



2026年4月7日、AWSはAmazon S3 Filesを一般提供(GA)開始しました。これはAmazon S3バケットのデータに対して、従来のオブジェクトAPIに加えてPOSIX準拠のファイルシステムアクセスを提供する新機能です。34のAWSリージョンで利用可能となり、ML/AIワークロードやデータ分析、既存アプリケーションの移行など、幅広いシナリオでS3の活用方法が大きく広がります。
本記事では、Amazon S3 Filesの概要から従来のS3アクセスとの違い、主なユースケース、利用開始方法、そして考慮すべき制限事項まで順を追って解説します。
Amazon S3 Filesとは何か
Amazon S3 Filesは、AWSのコンピュートリソースをAmazon S3バケット内のデータに直接接続するための共有ファイルシステムです。Amazon EFS(Elastic File System)をベースに構築されており、従来のオブジェクトストレージとしてのS3の特性を保ちつつ、ファイルシステムとしてのアクセスインターフェースを追加で提供します。
S3 Filesを利用すると、Amazon EC2、AWS Lambda、Amazon EKS、Amazon ECSといったAWSコンピュートサービスから、NFS(Network File System)プロトコル経由でS3バケット内のデータにアクセスできます。これにより、ファイルシステムを前提として設計されたアプリケーションが、S3のスケーラビリティや耐久性を活用しながら、コードの大幅な改修なしに動作できるようになります。
S3 Filesの主な特徴は以下のとおりです。
- NFSプロトコル対応 —NFS 4.1および4.2をサポートし、POSIXセマンティクス(ファイル権限、ファイルロック、read-after-write一貫性)を実現
- インテリジェントな読み取りルーティング —ファイルサイズに応じて最適なストレージ層から自動的に読み取り
- 自動スケーリング —スループットとIOPSをキャパシティプロビジョニングなしに自動でスケール
- 高耐久性 —同一AWSリージョン内の複数アベイラビリティゾーン(AZ)でデータを冗長化
- セキュリティ —転送中はTLS暗号化、保存時はAWS KMS(AWS所有キーまたはカスタマー管理キー)で暗号化
2026年4月7日の時点で34のAWSリージョンで一般提供が開始されており、多くのグローバル環境でそのまま活用できます。
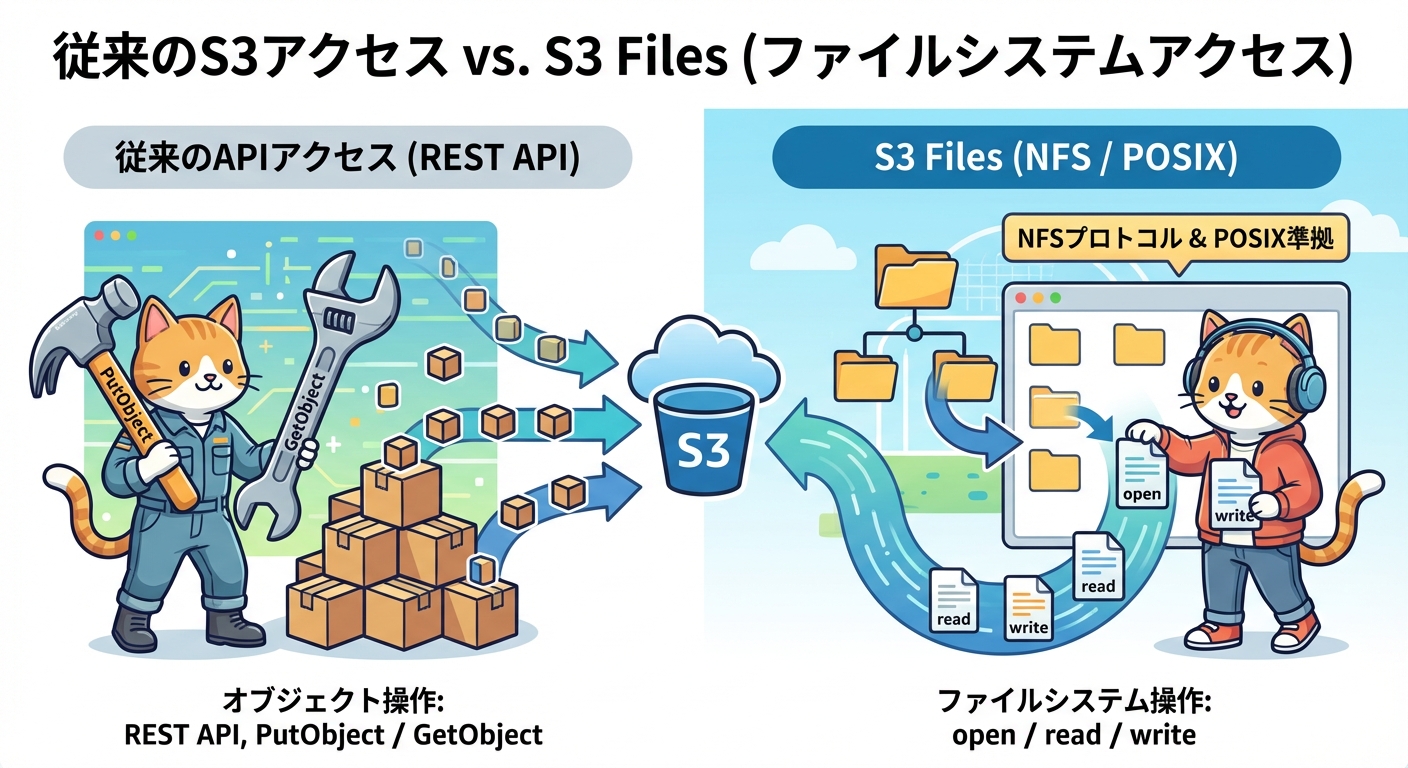
従来のS3アクセスとS3 Filesの違い
Amazon S3はもともと、HTTPベースのREST APIを通じてオブジェクト単位でデータを操作するオブジェクトストレージです。PutObjectでアップロード、GetObjectでダウンロード、DeleteObjectで削除といった操作がその基本です。このAPIは非常にシンプルかつスケーラブルですが、POSIXファイルシステムの操作(open、read、write、close、mkdir、rename等)とは異なる概念で設計されています。
