


Amazon Redshift は長くデータウェアハウスの定番として進化してきましたが、2026 年 5 月 12 日に発表された新しいインスタンスファミリー「RG インスタンス」によって、価格性能とアーキテクチャの両面で大きな転機を迎えました。AWS Graviton をベースにした RG ノードは RA3 比で最大 2.2 倍のデータウェアハウス性能を実現し、vCPU あたりの料金は 30% 低くなっています。さらに、Apache Iceberg や Apache Parquet を直接クエリできる統合データレイククエリエンジンを内蔵し、これまで Redshift Spectrum を経由していたデータレイク分析が同じクラスタ内で完結するようになりました。本記事ではデータエンジニア・バックエンド・インフラエンジニアの視点で、RG の特徴・スペック・移行パス・想定ユースケースを整理します。
RG インスタンスの登場が意味するもの
Amazon Redshift RG インスタンスは、従来の RA3 ノードファミリーを置き換える存在として 2026 年 5 月 12 日に一般提供を開始しました。バージニア北部、オハイオ、東京、大阪、ソウル、シンガポール、シドニー、フランクフルト、ロンドンなど 25 を超える AWS リージョンで利用可能で、初日から本番ワークロードに展開できる体制が整っています。
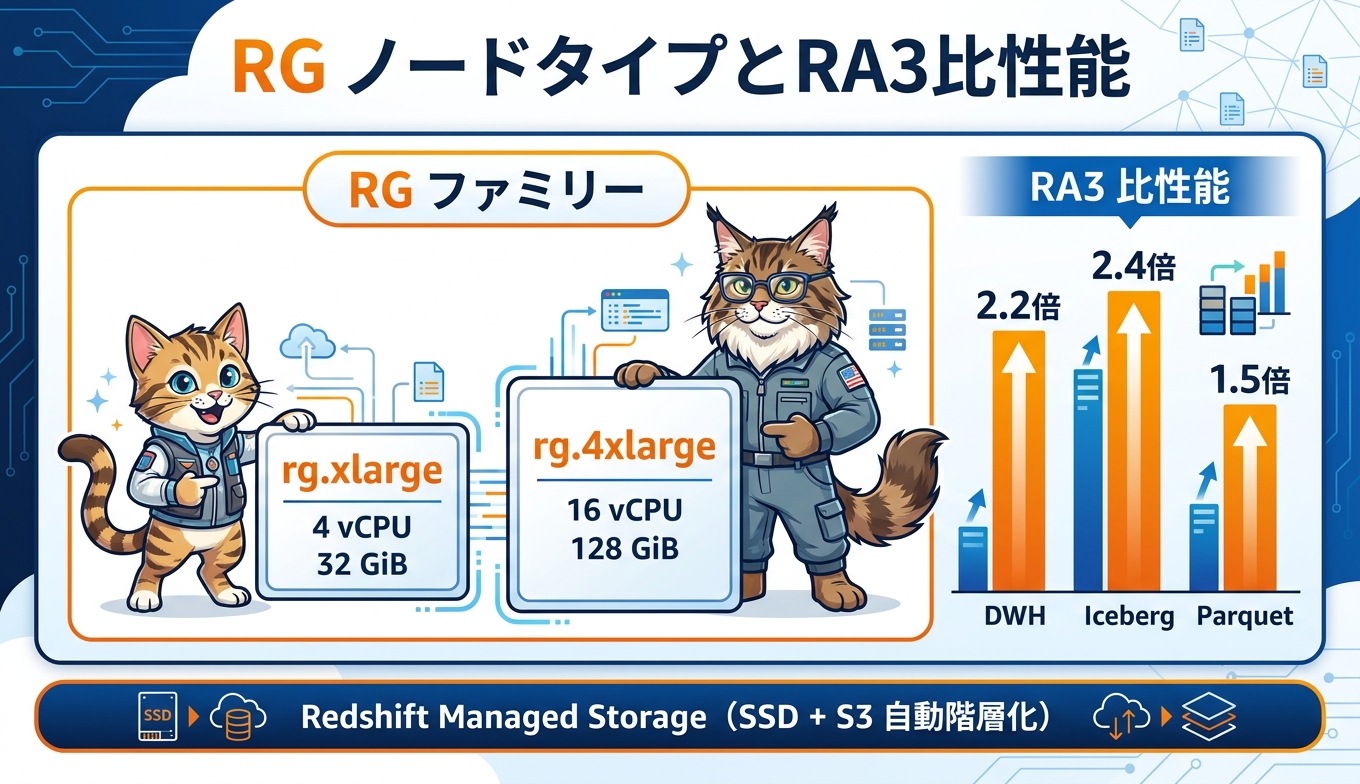
最大の特徴は 2 つあります。1 つ目は AWS Graviton 世代のプロセッサを採用したことで、データウェアハウスワークロードにおいて RA3 比で最大 2.2 倍の処理性能と vCPU あたり 30% の料金削減を実現した点です。2 つ目は、これまで Redshift Spectrum という外部レイヤで動いていたデータレイククエリを、RG クラスタ自身のコンピュートノード上で直接処理する統合データレイククエリエンジンを内蔵した点です。Apache Iceberg を最大 2.4 倍、Apache Parquet を最大 1.5 倍高速化しながら、Spectrum 利用時に発生していた 5 USD/TB のスキャン料金が不要になります。
