



時系列予測の現場では、単一の指標を追いかける単変量予測だけでなく、複数の指標が絡み合う多変量予測や、外部要因(共変量)を踏まえた予測が当たり前に求められます。Amazon が公開した時系列予測基盤モデル Chronos-2 は、こうした多様な予測タスクを追加学習なしのゼロショットで一手に引き受けます。本記事では Chronos-2 が何を変えるのか、その仕組みと実力、そして導入方法をエンジニア目線で整理します。
Chronos-2 が切り開く普遍的な時系列予測
Chronos-2 は Amazon Science が開発した時系列予測の基盤モデル(Time Series Foundation Model)です。最大の特徴は、単変量予測にとどまらず、多変量予測や共変量付き予測といった任意の予測タスクをゼロショットで処理できる点にあります。従来は予測対象や入力の構造が変わるたびにモデルを組み直したり再学習したりする必要がありましたが、Chronos-2 は学習済みの状態のまま、与えられた文脈に応じて柔軟に対応します。
対応タスクの幅は広く、単変量予測に加えて、アイテム横断のクロスラーニング、複数系列を同時に扱う多変量予測、過去のみ観測できる共変量(実数およびカテゴリ)、将来の値が既知の共変量(実数およびカテゴリ)までを一つのモデルでカバーします。需要予測でプロモーションの予定を入力に加えたり、インフラ監視で複数のメトリクスを相互に参照したりといった実務上のニーズに、追加学習という重い工程を挟まずに応えられます。
Chronos ファミリーはこれまでに累計 6 億回以上ダウンロードされており、時系列予測の領域で広く使われてきた実績があります。Chronos-2 はその系譜を受け継ぎつつ、単変量から普遍的な予測へと適用範囲を大きく広げた世代に位置づけられます。
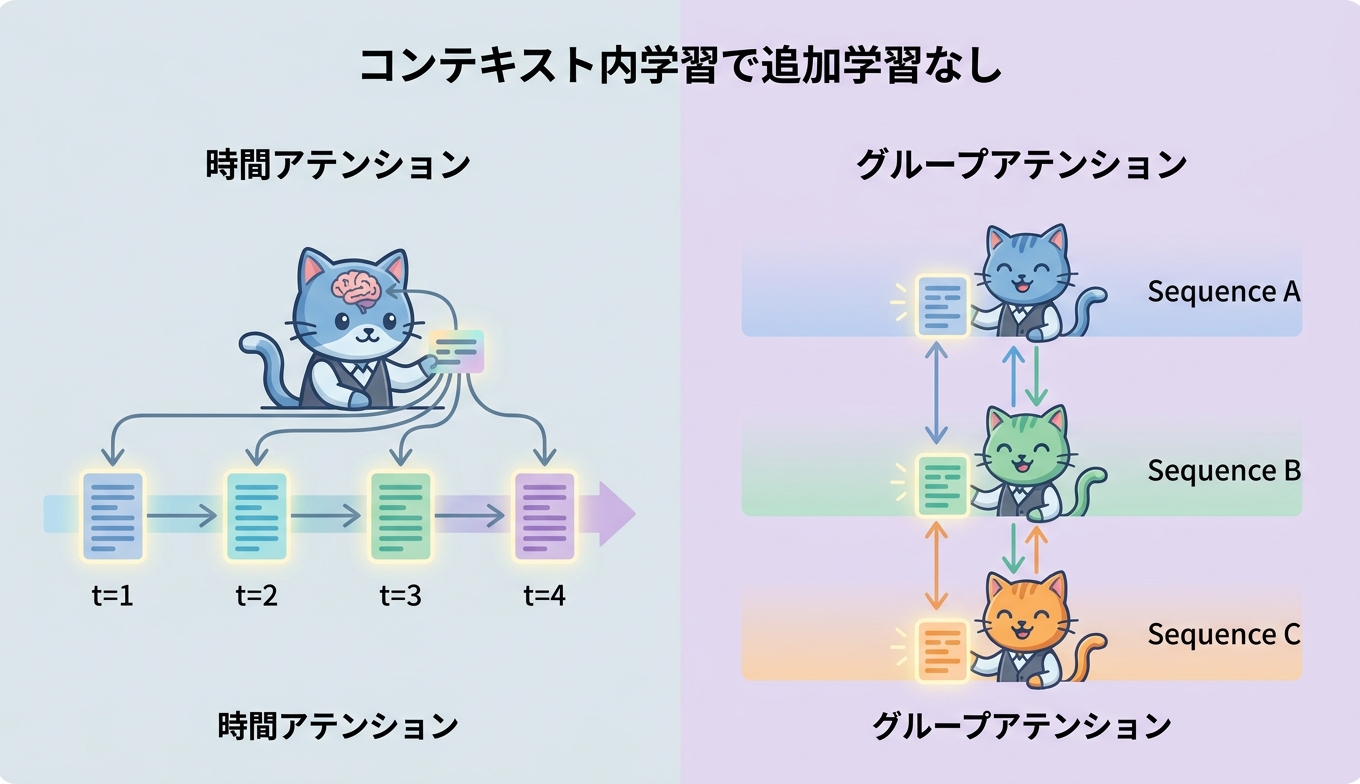
グループアテンションとコンテキスト内学習が支える仕組み
Chronos-2 のゼロショット性能を支えているのが、コンテキスト内学習(In-Context Learning、ICL)とグループアテンションという二つの要素です。ICL は、与えられた文脈から予測タスクの構造をその場で読み取り、任意の次元数の予測をゼロショットで解く能力をモデルにもたらします。単変量予測においても、複数の系列間で情報を共有するクロスラーニングが働くことで、より精度の高い予測につながります。
グループアテンションは、複数の時系列のあいだに存在する相互作用を捉えるための機構です。Chronos-2 では時間方向のアテンション層とグループ方向のアテンション層が組み合わさっています。時間アテンション層が単一の時系列の中でパッチ間の情報を集約するのに対し、グループアテンション層は各パッチインデックスにおいてグループ内のすべての系列間で情報を集約します。これにより、たとえばクラウドのメトリクスを予測する際に CPU 使用率のパターンからメモリ消費量の予測を補強したり、プロモーションの予定という共変量を需要予測に反映したりできます。
アーキテクチャは T5 のエンコーダに着想を得たエンコーダオンリー構成です。入力された時系列はロバストスケーリングで正規化されたあと、重ならないパッチへ分割され、残差ネットワークによって高次元の埋め込みへ変換されます。トランスフォーマースタックがこれらのパッチ埋め込みを処理し、マスクされた将来のパッチに対応するマルチステップの分位点予測を出力します。点推定だけでなく分位点を返すため、予測の不確実性を踏まえた意思決定にも使いやすい設計です。
合成データで汎用性を獲得した学習戦略
普遍的に使える時系列基盤モデルを学習させるには、多変量の依存関係や有益な共変量を含む多様なデータが必要です。ところが、こうした高品質な事前学習データは現実には不足しています。Chronos-2 はこの課題を、合成データの生成によって解決しています。
具体的には、ベースとなる単変量の生成器から時系列をサンプリングし、それらに多変量構造を付与することで学習データを作り出します。系列同士の関係性や共変量の効果を人工的に作り込むことで、実データだけでは確保しにくい多様性を担保し、未知のタスクへのゼロショット対応力を養っています。実際の業務データに依存しすぎず、幅広いパターンを学べる点が、適用範囲の広さにつながっています。