そのため、ファイルシステムを前提とした既存のアプリケーションをS3に接続しようとすると、通常は次のような対応が必要でした。
- アプリのコードをS3 SDK(Boto3、AWS SDKなど)向けに書き直す
- S3 FUSEなどのサードパーティツールを経由してマウントする(パフォーマンス・安定性のトレードオフあり)
- 一度EFSやEBSなどのファイルシステムにステージングしてからS3に転送するパイプラインを構築する
S3 Filesはこの課題を根本から解決します。NFSプロトコル経由でS3バケットをファイルシステムとしてマウントできるため、既存のファイルシステムAPIを使うアプリケーションがそのままS3データに接続できます。また、ファイルシステムAPIとS3 APIの両方で同時にデータにアクセスできる相互運用性も備えており、既存のS3ワークフローを維持しながらファイルシステムアクセスを追加するといった柔軟な構成が可能です。
読み取り性能面では、S3 Filesはインテリジェント読み取りルーティングを採用しています。デフォルトで128KBが閾値となっており、128KB未満の小さなファイルや部分的なランダム読み取りはハイパフォーマンスストレージ層(サブミリ秒〜1桁ミリ秒の低遅延)から処理されます。一方、128KB以上の大きなファイルの連続読み取りはS3バケットから直接ストリーミングされ、最大テラバイト/秒規模の高スループットを実現します。このルーティングはアプリケーション側で意識する必要がなく、S3 Filesが自動的に判断します。
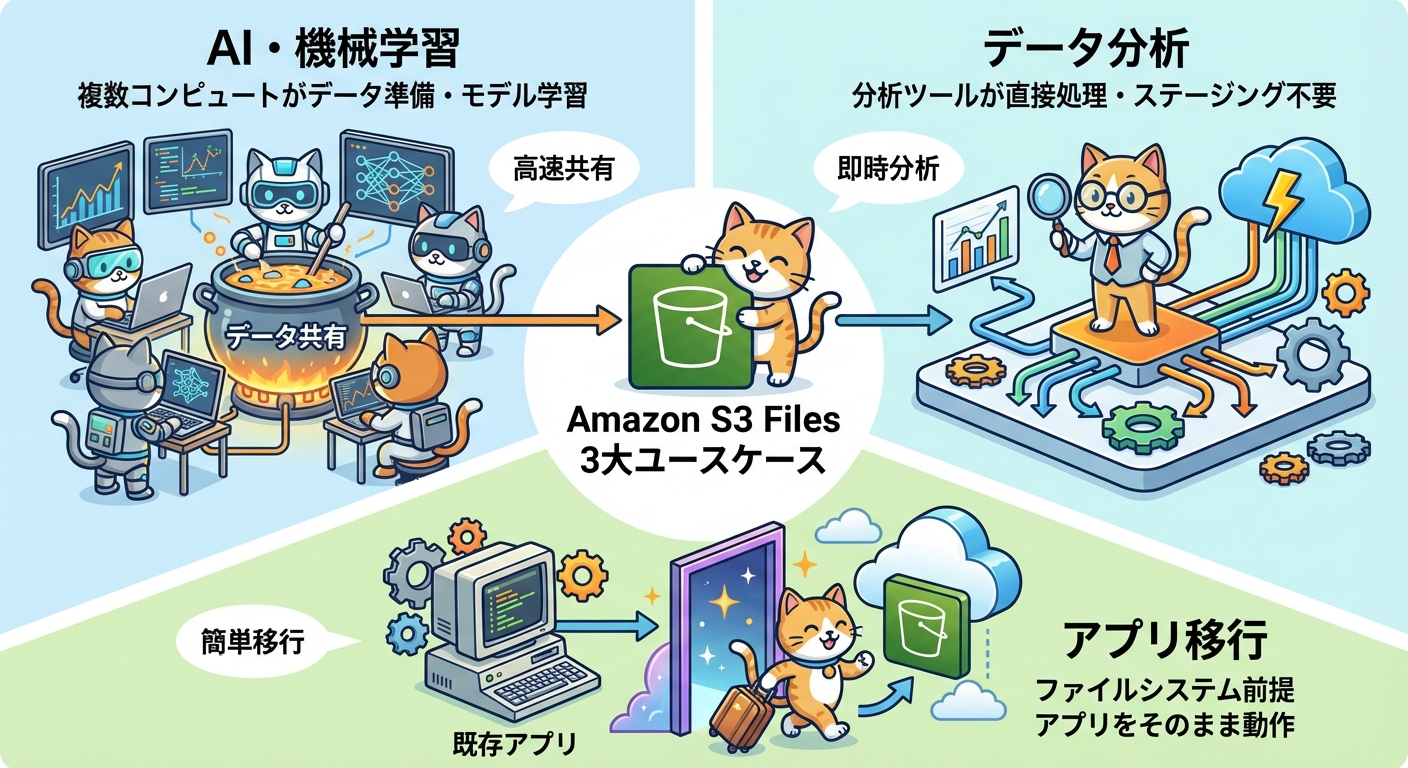
主なユースケース
S3 Filesが特に効果を発揮するユースケースを紹介します。
ML/AIワークロード
機械学習・AIの分野では、S3 Filesは非常に強力な選択肢になります。AIエージェントがパイプラインをまたいでメモリや状態を共有する際、従来はS3へのデータの読み書きを都度SDKで行う必要がありましたが、S3 Filesを利用すれば共有ファイルシステムとして直接アクセスできます。数千ものコンピュートリソースが同一のS3ファイルシステムに重複なく接続できるため、大規模な分散ML学習やデータ前処理パイプラインでも、データのコピーや移動を最小限に抑えられます。
また、MLチームがデータ準備作業を行う際、これまでは「S3からEFSやローカルにコピー → 加工 → S3に書き戻す」というステージングが必要でしたが、S3 Filesを使えばS3上のデータをそのままファイルとして操作でき、ステージング不要でデータ準備が完結します。
データ分析
Sparkや各種BIツールなど、ファイルシステムAPIを前提とした分析ツールがS3データを直接処理できます。分析のたびにS3からデータをダウンロードしてローカルやEFSに配置するステップが不要となり、パイプラインが簡素化されます。
既存ファイルベースアプリケーションの移行
