



AWS Sustainability Insights Framework とは何か
AWS Sustainability Insights Framework(以下 SIF)は、企業の炭素排出量追跡を自動化するアプリケーションの設計と実装を加速する基盤コンポーネント群です。公式 GitHub README と AWS Solutions Library では「炭素排出量追跡を自動化するアプリケーションの設計と実装を加速する基盤的なソフトウェアコンポーネントを提供する」と定義されており、SaaS ではなくお客様自身の AWS アカウントへデプロイして利用するリファレンス実装である点が特徴です。
配布は AWS Solutions Library Guidance の一つとして行われ、本体リポジトリは Apache License 2.0、CLI リポジトリは MIT-0 で公開されています。主要言語は TypeScript が約 65.6%、Gherkin が約 17.8%、Java が約 13.0% で、サーバーレス TypeScript 実装と業務領域に近い Java モジュールの組み合わせです。
類似機能の AWS Customer Carbon Footprint Tool(CCFT)は AWS 利用そのものに伴う排出量を AWS 側で算出して表示するツールで、2026 年 6 月 30 日に廃止予定として告知されています。SIF はこれと競合するものではなく、自社事業全体の排出量を企業横断で算定するための自前基盤として、CCFT と補完関係にあると位置づけられます。
SIF が解決する課題と GHG レポーティングでの位置づけ
多くの企業ではサステナビリティレポートや GHG 排出量の算定が、いまだに表計算ソフトでの集計に依存しており、属人化と再現性の低さが課題となっています。請求書、燃料消費記録、調達文書、IoT センサーといったデータソースは粒度も形式も異なり、排出係数のバージョン管理も難しいのが実情です。SIF はこれらのデータパイプラインと計算ロジックを共通基盤として整備し、自動化された排出量算定を実現します。
主用途は GHG Protocol に基づく Scope 1(直接排出)、Scope 2(間接排出)、Scope 3(サプライチェーン)の自動算定と、排出係数のバージョン管理です。米国 EPA Subpart W に基づく石油・ガス事業者の報告や、ESG 開示に向けた複数事業部・複数顧客向けレポーティングを単一基盤で支える設計意図がドキュメントから読み取れます。
関連ガイダンスとして Sustainability Data Fabric(SDF)や Sustainability Data Management on AWS が別途公開されています。いずれも持続可能性データの収集・統合・共有に焦点を当て、SIF とは補完関係として組み合わせて利用されます。後継や前身といった関係性は公式に明示されておらず、本記事でも補完関係としてのみ扱います。
モジュラーアーキテクチャの全体像と主要モジュール
