



はじめに!現場で動かすためのAgentic AI設計
「AIエージェントを実装したのに、本番環境では使われない」という悩みをよく聞きます。PoC段階では動くのに、運用フェーズで止まってしまう根本原因は何でしょうか。AWSのGenerative AI Innovation Centerが1,000社以上の支援から導き出した答えは、「エージェントが得意とする仕事の構造」を理解していないことにあります。本稿では、その4条件をコードと設定の視点で解説し、RagateがOpenClawを使って実践している設計パターンを紹介します。
AWSが定義するエージェントに向いている仕事の4条件
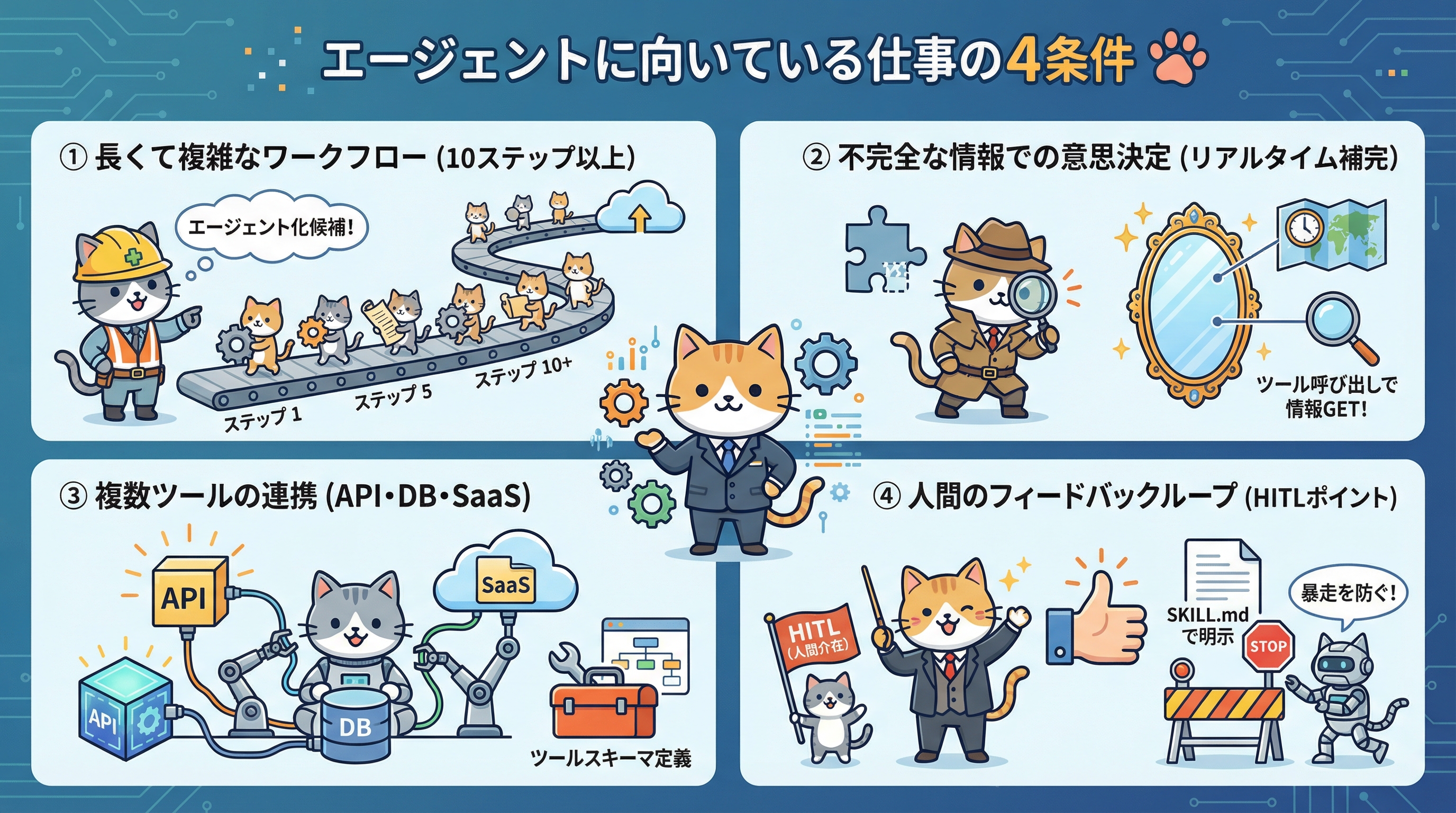
AWSは「Operationalizing Agentic AI」の中で、エージェントが活躍できる仕事の特徴を4つに整理しています。
条件 | 内容 | 設計上のポイント |
|---|---|---|
① 長くて複雑なワークフロー | 人間が手順を覚えていられないほど多ステップな処理 | ステップ数が10を超えるフローはエージェント化の候補 |
② 不完全な情報での意思決定 | 全情報が揃わなくても判断が必要な業務 | ツール呼び出しでリアルタイム情報を補完する設計 |
③ 複数ツールの連携 | API・DB・SaaS等を組み合わせる処理 | ツールスキーマを明確に定義し、LLMが選択しやすくする |
④ 人間のフィードバックループ | 承認・確認・修正が必要な場面を含む | HITLポイントをSKILL.mdで明示する |
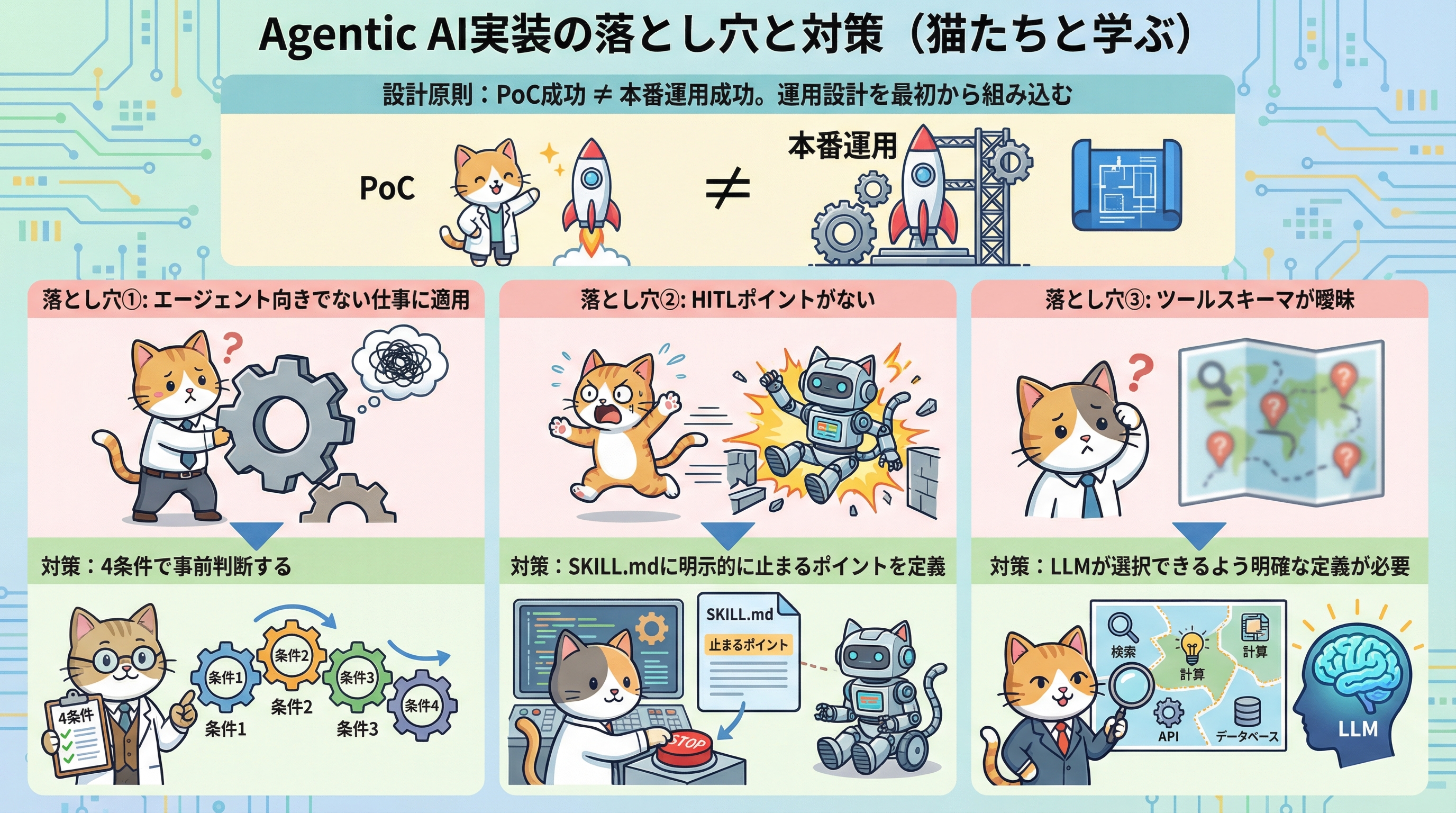
この4条件を満たしていない処理に無理やりエージェントを適用すると、過剰な複雑性とレイテンシが発生します。まず「この仕事はエージェント向きか?」を判断することが、現場実装の第一歩です。
