



Amazon S3 Filesとは何か — 概要とアーキテクチャ
2026年4月7日に一般提供(GA)が開始されたAmazon S3 Filesは、既存のAmazon S3バケットをNFSプロトコルでファイルシステムとしてマウントできるフルマネージドサービスです。AWSは同サービスを「クラウドオブジェクトストアとして初めて、完全な機能を持つ高性能ファイルシステムアクセスを提供する」と表現しており、これまでオブジェクトストレージとファイルシステムの間にあった大きな障壁を取り除く試みとして注目されています。
S3 Filesの最大の特徴は、既存のS3バケットへのデータ移行が不要なことです。従来、POSIXファイルシステムが前提のアプリケーションをS3に対応させるには、データをEFSなど別のストレージへコピーするか、アプリケーションのコードをS3 API向けに書き直す必要がありました。S3 Filesはその手間を不要にします。
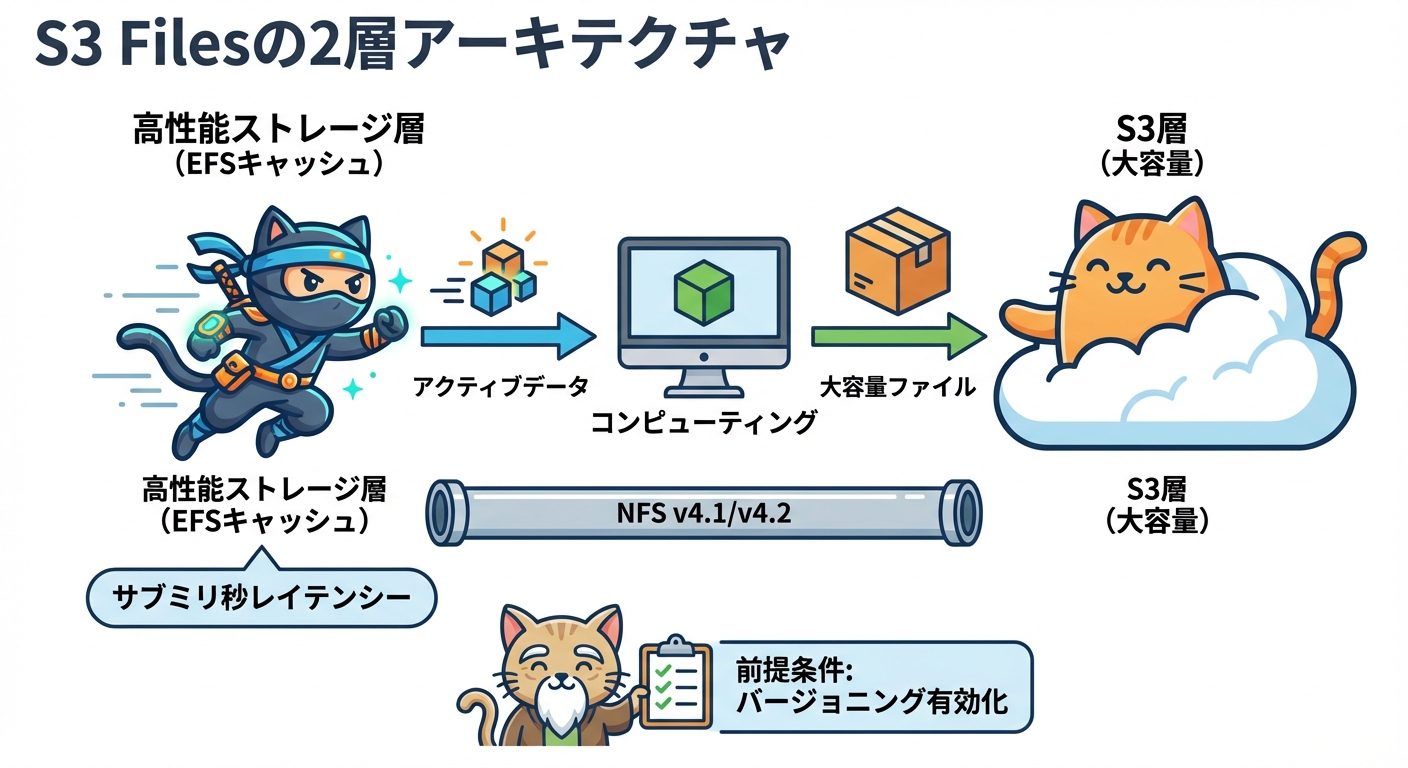
内部アーキテクチャはAmazon EFSのインフラを活用した2層構造を採用しています。
- 高性能ストレージ層(EFSバックドキャッシュ) — アクティブなデータをキャッシュし、サブミリ秒から数ミリ秒のレイテンシーで応答します
- S3永続ストレージ層 — フルデータセットの永続的な保存先です。1MB以上の大容量ファイルのシーケンシャル読み取りはこのS3層から直接サーブされます
POSIXパーミッションへの完全対応、アドバイザリーファイルロック、リード・アフター・ライト一貫性(Read-after-write consistency)を備えており、EC2・ECS・EKS・Lambda・AWS Fargate・AWS Batchなど各種コンピューティングリソースから最大25,000コネクションの同時アクセスが可能です。
利用には前提条件を満たす必要があります。S3バケットのバージョニング有効化が必須で、サーバーサイド暗号化はSSE-S3またはSSE-KMSが必要です(SSE-Cは不可)。マウントクライアントには amazon-efs-utils v3.0.0以降、TCPポート2049を開放したセキュリティグループ、DNSリゾルーションが有効なVPC、そしてファイルシステムアクセス用とコンピューティングリソース用の2つのIAMロールが必要です。
パフォーマンス特性 — サブミリ秒レイテンシーが意味するもの
キャッシュヒット時はサブミリ秒から数ミリ秒のレイテンシーで応答し、キャッシュ読み取りスループットは4.7 GB/sに達するという実測値が報告されています。S3から直接サーブされる初回読み取りでは289 MB/s、書き込みでは341 MB/s(いずれも100MBファイル・単一クライアントの実測値として報告されています)が得られるとされています。
