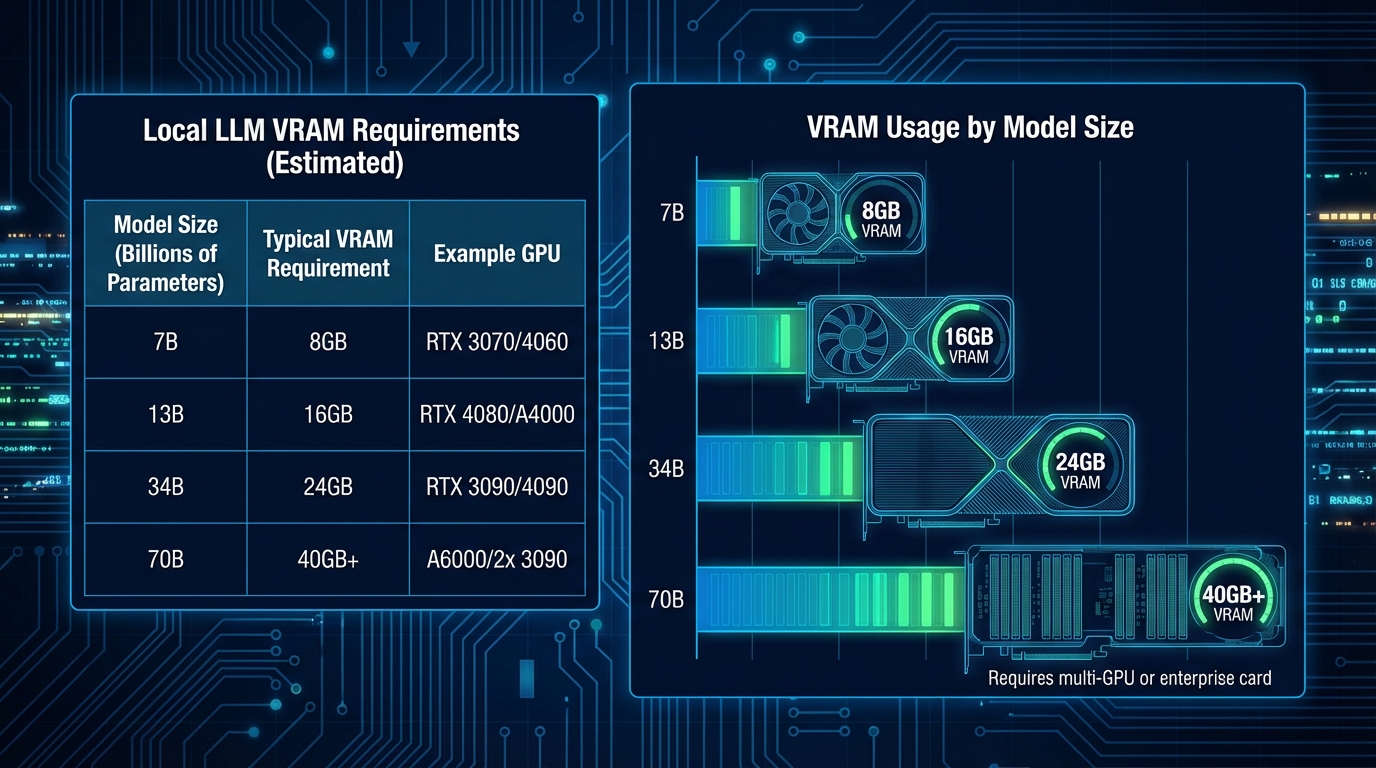
ハードウェア要件とパフォーマンス
ローカルLLMを快適に動かすには、十分なVRAM(グラフィックメモリ)やRAMが必要です。必要なVRAMはモデルのパラメータ数と量子化レベルによって大きく変わります。
VRAMの目安はQ4量子化ではパラメータ数(B)× 0.5、Q8量子化では× 1.0、FP16精度では× 2.0がおおよその目安です。
モデルサイズ | Q4量子化(推奨) | Q8量子化 | FP16精度 | 対応GPU例 |
|---|---|---|---|---|
3B(Phi-4 mini等) | 約2GB | 約3GB | 約6GB | GTX 1060以上 / M1 Mac |
7B(Mistral 7B等) | 4〜6GB | 7〜8GB | 約14GB | RTX 3060 / M2 Mac |
8B(Llama 3.1 8B等) | 5〜6GB | 8〜9GB | 約16GB | RTX 3060 / M2 Mac |
13B | 8〜10GB | 約13GB | 約26GB | RTX 3080 / M2 Pro Mac |
70B(Llama 3.3 70B等) | 35〜40GB | 約70GB | 140GB以上 | 複数GPU / H100サーバー |
量子化フォーマットについて
量子化はモデルの重みを低ビット精度に圧縮してVRAMを削減する技術です。主要フォーマットは3種類あります。GGUFはOllama・LM Studio標準で、Q4_K_Mで品質92%を保ちながらVRAMを大幅削減できます。CPU/GPUハイブリッド処理も可能です。
GPTQはGPU専用で最大5倍高速ですがGPU環境限定です。AWQは品質保持率95%で推論速度も優れており、精度が重要なマルチモーダル用途に向いています。Apple SiliconのMacはユニファイドメモリでCPU・GPUが共有するため、同容量のVRAM搭載GPUより大きなモデルを効率よく動かせる利点があります。
ユースケース別おすすめ構成とまとめ
ここまでの情報をもとに、用途・環境別のおすすめ構成を整理します。
ユースケース | おすすめモデル | おすすめツール | 最低VRAM目安 |
|---|---|---|---|
初めてのローカルLLM体験 | Llama 3.1 8B Q4 | LM Studio | 6GB |
プログラミング支援・コードレビュー | Llama 3.3 70B Q4 / Phi-4 | Ollama + VSCode連携 | 8GB〜40GB |
日本語文書の要約・翻訳 | Llama 3.1 8B / Gemma 3 12B | Ollama / LM Studio | 8GB |
社内ドキュメントへのRAG | Mistral 7B / Llama 3.1 8B | GPT4All | 8GB |
APIサーバーとしての組み込み | Llama 3.1 8B / Mistral 7B | Ollama(REST API) | 8GB |
低スペックPC・ノートPC | Phi-4 mini 3.8B / Gemma 3 4B | Ollama / LM Studio | 3GB |
ツール・モデル選択の指針
初めての方にはLM Studio + Llama 3.1 8Bがおすすめです。CLIに慣れた開発者はOllamaが高速でAPI連携もシームレスです。社内資料を参照させたい場合はGPT4AllのRAG機能が手軽です。商用利用ではMistral(Apache 2.0)やPhi-4(MIT)はライセンス制約が少なく扱いやすい選択肢です。
2025年のローカルLLMトレンドまとめ
2025年はローカルLLMの実用化が大きく前進した年です。Gemma 3 4BがGemma 2 27Bを超えたように小型モデルの性能向上が著しく、量子化技術の成熟で一般的なゲーミングPCでも実用的なモデルが動かせるようになりました。プライバシー保護・コスト削減・オフライン利用を重視する用途では、ローカルLLMは十分に実践的な選択肢です。
Ragateでは、ローカルLLMを活用したエンタープライズ向けAIシステムの設計・構築支援を行っています。社内データのプライベートなAI活用やRAGシステムの構築にご興味のある方は、ぜひお問い合わせください。
