SKILL.mdで実装するエージェントのジョブディスクリプション
RagateのOpenClawでは、各エージェントの役割・ツール・制約・HITLポイントをSKILL.mdというMarkdownファイルで定義します。これがエージェントの「ジョブディスクリプション」になります。
---
name: blog-post-draft
description: エンジニアブログの下書きを自動生成するスキル
trigger: ユーザーがブログ記事の作成を依頼したとき
---
## 役割
Ragate技術ブログのエンジニア向け記事を作成する。
## 使用ツール
- WebSearch: 技術トレンドの調査
- microCMS API: 既存記事の参照・下書き投稿
- image_upload: サムネイル画像のアップロード
## 処理フロー
1. ユーザーのブログテーマを確認
2. WebSearchで最新情報を収集
3. 記事構成(アウトライン)を作成 → **HITLポイント: ユーザー承認を待つ**
4. 本文をHTMLで生成
5. 画像を生成・アップロード
6. microCMSに下書き投稿(?status=draft 必須)
7. 管理URLをSlackで通知
## 制約
- 即時公開は禁止。必ず下書きで保存する
- 文末コロン「:」「:」は使用禁止
- 「項目名: 説明」形式の箇条書きはテーブルに変換する
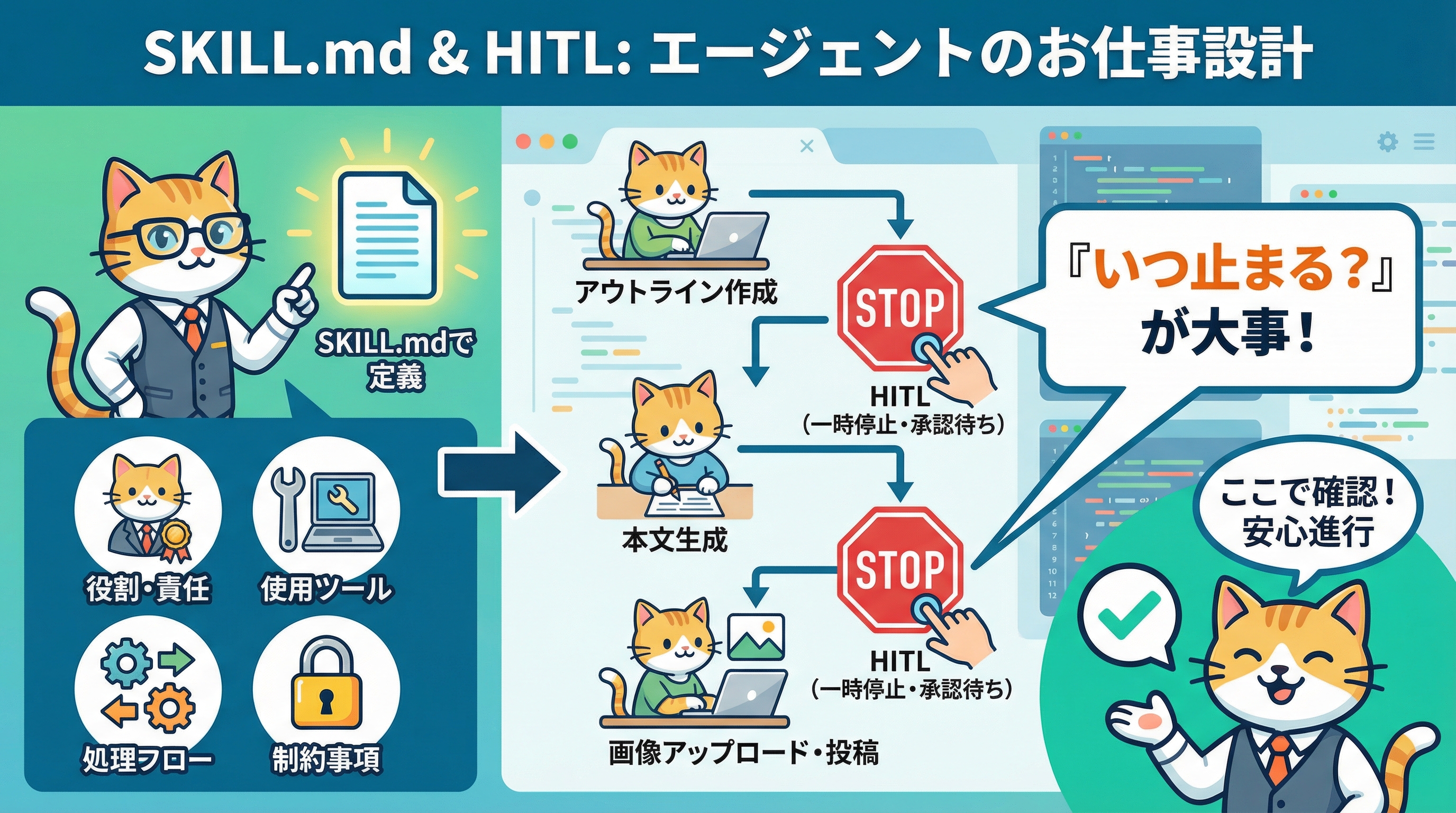
SKILL.mdの設計で重要なのは、「何をすべきか」ではなく「いつ止まるべきか」を明記することです。HITLポイントを設けることで、エージェントが暴走するリスクを設計段階で抑制できます。これはAWSが定義する4条件の「④人間のフィードバックループ」に直接対応しています。