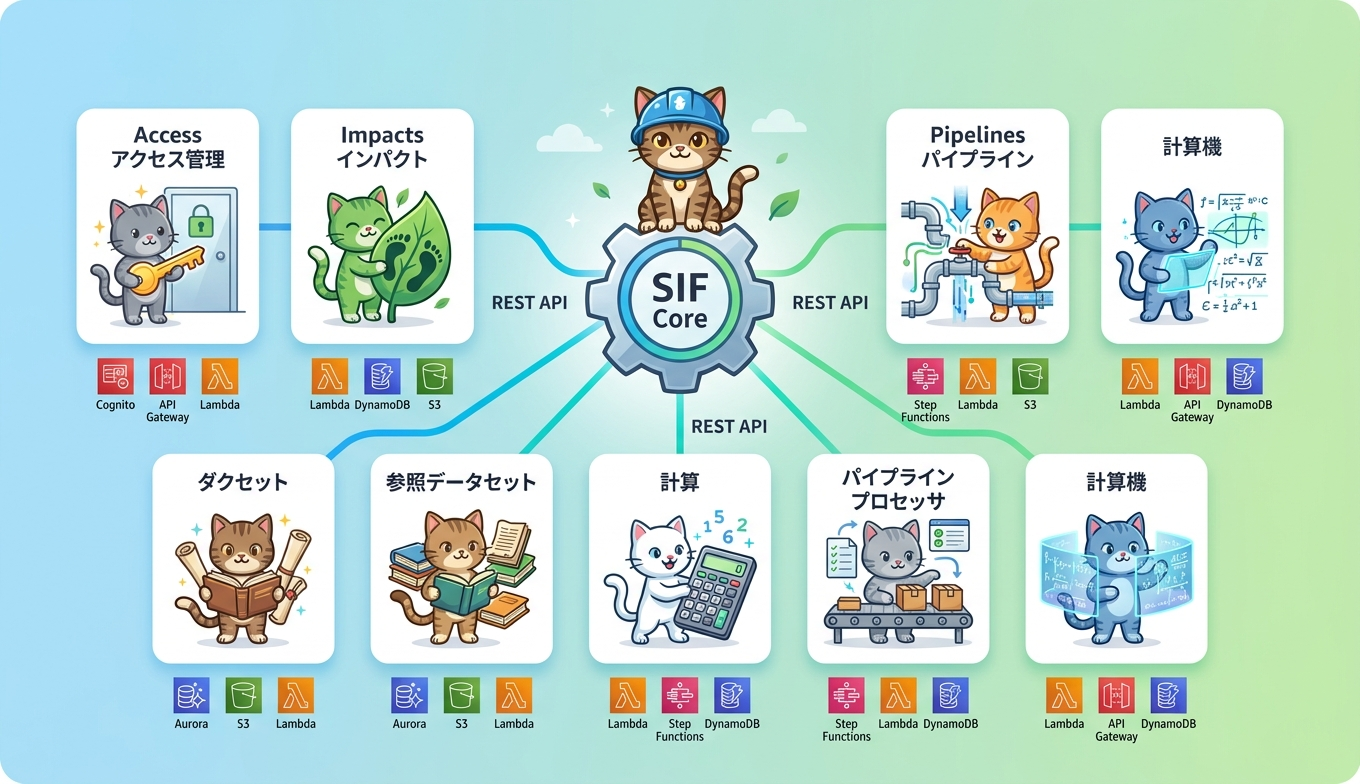
SIF は、責務を絞ったサーバーレスのモジュール群を REST API で束ねるアーキテクチャを採用しています。各モジュールは独立してデプロイ可能で、外部システムや独自フロントエンドからは REST API 経由で機能を呼び出します。公式サンプル aws-samples/aws-sif-carbon-accounting-portal のように、SIF の API を利用したカーボン会計ポータルを CDK で構築するリファレンスも公開されています。主要モジュールは次のとおりです。
モジュール | 役割 |
|---|---|
Access Management | ユーザー、グループ、権限を管理し、グループ単位でリソースを分離してマルチテナント運用の土台を提供します。 |
Impacts | GHG 排出係数などのインパクト関連リソースをカタログとして管理し、Calculations や Pipelines から参照されます。 |
Reference Datasets | ルックアップテーブル等のカスタムデータセットを取り込み、パイプラインから参照可能にします。 |
Calculations | 低コードで方程式や関数を定義・管理し、排出量計算ロジックを資産として再利用可能にします。 |
Pipelines | データ取込と変換パイプラインを定義し、CSV や AWS Clean Rooms、独自コネクタから取り込みます。 |
Pipeline Processor | パイプライン実行管理と集約処理を担い、KPI やメトリクスの算出を行います。 |
Calculator | 実際の演算実行と監査ログ生成を担い、Pipeline Processor から呼び出されます。 |
Calculator については独立モジュールとして紹介する資料と、Pipeline Processor の内部コンポーネントとして扱う資料があり、6 モジュールあるいは 7 モジュールと表現が分かれます。本記事ではどちらかを正解と断定せず、両方の表現が併存している点を共有します。SIF はマルチテナントとシングルテナントの両モードに対応し、業界固有の計算式を上位テナント側で提供する SaaS 的な運用も可能です。全体像は公式アーキテクチャ図 PDF で確認できます。
SIF を支える AWS サービススタック
SIF の実装ガイドには、利用する主要な AWS サービスが明記されています。コンピュートとオーケストレーションでは AWS Lambda、AWS Step Functions、Amazon EventBridge を組み合わせ、イベント駆動のサーバーレスワークフローを構築します。API と認証では Amazon API Gateway が REST エンドポイントを提供し、Amazon Cognito がユーザー認証を担います。
