



Google CloudのAlloyDB for PostgreSQLに、HAアーキテクチャを拡張する新機能「ホットスタンバイ(hot standby)」が一般提供されました。スタンバイノードを常時レプリカとして稼働させ、フェイルオーバー時の昇格を高速化し、切り替え直後もキャッシュが温まった状態でクエリ性能を維持することを狙った設計です。本稿ではPostgreSQLを運用するインフラエンジニア視点で、従来のコールドスタンバイ型との違い、メカニズム、適用条件、他のマネージドDBとの比較観点を公式ドキュメントに沿って整理します。
AlloyDBホットスタンバイが解こうとしている課題
マネージドDBの可用性設計で悩ましいのは、フェイルオーバーの所要時間そのものだけではありません。公式ドキュメントは、ホットスタンバイの目的を「AlloyDBのHAアーキテクチャを拡張し、フェイルオーバー時間の改善と、フェイルオーバー後の一貫したパフォーマンスを担保すること」と説明しています。「速さ」と「切り替え直後の安定性」の双方が機能設計の主眼に据えられています。
AlloyDBのHAインスタンスは公式に「業界トップクラスの99.99%可用性SLA」をうたい、別ゾーンのスタンバイへの自動フェイルオーバーを基本動作としてきました。一方で従来構成では、フェイルオーバー直後のバッファキャッシュが冷えた状態から始まりやすく、切替直後のクエリレイテンシが一時的に悪化する点が運用上意識されがちでした。ホットスタンバイはこのキャッシュウォームアップ問題に正面から取り組むアップデートと位置付けられます。
従来のコールドスタンバイ型フェイルオーバーとの違い
従来のAlloyDBのHA構成は、別ゾーンに配置されたactiveノードとstandbyノードの2台でプライマリインスタンスを構成し、ヘルスチェックで不健全を検知した際にスタンバイへ自動フェイルオーバーする方式でした。2023年6月17日のGoogle Cloudブログ「Understanding AlloyDB business continuity capabilities」では、この自動フェイルオーバーが「DBサイズと負荷に依存せず60秒以内に完了する」と紹介されています。ここで重要なのは、この60秒という値はホットスタンバイ登場以前のアーキテクチャに関する公式表現であり、ホットスタンバイ導入後の新しいRTOを示す数値ではない点です。
従来構成は概念的にコールドスタンバイ寄りの挙動でした。スタンバイノードは平常時に読み取りトラフィックを引き受けず、プライマリ昇格を機にread-write状態へと立ち上げ直す流れです。書き込みパスが復旧してもバッファプールはほぼ空に近く、ワーキングセットの再ロードに時間を要するため、フェイルオーバー直後はディスクI/Oが増えがちでした。ホットスタンバイはここを反転させ、スタンバイをreplicaとして常時稼働させ、平常時からレプリケーションを受けてバッファをウォーム状態に保つ発想に切り替えています。
高速化を支える技術メカニズム