AWS BedrockでAgentic AIを動かす最小実装
AWS BedrockのAgents APIを使った最小実装例を示します。ここでは、InvokeAgentをPythonから呼び出す基本パターンです。
import boto3
import json
bedrock_agent = boto3.client(
service_name="bedrock-agent-runtime",
region_name="us-east-1"
)
def invoke_agent(agent_id: str, alias_id: str, session_id: str, prompt: str) -> str:
"""Bedrock Agentを呼び出し、最終応答を返す"""
response = bedrock_agent.invoke_agent(
agentId=agent_id,
agentAliasId=alias_id,
sessionId=session_id,
inputText=prompt,
enableTrace=True, # デバッグ用。本番ではFalseに
)
final_response = ""
for event in response["completion"]:
if "chunk" in event:
chunk = event["chunk"]
final_response += chunk["bytes"].decode("utf-8")
return final_response
# エージェント設定(環境変数で管理推奨)
AGENT_ID = "XXXXXXXXXX" # Bedrock Agentsコンソールで取得
ALIAS_ID = "YYYYYYYYYY" # AliasのID
SESSION_ID = "session-001" # セッション管理用の任意ID
result = invoke_agent(
agent_id=AGENT_ID,
alias_id=ALIAS_ID,
session_id=SESSION_ID,
prompt="Agentic AIの導入効果についてブログ記事を作成してください"
)
print(result)
Bedrock Agentsでは、エージェントが持つアクショングループ(ツール)をOpenAPI形式で定義し、Lambda経由で実行します。SKILL.mdの「使用ツール」セクションをそのままアクショングループのスキーマに対応させると、設計と実装の一貫性が保てます。
現場エンジニアが陥りやすい3つの罠と対処法
罠 | 症状 | 対処法 |
|---|---|---|
ツール過多 | エージェントが適切なツールを選べずループする | 1エージェントのツール数は5個以下に絞る。責務を分割してマルチエージェントにする |
プロンプト汚染 | System Promptに矛盾した指示が混在し、挙動が不安定になる | SKILL.mdを単一の真実ソースとし、System Promptはそこから自動生成する |
HITLなしの自動化 | エージェントが意図しない外部API呼び出し・ファイル削除を実行する | 破壊的操作には必ずHITLポイントを設ける。dry-runオプションをデフォルトにする |
まとめ
Agentic AIを現場で動かすためには、「4条件に合った仕事の選定」「SKILL.mdによる明確なジョブディスクリプション」「Bedrock Agentsの適切な設定」という3つの柱が必要です。
RagateのOpenClawは、これらの設計パターンを蓄積した実践的なエージェントオペレーティングシステムです。自社のAgentic AI導入でお困りの場合は、ぜひRagateにご相談ください。
