結果として、RG インスタンスはデータウェアハウスとデータレイクを単一エンジンで横断する分析基盤を、より低コストで構築できる選択肢になりました。
ノードタイプとスペック詳細
RG ファミリーには現在 2 種類のノードタイプが用意されています。小規模から始められる rg.xlarge と、本格的な分析基盤に向く rg.4xlarge です。それぞれのスペックは下表のとおり整理できます。
ノードタイプ | vCPU | RAM | スライス/ノード | 管理ストレージ上限 | ノード範囲 | 合計ストレージ |
|---|---|---|---|---|---|---|
rg.xlarge (multi-node) | 4 | 32 GiB | 2 | 32 TB/ノード | 2〜16 | 1024 TB |
rg.4xlarge | 16 | 128 GiB | 8 | 128 TB/ノード | 2〜32 | 8192 TB |
RG ノードは RA3 と同様に Redshift Managed Storage を採用しており、各ノードに搭載した高性能 SSD と Amazon S3 を自動的に階層化します。ノード上の SSD 容量を超えたデータは自動で S3 にオフロードされ、コンピュートとストレージは独立して課金されます。データが増え続けるワークロードでも、ノード数を変えずにストレージ容量だけが伸びるため、容量計画が立てやすくなる点は従来どおりです。
クラスタの規模変更には、ダウンタイムが短い elastic resize と、ノードタイプ変更を伴う classic resize の 2 通りがあります。elastic resize を使えば rg.xlarge は最大 32 ノード、rg.4xlarge は最大 64 ノードまで拡張でき、ピーク時のスループットを柔軟に確保できます。本番ワークロードは複数ノード構成を前提とし、リーダーノードとコンピュートノードを分離して動作させる構成が推奨されます。
統合データレイククエリエンジンの仕組み