公式ドキュメントは、ホットスタンバイの仕組みを「With the hot standby feature, AlloyDB runs the standby node as a replica. During failover, this replica can transition to a read-write mode faster, reducing downtime.」と説明しています。さらに「the replication enables warm caches, which helps ensure consistent query performance after failover.」と続け、切り替え後のクエリ性能の一貫性をキャッシュウォーム化に求める設計意図を明確に示しています。
これを下支えしているのがAlloyDB特有のdisaggregatedアーキテクチャです。コンピュート層とストレージ層が分離され、ストレージ層はLog storage service、Log processing service、Block storage serviceに分かれてリージョン内3ゾーンに分散します。WALログとブロックストレージが別レイヤとして扱われるため、スタンバイ昇格時に大量データをコピーする必要がなく、共有ストレージに対してコンピュートの役割を切り替える発想に近い動きが可能です。ホットスタンバイは、この共有ストレージ前提の上で、コンピュート側のキャッシュ温度まで継続的に維持する拡張と捉えられます。
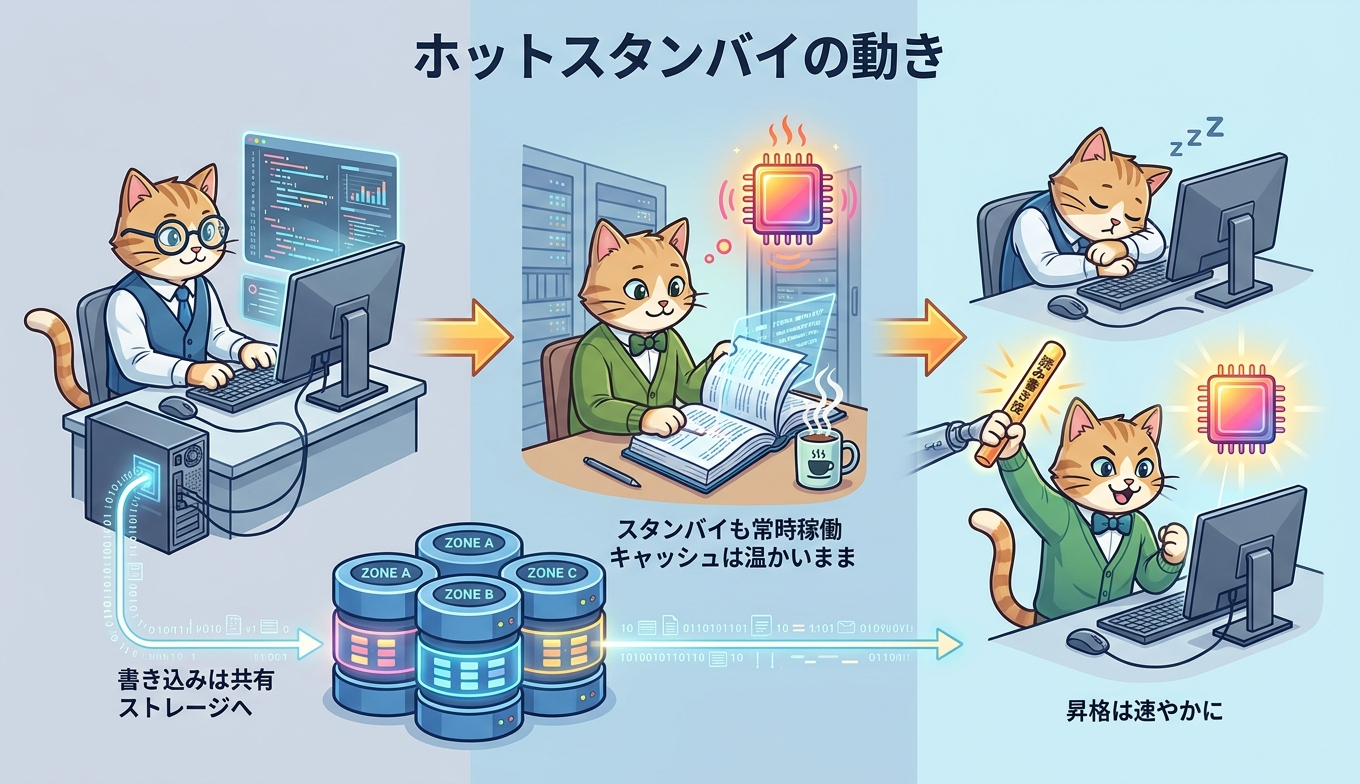
なお、フェイルオーバーが具体的に何秒に短縮されたかについて、公式ドキュメントは現時点で具体的な秒数を公表していません。リリースノートとHAドキュメントの表現は「improve failover times」「transition to a read-write mode faster, reducing downtime」「consistent query performance after failover」といった定性的な記述にとどまります。本稿でも数値の断定は避け、メカニズムの差分にフォーカスする姿勢を取ります。
適用条件と既存クラスタからの移行経路
適用条件はシンプルです。リリースノート2026年3月31日付エントリでは「This feature is generally available (GA) in PostgreSQL 18 and is automatically enabled for all new instances.」と明記され、HAドキュメントでも「Newly created AlloyDB instances with PostgreSQL 18 provide improved failover using the hot standby feature.」と表現されています。対象はPostgreSQL 18で新規作成されたAlloyDBインスタンスで、ユーザー側でオプションを有効化する操作は不要です。
