



AWS DevOps Agentとは何か
AWS DevOps Agentは、AWSが提供するインシデント対応自動化サービスです。生成AIをベースにした自律型エージェントが、アラートを受け取った瞬間から根本原因の特定まで、人間の代わりに調査を行います。
従来のインシデント対応ツールとの大きな違いは、「ルールベースの自動化」ではなく「自律的な推論と調査」を行う点です。たとえばCloudWatchのアラームが発火したとき、単純なツールであれば「このアラームが発火したらSlackに通知する」というルールを実行するだけです。AWS DevOps Agentは違います。アラームが発火したら、関連するメトリクスを自動で調査し、ログを解析し、デプロイ履歴と照らし合わせ、「直近のコードデプロイ後からエラーレートが上昇しており、特定のサービスへのAPI呼び出しがタイムアウトしている」といった形で根本原因を特定してきます。
処理の流れを整理すると、大きく以下のようなステップで動作します。
フェーズ | エージェントが行うこと |
|---|---|
トリガー | CloudWatchアラーム、Datadogアラート、外部Webhookなどのイベントを受信する |
コンテキスト収集 | 関連するメトリクス、ログ、トレース、デプロイ履歴、設定変更などを収集する |
推論・分析 | 収集した情報をもとに原因仮説を立て、追加調査を行い、根本原因を絞り込む |
レポート生成 | 調査結果と推奨アクションを含むインシデントレポートを生成する |
通知 | SlackやPagerDutyなどを通じて担当者に結果を通知する |
ぶっちゃけた話、これは「AIが全部やってくれる魔法のツール」ではないです。人間のエンジニアが最終的な判断と対応を行う必要がある場面は多い。ただ、初動調査に費やしていた2〜3時間が数分になることで、エンジニアが「何が起きているのか把握するフェーズ」をほぼスキップして「どう直すかを考えるフェーズ」から始められるようになります。これは体感的には相当大きい差です。
また、深夜帯に認知機能が落ちた状態で生ログを解析するのと、エージェントが整理したサマリーを見て判断するのとでは、判断の質も変わってきます。MTTRの短縮は数字の話だけじゃなくて、エンジニアのウェルネスという観点でも意味があります。
Agent Spaceとは何か、なぜ重要なのか
AWS DevOps Agentを使いこなすうえで、最も理解が必要な概念が「Agent Space」です。これを正しく設計できるかどうかで、エージェントの有効性が大きく変わります。
Agent Spaceを一言で表すなら、「エージェントがアクセスおよび調査できる範囲を定義する論理的なコンテナ」です。エージェントはAgent Spaceの外にあるリソースには一切アクセスできません。逆に言えば、Agent Space内に含まれるリソースに対しては、定義された権限の範囲で自律的に調査を行えます。
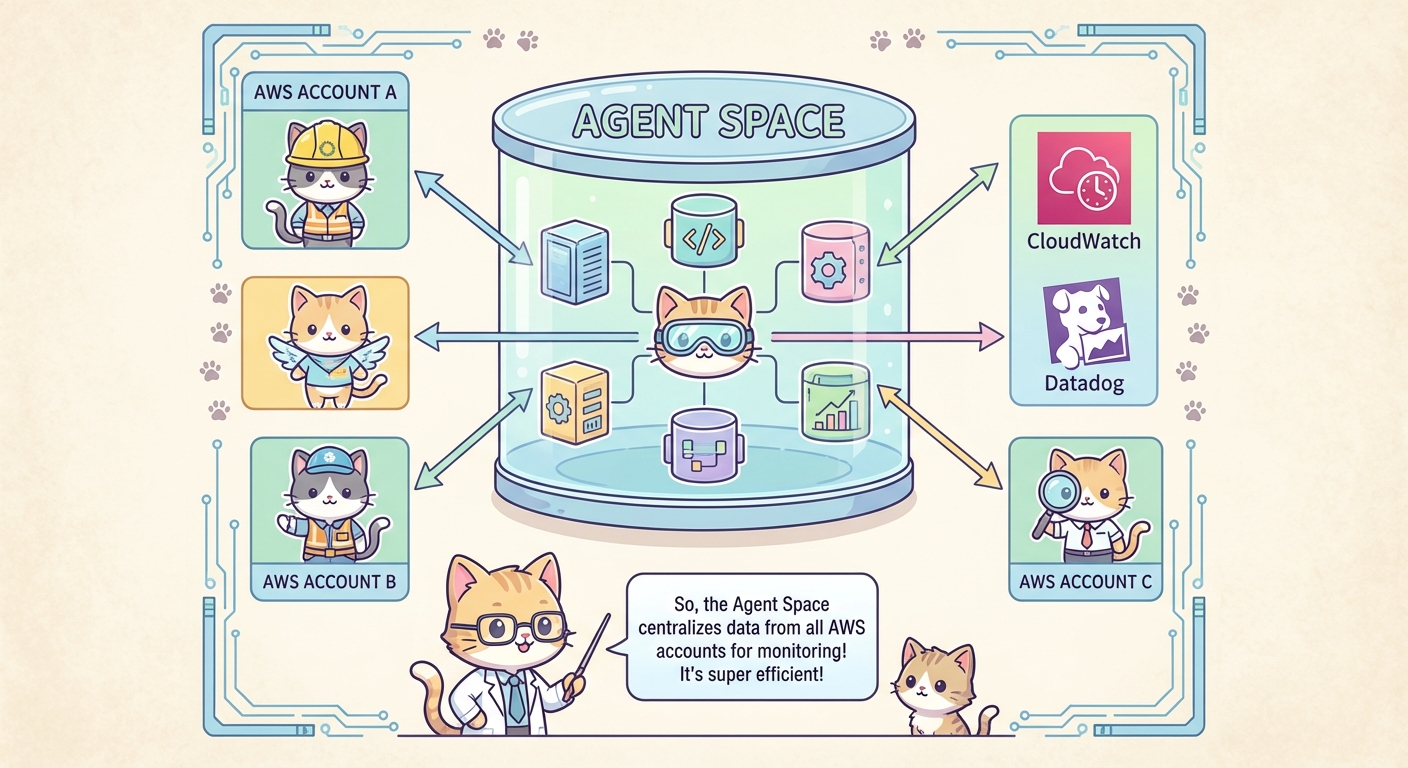
なぜこの概念が重要なのか。それはセキュリティとコンテキストの2つの観点から説明できます。
セキュリティの観点では、自律的に動作するエージェントに無制限のアクセス権を与えるのは当然リスクがあります。Agent Spaceによってアクセス範囲を明示的に制限することで、「このエージェントはこのAWSアカウントのこのリソースにしかアクセスできない」という状態を保証できます。最小権限の原則をエージェントにも適用するということです。