RG インスタンス最大の進化点が、統合データレイククエリエンジンです。RA3 では S3 上のデータをクエリする際に Redshift Spectrum という別レイヤのコンピュートが起動し、結果をクラスタへ戻していました。これに対して RG では、データレイククエリを RG クラスタ自身のコンピュートノード上で直接実行します。データウェアハウスと同じエンジンが Iceberg や Parquet を理解するため、SQL の組み立て方や外部スキーマの定義は変えずに、性能とコストの両方が改善する形になります。
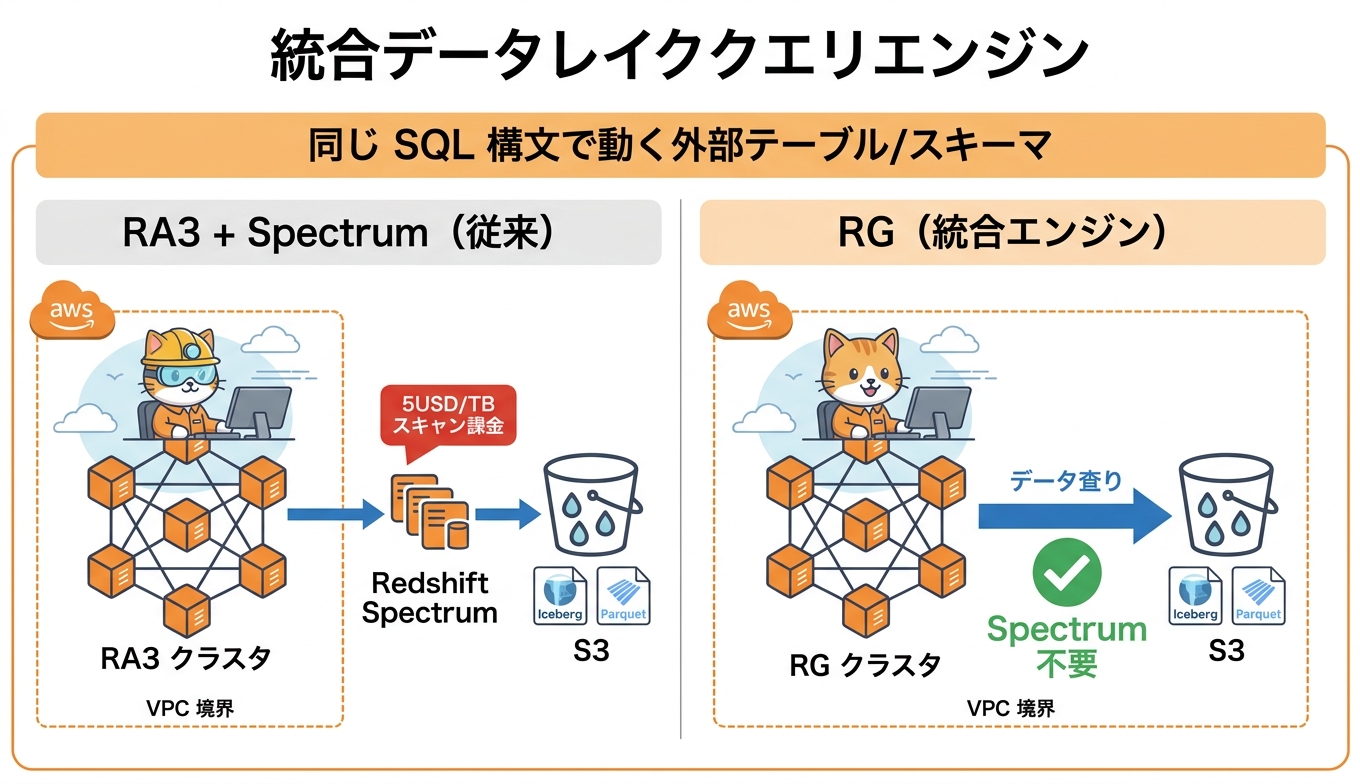
性能面では、Apache Iceberg のクエリで RA3 比 2.4 倍、Apache Parquet で 1.5 倍の高速化が公式に示されています。Iceberg のメタデータ操作やスナップショットを多用するレイクハウス型ワークロードほど効果が大きい傾向です。経済面では、Spectrum 利用時に課金されていた 5 USD/TB のスキャン料金が発生しなくなるため、データレイク中心の ETL や探索的分析を回しているチームにとっては月次のコスト構造が大きく変わります。
セキュリティ面でも見逃せない違いがあります。Spectrum はクラスタ外部のフリート上で動作していたため、ネットワーク経路の理解と監査が必要でした。RG ではクエリ処理が VPC 境界の内側で完結するため、データレイクへのアクセスをセキュリティグループや VPC エンドポイントで一貫して統制しやすくなります。
RA3 から RG への移行パス
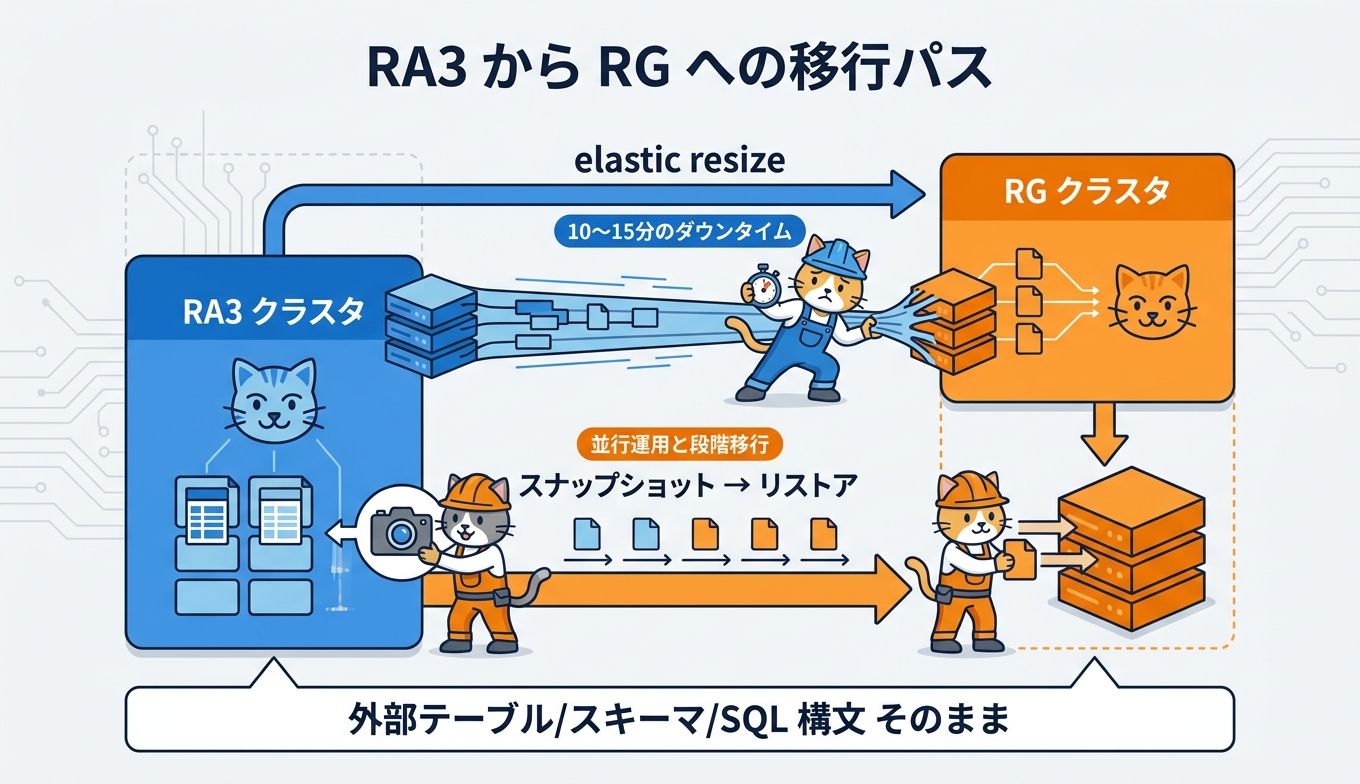
既存の Redshift ユーザーが RG に乗り換えるパスは、公式に 2 通り示されています。1 つ目は伸縮自在なサイズ変更(elastic resize)で、互換構成の RG クラスタへ 10〜15 分のダウンタイムで切り替える方法です。クラスタ ID やエンドポイントを変えずに移行できるため、アプリケーション側の切り替え影響を最小限に抑えられます。2 つ目は RA3 のスナップショットから RG クラスタを新規にリストアする方法で、現行クラスタを維持したまま並行で RG 環境を立ち上げ、ワークロード検証や DNS 切り替えで段階移行する運用に向きます。