1ファイルシステムあたり最大25,000コネクションをサポートしており、集約読み取りスループットはTB/s規模に達するとAWSは説明しています。最大読み取りIOPSは250,000、最大書き込みIOPSは50,000とされています(いずれも公式クォータページでの確認を推奨します)。
他のS3ファイルアクセス手段との比較を以下の表に示します。
ツール | レイテンシー | POSIX対応 | スループット | 管理形態 | 最適ユースケース |
|---|---|---|---|---|---|
S3 Files | サブミリ秒 | 完全対応 | TB/s規模 | フルマネージド | S3 + NFSハイブリッド |
s3fs-fuse | 10〜100ms | 部分対応 | 最大約100 MB/s | セルフ管理 | 読み取り中心の軽量用途 |
Mountpoint for S3 | 1〜10ms | 制限あり | GB/s規模 | マネージド | 追記のみのワークロード |
Storage Gateway | 1〜10ms | 完全対応 | 制限あり | マネージド | オンプレ/ハイブリッド環境 |
FSx for Lustre | サブミリ秒 | 完全対応 | TB/s規模 | マネージド | HPC/並列計算 |
大容量ファイル(1MB以上)のシーケンシャル読み取りはキャッシュ層をバイパスしてS3から直接サーブされるため、高性能キャッシュ層への追加料金が発生しません。これは大規模なメディアファイルやMLデータセットを扱う場合に特にコスト面でメリットがあります。
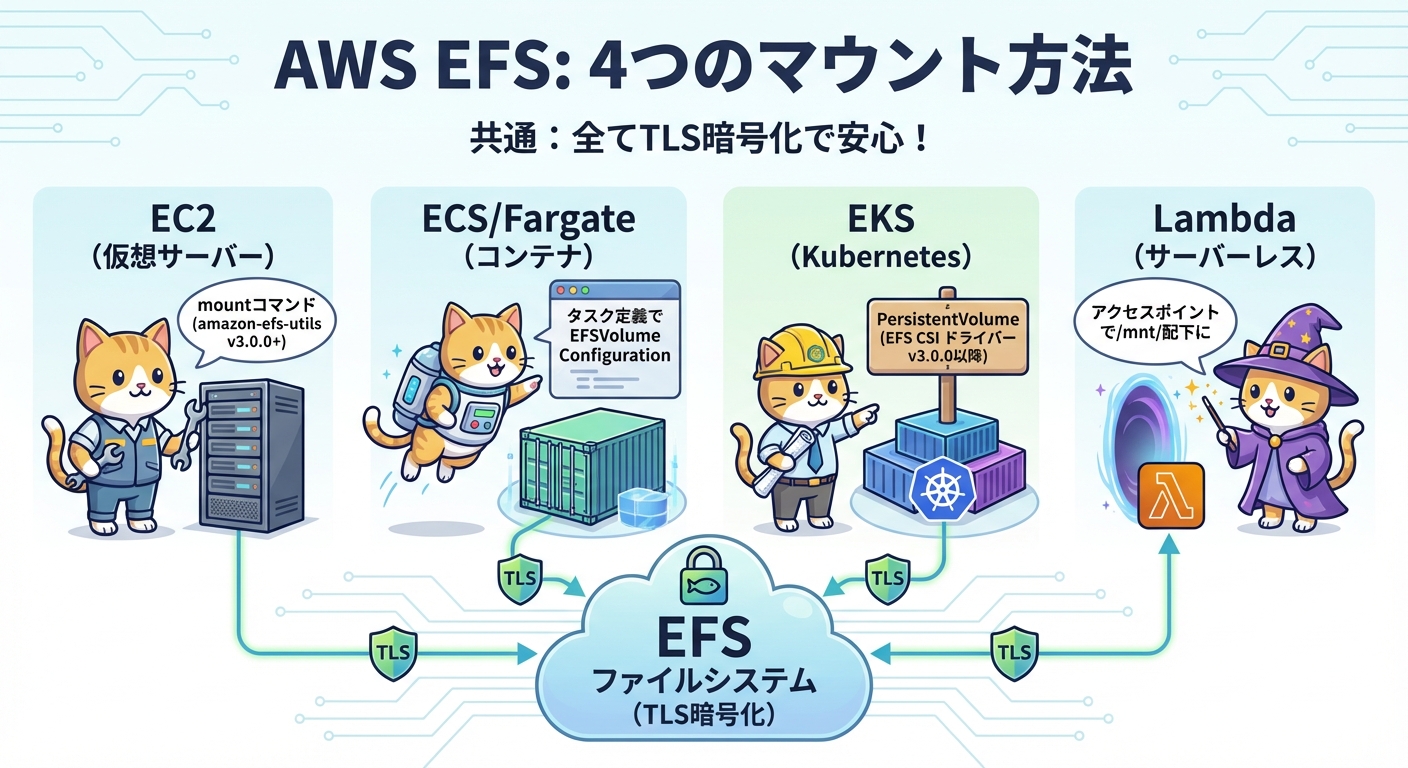
EC2・ECS・EKS・Lambdaへのマウント手順
EC2インスタンスへのマウントは最もシンプルです。amazon-efs-utils v3.0.0以降をインストールした後、以下のコマンドでマウントできます。
mount -t s3files <file-system-id> <mount-point>マウントヘルパーはインスタンスプロファイルから自動的に一時認証情報を取得します。TLS暗号化は強制適用され、無効化オプションはありません。起動時の自動マウントを /etc/fstab に設定する場合は、ブートハングを防ぐために _netdev および nofail フラグの付与を推奨します。
ECSコンテナでは、タスク定義に EFSVolumeConfiguration を設定することでマウントを実現します。EC2起動タイプとFargateの両方に対応しており、アクセスポイントを利用することでコンテナごとにUID/GIDとルートディレクトリを分離したPOSIX環境を構成できます。
EKSクラスターではAmazon EFS CSIドライバー v3.0.0以降を使用します。大まかな手順は以下のとおりです。
AmazonS3FilesCSIDriverPolicyマネージドポリシーをアタッチしたIAMロールを作成します- EKSクラスターに
efs-csi-driverをインストールします(作成したIAMロールを指定) - S3 FilesファイルシステムIDを指定してPersistentVolumeを作成します