コンテキストの観点では、調査範囲が広すぎると逆効果です。Eコマースサービスのインシデントを調査しているのに、社内ツールのメトリクスや機械学習プラットフォームのログまで読み込んでいたら、ノイズが増えて根本原因の特定が難しくなります。オンコールの担当者が「自分の責任範囲のシステム」を把握した上で調査するのと同じように、エージェントにも適切なスコープを与えることで調査の精度が上がります。
Agent Spaceには、複数のAWSアカウント、CloudWatch、Datadog、GitHub、PagerDutyなどの外部サービスとの統合設定、そしてIAMベースのアクセス制御設定が含まれます。単なる「見せる範囲の設定」ではなく、エージェントのアイデンティティそのものを定義するものといえます。
Agent Space設計のベストプラクティス:3つのパターン
Agent Spaceの設計には、組織の構造やシステム構成によってさまざまなアプローチがあります。AWSが推奨しているのは「オンコールの責任範囲と同じように考える」という考え方です。担当者がオンコール中にアクセスするシステムや情報と、エージェントのAgent Spaceを対応させるわけです。
また、本番環境と非本番環境は必ず分離することが基本原則です。開発環境の異常が本番環境の調査にノイズを持ち込む状況は避けなければなりません。本番インシデントの調査中に開発環境のデプロイによるメトリクス変動が混入してきたら、エージェントの判断が狂います。
パターン1:複数チームにまたがる調査が必要なケース
マイクロサービスアーキテクチャを採用している組織では、ひとつのインシデントが複数チームのサービスにまたがることがよくあります。フロントエンド、バックエンドAPI、決済サービス、在庫管理——これらが連携している場合、どこで問題が発生しているかを特定するには横断的な調査が必要です。
このパターンでは、各チームのリソースへの読み取り専用アクセスを持つAgent Spaceを作成します。重要なのは「読み取り専用」という点です。複数チームのリソースへの書き込み権限をエージェントに与えるのは、インシデント対応のスコープを超えてしまいます。あくまで調査目的に限定することで、予期せぬ副作用を防ぎます。
項目 | 設定内容 |
|---|---|
対象チーム | Frontend、Backend API、Payment、Inventoryなど複数チーム |
アクセス種別 | 読み取り専用(CloudWatchメトリクス、ログ、トレース) |
AWSアカウント | 各チームの本番アカウントすべてを含める |
利用シーン | サービス間の依存関係によるカスケード障害の調査 |
このパターンの注意点として、Agent Spaceに含めるアカウント数が増えるほど、エージェントの調査に時間がかかります。闇雲にすべてのアカウントを含めるのではなく、実際に依存関係があるサービスのアカウントに絞り込むことが大切です。
パターン2:共有サービスとNOCチームのケース
プラットフォームチームやSREチームが共有インフラを管理している組織では、専用のAgent Spaceを用意するパターンが有効です。データベース、メッセージキュー、認証基盤、CDNなど、複数のアプリケーションチームが利用する共有サービスに対して、NOC(Network Operations Center)や中央SREチームが一元的に調査できる環境を整えます。
このパターンでは、アプリケーションチームのAgent Spaceとは別に、共有インフラ専用のAgent Spaceを作成します。アプリケーション側のエージェントが「自分のサービスには問題なさそうだ、共有インフラ側に原因があるかも」と判断したとき、NOCチームが共有インフラ用のAgent Spaceで追加調査を行えるという分業体制が作れます。