互換性の高さも見逃せないポイントです。外部テーブル、外部スキーマ、SQL クエリ構文は変更不要で、Iceberg や Parquet を参照している既存の参照定義もそのまま動作します。これにより、移行対象のスコープは「データウェアハウス側のノード差し替え」と「Spectrum を前提としたコスト試算の見直し」に絞り込みやすくなります。
移行前にチェックしたいのは 3 点です。まずアカウントごとの RG ノード数クォータを確認し、本番規模のクラスタが起動できる枠を確保します。次にリザーブドインスタンスを保有している場合は、RA3 向け予約と RG 向け予約の扱いを確認し、コミットメント期間と新ノードへの適用条件を整理します。最後に既存の Spectrum スキャン量と新エンジンの料金構造を比較し、TCO ベースで効果が出るワークロードから優先的に移行します。
想定ユースケースと設計指針
RG インスタンスが特に効くのは、ほぼリアルタイム分析、BI ダッシュボード、ETL パイプライン、そして自律的な目標指向型 AI エージェントの 4 つです。いずれもデータウェアハウスとデータレイクの境界を頻繁にまたぐワークロードであり、Spectrum 経由の往復オーバーヘッドが大きかった領域に該当します。
具体的なシナリオとしては、S3 上に Iceberg テーブルとして蓄積したログデータを Redshift から直接クエリし、ダッシュボード側では集計済みのウェアハウステーブルを参照する構成が挙げられます。これまで Spectrum 経由で重かった集計クエリが、RG ノード上で完結するためレスポンスが安定し、運用コストも下げやすくなります。AI エージェントが動的に SQL を組み立ててレイクのデータを探索するシナリオでは、低レイテンシで結果を返せる点が特に効きます。