データストアは用途に応じて使い分けられ、柔軟なスキーマには Amazon DynamoDB、パイプライン処理の関係データには Amazon Aurora Serverless v2、データセットや取込ファイルには Amazon S3 が利用されます。メッセージングには Amazon SQS と Amazon Kinesis Data Firehose、運用とセキュリティ、IaC では AWS KMS、AWS Systems Manager Parameter Store、AWS CloudFormation、AWS Cloud Development Kit(AWS CDK)が中心です。
外部データ連携のコネクタとして AWS Clean Rooms、AWS DataZone、Amazon Kinesis が利用可能で、サプライヤー連携やデータカタログ統合に対応します。Sustainability Data Fabric などのガイダンスと連携することで、データ収集から算定、レポートまでをエンドツーエンドに自動化する土台が整います。
導入手順 CDK ウォークスルーと sif-cli の使い分け
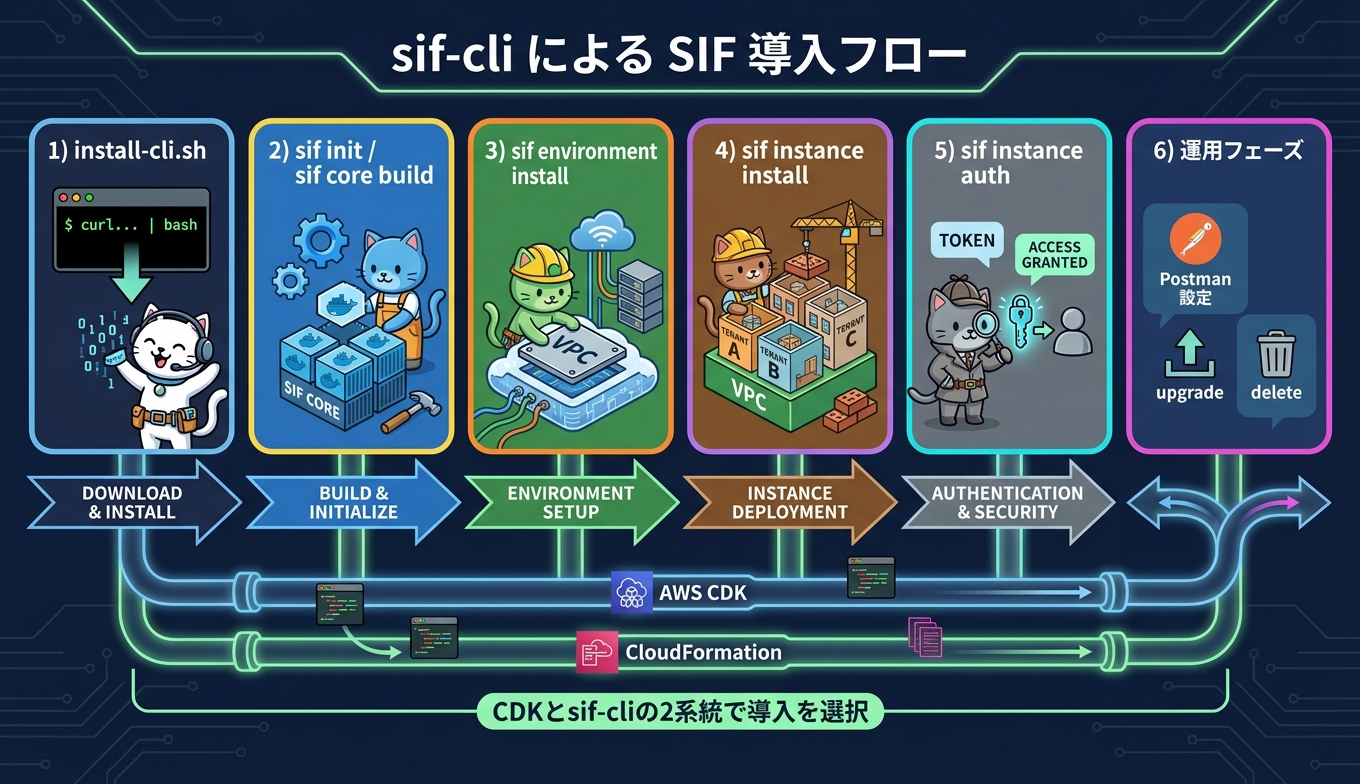
SIF の導入には 2 系統の方法が用意されています。1 つ目は AWS CDK を用いた手動デプロイで、GitHub 本体リポジトリの docs/deployment/cdk_walkthrough.md に沿って AWS CLI、AWS CDK、適切な IAM 権限を準備し、モジュール単位でデプロイします。2 つ目は別リポジトリで提供される sif-cli を利用する方法で、SIF のクローン、ビルド、バージョン切替、環境とテナントのライフサイクルを CLI に集約できる点が利点です。公式ブログでも sif-cli 経由のデプロイが推奨手順として案内されています。
sif-cli の前提条件は次のとおりです。リポジトリ取得とバージョン切替に Git、Java モジュールのビルドに Docker、CDK 実行用の適切なポリシーを持つ AWS 認証情報が必要です。既存 VPC を流用する場合は isolated と private サブネットの設計が要件となり、必要に応じて AWS Client VPN 証明書を有効化できます。代表的なコマンドフローは次のとおりです。
# インストール
curl https://raw.githubusercontent.com/aws-solutions-library-samples/guidance-for-aws-sustainability-insights-framework/main/scripts/install-cli.sh | sh
# 初期化と本体ビルド
sif init
sif core clone
sif core build
sif core switch -r v1.8.1
# 環境とテナント作成
sif environment install -e demo
sif instance install -e demo -t sampleTenant
# 認証と Postman 設定
sif instance auth -e demo -t sampleTenant -u test@user.com -p password -g /