Agent Space | 担当チーム | 含まれるリソース |
|---|---|---|
AppTeam-Prod | 各アプリケーションチーム | 自チームのサービスリソース |
SharedInfra-Prod | SRE / NOCチーム | DB、MQ、認証基盤、CDN等 |
Network-Prod | ネットワークチーム | VPC、Transit Gateway、Direct Connect等 |
インシデントの「所有権」がどこにあるかを明確にするという意味でも、このパターンは組織的な責任分担を技術的な設定として表現できるメリットがあります。
パターン3:中央運用チームによる大規模管理
大規模な組織や、数十〜数百のAWSアカウントを管理しているケースでは、Infrastructure as Code(IaC)を使ってAgent Spaceを大規模管理するパターンが現実的です。CDKやTerraformでAgent Spaceの定義をコードとして管理することで、新しいアカウントやサービスが追加されたときにも一貫した設定を維持できます。
このパターンのポイントは、Agent Spaceの設定そのものをソフトウェアエンジニアリングのプラクティスで管理するということです。設定変更はプルリクエストで行い、レビューを経てデプロイする。ドリフト検出を行い、意図しない設定変更を検知する。テスト環境で変更を検証してから本番に適用する。これらのプラクティスをAgent Spaceの管理にも適用できます。
具体的な実装については次のセクションで詳しく説明します。
実際にやってみた:CDKとCLIによる実装
では、実際のコードを見ながら実装の流れを追っていきます。ここではAWS CDKを使ったアプローチと、AWS CLIを使ったシンプルなアプローチの両方を紹介します。
前提条件の確認
Agent Spaceを作成する前に、いくつかの前提条件を確認する必要があります。まず、Agent Spaceを管理するアカウント(管理アカウント)でIAM権限が適切に設定されているかを確認します。AWS Organizationsを使用している場合は、SCPがdevopsagent関連のAPIを許可していることも確認が必要です。
モニタリング対象のアカウント側には、エージェントが引き受けるためのIAMロールを事前に作成しておく必要があります。このロールには、CloudWatchのメトリクス・ログへの読み取り権限などが必要です。
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Principal": {
"Service": "devopsagent.amazonaws.com"
},
"Action": "sts:AssumeRole"
}
]
}このトラストポリシーをモニタリング対象アカウントのIAMロールに設定することで、エージェントがそのアカウントに対して調査を行えるようになります。
CDKによるAgent Space作成
CDKを使ったAgent Space作成の実装例です。複数アカウントのアソシエーションをループで処理しているのがポイントです。アカウントが増えても配列にエントリを追加するだけで対応できます。
import * as cdk from 'aws-cdk-lib';
import * as devopsagent from 'aws-cdk-lib/aws-devopsagent';
import * as iam from 'aws-cdk-lib/aws-iam';
import { Construct } from 'constructs';