この学習戦略は、特定ドメインへの過剰適合を避け、初見のデータでも安定した予測を出すうえで効いてきます。利用する側からすると、自前のデータでファインチューニングを行わなくても、そのまま当てはめて一定の精度を期待できるという利点になります。
ベンチマークで示された予測精度
Chronos-2 は、時系列予測の代表的なベンチマークである fev-bench、GIFT-Eval、Chronos Benchmark II において、公開モデルの中でゼロショット精度の最高水準を達成しています。汎用性を高めた基盤モデルが、精度の面でも妥協していないことを示す結果です。
とりわけ fev-bench では、平均勝率 90.7 パーセント、スキルスコア 47.3 パーセント(SQL メトリック)を記録しました。次点のモデルである TiRex の勝率 80.8 パーセント、スキルスコア 42.6 パーセントを明確に上回っており、差は小さくありません。GIFT-Eval でも事前学習モデルの中で 1 位に立ち、TimesFM-2.5 や TiRex を加重分位点損失(WQL)と平均絶対スケール誤差(MASE)の両方で上回っています。
世代間の比較でも進歩は明確です。前世代の Chronos-Bolt との直接対決では、Chronos-2 が 90 パーセントを超える勝率を収めています。多変量や共変量への対応という機能面の拡張だけでなく、単変量予測そのものの精度も着実に底上げされていることがわかります。

推論効率と導入方法
Chronos-2 はパラメータ数が 120M とコンパクトで、推論効率の高さも見どころです。単一の A10G GPU で 1 秒あたり 300 を超える時系列の予測を生成でき、GPU だけでなく CPU での推論にも対応しています。比較的軽量な GPU でも実用的なスループットが出るため、運用コストを抑えながらバッチ予測やオンライン予測を回しやすい構成です。最大コンテキスト長は 8192、最大予測長は 1024 と、長めの履歴や予測期間にも対応します。
導入経路も整っています。モデルは Apache-2.0 ライセンスのもとオープンソースとして公開されており、Hugging Face のモデルカードから利用できます。さらに Amazon SageMaker 上へデプロイするためのノートブックや、GitHub のリポジトリも提供されています。手元の環境で試すところから、本番のマネージド推論環境への展開まで、段階を踏んで進められます。
ライセンスが寛容で、軽量なハードウェアでも動かせることから、検証のハードルは低めです。まずは自社の時系列データを与えてゼロショットの精度を確かめ、必要に応じて共変量を足していくといった試し方が現実的でしょう。
エンジニアの実務にもたらす変化
Chronos-2 がもたらす最も大きな変化は、予測タスクごとにモデルを設計し学習させるという前提が崩れる点にあります。単変量から多変量、共変量付きまでを一つのモデルで賄えるため、予測基盤のアーキテクチャをシンプルに保てます。タスクが増えるたびにパイプラインを増設するのではなく、入力の与え方を変えるだけで対応できる場面が増えていきます。
想定されるユースケースは幅広く、複数メトリクスを相互参照するクラウドリソースの監視や、プロモーション情報を加味した需要予測、相関のある指標群をまとめて扱う在庫やトラフィックの予測などが挙げられます。共変量を素直に渡せる設計は、ドメイン知識をモデルに反映させたいエンジニアにとって扱いやすいはずです。
もちろん、すべての予測課題が基盤モデル一つで解決するわけではありません。ただし、ゼロショットで一定水準の精度がすぐ得られるという出発点は、検証サイクルを速め、専用モデルを作るべき領域とそうでない領域を見極める助けになります。Chronos-2 は、時系列予測を始めるときの第一の選択肢として検討する価値のあるモデルです。
