Lambda関数では、アクセスポイント経由で /mnt/ 配下にマウントし、通常のPOSIXファイル操作がそのまま利用できます。Lambdaには最大15分の実行時間制限があるため、長時間のファイル処理は複数の関数呼び出しに分割する設計が必要です。AWS BatchとEKSの統合もサポートされており、BatchジョブでPersistentVolumeClaimを用いたアクセスが可能です。
AI・MLとメディア処理での活用シナリオ
S3 Filesが最も大きな価値を発揮するのは、複数のコンピューティングリソースが同一データセットを同時に参照する場面です。最大25,000コネクションの同時アクセスをサポートするため、大規模な並列処理ワークフローをそのまま収容できます。
AI・MLのトレーニングパイプラインでは、PyTorchやTensorFlowなどのMLフレームワークがPOSIXパスでのデータアクセスを前提とすることが多く、S3 Filesを使うことで追加設定なしにS3上のデータセットを読み込めます。全クライアントが同一データへの一貫したビューを持つため、複数トレーニングノードの並列読み込みでも整合性の問題が起きません。
また、AIエージェントのパイプライン間でのメモリ永続化(状態保持)にも活用できます。エージェントの中間状態をS3に書き込みながら、他のエージェントやオーケストレーターがリアルタイムに参照するアーキテクチャが実現します。
メディア処理の分野では、動画・画像などの大容量ファイルをS3に置いたまま既存の編集ツールやエンコーダーから直接アクセスできます。高性能キャッシュ層の効果により、繰り返しアクセスが多い素材ファイルにはローカルNVMeに近い速度を体感できるとされています。
ビッグデータの用途では、AthenaやEMRなどの分析クラスターがS3上のデータをファイルシステムとして直接処理できるため、EFSやFSxへのデータコピーが不要になります。
従来のS3 APIとの比較と使い分け
S3 FilesとS3 APIは同じS3バケットを共有しますが、データの可視性タイミングに差があります。NFS経由で書き込んだデータがS3 API経由で参照可能になるまでに約60〜70秒の遅延が生じるという実測値が報告されています。公式保証値ではない可能性があるため、本番設計ではポーリングまたはS3イベント通知を活用した設計を推奨します。一方、S3 API経由でアップロードされたオブジェクトはNFS初回アクセス時に即座にキャッシュへロードされ、以降は高速にサーブされます。
S3 API経由で設定したカスタムオブジェクトメタデータはNFSマウント経由では参照できないため、そのロジックはS3 API側に実装します。S3 Filesと通常のS3 APIの使い分けをまとめます。
- S3 Filesが適する場面 — 既存のファイルシステムアクセスコードをそのまま再利用したい場合、NFSマウントを前提とするアプリケーション、複数のコンピューティングリソースからの同時アクセスが必要な場合