export class DevOpsAgentStack extends cdk.Stack {
constructor(scope: Construct, id: string, props?: cdk.StackProps) {
super(scope, id, props);
// Agent Space の作成
const agentSpace = new devopsagent.CfnAgentSpace(this, 'EcommerceProdAgentSpace', {
name: 'EcommerceProd',
description: 'Eコマース本番環境のインシデント調査用Agent Space',
});
// モニタリング対象アカウントの定義
// 本番アカウントのロールARNは別途作成しておく
const prodRole = iam.Role.fromRoleArn(
this, 'ProdMonitorRole',
'arn:aws:iam::111111111111:role/DevOpsAgentMonitorRole'
);
const devRole = iam.Role.fromRoleArn(
this, 'DevMonitorRole',
'arn:aws:iam::222222222222:role/DevOpsAgentMonitorRole'
);
const accounts = [
{ id: "111111111111", name: "Prod", role: prodRole, stage: "prod" },
{ id: "222222222222", name: "Dev", role: devRole, stage: "dev" },
];
// 各アカウントとのアソシエーションを作成
accounts.forEach(account => {
const association = new devopsagent.CfnAssociation(
this,
`${account.name}Association`,
{
agentSpaceId: agentSpace.ref,
serviceId: "aws",
configuration: {
aws: {
assumableRoleArn: account.role.roleArn,
accountId: account.id,
accountType: "monitor"
}
}
}
);
// アソシエーションはAgent Space作成後に行う
association.addDependency(agentSpace);
});
// CloudFormation出力
new cdk.CfnOutput(this, 'AgentSpaceId', {
value: agentSpace.ref,
description: 'Agent Space ID',
});
}
}このコードのポイントをいくつか補足します。`accountType: "monitor"` は読み取り専用のモニタリングアクセスを意味します。書き込み権限が必要なケース(例:インシデント対応の自動化アクションを含める場合)は別途検討が必要ですが、まずは読み取り専用から始めることを強く推奨します。
`association.addDependency(agentSpace)` は明示的には省略可能な場合もありますが、CDKのデプロイ順序を保証するために明示的に記述しておくほうが安全です。Agent Spaceが作成される前にアソシエーションを作ろうとすると、当然エラーになります。