既存クラスタへの適用や、PostgreSQL 14/15/16/17への展開時期について、公式ドキュメント、リリースノート、関連ブログのいずれにも「今後数カ月で展開」といった明確なロードマップ表現は確認できませんでした。したがって他バージョンへの展開予定は断定せず、将来的な展開可能性として読み解くにとどめるのが安全です。
一方、既存資産からPostgreSQL 18へ到達するルートそのものは整備が進んでいます。リリースノート2026年3月25日付エントリでAlloyDBにおけるPostgreSQL 18互換性がGAとなり、PostgreSQL 14/15/16/17から18へワンクリックでアップグレード可能です。2026年5月12日にはGoogle Cloud Blogで「Postgres 18 and Extended Support for legacy versions in AlloyDB」も公開されています。
他マネージドDBとのフェイルオーバー設計比較
他社のマネージドDBと比較する際は、優劣ではなく「設計思想の違い」を押さえると整理しやすくなります。ここでは公開仕様に基づき、フェイルオーバーの仕組みの観点だけを並べます。
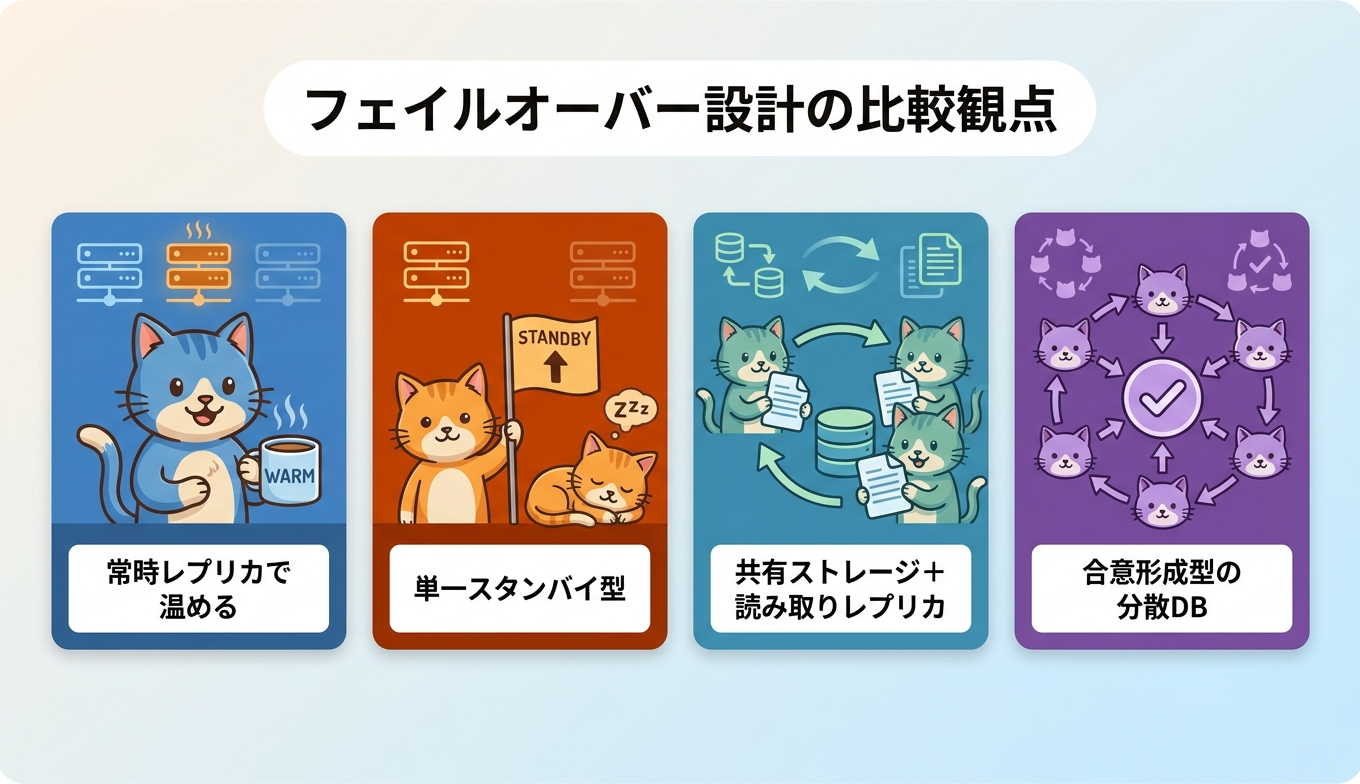
Amazon RDSのMulti-AZ DB instance構成では、スタンバイは別AZへ同期レプリケーションされる一方、AWSの公式ドキュメントは「You can't use a standby replica to serve read traffic.」と明示しており、平常時に読み取りに使うモデルではありません。これに対しMulti-AZ DB cluster構成では「standby DB instances that provide failover support and can also serve read traffic.」と明記され、スタンバイ的なノードが読み取りトラフィックを引き受けます。
Amazon Auroraはストレージとコンピュートを分離し、6コピーを3 AZに同期する設計です。Aurora Replicaは最大15台まで配置でき、平常時から読み取りに参加します。Aurora ReplicaがあるケースのフェイルオーバーはAWSドキュメントで「service is typically restored in less than 60 seconds, and often less than 30 seconds.」と表現されています。Cloud SQL for PostgreSQLのHA構成は、各ゾーンのpersistent diskへの同期レプリケーションでデータ永続性を担保するモデルで、フェイルオーバー時の不可用時間は公式に「about sixty seconds」と表現されています。Cloud Spannerは複数ゾーンへの自動レプリケーションとquorum書き込みを前提とした分散DBで、プライマリ→スタンバイ昇格モデル自体が当てはまらない領域です。