レガシーシステムやオンプレミスで動作していたファイルシステム前提のアプリケーションをAWSに移行する際、従来はEFSやEBSが選択肢でしたが、S3 FilesによってS3をバックエンドとしつつファイルシステムインターフェースを維持できます。S3の高い耐久性(99.999999999%)とスケーラビリティを享受しながら、アプリのコード変更を最小化して移行できます。
利用開始方法と構成手順
S3 Filesを利用するには、以下の手順で設定を進めます。なお、具体的なコマンドや詳細設定は公式ドキュメントのチュートリアルを参照してください。
1. 前提条件の確認
S3 Filesを利用するには以下が必要です。
- VPC —ファイルシステムとコンピュートリソースが同一VPC内に存在すること
- IAMポリシー —S3 FilesおよびEFSへのアクセス権限を持つIAMロール・ポリシーの設定
- S3バケット —リンク先のS3バケット(既存バケットの利用可能)
- セキュリティグループ —マウントターゲットへのNFSトラフィック(ポート2049)を許可
2. S3ファイルシステムの作成
AWSマネジメントコンソール、AWS CLI、またはAWS CloudFormation/CDKを使って、S3ファイルシステムを作成します。作成時に以下を指定します。
- リンクするS3バケット名
- ハイパフォーマンスストレージ上のデータ有効期限(1〜365日、デフォルト30日)
- 暗号化設定(KMSキーの選択)
3. マウントターゲットの設定
VPC内のアベイラビリティゾーンごとにマウントターゲットを作成します。マウントターゲットはNFS接続のエンドポイントとなり、コンピュートリソースからアクセスする際のIPアドレス・DNSホスト名を提供します。
4. コンピュートリソースへのマウント
EC2インスタンスの場合、Amazon EFSと同様のコマンドでマウントできます。
sudo mount -t nfs4 \
-o nfsvers=4.2,rsize=1048576,wsize=1048576,hard,timeo=600,retrans=2,noresvport \
<マウントターゲットのDNS名>:/ \
/mnt/s3filesAWS Lambda、Amazon EKS、Amazon ECSについても、それぞれ公式ドキュメントに記載されたマウント手順があります。EKSの場合はCSIドライバーを利用し、Lambdaの場合はEFS同様のマウントポイント設定をLambda関数定義に追加する形になります。
5. アクセスポイントの設定(任意)
アクセスポイントを作成することで、アプリケーションごとに異なるユーザーIDや権限を適用できます。マルチテナント構成やチーム間でファイルシステムを共有する際に有効です。
考慮事項と制限事項
S3 Filesは非常に強力な機能ですが、導入前に把握しておくべき考慮事項があります。
コスト構造
S3 Filesは通常のS3ストレージ料金に加え、ハイパフォーマンスストレージ層のコストが追加で発生します。具体的には以下の課金が生じます。