AWS CLIによるシンプルな作成
CDKほど大規模な管理が不要な場合や、まず動かして試してみたいときは、AWS CLIからも作成できます。
# Agent Space の作成
aws devopsagent create-agent-space \
--name "EcommerceProd" \
--description "Eコマース本番環境のインシデント調査用" \
--region us-east-1
# 出力例
# {
# "agentSpace": {
# "agentSpaceId": "agentspace/EcommerceProd",
# "name": "EcommerceProd",
# "status": "ACTIVE",
# ...
# }
# }
# AWSアカウントとのアソシエーション作成
aws devopsagent create-association \
--agent-space-id "agentspace/EcommerceProd" \
--service-id "aws" \
--configuration '{
"aws": {
"assumableRoleArn": "arn:aws:iam::111111111111:role/DevOpsAgentMonitorRole",
"accountId": "111111111111",
"accountType": "monitor"
}
}' \
--region us-east-1CLIで作成した場合も、後からCDKでインポートして管理下に置くことができます。最初の検証フェーズはCLIで素早く試して、本番運用に移行するタイミングでIaC化するというアプローチも現実的です。
Terraformによる実装
TerraformでインフラをすでにIaC管理している組織向けの実装例も確認しておきます。CDKと同様の構成をHCLで記述できます。
terraform {
required_providers {
aws = {
source = "hashicorp/aws"
version = "~> 5.0"
}
}
}
# Agent Space の作成
resource "aws_devopsagent_agent_space" "ecommerce_prod" {
name = "EcommerceProd"
description = "Eコマース本番環境のインシデント調査用Agent Space"
}
# モニタリング対象アカウントの定義
locals {
monitoring_accounts = [
{
account_id = "111111111111"
role_arn = "arn:aws:iam::111111111111:role/DevOpsAgentMonitorRole"
name = "prod"
},
{
account_id = "222222222222"
role_arn = "arn:aws:iam::222222222222:role/DevOpsAgentMonitorRole"
name = "dev"
}
]
}
# 各アカウントのアソシエーション
resource "aws_devopsagent_association" "aws_accounts" {
for_each = { for acct in local.monitoring_accounts : acct.name => acct }
agent_space_id = aws_devopsagent_agent_space.ecommerce_prod.id
service_id = "aws"
configuration = jsonencode({
aws = {
assumableRoleArn = each.value.role_arn
accountId = each.value.account_id
accountType = "monitor"
}
})
}
output "agent_space_id" {
value = aws_devopsagent_agent_space.ecommerce_prod.id
}
TerraformのforEachを使うことで、アカウント数が増えたときもlocalsのリストを更新するだけで対応できます。Terraformのstateファイルはリソース名でアソシエーションを管理するため、アカウントの追加削除時にplan結果を必ず確認してから適用するようにしてください。
統合設定:CloudWatch、Datadog、GitHubとの連携
Agent Spaceを作成したあと、実際に機能させるには各種ツールとの統合設定が必要です。エージェントが調査に使えるデータソースが多いほど、根本原因の特定精度が上がります。逆に統合が少ないと、エージェントが「情報が足りない」状態になって曖昧な分析しか出てきません。
CloudWatchとの統合
AWS環境であれば、CloudWatchとの統合は最優先で設定すべきです。CloudWatch Logs、CloudWatch Metrics、CloudWatch Alarms、X-Rayトレースなど、AWSの標準モニタリングスタックの情報をエージェントが直接参照できるようになります。
基本的には、モニタリング対象アカウントにアタッチしたIAMロールに適切なCloudWatch読み取り権限を付与するだけで統合は完了します。ただし、ロググループの数が膨大な場合は、エージェントがどのロググループを調査すべきかを適切に判断できるよう、リソースタグを活用してグルーピングしておくことを推奨します。
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"cloudwatch:GetMetricData",