AlloyDBホットスタンバイの位置づけは、こうしたスペクトラムの中で「ストレージ・コンピュート分離型アーキテクチャの上で、スタンバイノードを常時レプリカとして暖めておくモデル」と読み解けます。フェイルオーバー直後のキャッシュ温度を平常時の継続レプリケーションで整える設計が特徴です。
運用設計への示唆と次の一手
ホットスタンバイが運用設計にもたらす示唆はいくつかあります。第一に、フェイルオーバー直後のSLO観点での見直し余地です。これまではキャッシュウォームアップ期間を見越したアラートしきい値やオートスケール挙動を組んでおく必要がありましたが、キャッシュ温度の維持が公式設計に組み込まれたことで、切り替え直後の挙動に関する前提を再点検する価値が出ています。
第二に、リージョン障害への備えの整理です。AlloyDBのHAアーキテクチャはあくまでリージョン内ゾーン冗長で、リージョン跨ぎのDRはクロスリージョンレプリケーションが担います。secondaryクラスタが別リージョンで独自のストレージとコンピュートを持つ構造を踏まえ、HAとDRを別レイヤの保護として整理しておくと迷子になりにくくなります。第三に、PostgreSQL 18採用のロードマップ化です。本機能はPostgreSQL 18の新規インスタンスが対象なので、新規構築系から段階的に18へ寄せる設計が現実的です。課金や書き込みレイテンシへの影響など公式に明示されていない論点は、自社ワークロードでの検証を通じて自分たちの数字を持つアプローチが引き続き有効です。
参考リンク
- AlloyDB high availability overview(公式ドキュメント)
- AlloyDB release notes(公式ドキュメント)
- AlloyDB overview(公式ドキュメント)
- AlloyDB Fail over a primary or secondary instance manually(公式ドキュメント)
- AlloyDB cross-region replication overview(公式ドキュメント)
- AlloyDB for PostgreSQL intelligent scalable storage(Google Cloud Blog)
- Understanding AlloyDB business continuity capabilities(Google Cloud Blog, 2023-06-17)
- Postgres 18 and Extended Support for legacy versions in AlloyDB(Google Cloud Blog, 2026-05-12)
- Cloud SQL for PostgreSQL high availability(公式ドキュメント)
- Cloud Spanner regional/multi-region configurations(公式ドキュメント)
- Cloud Spanner SLA
- Amazon RDS Multi-AZ deployments(公式ドキュメント)
- Amazon Aurora High availability(公式ドキュメント)
