ノードタイプの選び方は、データ量と並列度のバランスで決めます。検証や中規模データマートには rg.xlarge を 4〜8 ノードで構成し、ペタバイト級の本番データウェアハウスには rg.4xlarge をベースに 8 ノード以上から始めるのが標準的です。スループット重視のバッチ ETL は rg.4xlarge、対話型クエリ中心であれば rg.xlarge を細かく増減させる運用が扱いやすくなります。
導入前に押さえておきたい検討ポイント
性能評価は、自社で代表的なワークロードのリプレイができる前提が重要です。AWS が公表している 2.2 倍や 2.4 倍といった数値は、特定のベンチマーク条件における最大値であり、実ワークロードでは上振れも下振れもあり得ます。本番移行前に、最低でもクエリパターンを 3 種類ほど抜き出して RA3 と RG の両方で計測し、レスポンス分布とコストを比較するのが堅実です。
TCO の比較は、ノード時間単価だけでなく Spectrum 廃止分を含めた総額で行います。たとえば rg.4xlarge は us-east-1 で 3.04267 USD/時、ra3.4xlarge は 3.26 USD/時で、ノード単価そのものでも RG が安価です。これに加えて、月数十 TB 規模で Spectrum スキャンを発行していたチームでは、5 USD/TB の課金が消える効果が大きく、年間コストで二桁パーセントの削減が現実的なケースもあります。
監視と運用面では、CloudWatch のクラスタメトリクスに加えて、データレイククエリの応答時間とスキャン量を独立して追える運用が望ましい姿です。Spectrum 時代に分けて見ていた指標が RG では同じノード上に寄るため、クエリプロファイルでウェアハウス側とレイク側の処理を可視化し、ボトルネックの所在を見失わない工夫が必要になります。
最後に、RG インスタンスはデータウェアハウスとデータレイクを単一エンジンで運用するアーキテクチャを、より低コストで実現する選択肢として有力です。まずは検証用に rg.xlarge クラスタを 1 つ立ち上げ、Iceberg や Parquet を含む現行クエリの一部をリプレイしてみるところから着手するのが、効果と移行コストを見極めるうえでの近道です。
