"cloudwatch:GetMetricStatistics",
"cloudwatch:ListMetrics",
"cloudwatch:DescribeAlarms",
"logs:DescribeLogGroups",
"logs:DescribeLogStreams",
"logs:GetLogEvents",
"logs:FilterLogEvents",
"logs:StartQuery",
"logs:GetQueryResults",
"xray:GetTraceSummaries",
"xray:BatchGetTraces"
],
"Resource": "*"
}
]
}
Datadogとの統合
CloudWatchだけでなく、Datadogなどのサードパーティモニタリングツールとも統合できます。多くの組織ではAWS標準のモニタリングに加えてDatadogやNew Relicを使っているので、これらのデータもエージェントの調査対象に含めることが重要です。
DatadogとのAssociation設定はAWSコンソールまたはAPIから行います。DatadogのAPIキーとアプリケーションキーをAWS Secrets Managerに保存しておき、そのARNを参照する形で設定します。
// Datadogの認証情報をSecrets Managerで管理
const datadogSecret = new secretsmanager.Secret(this, 'DatadogCredentials', {
secretName: '/devopsagent/datadog/credentials',
generateSecretString: {
secretStringTemplate: JSON.stringify({
apiKey: 'YOUR_DATADOG_API_KEY',
appKey: 'YOUR_DATADOG_APP_KEY',
}),
generateStringKey: 'dummy', // 実際はManual rotationで設定
},
});
// Datadogとのアソシエーション
const datadogAssociation = new devopsagent.CfnAssociation(
this,
'DatadogAssociation',
{
agentSpaceId: agentSpace.ref,
serviceId: "datadog",
configuration: {
datadog: {
secretArn: datadogSecret.secretArn,
site: "datadoghq.com" // または datadoghq.eu 等
}
}
}
);
Datadogとの統合によって、APMのトレース、カスタムメトリクス、Datadogのダッシュボードに表示されているSLI/SLOの状況なども調査対象に入ります。CloudWatchだけでは見えない、アプリケーションレベルのパフォーマンス情報を活用できます。
GitHubとの統合
インシデントの根本原因として「直近のデプロイによるコード変更」が疑われるケースはかなり多いです。GitHubとの統合を設定しておくと、エージェントがコミット履歴やプルリクエストの内容まで参照できるようになり、「このデプロイで何が変わったか」をインシデント調査の文脈に含められます。
// GitHub Personal Access Token または GitHub App のシークレット
const githubSecret = new secretsmanager.Secret(this, 'GitHubToken', {
secretName: '/devopsagent/github/token',
});
// GitHubとのアソシエーション
const githubAssociation = new devopsagent.CfnAssociation(
this,
'GitHubAssociation',
{
agentSpaceId: agentSpace.ref,
serviceId: "github",
configuration: {
github: {
secretArn: githubSecret.secretArn,
organization: "your-github-org",
repositories: [
"ecommerce-backend",
"ecommerce-frontend",
"shared-infrastructure"
]
}
}
}
);
GitHubとの統合で注意すべき点として、リポジトリへのアクセス範囲は必要最小限に絞ることです。全リポジトリへのアクセスを許可するのではなく、対象のAgent Spaceが担当するサービスのリポジトリのみに限定してください。
WebhookとMCP Serverによる高度な統合
CloudWatchやDatadog以外のカスタムデータソースとの統合には、WebhookとMCP(Model Context Protocol)Serverを活用できます。社内独自のデータベースや、AWSが標準でサポートしていない監視ツールとの連携に使えます。
MCP Serverを経由することで、エージェントが呼び出せるカスタムツールを定義できます。たとえば「社内のCMDB(構成管理データベース)から特定のサービスの依存関係情報を取得する」というツールをMCP Serverとして実装しておけば、エージェントがインシデント調査中にそのツールを自律的に呼び出すことができます。
// MCP Server Endpointとのアソシエーション