- 通常のS3 APIが適する場面 — コスト最優先の用途(S3 APIのみであれば追加料金が発生しない)、S3 APIネイティブなアプリケーション、大容量ファイルの一括転送
書き込みをS3 APIで行い、読み取りをS3 Files経由で行うハイブリッドアーキテクチャは、コストとパフォーマンスのバランスを取る有効な選択肢です。
制限事項・注意点とコスト設計
主なハードリミットとして、最大ファイルサイズは48 TiB、アカウントあたりの最大ファイルシステム数は1,000、1ファイルシステムにつきVPCは1つのみです。ハードリンク、S3 Glacierストレージクラス、Kerberos認証、pNFS、S3 ACLは非対応です。また、S3のキー長上限1,024バイトの制約が有効なため、深いディレクトリ構造や長いファイル名には注意が必要です。
料金体系は3つのコンポーネントで構成されます。
- 高性能ストレージ料金 — キャッシュ上のデータ量に対するGB/月単価です。バケット全体ではなくキャッシュに乗っているデータ分のみが課金対象です
- ファイルシステムアクセス料金 — キャッシュ層でのNFSオペレーションに対するリクエストあたりの料金です。メタデータルックアップ、ディレクトリ一覧表示、128KB未満の読み取りなど小さいファイル操作が対象です
- 標準S3料金 — これまでどおり変更ありません。1MB以上の大容量ファイルのシーケンシャル読み取りはS3から直接サーブされるため、S3 Filesの追加料金は発生しません
AWSは、従来のようにS3とEFSなど別ファイルシステム間でデータを往来させる構成と比較して最大90%のコスト削減が可能と主張しています。容量のプロビジョニングは不要で完全な従量課金です。
本番運用のベストプラクティスをまとめます。
- アプリケーションごとにアクセスポイントを作成し、UID/GIDとルートディレクトリを分離します
- CloudWatchのキャッシュヒット率を確認しながら、キャッシュ有効期限(1〜365日、デフォルト30日)を最適化します
- コンピューティングリソースと同じAZにマウントターゲットを配置し、クロスAZ転送コストを回避します
/etc/fstabへの登録時は_netdevとnofailフラグを指定してブートハングを防止します- セキュリティグループのポート2049は特定のソースSGに限定し、最小権限を維持します
- CloudWatchでキャッシュとS3間の同期エラーを監視し、データ整合性の問題を早期に検知します
Amazon S3 Filesは、オブジェクトストレージとファイルシステムの境界を取り払う画期的なサービスです。AI/MLワークフロー、メディア処理、大規模なデータパイプラインを運用するチームにとって、データ移行コストや二重管理の手間を削減できる有力な選択肢となるでしょう。
