sif instance postman -e demo -t sampleTenant
# 更新と削除
sif environment upgrade -e demo
sif instance upgrade -e demo -t sampleTenant
sif instance delete -e demo -t sampleTenant
sif environment delete -e demo
本番運用に進む前には docs/deployment/path_to_production.md のチェックリストを確認し、VPC 設計、ログ、バックアップ、認証設計を棚卸しすることが推奨されます。本体の最新タグは v1.10.0(2024 年 4 月 26 日公開)、直近の push は 2024 年 10 月 20 日であり、アーカイブされていないものの更新は止まっています。パッチ追従とセキュリティ対応は自社で担保する前提で採用判断を行う必要があります。
導入メリットと運用上の注意点
SIF を採用する主なメリットは次のとおりです。手動の Excel 集計を自動化することで人的エラーを削減でき、計算ロジックと参照データのバージョン管理、監査ログの自動生成によって透明性と監査可能性が向上します。共通スキーマで品質とレポート粒度を統一でき、サーバーレス基盤による自動スケールと AWS Well-Architected Framework の 6 本柱への整合性も確保されます。マルチテナント運用が可能で、ライセンス費用は不要、利用した AWS サービスの従量課金のみで運用できます。コスト最適化では Compute Savings Plans、DynamoDB と Aurora の自動スケーリング、コスト配分タグなどが活用可能です。
運用上の注意点として、対応リージョンが公式ガイドに明記されていないため、Aurora Serverless v2 や Kinesis Data Firehose など利用する AWS サービスのリージョンサポート状況を基準にデプロイ先を選定します。料金も月額固定の料金表はなく、Lambda や Aurora Serverless v2、DynamoDB、API Gateway、S3 などの従量課金合算となるため、コスト配分タグでの可視化と継続的な見直しが重要です。算定精度は Impacts と Reference Datasets の品質に依存するため、排出係数の出典管理と改定追従の運用設計が欠かせません。
関連プロダクトとの混同にも注意が必要です。CCFT は AWS 利用に伴う排出量を可視化するもので SIF とは別物であり、Sustainability Data Fabric は SIF と組み合わせるデータ統合レイヤとして整理されます。国内事例については公開情報での確認が限定的なため、まずは PoC 規模で sif-cli を用いたデモ環境を構築し、自社データを当てはめながら段階的に評価するアプローチが現実的です。
