const mcpAssociation = new devopsagent.CfnAssociation(
this,
'McpServerAssociation',
{
agentSpaceId: agentSpace.ref,
serviceId: "mcp",
configuration: {
mcp: {
endpointUrl: "https://your-mcp-server.internal.example.com/mcp",
secretArn: mcpAuthSecret.secretArn,
description: "社内CMDBとデプロイ管理システムへのアクセス"
}
}
}
);
MCP Serverの実装自体はAWS Lambda + API GatewayやECS Fargateで構築するのが一般的です。外部に公開する必要はなく、VPC内のプライベートエンドポイントとして実装できます。
アクセス制御:IAMポリシーの設計
Agent Spaceを作成したあと、誰がそのAgent Spaceを使って調査を開始できるか、また調査結果を参照できるかを制御する必要があります。IAMポリシーによってこれを細かく制御できます。
基本的なIAMポリシー構成
devopsagent APIへのアクセスは、標準のIAMポリシーで制御します。Agent Spaceごとにリソースを指定することで、特定のAgent Spaceへのアクセスのみを許可するポリシーを作れます。
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "AllowDevOpsAgentInvestigation",
"Effect": "Allow",
"Action": [
"devopsagent:GetAgentSpace",
"devopsagent:StartInvestigation",
"devopsagent:GetInvestigation",
"devopsagent:ListInvestigations"
],
"Resource": "arn:aws:devopsagent:us-east-1:123456789012:agentspace/EcommerceProd"
}
]
}
このポリシーをアタッチされたIAMユーザーまたはロールは、EcommerceProd Agent Spaceに対してのみ調査を開始・参照できます。他のAgent Spaceにはアクセスできません。
役割別のポリシー設計
組織内の役割に応じて、以下のようなポリシー設計が一般的です。
役割 | 許可するアクション | 対象リソース |
|---|---|---|
オンコール担当者 | StartInvestigation, GetInvestigation, ListInvestigations | 自チームのAgent Space |
SRE / プラットフォームチーム | 上記に加えてCreateAssociation, UpdateAgentSpace | 管理対象のAgent Space全て |
セキュリティ監査担当 | GetAgentSpace, ListAgentSpaces, GetInvestigation(読み取りのみ) | 全Agent Space(監査目的) |
Agent Space管理者 | 全devopsagentアクション | 全Agent Space |
SCPによる組織レベルの制御
AWS Organizationsを利用している場合、SCPでdevopsagent関連APIへのアクセスを組織レベルで制御することもできます。特定のOUでしかAgent Spaceを作れないようにする、といった制限をかけることで、意図しないアカウントでAgent Spaceが作成されるリスクを防げます。
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "DenyDevOpsAgentOutsideApprovedAccounts",
"Effect": "Deny",
"Action": [
"devopsagent:CreateAgentSpace",
"devopsagent:DeleteAgentSpace"
],
"Resource": "*",
"Condition": {
"StringNotEquals": {
"aws:PrincipalAccount": [
"123456789012",
"234567890123"
]
}
}
}
]
}
このSCPはAgent Spaceの作成・削除を承認済みアカウント(管理アカウントなど)からのみ許可します。各開発チームのアカウントでは、Agent Spaceの調査機能のみを使えるという制限をかけられます。
アンチパターンと注意点
AWS DevOps Agentの導入で失敗しやすいパターンをいくつか紹介します。実際に運用してみると「やっておけばよかった」「やってしまった」という反省点が出てくるので、先に知っておくことで回避できます。
アンチパターン1:Agent Spaceに何でも詰め込む
「たくさん見えるほうが良い調査ができる」という発想で、Agent Spaceに大量のアカウントやリソースを詰め込むのはやめたほうがいいです。エージェントの調査範囲が広すぎると、調査時間が長くなるうえに、ノイズの多い分析結果が出てくることがあります。
Agent Spaceはオンコールの責任範囲と対応させる、という原則を守ることが重要です。「このインシデントで実際に調査が必要になるリソース」だけを含めるという絞り込みの感覚が大切です。後から追加するほうが、最初から盛りすぎるよりずっと安全です。
アンチパターン2:本番と非本番を同じAgent Spaceで管理する