- ハイパフォーマンスストレージに常駐しているデータのストレージ料金
- ハイパフォーマンスストレージへの読み書きアクセス料金
- S3バケットとの同期操作(インポート・エクスポート)の料金
なお、128KB以上のS3同期済みデータをS3から直接ストリーミングで読み取る場合は、ファイルシステムアクセス料金は発生せず、通常のS3 GET料金のみとなります。コスト最適化の観点では、大ファイル中心のワークロードほどS3ダイレクト読み取りの恩恵を受けやすい構造です。
データ有効期限の管理
ハイパフォーマンスストレージ上のデータには有効期限があります。デフォルトは30日で、1〜365日の範囲で設定可能です。一定期間アクセスされなかったデータはハイパフォーマンスストレージから期限切れとなり、次回アクセス時はS3バケットから再インポートされます。アクセスパターンを把握した上で、有効期限の設定を最適化することが推奨されます。
ネットワーク設計
S3 Filesを利用するには、コンピュートリソースとマウントターゲットが同一VPC内に配置されている必要があります。マウントターゲットはAZごとに作成するため、マルチAZ構成での利用では各AZにマウントターゲットを設置する設計が必要です。また、セキュリティグループでNFSポート(TCP 2049)の許可を忘れずに設定してください。
非サポート機能の存在
S3 FilesはAmazon EFSをベースに構築されていますが、EFSのすべての機能が利用できるわけではありません。また、S3オブジェクトの全機能(バージョニング、ライフサイクルポリシー等との完全な相互作用など)が同一の操作感で利用できるとは限りません。公式ドキュメントの「Unsupported features, limits, and quotas」ページで制限事項を事前に確認することを強く推奨します。
EFSとの使い分け
既存のデータがS3に保存されており、ファイルシステムアクセスを追加したいケースではS3 Filesが最適です。一方、S3を使わず純粋なネットワークファイルシステムが必要な場合や、EFSで十分なパフォーマンス要件であれば、従来通りEFSを利用するほうがシンプルな場合もあります。ユースケースとコスト要件を踏まえて選択してください。
まとめ
Amazon S3 Filesは、「S3のスケーラビリティ・耐久性」と「ファイルシステムの使い勝手」を両立させる画期的な機能です。NFS経由のPOSIX準拠アクセス、インテリジェントな読み取りルーティング、S3との双方向同期を組み合わせることで、ML/AI・データ分析・既存アプリ移行など多様なワークロードに対応します。
導入にあたってはコスト構造やデータ有効期限、VPCネットワーク設計、非サポート機能の確認が重要です。公式ドキュメントのチュートリアルを参考に、まずは開発環境での検証から始めることをおすすめします。2026年4月時点で34リージョンで利用可能です。
