コスト節約や管理の簡略化を目的として、本番環境と開発環境を同じAgent Spaceに含めるのは避けてください。開発環境での意図的な高負荷テストやデプロイがエージェントの分析に混入し、本番インシデントの根本原因特定が困難になります。
「本番/非本番は必ず分離する」はAgent Space設計の絶対原則と思っておいてください。管理の手間は増えますが、調査精度への影響を考えると分離は必須です。
アンチパターン3:IaC管理なしで手動運用する
最初の検証フェーズはCLIで手動作成しても構いません。ただし、そのまま本番運用に入ってしまうと、Agent Spaceの設定がいつの間にかドリフトしていたり、担当者しか設定内容を把握していない状況が生まれます。
本番稼働前には必ずIaC化してください。CDKでもTerraformでもCloudFormationでも、選択肢は組織の状況に合わせて構いません。設定をコードとして管理し、変更履歴を残し、レビューを経てデプロイするというプロセスを整えることが重要です。
アンチパターン4:統合設定を最小限にしたまま運用する
CloudWatchだけ繋いでとりあえず動かしてみた、という状態で「エージェントの分析が浅い」と感じるケースがあります。エージェントの調査品質は、利用できるデータソースの質と量に直結します。
Datadog、GitHub、PagerDutyなど、インシデント調査で実際に参照するツールを積極的に統合してください。統合を追加するたびにエージェントの調査能力が上がることを体感できるはずです。
アンチパターン5:エージェントの出力を盲目的に信頼する
これは技術的な話というよりは運用面の話ですが、重要です。エージェントが出す根本原因分析は高精度ですが、100%正確ではありません。特に複雑な依存関係があるシステムや、過去に類例のないインシデントでは、エージェントの推論が的外れになることもあります。
エージェントの出力はあくまで「調査の出発点」として扱い、担当エンジニアが最終確認を行う体制を維持することが大切です。エージェントが「これが原因です」と言っても、エンジニアが「本当にそうか?」と確認するステップは省かないようにしてください。
IAMロールの過剰な権限付与
モニタリング対象アカウントのIAMロールに、CloudWatch読み取り以上の権限を与えてしまうケースがあります。「調査中にリソースを再起動できたら便利」という発想は理解できますが、エージェントが自律的に本番環境のリソースを変更できる状態を作るのは慎重に検討すべきです。
読み取り専用で始めて、書き込み系のアクションは人間が承認した上でのみ実行されるフローを設計することを推奨します。
運用フェーズでの継続的改善
Agent Spaceを設定して終わりではなく、実際のインシデント対応での使用経験をもとに継続的に改善していく必要があります。
最初の数ヶ月は、エージェントの分析結果と実際の根本原因を照合して精度を評価してください。エージェントが的中したケースと外れたケースのパターンを分析することで、統合が不足しているデータソースや、Agent Spaceの設計上の問題点が見えてきます。
また、チームの構成変更やシステムアーキテクチャの変化に合わせて、Agent Spaceの設定も更新していく必要があります。新しいマイクロサービスが追加されたときに、そのAWSアカウントをAgent Spaceに追加し忘れると、そのサービスに関連するインシデントの調査精度が落ちます。IaC管理にしておけば、新サービスのオンボーディングプロセスにAgent Space設定の更新を組み込めます。
改善サイクル | 確認内容 | 想定アクション |
|---|---|---|
インシデント後 | エージェントの分析精度の評価 | 不足していた統合の追加、スコープ調整 |
月次 | Agent Spaceのドリフト確認、IAMポリシーのレビュー | 不要な権限の削除、設定の最新化 |
四半期 | 組織構造・システム構成の変化への対応 | Agent Spaceの再設計、新サービスのオンボーディング |
年次 | 全体的なアーキテクチャレビュー | Agent Space設計のゼロベース見直し |
まとめ
AWS DevOps Agentの本番環境デプロイを成功させるためのポイントをまとめます。
一番重要なのは、Agent Spaceの設計です。オンコールの責任範囲と対応させ、本番と非本番を分離し、必要なリソースだけを含める。この3点を守るだけで、エージェントの分析精度は大きく変わります。
次に重要なのは、データソースの統合の充実度です。CloudWatchだけで始めるのは構いませんが、Datadog、GitHub、PagerDutyなど実際の調査で使っているツールを積極的に統合していくことで、エージェントの能力が上がります。
実装面では、CDKかTerraformでIaC管理するのが本番運用の前提条件です。設定をコードとして管理することで、変更の追跡、レビュー、テストが可能になります。手動運用は最初の検証フェーズまでにとどめてください。
アクセス制御は最小権限の原則を徹底します。まず読み取り専用で始め、書き込み系のアクションは慎重に検討してください。Agent Spaceごとにリソースを指定したIAMポリシーで、アクセスできる範囲を明示的に制限します。
深夜のインシデント対応でエンジニアが消耗する状況は、技術的に改善できるところまで来ています。MTTRの短縮はビジネス的な価値だけじゃなく、エンジニアの健康と持続性にも直結します。AWS DevOps Agentを適切に設計・デプロイすることで、インシデント対応の質を変えられます。設計にかける時間は、必ず後で取り戻せます。
























